
Apache Pinot, the real-time distributed OLAP datastore, has announced the release of version 1.3.0, introducing significant enhancements and new features to improve performance, scalability, and user experience.
Key highlights of Apache Pinot 1.3
- Multi-stage query engine enhancements:
- Expression reuse across stages: Optimizes query execution by reusing common expressions across different stages, enhancing efficiency and reducing redundancy.
- Detailed execution plans: Provides comprehensive execution plans for multistage queries, offering deeper insights into query performance and aiding in optimization.
- Introduction of time series query engine:
- A new engine designed for efficient time series data analysis, enabling faster and more accurate insights into temporal data patterns.
- Database query quotas:
- Implements mechanisms to set limits on query rates, ensuring fair resource allocation and preventing system overloads.
- Cursor-based pagination:
- Introduces cursor-based pagination for handling large result sets, allowing seamless navigation through extensive data without performance degradation.
- Multi-stream ingestion:
- Supports ingestion from multiple data streams concurrently, enhancing data integration capabilities and real-time analytics.
- New function support:
- URL functions: Adds functions to parse and manipulate URL data, facilitating more straightforward analysis of web-related datasets.
- GeoJSON functions: Introduces functions to handle GeoJSON data, enabling advanced geospatial analytics and location-based insights.
- Security enhancements:
- Addresses known vulnerabilities, reinforcing the platform’s security and ensuring a more robust environment for data analytics.
- Performance improvements and bug fixes:
- Includes various optimizations and resolutions to known issues, contributing to a more stable and efficient system.
Let’s go through each of these new capabilities in more detail. But also, if you want to hear more about the innovation in the Apache Pinot 1.3.0 release, make sure to sign up for the upcoming webinar on March 6th 2025: Real-Time Observability with Apache Pinot 1.3. (Or, if you’re reading this after that date, check out the video on demand.)

Multi-stage query engine enhancements
Expression reuse across stages
Modern queries may contain multiple joins to the same table such as in the case of the following query:
SELECT *
FROM T1
JOIN T2 as t2first
ON T1.col1 = t2first.col2
JOIN T2 as t2second
ON t2first.col3 = t2second.col3Code language: JavaScript (javascript)Typically, this query is broken into smaller chunks that look like the following tree structure:
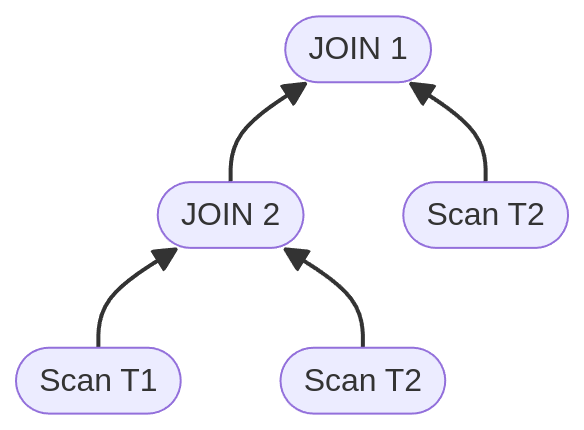
Notice that in the above plan, table T2 will be scanned in two stages.
This feature makes it so that the resulting plan looks more like the following, reusing an expression result like so:
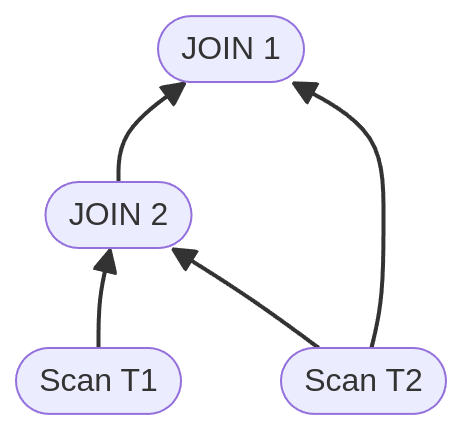
There is a lot more nuance to this, and the details can be found in the related PR here: https://github.com/apache/pinot/pull/14507
Detailed execution plans
In an effort to provide a comprehensive execution plan, a new ExplainedPlanNode is introduced. This node adds physical details related to the query execution, making it easier for users to debug and optimize queries.
Time series query engine
This enhancement addresses limitations in Pinot’s current SQL-based query engines for time-series analysis, providing optimized performance and usability for observability use cases, especially those requiring high-cardinality metrics. Supported domain-specific languages include PROMQL, MQL, and M3QL.
