
At Real-Time Analytics Summit 2024, the Apache Pinot and real-time analytics communities gathered to discuss the latest innovations and share user stories and best practices. In his opening keynote, StarTree’s CEO and co-founder Kishore Gopalakrishna spoke about the current state of the industry, the latest advancements in Apache Pinot, and new pricing and functionality for StarTree Cloud.
Kishore’s message: Stay ahead or be left behind
Kishore’s keynote was dedicated to the skeptics of real-time analytics — those who have found issues turning their data into insights in seconds or milliseconds. In the past, people questioned the need to move to real-time systems. Storage costs were prohibitive, so only critical events were even logged. Query costs were also high. Moreover, creating end-to-end solutions was complex.

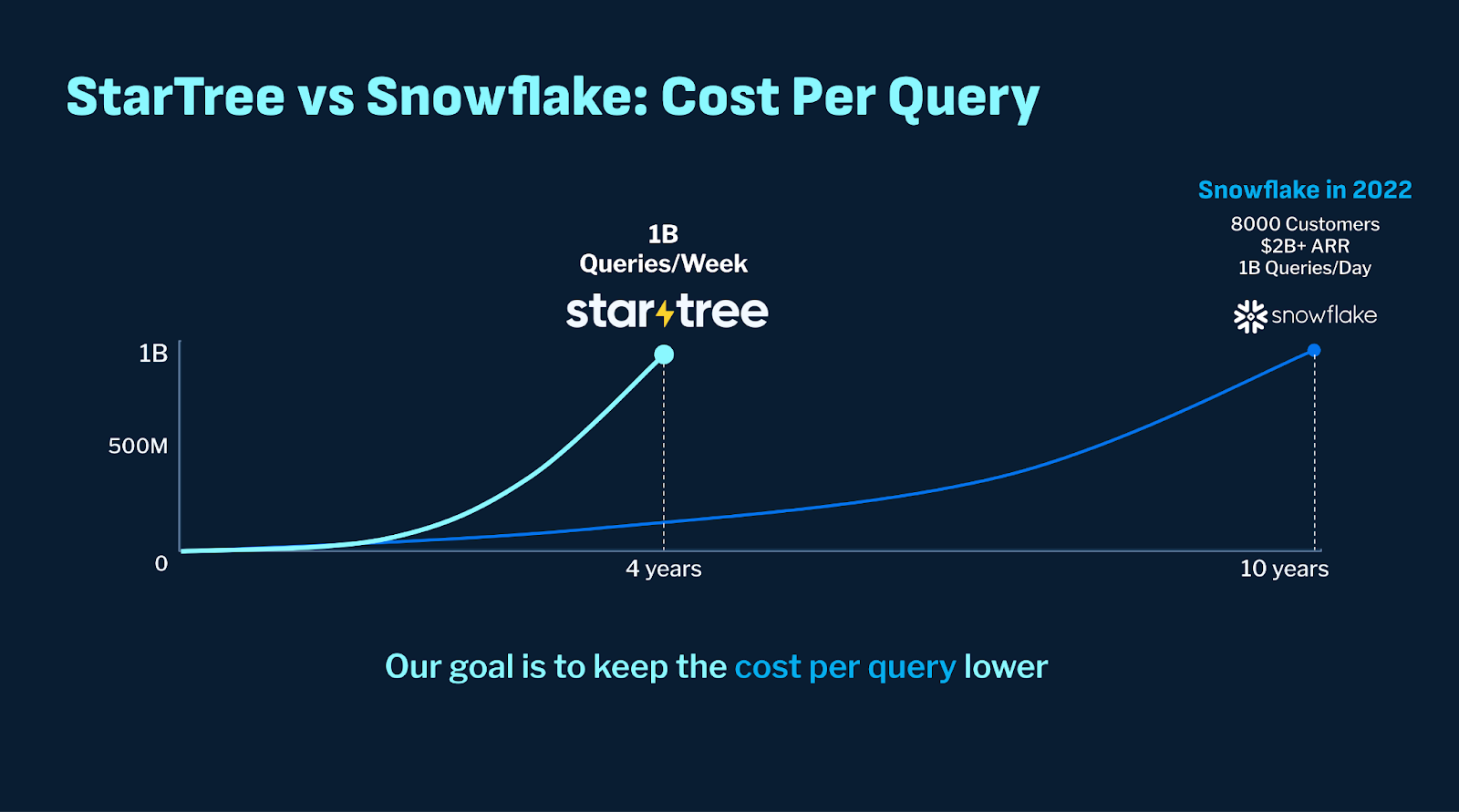
The state of real-time data is different in 2024. Kishore observed how StarTree is now, after four years of operations, serving 1 billion queries per week. It took Snowflake 10 years to reach 1 billion queries per day. Given the scale of StarTree versus Snowflake (which is currently at $2.8 billion annual revenue), Kishore suggested the audience do the math and consider that StarTree, powered by Apache Pinot, can serve this same scale of queries at a far more affordable rate.
