
StarTree recently hosted an online meetup with representatives from across the Apache Pinot open source community to share the current state and direction of the project. Representatives from LinkedIn, Uber, Hubsput, Careem, and, of course, StarTree all shared what they’ve been working on for the past year and provided a glimpse into the roadmap for 2025.
Apache Pinot: One of 2024’s Top 3 Big Data and AI Open Source Projects to Watch!
Since this meetup was held, Apache Pinot was recognized by BigDataWire’s Editor’s Choice Awards as one of 2024’s Top 3 Big Data and AI Open Source Projects to Watch. Congratulations to the community!

Watch the meetup on demand
You can watch the meetup on YouTube, and check out the slides here.
The state of the community
Mayank Shrivastava, one of the members of the Apache Pinot Project Management Committee (PMC), kicked off the meeting going over the state of the community, noting how the Apache Pinot Slack channel reached over 5,000 members earlier in the year, and hundreds more have joined since. The community is vibrant and engaging; over 32,000 messages have been shared this past year over Slack, mostly technical questions and answers.
Users can also stay in touch with each other across the global community, and share their work via the growing list of meetups for Apache Pinot. There are 105 groups across 39 countries around the world. Get in touch if you want to organize your own events. Mayank also invited the community to share how they use Apache Pinot in their organization. “The more we talk about it, the more we discuss, the more the community grows.”
The community also welcomes published blogs and talks submitted to events, such as the upcoming Real-Time Analytics Summit. (Reminder: the Call for Speakers is still open!)

The highest level of engagement is to be a code committer. Apache Pinot welcomes new contributors, and the most-active committers are featured in the growing list of All-Stars. To get involved, check out the contribution guidelines, the open issues (especially the beginner tasks), and read the code of conduct. You can also help improve the documentation.
Over the past year there were over 13 million Docker pulls and the Github repository now has more than 5,500 Github stars. Dozens of developers collectively added over 11,000 commits.

Next up to speak was Yarden Rokach, Community Manager for StarTree. She noted efforts on the Apache Pinot brand, including the redesign for the Apache Pinot website, and the new logo.

To distinguish between the old and new logotype, note first the burgundy color; second, the base of the wine glass is broader; and thirdly, the lowercase “t” in Pinot has a terminal (that curve at the bottom). Make sure to update your blogs, block diagrams, and slides appropriately!
Speaking about blogs, Yarden noted articles about Apache Pinot had 8 million media impressions throughout the year in publications like Forbes, The New Stack, and elsewhere, reflecting growing interest in real-time analytics.
Yarden encouraged the audience to follow the project on the social platform of their choice, whether on X/Twitter or the brand new Bluesky account. (And don’t forget, there’s even a subreddit: r/ApachePinot!)
For the Apache Pinot website, you can check if your company’s logo is already listed on the “Powered by” page. And if it isn’t, make sure you tell us about your Apache Pinot User Story.

User stories: HubSpot and Careem
Speaking of user stories, next up were two speakers from the Apache Pinot open source community: Hubspot’s Ilam Kanniah, and Careem’s Jatin Kumar.
HubSpot

Hubspot is the industry-leading Customer Resource Management (CRM) platform for marketing teams. Customers of Hubspot can use their platform to manage the effectiveness of their marketing campaigns and activities.
Ilam described how Hubspot uses its own internal fork of Apache Pinot, deployed on AWS infrastructure via a custom Kubernetes (K8s) operator. They support a secure multi-tenant deployment using both high performance SSD, as well as affordable HDD in a tiered storage configuration. Hubspot maintains five separate clusters, including one dedicated for experimentation. Ilam described one large Pinot cluster that stores 70 terabytes on disk, capable of maintaining p99 query latencies below half-a-second (480ms) for DISTINCT counts, though other queries are even faster: <100 ms.
Careem

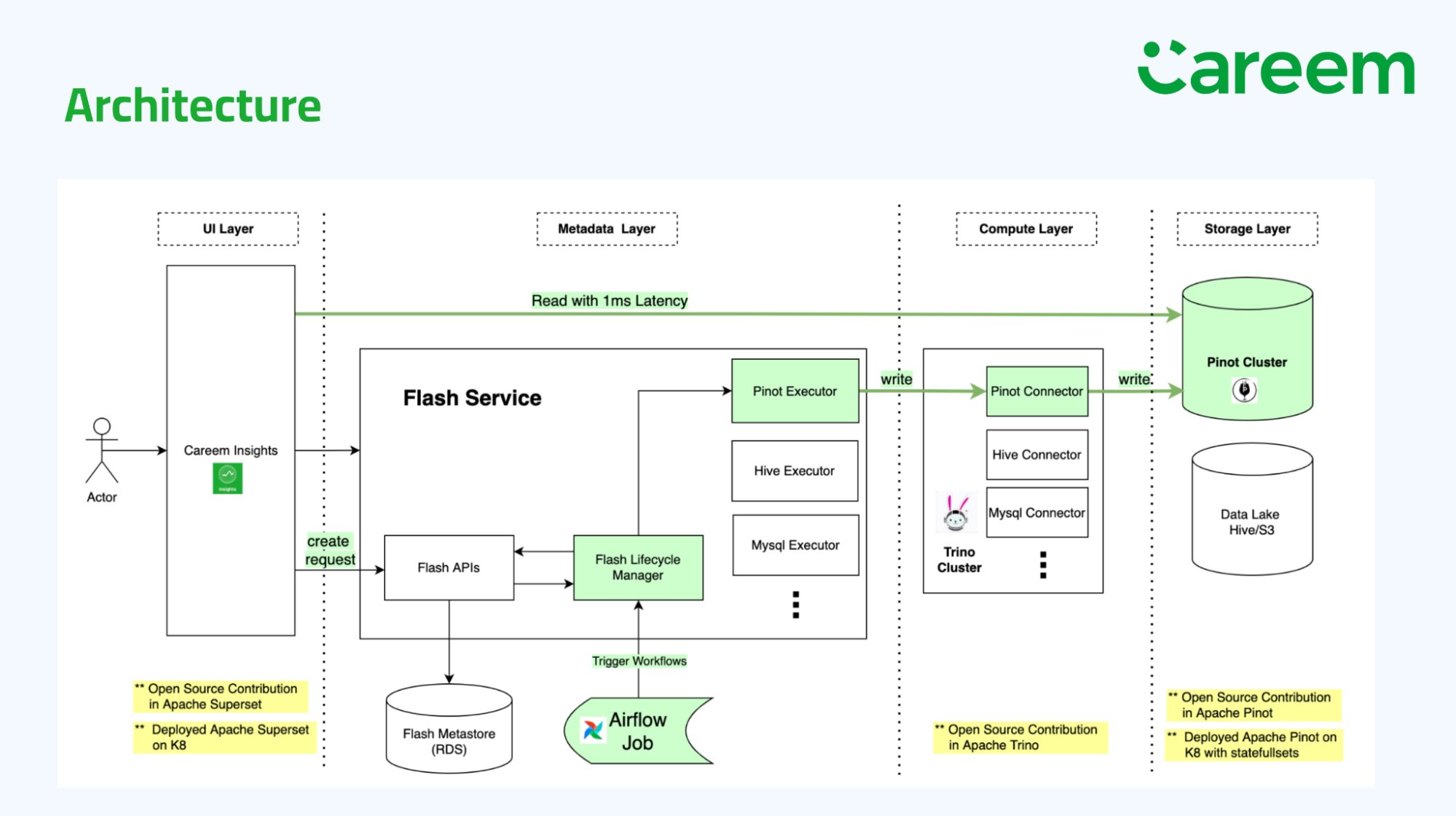
Careem is “the everything app” for users across the U.A.E. and Kuwait. Careem combines functionality of ridesharing, dining, delivery services and payments. Whereas these tend to be separate mobile apps in the United States, in Asia there is a growing market for “super apps” that provide all-in-one experiences.
Jatin’s team used the combination of Apache Pinot and Apache Superset as alternatives to replace Tableau, saying their performance with Apache Pinot now was “super fast” with query latencies as low as 1 ms. Careem is deployed on AWS using Elastic Kubernetes Service (EKS) and statefulsets, as well as ArgoCD. Jatin said he team is next looking to deprecate the use of Apache Druid by migrating that use case to Apache Pinot as well.
Overview of new Pinot features
Next came the overview of Apache Pinot features introduced in the past year, and a glimpse into the capabilities coming in days ahead, divided into the following groupings:
- Query engine
- Multi-stage query engine (MSQE)
- Pinot core
- Real-time ingestion
- Batch ingestion
- Enterprise readiness
Query engine
Null handling
StarTree’s Yash Mayya described how he and StarTree’s Gonzalo Ortiz improved query-time improvements for null handling in the query engine. First, column-based null handling was introduced so that nullability was controlled at the column level not the table level. As Yash said, “This finer granularity is important from a performance perspective, because column nullability affects performance negatively and in many use cases, not all columns of a table need to be nullable.” Column-based null handling is now mandatory for null support in the multi-stage query engine.
Null handling support was also added to most of Pinot’s aggregate functions, and enhancements were added to support null handling in GROUPBY for multivalue (MV) columns.
“We made sure that there is no additional cost for aggregations when query time null handling is enabled, but there are no actual null values in the columns of a segment. With these changes we saw performance improvements of up to 20x on aggregations with null handling enabled (and with actual null values present) by making better use of roaring bitmap APIs.” (See PR#13791.)
Yash finally cautioned that the star-tree Index can’t currently be used when there are actual null values in the columns. “But we’ve made sure to use the fast query execution path wherever there are no actual nulls, even when null handling is enabled. And this is true for aggregations, filters, GROUPBYs. Any part of the query.”

