
Time Series databases (TSDBs) such as Prometheus, InfluxDB, or TimescaleDB have gotten increasingly popular in the last few years to store and query data produced over a period of time. They’re specifically designed to process a high rate of time-stamped events such as application or system metrics, sensor data from IoT devices, stock market data, and so on. This is then used to power various use cases like observability, dashboarding, forecasting, and also troubleshooting.
Although they work great in the scenarios they were designed to handle, the question remains whether they can be used as a general purpose real-time online analytical processing (OLAP) database. In this blog, we will explore this idea further.
While presenting this analysis, we looked at some of the popular TSDBs such as Prometheus, OpenTSDB, InfluxDB and TimeScaleDB. It’s possible that we’ve missed certain capabilities that exist in other such technologies.
Requirements of a real-time OLAP platform
In a previous blog, we enumerated the various requirements of an ideal real-time OLAP platform. Here are the key dimensions:
Use cases
The real-time analytics use cases can be quite diverse, ranging from user-facing analytics and personalization to internal analytics using dashboards. Here’s a quick view of the industries and the typical use cases thereof.
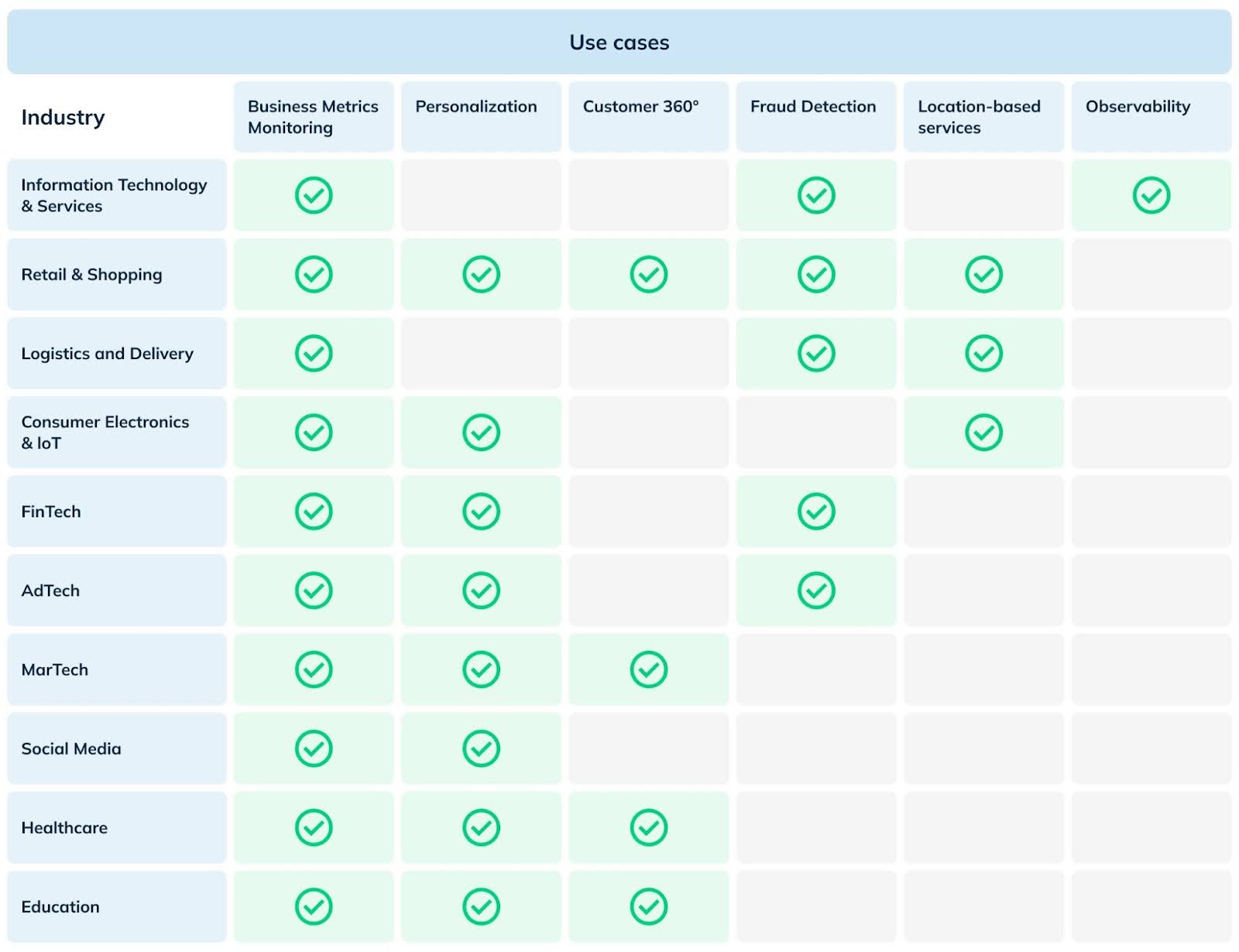
Figure 1: Use cases of real-time analytics and corresponding industries
Query performance

Figure 2: Varied requirements for real-time analytics use cases
As depicted in figure 2, the performance requirements of the aforementioned use cases are quite varied. For instance, the user-facing analytical applications can issue a very high rate of queries (from 10s to 100s of thousands of queries per second) and expect the latency to be sub-second. On the other hand, dashboarding or ad-hoc analytics may only issue 10s of queries per second, but the queries can be quite complex and take much longer to execute.
Data ingestion
Users need the ability to analyze data coming from various sources such as:
- Streaming: User activities or clickstream events captured via the website or app in systems like Apache Kafka or Amazon Kinesis.
- Batch: Comprises raw as well as derived data (post-ETL/ELT) stored in cloud object stores or data lakes.
- SQL sources: Entity data managed by traditional Online Transaction Processing (OLTP) RDBMS such as MySQL or Postgres or data warehouses such as Snowflake or BigQuery.
Furthermore, the actual data from these sources may be represented in various formats such as CSV, Json, Avro, Protobuf, and so on with various compression schemes. Finally, we want to ensure that data is ingested as quickly as possible to enable a high degree of freshness.
Cost to serve
