

In our post on How To Pick A Real-Time OLAP Platform we highlighted some of the typical use-cases and requirements people look for when choosing a ‘real-time’ OLAP platform. Such a system needs to be capable of delivering extremely high throughput with low query latency and at the same time provide high query accuracy – in the presence of data duplication and real-time updates. Similarly, the same system must be able to ingest data from all kinds of data sources, handle unstructured data and real-time upserts.
Enter Apache Pinot – a system that was purpose-built for supporting analytical use cases at scale and which has evolved to a highly customizable platform.
This article reviews some of the different capabilities of Apache Pinot that satisfy the needs of real-time analytics at scale.
Overview of Apache Pinot
Apache Pinot is a distributed analytics data store that is rapidly becoming the go-to solution for building real-time analytical applications at scale. Pinot stands out due to its ability to deliver low-latency performance for high-throughput analytical queries. This makes it an ideal fit for powering internal dashboards as well as mission-critical, user-facing applications such as LinkedIn’s user profile analytics and Uber’s Restaurant Manager.
Let’s review it’s core capabilities:
High Speed Ingestion for Fresh Queries
As mentioned before, Pinot provides a convenient way to ingest data from various streaming sources (Apache Kafka, Amazon Kinesis) and batch sources (HDFS, GCS, S3). A special case of the streaming source is to ingest Change Data Capture (CDC) events from transactional data stores like MySQL or Postgres using standard technologies such as Debezium (see here for more details). Pinot’s distributed architecture enables ingesting large volumes of data quickly and makes it available for querying with millisecond level freshness guarantees.
Here are some of the salient ingestion features of data ingestion in Pinot
Upserts
Pinot has built-in support for handling data upserts in a realtime table, based on a primary key. This can be accomplished in 2 ways:
- Full row upsert: Replace the entire row with the new one for the same primary key
- Partial upsert: Replace a subset of the columns for the same primary key
This is very useful to handle column updates appearing in a CDC stream. It also provides a way to resolve duplicates or updates to data in real-time and hence provide accurate query results.
Data transformation support
Pinot can transform records on the fly during ingestion. This removes the need for external, pre-processing workflows for common scenarios, such as filtering records, derived columns, or flattening complex fields. Pinot offers a plethora of transform functions including JSON, date-time functions, array/string/math functions, and even an ability to write Groovy scripts for custom transform logic. It’s also very easy to plug in your own UDF (User Defined Function). See here for more details.
Scheduling and efficiency
In the case of large data sets hosted on the likes of HDFS, S3, Pinot provides a framework known as Segment Build And Push, to ingest data quickly. As the name implies, the build phase generates segments from the input data which are then pushed to the Pinot cluster. Such build and push jobs can be executed on the Pinot Minions at scheduled intervals. Naturally, this frees up the Pinot servers from the overhead of segment creation. Thus, bulk loading of terabytes of data has a negligible impact on the scarce resources in the Pinot cluster and minimizes impact on the critical serving performance.
Unstructured Data
Pinot provides out-of-the-box support for handling unstructured data. For arbitrarily nested JSON data, we can store it as a ‘JSON’ type column and be able to store it in Pinot without the need for complex pre-processing (eg: flattening). In addition, we can specify a JSON index for this column to accelerate nested data structure queries, using the JSON_MATCH function. The JSON index is highly performant and enables users to execute such queries within milliseconds. Similarly, Pinot also provides ease of querying for columns containing large text blobs using the TEXT index which allows users to do term, phrase, prefix, or regex-based text search queries in a fast manner.
Columnar Storage with Flexible Tiering
Pinot is built around a highly optimized and flexible storage layer within each Pinot server. Following are the highlights of Pinot’s storage capabilities.
Columnar Representation
Data within a Pinot segment is organized in a columnar format which helps in reducing the amount of data that needs to be processed and stored in memory. This helps in speeding up analytical queries that focus on a few columns within a high-dimensional dataset. In addition, Pinot employs the following optimization techniques for further reducing in-memory and on-disk overhead:
- Dictionary encoding: By default, each unique value for a given column is assigned a unique ID which in turn is stored as the column value. Thus, for most columns, this leads to a compact representation of all the column values.