Time series query language support
Uber’s Ankit Sultana was next up to talk about a generic time series engine with a Service Provider Index (SPI) to support various observability dialects: PromQL (used by Prometheus for time series metrics observability) and M3QL (used by Uber’s large-scale metrics database, M3). Ankit noted how Apache Pinot is especially useful for high cardinality metrics (“HiCaM”).
See issue #13760 and the related design document for more details. Uber has already committed code (PR#13855) and is using this capability in production for a critical use case. In due time, more dialects can be added, as well as support for the multi-stage query engine.

Real-time log seach / Lucene optimizations
Text search capabilities are also vital for observability; especially for scanning logs at petabyte scales in real-time. Ting Chen from Uber described the work done to optimize performance on the Apache Lucene search library in Apache Pinot. Ting noted Uber had previously used ClickHouse, but it was hard to operate and had performance issues. Using Apache Pinot they were able to performantly get textual log analytics, aggregation functions, and structured searches. Pinot is now the production logging service for thousands of Uber engineers.
Uber improved the Lucene integration to minimize ingestion latency, query latency, and to improve phrase search capabilities. Ting credited Chris Peck’s work on performance optimization, which you can learn more about in this talk at P99 CONF: Taming Tail Latencies in Apache Pinot with Generational ZGC. They also used Apache Pinot’s capabilities for scanning compressed logs (see Stream ingestion with CLP) as well as its flexible indexing capabilities to avoid brute force processing where possible.
The results of Uber’s efforts were impressive. They were able to improve the log service’s query success rate by an order of magnitude — from <99% to 99.9%. They also reduced the search query latency dramatically by half (yes, the slide says “by more than 100%” but that’s mathematically impossible). Shifting to Apache Pinot saves Uber millions of dollars annually.

Cursors
Cursor support in Apache Pinot (#13185), a long requested feature (#8668), will allow clients to consume smaller query result sets, even as total data in the database grows. StarTree’s Rajat Venkatesh addressed the state of this work. Rajat noted this kind of data slicing (or chunking) allows lower memory overhead for clients and enables more granular management of the data, because the database is responsible for the management of the result set, not the client. It also is the infrastructure needed for pagination support (#5246), allowing users to go forwards and backwards through result sets.
Cursors can be requested when submitting a query, and can use an API to page through the query response. The implementation provides an SPI to define response stores, using PinotFS as the default response store. It could also work with other databases, like key-value stores, file systems or block stores, such as AWS S3.

Memory optimizations
LinkedIn’s Vivek Iyer Vaidyanathan and Dino Occhialini then spoke about work on memory optimization in Apache Pinot. Vivek covered the heap memory optimization, suited for on-heap string and byte dictionaries. “For a couple of use cases at Linkedin we did observe the heap usage was bloating when we used on-heap string and byte dictionaries,” Vivek noted. “Analyzing the heap dump with a tool like JXRay, we were able to find out that this was mostly being contributed by duplicate values across segments in the column.” (You can see the before and after results in the slide below.)
LinkedIn was also seeing Spiky P99 latency issues caused by increased Java Garbage Collection (GC). They solved this using a fixed-array lock-free interning technique that opportunistically deduplicates frequently seen duplicate values across the dictionary, and across segments. The work they did was able to save 12GB of heap memory usage per host and improved P99 query latencies by 35%.
The work they did was covered in an excellent talk presented at the recent P99CONF; watch it online here: Java Heap Memory Optimization to Improve P99 Query Latency at Linkedin Scale.

Dino then talked about the MADVISE support for MmapMemory (see Github issue #12166 and PR#13721). “What we found is that in certain cases, mmap is not useful, and ends up kind of thrashing our page cache a bit.” This feature allows users to set a MADVISE for segment loads. Dino noted, “in the future I think we’ll look to extend this into even smarter type hinting.”
Multi-stage query engine
The multi-stage query engine, also called the v2 engine, was first introduced way back in 2022, and it was central for the support of query-time JOINs in Apache Pinot 1.0 in 2023. More improvements and refinements have since been made in Apache Pinot 1.1.0, and 1.2.0, and innovation continues to this day.
Lookup join support
StarTree’s Xiaotian (Jackie) Jiang described work on this core feature (see #11651, and the related proposal document). For join operations, he noted,“usually the performance is bound by shuffling and by building the lookup table in memory.” The Apache Pinot design has already addressed shuffling by using co-located data. But the limitation there is the join key has to be the primary key, and then the table has to be partitioned before that.
To enable lookup joins with the multi-stage query engine, a new server-side join operator, using a new strategy and a join hint, was added. Using this new capability, join query latencies have been observed to drop from ~30 seconds to 2.5 seconds — a 12x improvement.