Some of these use cases require users to store several terabytes to petabytes of data in the presence of highly concurrent queries. Ideally, we would want to minimize the cost to serve for such queries and store large datasets efficiently so that we reduce the Total Cost of Ownership (TCO).
Evaluating fit for time series databases
Let’s analyze how time series databases fare on the above dimensions.
Use cases
Most of the TSDBs were designed with a specific purpose: to store time-stamped data points efficiently with a high degree of freshness and to perform filtering and aggregations in a low latency manner. This makes them a great fit for observability use cases — specifically for metrics. The common applications include:
- Internet of Things (IoT): Being able to monitor and aggregate sensor data coming from connected devices
- Financial monitoring: Being able to identify trends (eg: moving average) in high-frequency trading data, stock market tick data, cryptocurrency transactions, and other financial metrics
- System monitoring: A common use case is to visualize and alert on metrics captured from various applications and systems related to network, CPU, memory usage, system health, performance and so on.
- Weather forecasting: TSDBs are a good fit for storing recordings of changing temperature, wind speed, humidity which in turn are analyzed for accurate weather forecasting.
You can find other such applications in this great New Stack article, “What Are Time Series Databases, and Why Do You Need Them?”
However, time series databases fall short when it comes to high cardinality data, complex slice-and-dice use cases, or complex event processing — or in general when the underlying data may not have a time component associated with it. For example:
- User-facing analytics: Take LinkedIn’s example, where each of their one billion global users can, at any time, get a personalized view of their posts, which users can filter based on various dimensions (geography, industry, role). Building this using TSDBs would be a challenging task because while they may support aggregate functions, TSDBs often do not handle aggregations easily, efficiently, or performantly.
- Funnel analysis: Even though clickstream data captured from a website is a time series dataset, performing complex analytical operations like sales funnel analysis (conversion / drop off rates) or session analysis is difficult to do on time series databases.
- Fraud detection: Although we could perform basic anomaly detection using TSDBs that involve single metrics, complex contextual analysis that takes into account various factors — high dimensionality analysis — such as user behavior, transaction history, and account activity is not possible with TSDBs. Some of these datasets may not be time series in nature either (eg: trust score).