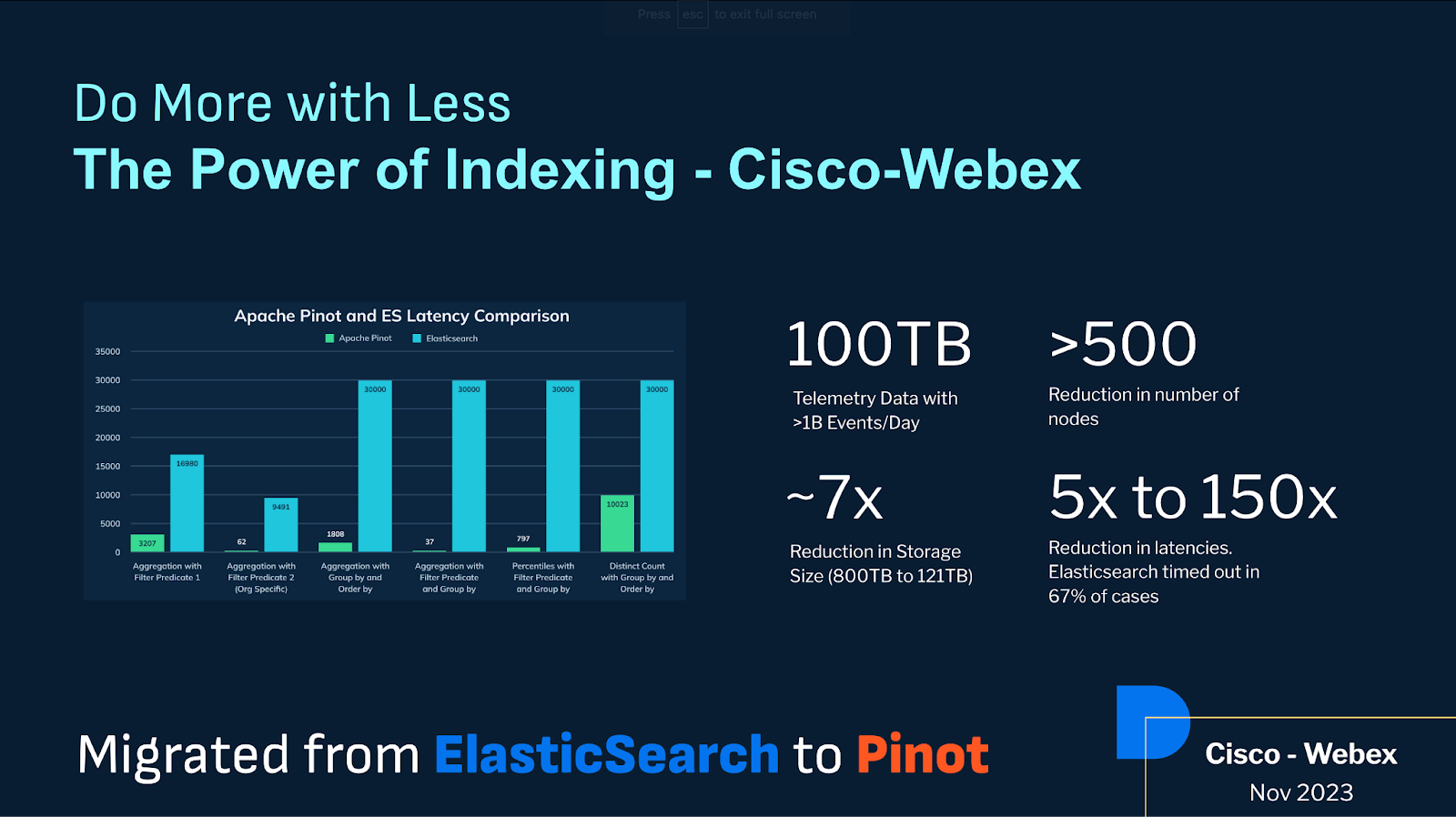
Kishore noted success stories, such as how Uber migrated from Elasticsearch to Apache Pinot, saving $2 million in annual infrastructure costs for one use case alone. Uniqode (formerly Beaconstac) likewise saw a massive reduction in infrastructure while improving latencies by 20x. Cisco WebEx was able to reduce their required storage by 7x — going from over 800 terabytes storage to only 121 terabytes, while reducing their long-tail latencies between 5x to 150x. These results are all due to the indexing and storage efficiencies of Apache Pinot.
So while “real-time” used to mean more expensive and more complex, that is no longer the case. In fact, Kishore posited the opposite — that not doing real-time in 2024 is expensive.
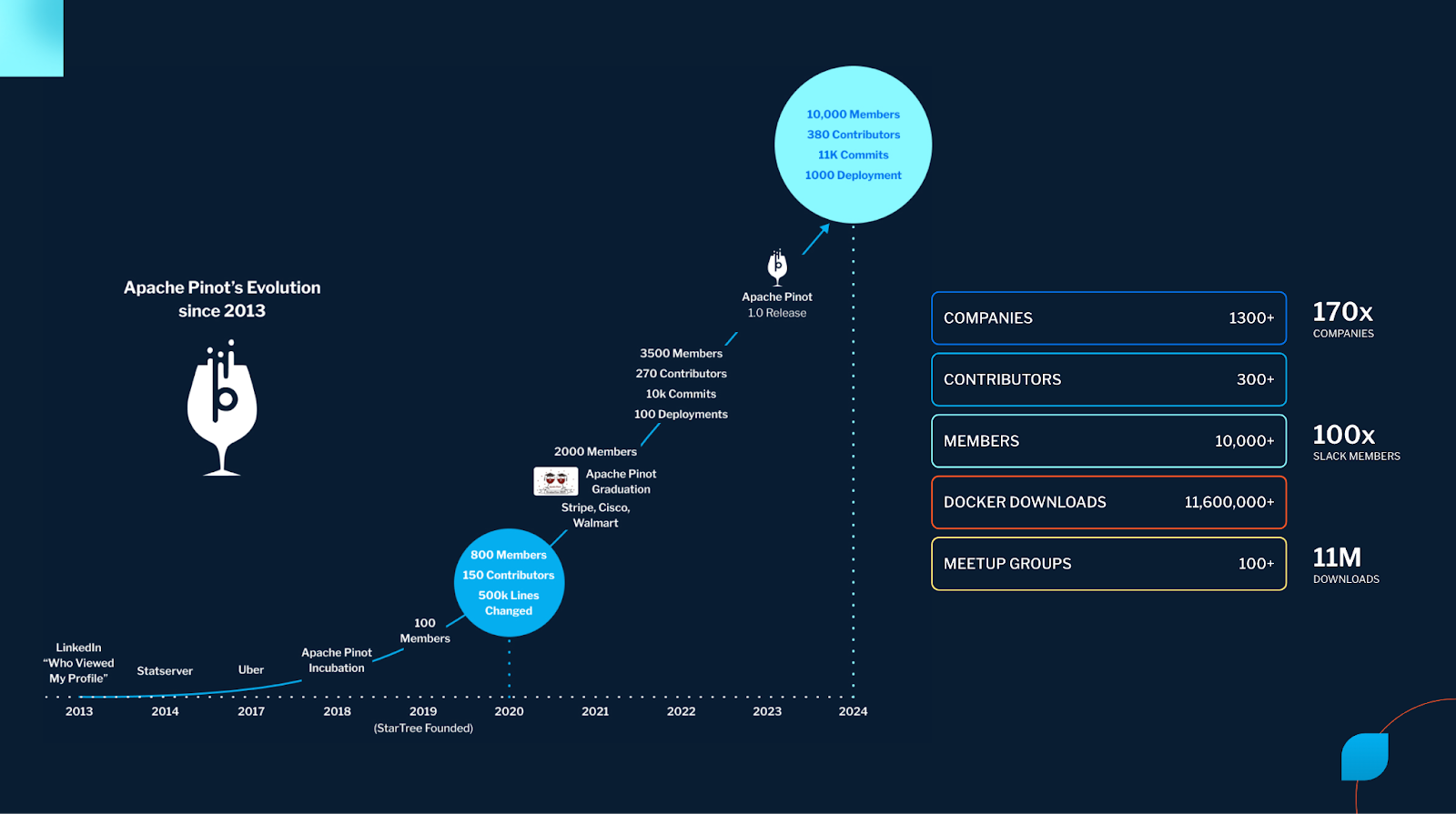
Kishore cited the momentum behind the rapidly growing community. There are now 1,300+ companies powered by Apache Pinot. Over 300 committers to the open source project, 10,000 members of the community Slack ( you can join too! ) and a hundred global meetup groups. There have been over 11,000,000 Docker downloads to date.