Window functions
StarTree’s Yash Mayya presented the window function improvements on behalf of himself and Xiang Fu, which ranged from new features, bug fixes and performance improvements. There was a fundamental refactoring of the processing model from a row-based model to one where data is first partitioned and then processed in batch for efficiency.
Over a dozen new window functions were added for aggregate window, rank-based window, and value-window functions (see the slide below for a full list).
Support was added for custom window frames such as for rows and ranges, following standard SQL semantics. The rows window frames can be used with UNBOUNDED PRECEDING, CURRENT ROW, UNBOUNDED FOLLOWING, or offset PRECEDING and FOLLOWING, while the range window functions can only be used with UNBOUNDED PRECEDING, CURRENT ROW, UNBOUNDED FOLLOWING — i.e., no offsets for range window frames for now (read the docs here). The plan is to add offsets for range window frames in the future.
FIRST_VALUE and LAST_VALUE supports an IGNORE NULLS option, useful for gap-filling missing data. Finally the window cache size was made configurable to protect the server from out-of-memory (OOM) errors.

OOM query termination
Speaking of OOM issues, Rajat Venkatesh from StarTree returned to speak about cluster protection and termination of queries that were taking up too much memory, (part of #13436 overall, and in specific, #13433) often due to badly-written queries. This was already available for the single-stage (v1) engine. With join support on the multi-stage query engine, this was even more vital. Two related debug APIs were also added to help triage incidents.
Two pieces were key to implement this feature: resource accounting of memory and CPU, and query termination. With this accounting in place, query termination works without any modification.

Ease-of-use
Yash also covered Gonazlo Ortiz’ work on ease-of-use for the multi-stage query engine. Three big improvements (and related documentation) were made:
- New query stats
- New explain plan
- Multi-stage operators and their hints
Yash explained, “The new stats give us extremely granular information about things like the execution time for each operator in each stage of a query, the number of rows emitted from each operator, the fan out, the parallelism, the (de)serialization overhead, and so on. The stats collection is extremely efficient, and on by default. They’re extremely valuable to find out bottlenecks in your queries.”
“The new explain plan for the multi-stage query engine is also a game changer for debugging slow queries. It gives segment-level information that you might already be familiar with from the single stage engine’s explain plan alongside the rest of the logical plan from the multistage query engine. This allows you to find out if a query is using the expected indexes that you wanted to use to speed up your query. It was really tricky to debug these sorts of issues where you didn’t quite know whether a query was using an index that you expected or not, whereas now you can see the entire plan for a query, including the segment level information.”

The next two ease-of-use capabilities Yash explained for the multi-stage query engine were no downtime upgrades and co-located joins without hints.
With the 1.2.0 release, guardrails were added to ensure that going forward all releases will be backward compatible, and upgrades can be performed safely without any downtime for queries. As Yash explained, “A major change was to use protos to serialize and deserialize query plans that are sent from brokers to servers via gRPC. Earlier this serialization and deserialization was done via reflection, which is extremely brittle to changes across versions.” On top of this, regression test suites now run against each pull request and automatically sends alerts for any breakage in compatibility.
For co-located joins, Yash noted, “Another big improvement was to allow co-located joins by default when the table partitioning supports it, instead of requiring an explicit hint like earlier. Co-located joins can massively boost performance by eliminating the data shuffling network overhead during joins on tables that are partitioned as well as co-located. Essentially, they are partitioned on the same column and we know for a fact that data with the same key will be on the same server, so we don’t need to shuffle it — we can just join it on the same server locally.”

Performance improvements
Yash continued, “Many performance improvements have been made to the multi stage query engine over the past year. A major one, again contributed by Gonzalo, was to massively improve the data block serialization and deserialization cost (during data shuffle in the MSQE) by reducing the number of allocations and copying done.”
This work involved adding a bunch of new buffer and I/O streams-related code (PR#13304) and resulted in up to 3x speedup and up to 8x less memory allocation during serde [serialization/deserialization] (PR#13303).

On-by-default
There has been a lot of work to bring the multi-stage query engine (v2) into parity with the v1 engine, such as overhauling the UDF registry with Apache Calcite, which incidentally added support for polymorphic scalar functions.
TLS support was also added between brokers and servers.
Migration assistance tools were also added, along with a metric to indicate the number of executed single stage engine queries that would need to be rewritten slightly to work with the multi-stage engine. This allows users to know how much of an effort they need to put in to migrate their existing workloads from the v1 engine to the v2 engine. There’s also a query result comparator API. This was added to run queries and return results from both engines to highlight any differences in results.