There are many such examples where, instead, we may need to choose a general purpose real-time OLAP database to achieve our goals.
Query performance
Most TSDBs were designed for internal analytics such as monitoring, dashboarding and alerting where the Queries Per Second (QPS) are in the 100s or lower. These databases are not typically used in cases where the QPS can be very high — think of 10,000 to 100,000 queries per second. This makes them not suitable for building user facing analytical applications as described above.
In terms of query latency TSDBs are very fast when it comes to simple aggregations. However, when we have complex filters, group by, order by or even data joins, it is difficult to achieve sub-second latencies. This in turn limits the number of use cases that can be powered by TSDBs.
This is a good article that compares performance across different TSDBs: “DevOps Performance Comparison: InfluxDB and TimescaleDB vs. TDengine”
Data ingestion
Data source support
- Real-time / Streaming data sources: TSDBs are custom-built to handle a high rate of ingestion in real-time with a high degree of data freshness. If the data is coming from systems like Apache Kafka, some TSDBs like InfluxData provide a plugin to natively ingest from Kafka. Others, like Timescale DB, provide a JDBC connector.
- Batch & SQL sources: Most of the TSDBs don’t have any native support for bulk loading data stored in batch and SQL sources such as Amazon S3, Snowflake, or Google BigQuery (there are some exceptions such as Amazon Timestream).
Data format support
Most TSDBs have a great support for data formats related to metric collection such as Dropwizard, Graphite, collectd, InfluxDB line protocol, and so on. They also support some standard data formats like Avro, CSV, and JSON, but the support is not very extensive (for example, Protobuf is not supported in all the TSDBs).
Other considerations
- Upsert: Some databases such as InfluxDB and TimescaleDB support native upsert semantics, but not all do.
- Data backfills: This is generally inefficient for most TSDBs and has severe performance implications when backfilling data in the presence of live traffic. If the source of backfill is in systems like Amazon S3, then custom integrations will most likely be needed.
- Schema evolution: This is easier in TSDBs with tag set data models (schemaless) such as Prometheus/InfluxDB, but slightly more complex for those with relational data models such as Timescale DB. On the flip side, a tag set data model is restrictive and makes it very difficult to issue complex OLAP queries.
Cost to serve
The datasets hosted and processed by TSDBs are generally huge in volume and account for a substantial chunk of the cost to serve. It’s only natural that TSDBs are optimized for efficient storage of such time series datasets, thus lowering overall cost to serve. Here are the key dimensions that help minimize storage footprint:
- Columnar storage: Some TSDBs like InfluxDB provide a columnar storage option that enables more efficient compression of data, thus reducing the storage overhead. In addition, this also reduces query time overhead for certain types of queries.
- Compression: TSDBs employ compression techniques (eg: Delta, run-length, Gorilla, Snappy, LZ4, and so on) to further reduce the storage footprint for data at rest.
- Rollups: Most of the time series analytics use cases are interested in fresh data, and hence that’s typically stored in the raw form. Rollups are an excellent way to aggregate older data into coarser granularity, thus leading to storage and query efficiency.
In addition, TSDBs also use time-based indexing, partitioning, and sharding mechanisms to accelerate query processing, which tends to reduce overall cost to serve.