Enhanced capabilities in Apache Pinot
Kishore also covered how the Apache Pinot community is continuing to deliver exciting new features, functions, and capabilities for organizations to build new generations of applications. Efforts here focused around improved performance, innovation, ease of use, and compatibility.
Multi-stage query engine performance
One key driver of recent adoption has been the ability for Apache Pinot to do query-time JOINs, enabled by the Multi-Stage Query Engine released in Apache Pinot 1.0. Prior to this, you had to compromise on flexibility by denormalizing all data before you brought it into Pinot. Now data can retain a normalized star schema. There is no need to delay ingestion to denormalize all tables. Since initial release, there have been ongoing improvements in the JOIN algorithm itself. According to Kishore, “Now you don’t have to compromise on the performance because we are actually leveraging the indexes in JOINs, which is very different from traditional databases.”
Vector indexing: GenAI support in Apache Pinot
With Apache Pinot 1.1.0, vector indexing is now supported in StarTree Cloud. “Indexes are a first class citizen in Pinot,” Kishore noted. “So adding another index is not really hard for us. We already added HNSW [Hierarchical Navigable Small Worlds]. We’re going to keep adding more and more indexes as we learn.” Apache Pinot is working to adhere to Postgres syntax overall, so vector indexes in Pinot will follow pgvector syntax.
Additional improvements
This led Kishore to talk about the broader initiative to bring Apache Pinot into Postgres wire protocol compatibility. “This is the most-asked feature in the community.” It is in line with making Pinot easier to adopt. This will ensure that all the clients and all the tools that are already compliant with Postgres will be seamlessly compatible with Pinot. All your visualization tools. All your JDBC drivers. Likewise, Apache Pinot is working towards ensuring it is fully ANSI SQL compliant, to add windowing functions, lateral JOINs, and so on.
There is also ongoing work on storage and indexing optimizations, and better workload resource isolation. For example, multitenancy, serving many use cases in a single cluster. “This is already possible, but we are going to make it better and easier.”