Pinot core
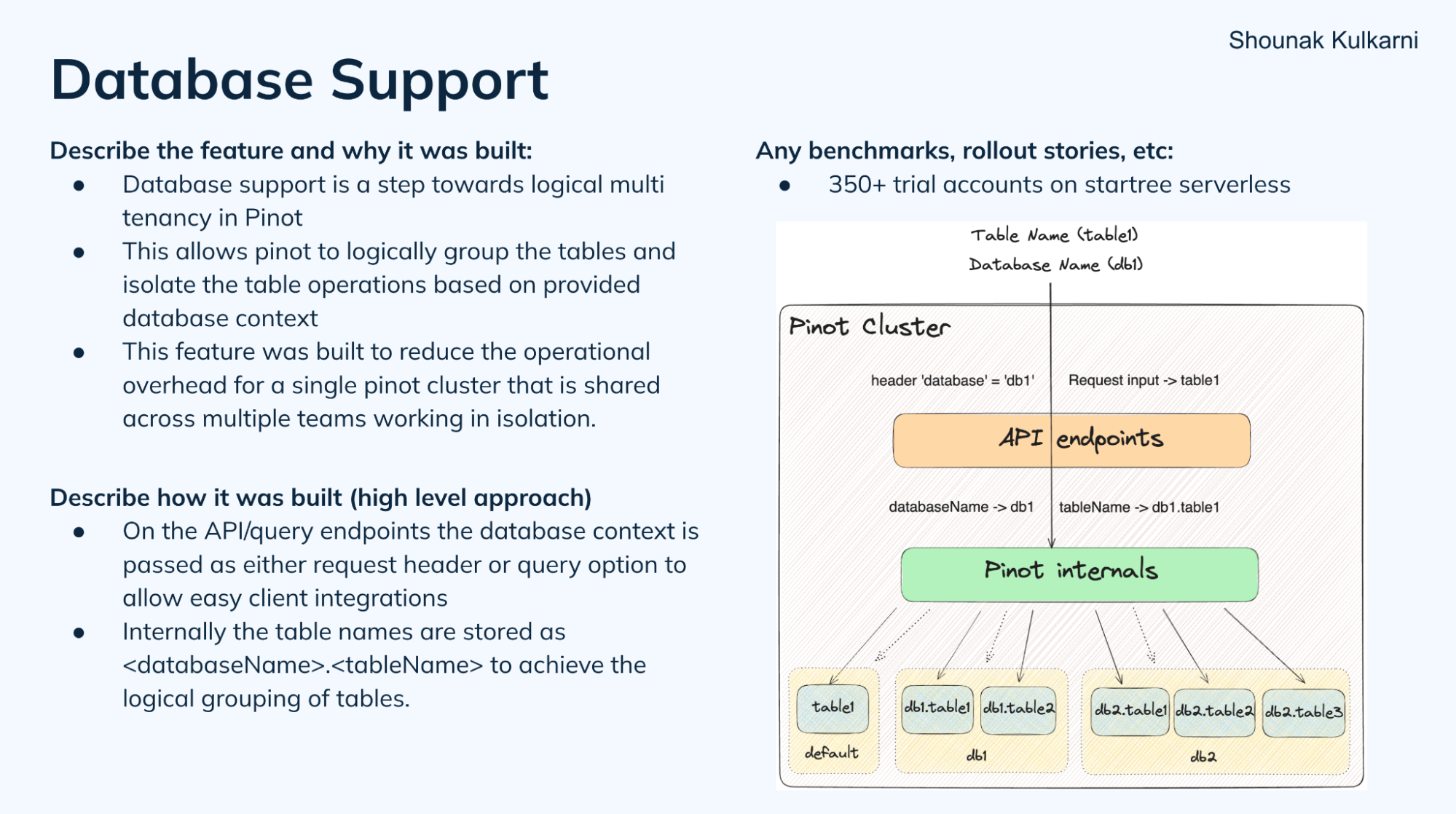
Database support
StarTree’s Shounak Kulkarni described the work he was doing to support logical database concepts (introduced in Apache Pinot 1.2), and why it is required to support isolation correctly for multi-tenancy. This is accomplished by prepending the database prefix to the table name. For example, “db1.table1” is a fully qualified table name, which is passed in the request header.
This can be see on StarTree Cloud, supporting hundreds of Apache Pinot users.
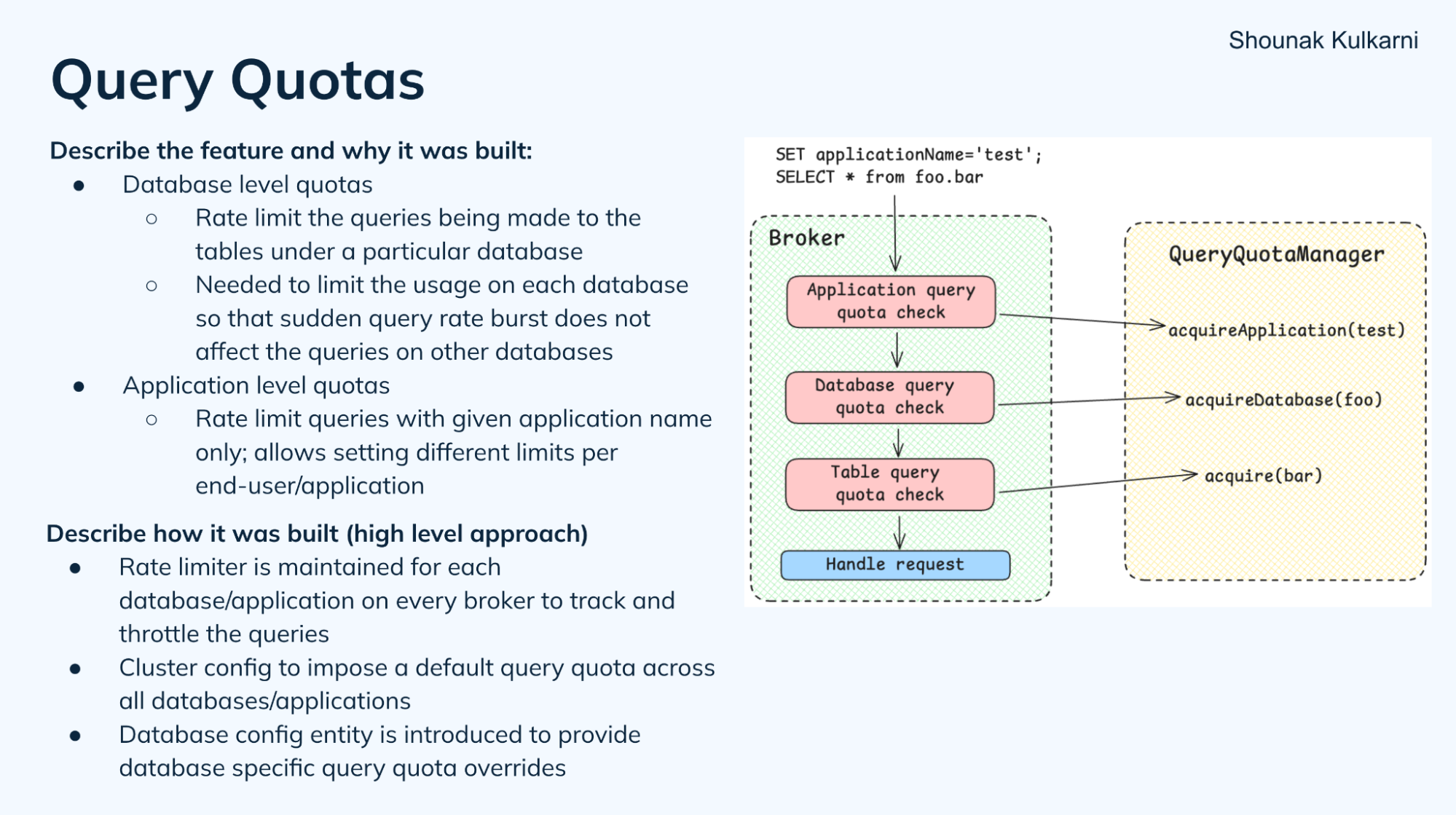
Query quotas
With the introduction of the logical database concept, there are now more query quotas. Prior, there was just a table-level query quota. Now there are database-level query quotas (PR#13544), which apply to all tables in a database. There’s also application-level quotas (PR#14226), to provide separate limits to various applications querying the same database.
Segment isStale API
Rajat then covered the Segment isStale API (#14450, more at PR#14451), which is more of an internal functionality. “Figuring out which segments are stale or have deviated from the table config has been such a bugbear in the past that it’s worth calling out.” The goal of this feature was to identify stale segments in a reusable, reviewable and scalable manner. This allows you to understand the scope of work before kicking off minion tasks like segment refresh. It delegates the work of determining which segments are stale to the servers.