A new API allows for pluggable DSL support via both the Broker and Server endpoints by introducing the AbstractLogicalPlanner and BaseTimeSeriesOperator classes, illustrated by the following diagram:
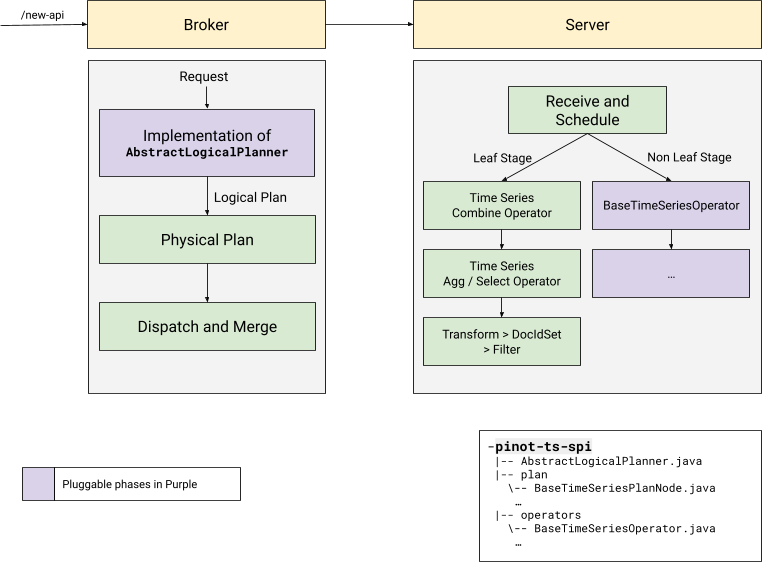
For instance, if a user were to enable the pinot-m3ql plugin, then they will be able to run queries such as the following natively in Pinot:
# Uber inspired example.
# This query plots hourly order count for a given merchant chain in city_id=1. The order count is plotted for each location.
using table:my_restaurant_table_REALTIME value:order_count
| fetch city_id:1 merchant_chain:’e0b35246-864c-4e8a-a64a-392b5ae7306e’
| summarizeBy 1h sum store_name
| transformNull 0Code language: PHP (php)This new engine significantly enhances Pinot’s ability to handle complex time-series analyses efficiently, making it an ideal database for high-cardinality metrics and observability workloads.
To learn more about the new time series query engine, check out the design document here, and the list of related 20 PRs committed to the release here.
Cursor-based pagination
Cursor support will allow Pinot clients to consume query results in smaller chunks. This feature allows clients to work with lesser resources, especially memory. Application logic is simpler with cursors. For example an app UI paginates through results in a table or a graph. Cursor support has been implemented using APIs.
Multi-stream ingestion
Apache Pinot introduces support for ingesting data from multiple sources into a single table, enhancing flexibility and data integration capabilities. This functionality leverages the existing TableConfig interface to define multiple streams seamlessly. By separating the partition ID definition between the data stream and Pinot segments, the implementation ensures compatibility with existing stream partition auto-expansion logic. Importantly, this feature does not alter any existing interfaces, allowing users to define table configurations as before while maintaining compatibility with other transform functions and instance assignment strategies. (Relevant release notes here and design doc here.)
An example of such an ingestion config:
"ingestionConfig": {
"streamIngestionConfig": {
"streamConfigMaps": [
{
"realtime.segment.flush.threshold.rows": "0",
"stream.kafka.decoder.class.name": "xxxxDecoder",
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"realtime.segment.flush.threshold.segment.size": "200MB",
"stream.kafka.broker.list": "<host>:<port>",
"realtime.segment.flush.threshold.time": "7200000",
"stream.kafka.consumer.prop.auto.offset.reset": "largest",
"stream.kafka.topic.name": "topicName1"
},
{
"realtime.segment.flush.threshold.rows": "0",
"stream.kafka.decoder.class.name": "xxxxDecoder",
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"realtime.segment.flush.threshold.segment.size": "200MB",
"stream.kafka.broker.list": "<host>:<port>"",
"realtime.segment.flush.threshold.time": "7200000",
"stream.kafka.consumer.prop.auto.offset.reset": "largest",
"stream.kafka.topic.name": "topicName2"
}
],
"columnMajorSegmentBuilderEnabled": true
},
"transformConfigs": [
{
"columnName": "_ingestionEpochMs",
"transformFunction": "__metadata$recordTimestamp"
}
],
…
}Code language: PHP (php)New function support
This release implements various URL functions to handle various aspects of URL processing, including extraction, encoding/decoding, and manipulation, making them useful for tasks involving URL parsing and modification.
Additionally, several new scalar functions were introduced.
For a detailed list, go the the release notes here: https://docs.pinot.apache.org/basics/releases/1.3.0#url-functions-support-14646
Security enhancements
Recent updates to Apache Pinot include several key enhancements and fixes aimed at improving security, compatibility, and functionality. These updates introduce daily SSL certificate reloads using a scheduled thread, TLS configuration support between brokers and servers in the multi-stage engine, and enhanced TLS support for QueryServer, Dispatch Clients, and Minion. Additional changes include the ability to strip matrix parameters from BasePath checks, disabling environment variable and system property replacements in the table configs REST API, and upgrading dependencies and Hadoop to address vulnerabilities. Furthermore, improved exception handling now returns table names failing authorization for multi-stage engine queries.
These updates reflect Apache Pinot’s commitment to providing a high-performance, real-time analytics platform that meets the evolving needs of its users.
For a detailed overview of the changes and to access the release notes, visit the official release page:https://github.com/apache/pinot/releases/
Check out more great Pinot resources
Want to hear how leading companies are using Apache Pinot for their real-time analytics projects? Register now for Real-Time Analytics Summit 2025 (it’s virtual!). You can also try managed Apache Pinot for free with StarTree Cloud. Get request a trial on a fully-managed serverless environment with StarTree Cloud.