StarTree Innovations
Kishore also covered innovations unique to the StarTree Cloud platform itself.
Expanding Ecosystem of Integrations
Kishore began by noting that “in today’s world, it’s not just one system that can solve all your problems. You have to work very well with the entire ecosystem.” Historically Pinot began at LinkedIn by just integrating with Apache Kafka, Avro, and Hadoop. Fast forward to today, you have all these systems very well integrated. “You don’t have to write a single line of code to get the data into StarTree Cloud from any of these systems.” Data Manager allows you to point at any of these sources and data immediately starts synching in. All of this already existed, but look forward to the announcement of new integrations in coming months.
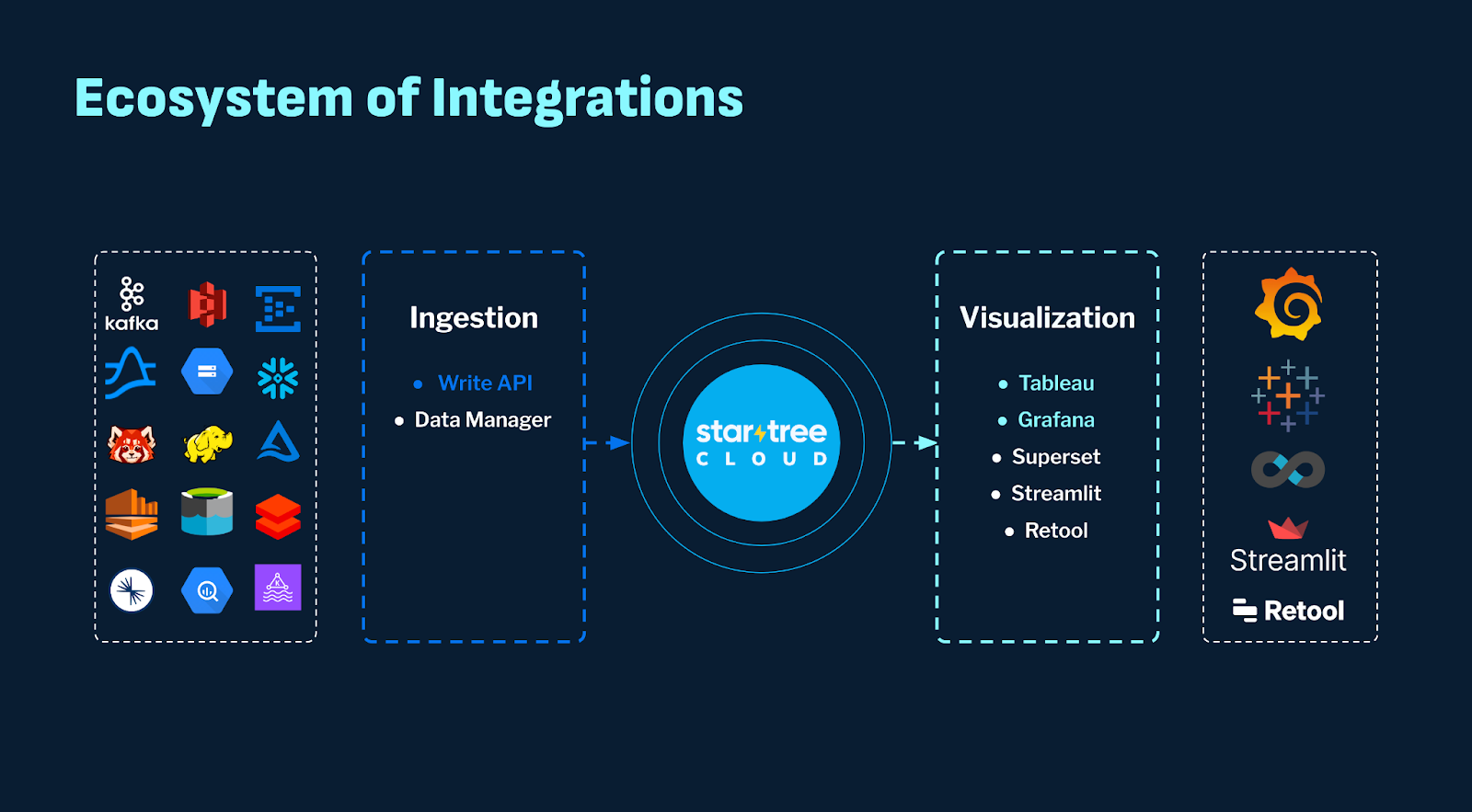
Write API
New and unique for 2024 is the Write API. Whereas Data Manager is more of a “pull” or polling update model, the Write API is more of a “push” model. This new feature, currently in private preview, will allow developers to utilize a JDBC driver to insert data directly into StarTree Cloud.