Real-time ingestion
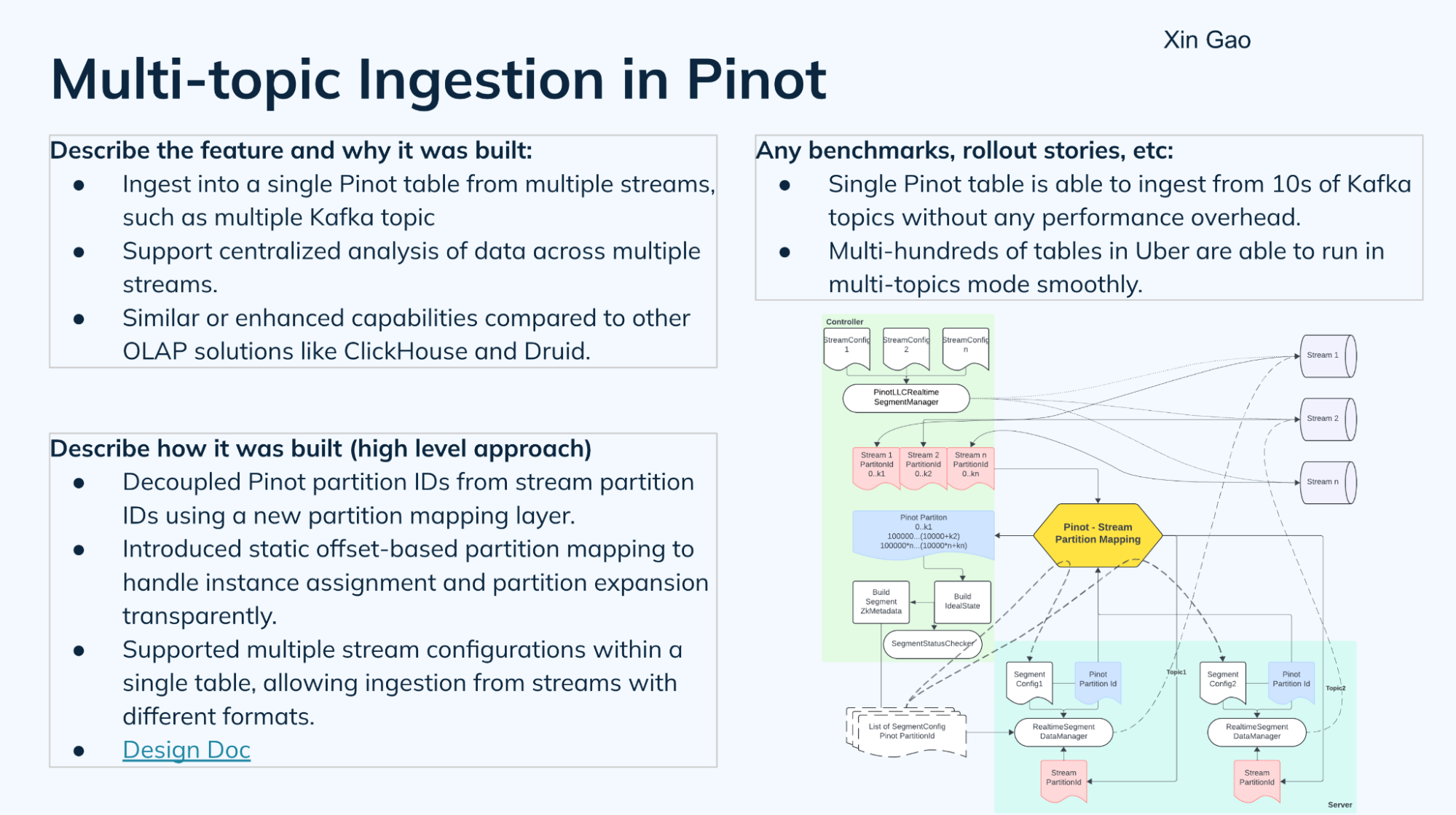
Multi-topic ingestion in Pinot
Xin Gao, a staff engineer at Uber, covered this highly-requested feature to allow a single Pinot table to ingest data from multiple streams, such as Apache Kafka topics. It allows users to centralize analysis and querying across streams that serve similar purposes or have similar characteristics. The core idea behind the design required decoupling the Pinot partition concept from the streams partition concept. There’s now a mapping logic between the Pinot and stream partitions, giving Pinot its own partitioning behavior. Thus, segment names no longer need to match the stream topic partition names. Best of all it handles this seamlessly without impacting ingestion — Uber’s testing showed how a single Pinot table could ingest from 10s of Kafka topics without any performance overhead — nor does it require changes to how you define tables or configure ingestion.
You can read the design document, and also check out Github issue #13780 and PR#13790. Hopefully we will have more documentation and even an in-depth blog in due time.
Support for deduplication
StarTree’s Deepthi (Chaitanya Deepthi Chadalavada) covered work done by herself, Xiaobing Li and Haitao Zhang on metadata Time To Live (TTL) support for deduplication (dedup) (PR#13636). Before this work the dedup metadata map can grow an unbounded number of primary keys. So now with metadataTTL, you can automatically evict old primary keys from the metadata map to relieve memory pressure. Related dedup docs were also updated.

Upsert compaction and deletions
Uber’s Pratik Tibrewal described how the rideshare giant wanted to support around a half-billion upsert deletes per day — adding around 5,000 new keys per second and deleting older keys at the same rate. Uber wanted infinite retention for those tables. This meant they had to delete both metadata and data from disk over time to keep both heap memory usage and storage usage flat. (The prior design in Apache Pinot only deleted the data from query results; the actual data was still on disk, and the metadata table kept growing.)
To address this, a new upsertConfig option was added, deletedKeysTTL. This both removes the primary keys from the metadata map (reducing memory pressure), and also marks the docID as invalid for the latest segment, which will then be deleted after an upsert-compaction task. The design also added a means to ensure data consistency.
You can read more in the blog by Uber Engineering: Enabling Infinite Retention for Upsert Tables in Apache Pinot.