- Bit compaction: Bit compression or bit packing allows us to represent a list of numbers using far fewer bits than their original representation. In the case of dictionary encoding, the dictionary IDs can be a bit compressed to further reduce the size of a dictionary encoded column.
- Sorting: One of the columns in a given Pinot table can be sorted and then stored using run-length encoding which drastically reduces the total column size.
Advanced Indexing for High Concurrency Query
Pinot provides a rich set of indexes for accelerating a variety of use cases. Each such index can be defined for any of the columns within the table config. As data is being ingested, Pinot will automatically generate the specified indexes and store them as part of the segment. What’s more, we can also add indexes on the fly to the existing segments. Here’s a quick summary of the indexes available in Pinot.
| Index Type | Description |
|---|---|
| Bloom Filter | Accelerates equality predicates (where col = x) |
| Inverted Index | Accelerates equality predicates (where col = x) |
| Sorted Index | Accelerates equality predicates (where col = x) |
| Range Index | Accelerates range queries (where col > y) |
| JSON index | Accelerates queries on unstructured JSON column data |
| StarTree Index | Pre-aggregates values for a combination of dimensions. Provides extremely low query latency for aggregation queries. |
| Text Index | Accelerates queries on text columns (regex) |
| GeoSpatial Index | Accelerates geo-spatial queries (eg: ST_Distance/ST_Within queries) |
These indexes provide several orders of magnitude improvement in query performance (in some cases query latency goes from 30+ seconds without index to about 50 milliseconds with the index). For more details about each index and its benchmark, please refer to What makes Apache Pinot fast – Chapter 2.
Query and Routing
This layer deals with processing user queries in a highly optimized manner across all the Pinot servers. At the same time, Pinot also provides a way to run highly complex queries (ANSI SQL compliant) for greater flexibility.
Query and Routing Optimizations
Upon receiving a query, it goes through several rounds of optimizations:
Broker level Pruning: Data is usually partitioned across the Pinot servers based on a particular column (time column by default). During query time, Pinot brokers will perform partition-aware query routing – a query with a filter predicate on the partitioned column will intelligently be routed only to the segments which contain that column. This effectively minimizes the number of segments that need to be processed across the cluster, thus lowering the per-query latency and boosting the throughput.
Server level Pruning: When a Pinot server receives a query request from the broker, it will first prune (remove) the segments that don’t need to be processed. This is done by utilizing column metadata such as min/max values and bloom filters. Similar to broker pruning, this reduces the set of segments that need to be processed locally and hence improves overall throughput and query latency.
Filter and aggregation optimizations: Pinot offers a rich set of indexes as described above to speed up filtering and aggregation operations as part of query processing.
Per Segment Query Planning
Although Pinot has a lot of advanced indexing techniques, one of the challenges is to pick the right strategy depending on the query. To achieve this, unlike other DBMS systems that optimize the high-level logical query plan, Pinot utilizes per segment query plan. This allows optimizing query execution for certain scenarios such as predicate matching all the (column) values of a given segment. In other cases, Pinot can generate a query plan that relies solely on the segment metadata for answering things like count, min, or max aggregation without any predicates. This allows segments to have different indexes and physical layouts and still obtain optimum query latency during execution.
Full SQL semantics
Pinot natively supports Calcite SQL with rich semantics including:
- Standard OLAP functionality (filtering, projection, aggregation, group-by, order-by)
- Lookup join using the concept of dimension table
- A rich library of built-in functions and the ability to plugin UDFs
- Approximate or probabilistic query support
- Ability to do text, JSON, geo-spatial queries powered by the built-in indexes
Joins and nested queries
The ability to perform nested queries or joins across multiple tables is available with Pinot’s multi-stage query engine which enables complex analytical operations such as joins, window functions, and set operations across multiple tables.
Conclusion
Thanks to all the above mentioned capabilities, Pinot meets the critical requirements of a highly-performant, scalable real-time analytics database.
| Throughput | Very high. Can easily scale to upwards of 100,000 queries per second. |
| Query Latency | Very low. Typically 100ms p99 for critical use cases |
| Consistency /Accuracy | Tunable. Highly accurate when upserts are enabled. |
| Query Complexity | Moderate for most use cases. Presto/Trino connector is available to support complex use cases albeit at higher latencies. |
Pinot also offers a rich capability to ingest data from various data sources and formats. This allows for easy integration into the existing Data ecosystem.