New visualization support
Apache Pinot has supported Apache Superset, Streamlit, and Retool integration for visualization. Now, StarTree supports integration with Tableau for business Intelligence (BI) (immediately available) and Grafana for observability.
Serverless deployment, and more pricing options
StarTree has supported multiple deployment models for a while, such as BYOC vs Dedicated SaaS. StarTree Cloud now offers a trial, powered by the new StarTree Serverless architecture.
“You can get started today. You get a workspace and it automatically scales behind the scenes. You don’t have to worry as you add more workload. You don’t need to think about capacity planning. The best part is you get better performance, because you have a larger pool of nodes serving your workload.”
Get started quickly. Easy to scale. Better performance. And best of all, free to use for as long as you like. What’s not to love?
Here’s StarTree’s head of Developer Relations, Viktor Gamov, to further introduce you to StarTree’s Trial Service:
Users can easily and transparently move from StarTree’s trial which is designed for learning, developing, and prototyping, to these production-ready clusters.
Cloud-native storage
Apache Pinot can support two different classes of tiered storage: locally attached storage, such as dedicated local NVMe SSD, and block storage. StarTree expands that tiered storage model by supporting object stores, such as Amazon S3, Google Cloud Storage, and Azure Blob Storage. The data can be stored directly on these object stores, and StarTree uses the native APIs to access it. This further reduces costs to serve. StarTree has invested a great deal of engineering into this effort, resulting in high performance on object stores — achieving sub-second latencies.
Observability