Evaluating fit for real-time OLAP with Apache Pinot
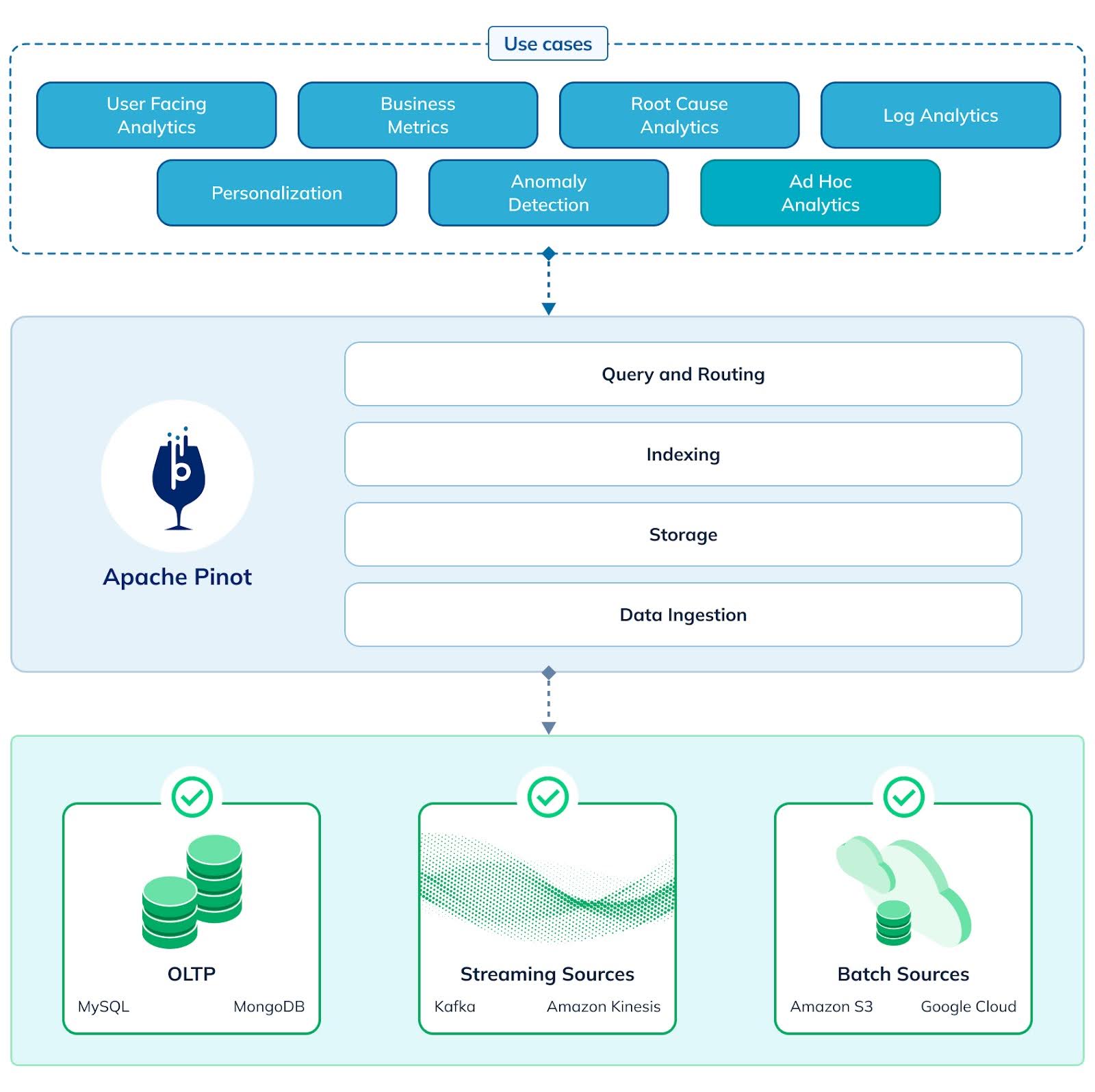
Figure 3: Apache Pinot is purpose-built for popular real-time analytics use cases with features such as querying and routing, indexing, storage, and data ingestion
In the second part of our blog series on how to choose an OLAP platform, we describe in detail how Apache Pinot is a great fit as an ideal OLAP platform. Below is a quick summary along with the previously discussed dimensions.
Use cases
Apache Pinot enables users to build all kinds of use cases in the same platform due to its high query performance, variety of indexes at the disposal, and ANSI SQL compatibility, amongst other key features. Some of the biggest companies in the world are leveraging Apache Pinot for building powerful analytical applications such as:
- User-facing analytics: Uber’s Restaurant Manager
- Personalization: LinkedIn’s content relevance
- Business metrics: Stripe’s metrics platform
- Observability: Cisco Webex’s real-time observability
- Anomaly detection & RCA: Just Eat Takeaway’s intelligence platform
These and many other Pinot use cases are documented here.