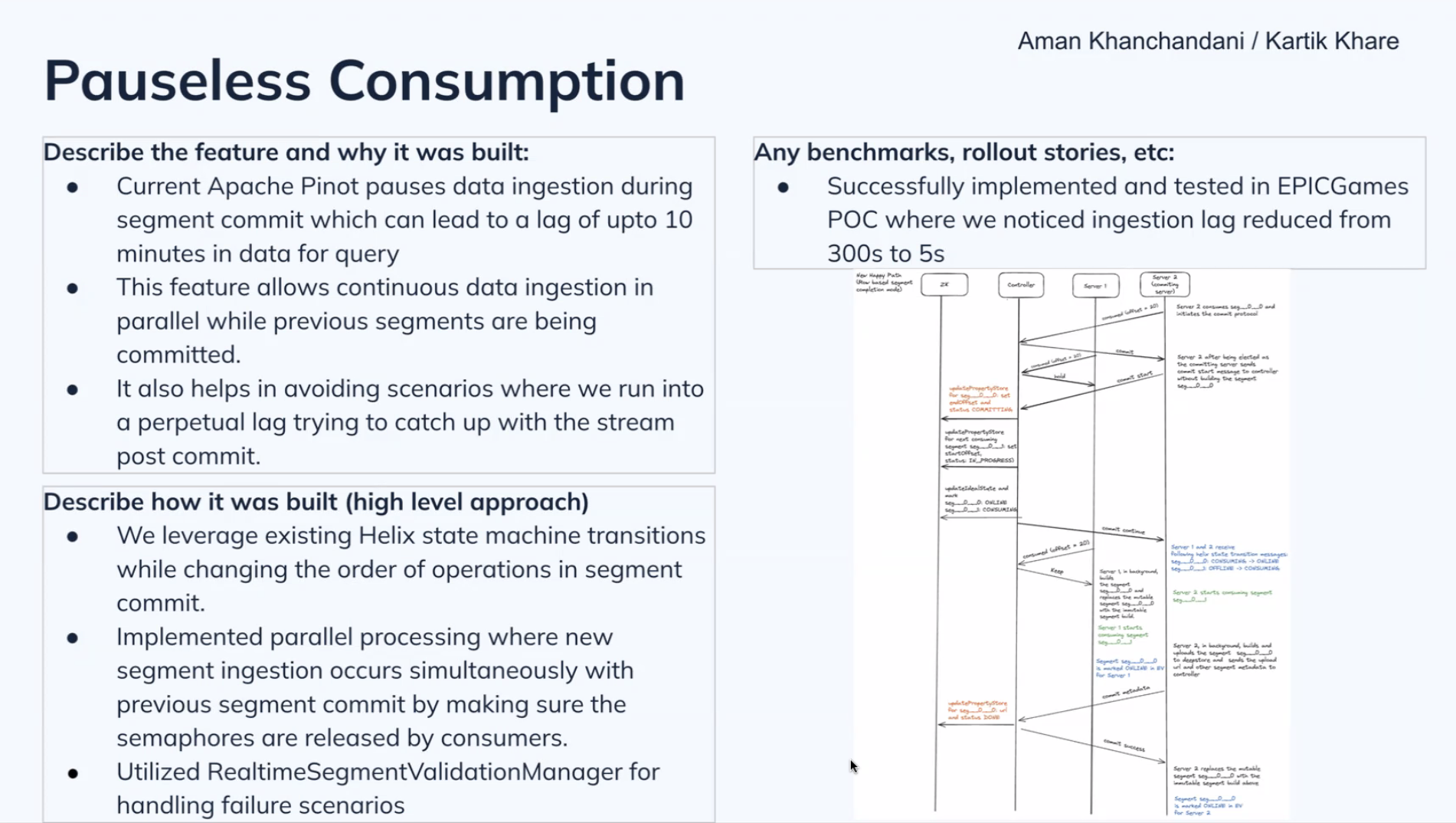
Pauseless consumption
StarTree’s Kartik Khare covered this feature. While Apache Pinot generally ingests data in real-time, during segment commits it can take a few seconds to begin ingestion again. In rare cases of hitting concurrent segment build thresholds, it could even take tens of minutes. Such behavior is unacceptable for many use cases where maintaining data freshness is vital.
The solution was to refactor to allow for continuous ingestion, splitting new segment building (which needs to happen continuously) from segment commits (which take time to write to disk). There also needed to be significant work to deal with various failure conditions. StarTree has already implemented pauseless ingestion in StarTree Cloud and rolled it out into production for its customers. In one case, ingestion lag was reduced from 300 seconds to 5 seconds.
The next level of effort is to provide similar functionality in open source Apache Pinot (#10147).
Upsert backfill
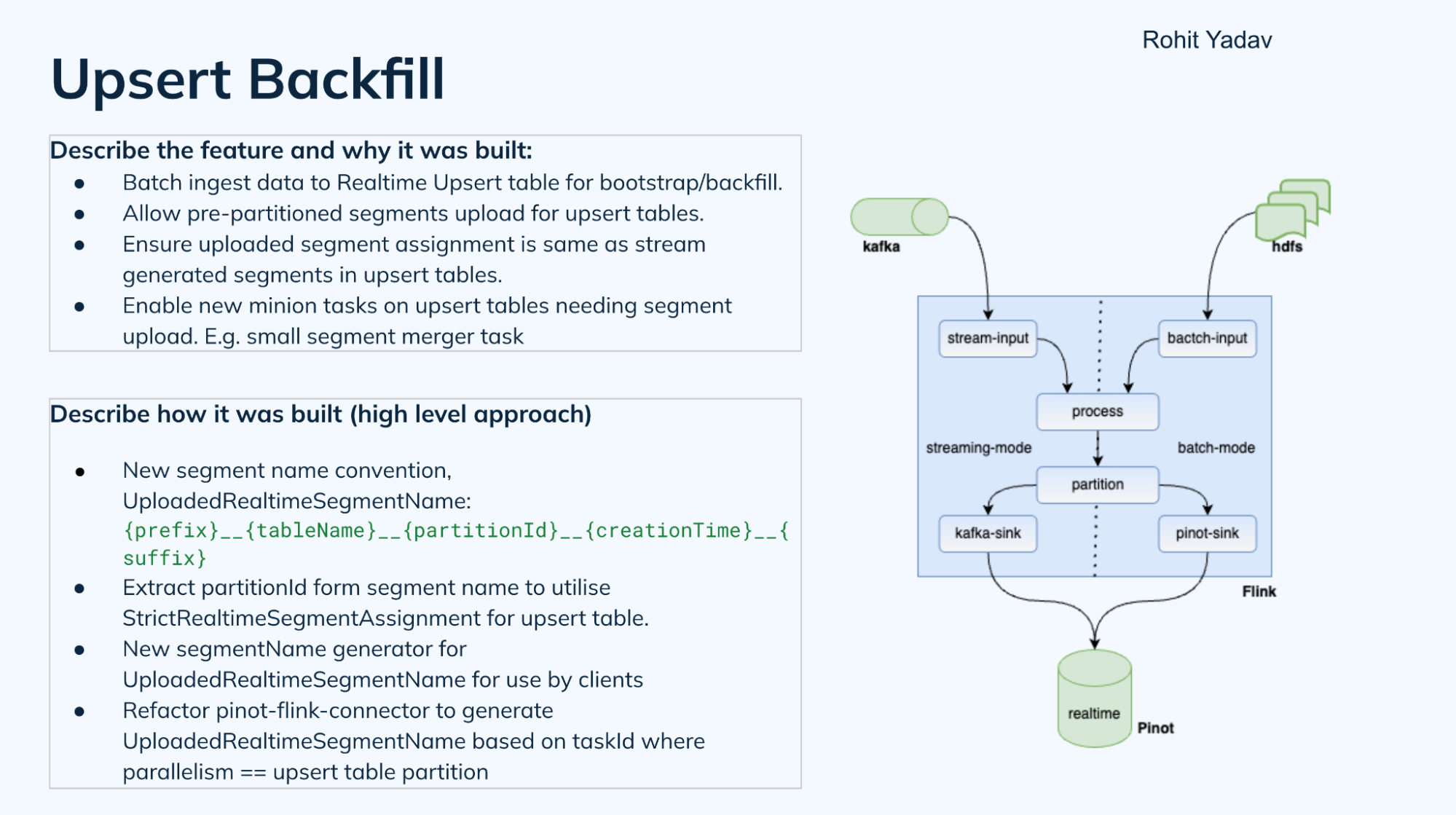
Uber’s Rohit Yadav talked about upsert backfill, a vital capability for disaster recovery. Upserts are a popular feature at Uber, and they often come with a very long retention period — often more than a month. A single table could have more than 50 billion primary keys. So when they tried to backfill simply by replaying a stream, there are basic problems of scale.
While Apache Pinot does have hybrid tables — combinations of offline (batch) and real-time data — they cannot be used for upserts, which are by design for real-time tables. So how do you do “batch” backfill of real-time tables? How do you make it a pre-partitioned stream so data is assigned to the correct segments?
This was accomplished via minion tasks, and also by defining a new naming convention for segments only uploaded to real-time tables in the form of:
UploadedRealtimeSegmentName: {prefix}__{tableName}__{partitionId}__{creationTime}__{suffix}
This allows the segment assigner to know which partitionID data belongs to, and assigns it to the right instances. It also required a segment name generator so that clients can generate segment names and use them in, say, a Flink or Spark job, as well as in the minion task. The Pinot-Flink connector was also refactored to generate these segment names.
Rohit defined how they were doing this as a “Kappa+ architecture,” capable of both batch and streaming. You can follow the discussion on Github issue #12987.
Batch ingestion
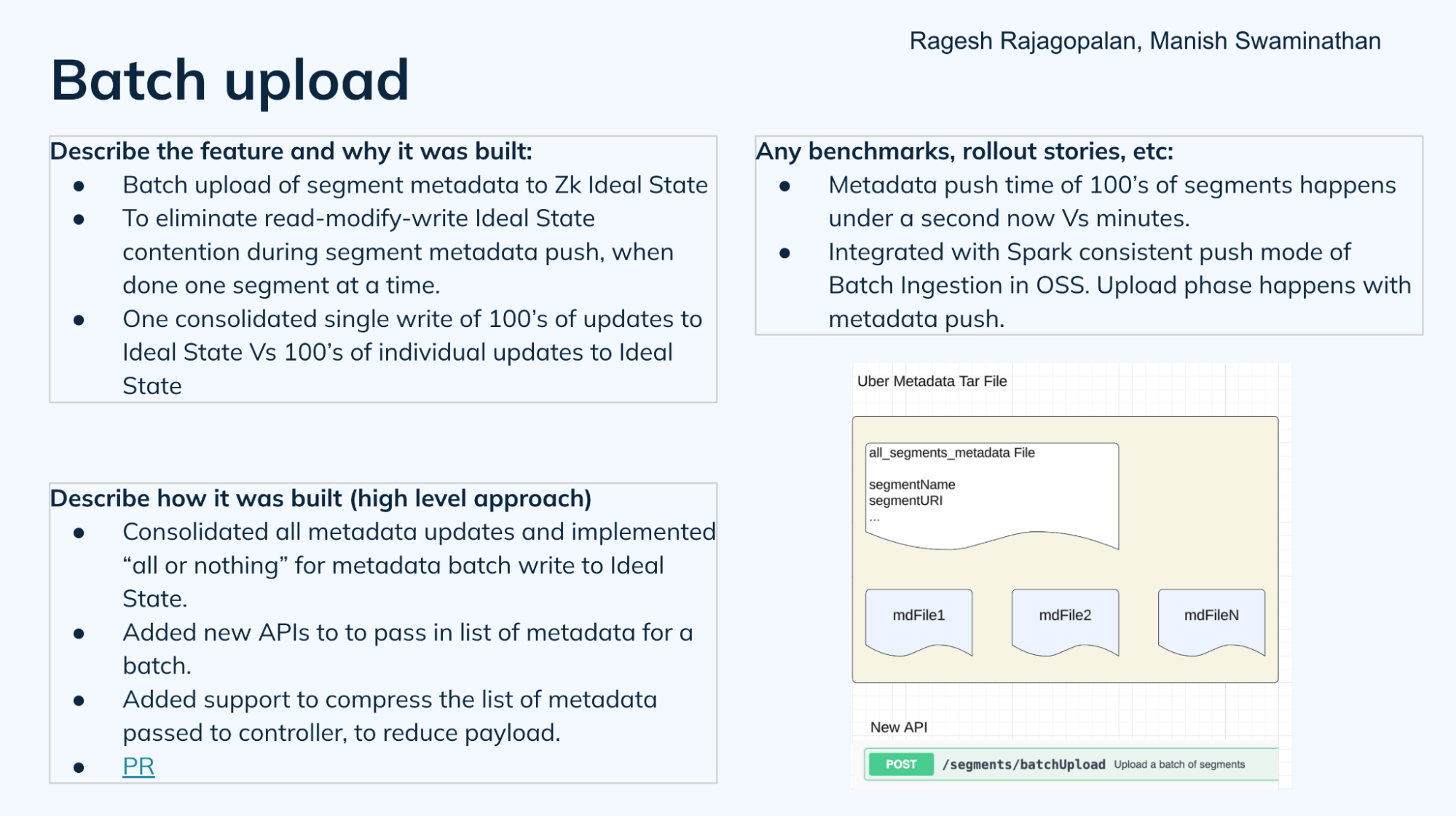