Another capability Kishore admitted he’s super excited about is the support of observability in StarTree Cloud. This feature is available in private preview. While attendees could get a demo at the StarTree booth at Real-Time Analytics Summit, if you want to see this for yourself, you’ll want to schedule a demo with our team.
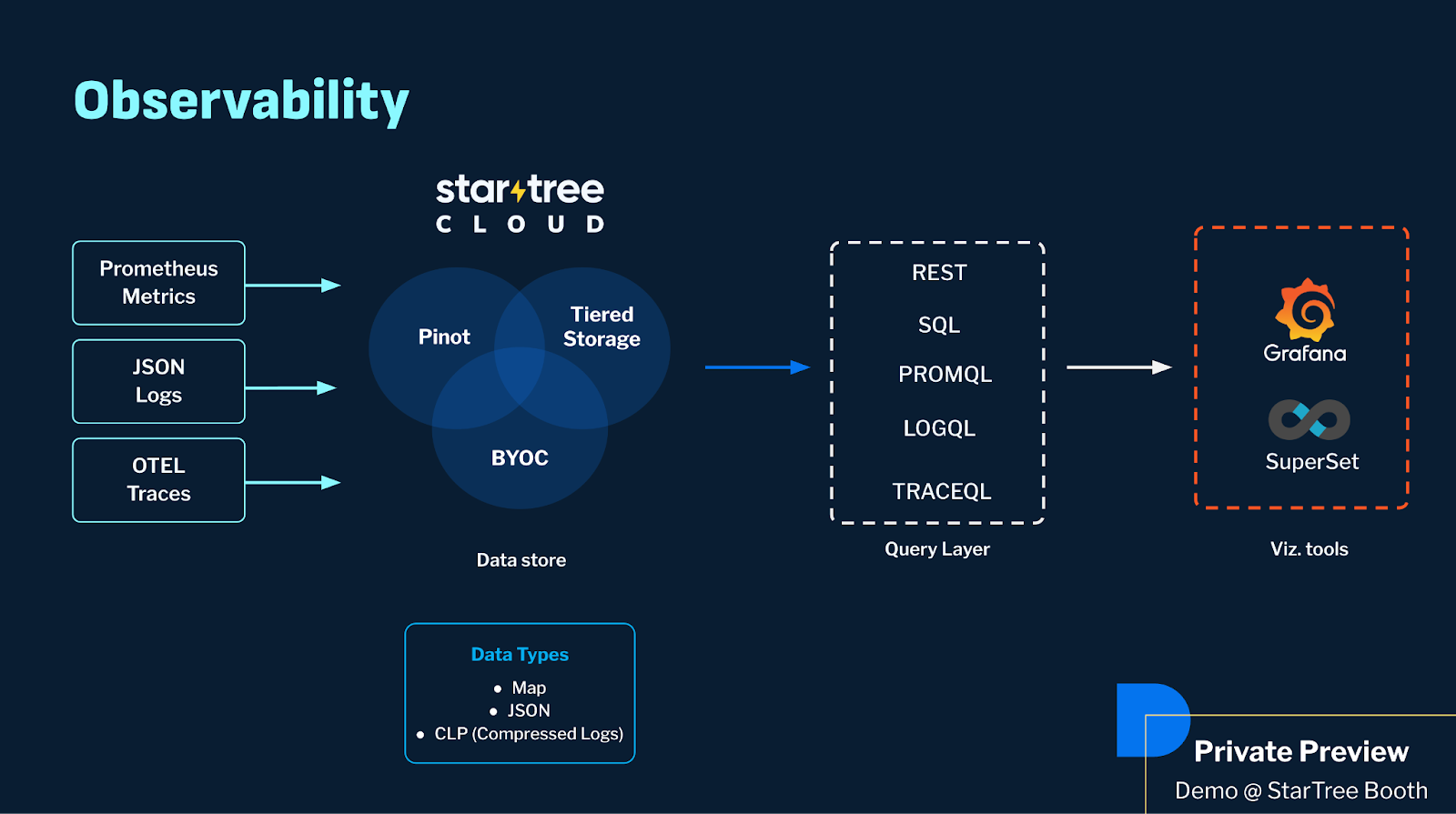
This new capability allows StarTree Cloud to ingest metrics, logs, and traces. “Now you can ingest your Prometheus metrics, JSON logs, and your OTEL traces into Pinot.” There are also new data types in Apache Pinot, like map, JSON, and Compressed Log Processor (CLP). Kishore took a moment to thank Uber for this latter contribution to the open source. “You can save an amazing amount of compression on your logs. Almost close to 150x.” For the maps and JSON, “we automatically infer the schema. We separate out what are the dense columns, what are the sparse columns, and we have efficient storage there.”
For the consumption side, StarTree Cloud has added PromQL, LogQL, and TraceQL for integration with industry-standard tools like Grafana and Apache Superset. “This allows you to connect with other tools that you are already familiar with. You can get going off the bat very quickly.”
StarTree ThirdEye general availability (GA)
StarTree ThirdEye is a flagship anomaly detection and Root Cause Analysis (RCA) suite of tools that runs on top of StarTree Cloud. It is now generally available. DoorDash spoke at the Summit about their use of ThirdEye for real-time detection of API failures for third-party developers.
Watch Kishore’s keynote in full:
Check out RTA Summit sessions on-demand
Check out our full recap of Real-Time Analytics Summit 2024 for more. All RTA Summit session videos are now available on YouTube. In coming weeks, we’ll also have more deep-dive blogs on some of the amazing talks held over the course of the event.