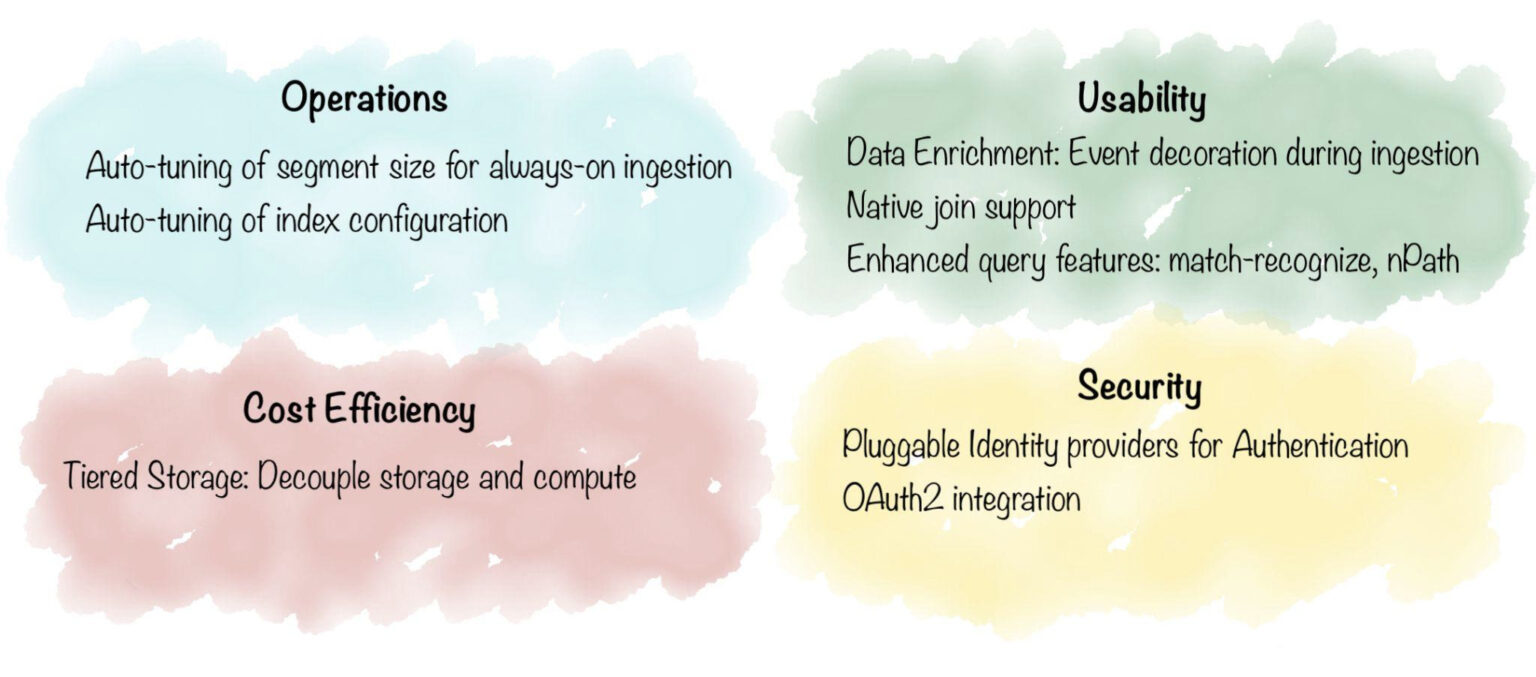
Overall, Apache Pinot is indeed a strong contender for the ideal OLAP platform. In the next phase of Pinot’s evolution, the community plans to add significant improvements as shown in the diagram below. Overall, this will help bridge the gap in query flexibility, support even more use cases, and make it the cheapest and fastest OLAP store to operate in the cloud. Stay tuned!
Try Apache Pinot on StarTree Cloud
The easiest way to get started is with Apache Pinot on StarTree Cloud. Book a Demo or Request a Trial to get started today.