Batch upload
StarTree’s Ragesh Rajagopalan explained how you could use this feature to upload hundreds or thousands of segments into Apache Pinot in one shot. Since Pinot already supported metadata file push, they extended the capability to push up to thousands of metadata files in one shot, reducing all of the individual requests to a single consolidated tar file to specify the ideal state. Before this new implementation, minions might take several minutes in contention to get the necessary lock. The new design can complete the metadata updates in less than a second — even as little as a few milliseconds in some cases.
Automatic segment refresh
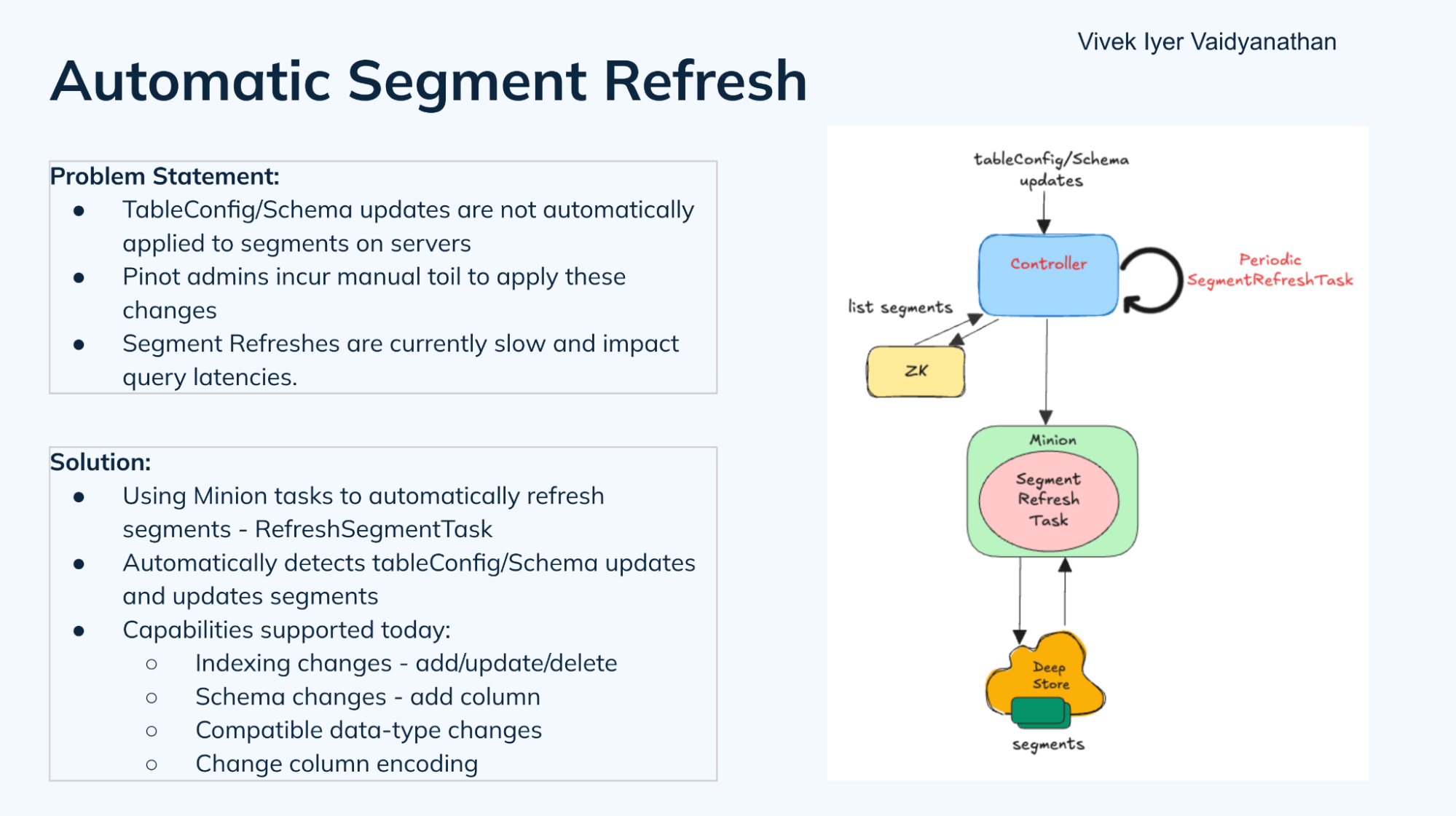
LinkedIn’s Vivek Iyer Vaidyanathan returned to talk about this feature (PR#14300) He described the problem with the prior state: “Whenever there are table config or schema updates, think of it like adding new indexes or removing indexes or adding new columns. These changes are not automatically updated most of the time on the segments and the servers, and they typically either involve calling an API or manually applying these changes. And this has been a source of significant manual toil for us, at least for these large tables that we have at Linkedin.” On top of that, refreshes were extremely slow because they occur on the servers, limiting them to refreshing a few segments at a time to avoid increasing query latencies.
The new design automates and offloads this task as a minion job, kicked off by a periodic controller job that automatically detects changes to table configs and schema. Right now the implementation supports indexing changes, schema changes like adding a new column, column encoding, and data type changes. In the future the goal is to support more capabilities like repartitioning.
Enterprise readiness
Graviton support
StarTree’s Prashant Pandey described the work to make Apache Pinot compatible with AWS Graviton processors, powered by ARM chips. These processors are designed to provide equivalent performance at a lower power consumption to x86 CPUs, and thus, a lower per-hour instance cost. The level of effort required ensuring ARM64 feature and performance parity with AMD64. Maven builds profiles were added for osx-aarch64 and linux-aarch64.
Benchmarking on r7g vs. r6a instances showed Graviton was ~5% cheaper for ingestion and ~7-20% cheaper for querying compared to x86. As Prashant summarized “With this native support added. We can basically run Pinot on an ARM64 machine without any changes.”