Query performance

Figure 4: Query performance of Apache Pinot at Uber and Stripe
Apache Pinot has been purpose-built for supporting high-throughput, low-latency analytical queries. We’ve discussed in detail the architectural choices that led to this high performance in our 2-part blog series: What Makes Apache Pinot Fast. Some of the key highlights are:
- Ability to run 10s to 100s of thousands of queries per second on a single cluster
- Ability to achieve p99 query latency under 100 ms
- Optimizations applied at various layers: Query routing, per server, and even per segment (unit of data processing in Pinot)
In addition, Pinot also supports high performance join queries through various optimizations, as detailed in our blog on Query-time JOINs in Apache Pinot 1.0. In the given case study, Pinot was able to execute sub-second join queries between tables hosting billions of rows with more than 1 billion records to be processed post-filter.
Data ingestion
Apache Pinot has excellent native support for ingesting data from various sources such as streaming (Apache Kafka, Amazon Kinesis, Google PubSub), batch (Amazon S3, Google GCS, Azure ADLS) and SQL (Snowflake, BigQuery). You don’t need any external ETL component to ingest these datasets. Similarly, it also has rich support for various data formats such as Parquet, Avro, Json, Protobuf, and so on.
Other considerations
- Real-time upsert support: Users can ingest upsert records or de-duplicate data in real-time.
- Backfill / Data correction: Natively supported via Pinot minion framework. Users can either run periodic backfill jobs or a one time customized backfill for replacing a certain time window.
- Schema evolution: Users can evolve the Pinot schema as long as it’s backwards compatible and then backfill historical data for newly added columns.
Cost to serve
Similar to TSDBs, Apache Pinot has been optimized for efficient storage through the following capabilities:
- Columnar storage: Unlike TSDBs, Apache Pinot is a pure column store, which enables it to store wide tables with several dimensions in an efficient way. Unlike TSDBs, this makes it easy to store and process metrics tags and values in a standard fashion.
- Compression: In addition to columnar compression, Apache Pinot also supports dictionary encoding, run-length, LZ4, and Snappy compression techniques for compressing data within a segment.
- Rollups: Users can rollup historical data at a coarser granularity based on the data age. For example, Pinot can store incoming data at raw granularity and after 1 week automatically rollup to a weekly/monthly granularity.
- Tiered storage: Pinot enables the data to be spread across various storage tiers, from hot storage (local SSD) and warm storage (EBS volumes) to cold storage where data is stored on cheap cloud storage. Users can further optimize performance by configuring indexes on the remote data, prefetching and caching as well as index pinning. See this wiki for more details.
Comparing time series databases vs. real-time OLAP
In this blog, we enumerated the various requirements of a real-time OLAP platform and compared TSDBs to Apache Pinot on the dimensions of use cases, query performance, data ingestion, and cost to serve. One thing clearly stands out — Apache Pinot has been architected as a generic platform, whereas TSDBs are more niche.
TSDBs seem to excel in:
- Observability use cases especially for fresh data
- Optimized for storage efficiency and hence lower TCO
TSDBs seem to have certain gaps around:
- Not applicable for a variety of real-time analytics use cases as described above
- Query performance is limited
- Does not have a comprehensive data ingestion story
- Data types are limited
- Not efficient for handling high-cardinality time series
On the other hand, Apache Pinot does satisfy most of the requirements mentioned above. Specifically:
- Generic platform for building various kinds of use cases
- Best-in-class query performance
- Rich data ingestion support for both real-time and historical data
- Optimized for storage efficiency as well — similar to TSDBs
- Highly scalable and easily handles high cardinality data
In conclusion, Apache Pinot is a great fit for various real-time OLAP use cases, including those involving time-series datasets at high cardinality and scale.
Get Started with Apache Pinot on StarTree Cloud
The best way to get started with real-time analytics and Apache Pinot is with a StarTree Cloud trial account. Request a trial to get your own managed serverless account for development and testing use. Or Book a demo if you have questions and would like a quick tour of how StarTree Cloud can work for you.