Monitoring improvements
Prashant also covered these updates (PR#14348). Testing Pinot metrics used to be extremely manual and brittle. Adding new JMX metrics required changing the Prometheus Exporter regular expressions (regexps) configs, which could be risky. There was also significant config file bloat when users added alerts.
To remove some of the fragility last quarter a comprehensive test framework was implemented to test metrics without setting up the entire monitoring stack, allowing testing the new metrics and ensuring it exported correctly. Changes to existing metrics were detected automatically because they would result in immediate test failures.
The testing even discovered a number of redundant regular expressions, resulting in smaller config files, which resulted in a 33% reduction of memory required for the compiled expressions.
Lastly, in the roadmap Prashant mentioned the intention to migrate from Yammer to Dropwizard, which should be fairly easy now.

BinaryWorkloadScheduler
Vivek returned for the last feature of the day, talking about BinaryWorkloadScheduler, which is an initial form of workload isolation implementation. Table owners want to run some queries at higher or lower priorities depending on Service Level Agreements (SLAs). Ideally higher priority queries should not be impacted by lower priority queries.
In this initial implementation, primary queries are executed using the default unbounded First Come First Serve (FCFS) scheduler. The secondary queries go through constrained processing, where there is a limited number of runner and worker threads assigned to it, and are queued for staggered execution. This allows primary queries to end up using the entire CPU if they require, while secondary queries have an upper cap in terms of the CPU, which limits the effect they have on primary query latencies.
This feature is already used in production at LinkedIn and Activision, and serves as a foundation for a more generalized capability for query resource isolation in Pinot (read more here: #14551).

Thank you to all of the contributors!
Our great thanks to the dozens of human committers to Apache Pinot who made nearly a 1,000 commits in total. (Sorry, we’re not counting you, dependabot!) You’ve truly made 2024 a remarkable year in Apache Pinot’s history.
Getting committed
If you’d like to be part of the community of committers, the first step is to join the Apache Pinot Slack and introduce yourself, so you can get your questions answered from the more than 5,000 community members already congregating there. Then make sure to give a star to the Github project apache/pinot while you check out the contribution guidelines.
