Elevate Apache Pinot with StarTree
Support from the creators of Apache Pinot
Our team work hands-on with yours – from onboarding through production, helping with everything from data modeling and pipeline integration to query optimization and system tuning. Whether you need help scaling a critical dashboard, configuring ingestion from Kafka, or navigating schema design, you’ll have direct access to the same experts who helped companies like Stripe, Cisco, and DoorDash build their Pinot-based systems.

Fully managed, with flexible deployment options
SaaS
Get started quickly with the fully managed, StarTree Cloud service. Ideal for organizations that want zero ops overhead and rapid time-to-value.
Setup is simple, leaving you to focus on your data, your schema, and queries. And your SaaS instance is isolated from noisy neighbors at the infrastructure level.

BYOC
For customers who prefer dedicated infrastructure and deeper integration with enterprise systems, we offer a Bring Your Own Cloud (BYOC) model with VPC peering, custom SLAs, and enhanced observability.
In this case, the entire software stack is deployed in your cloud account and data never leaves your governance boundary
BYOK
For highly regulated environments, StarTree can be deployed behind your firewall—offering full control while still leveraging the power and capabilities of StarTree Cloud.
With this model you can deploy the entire stack in an existing Kubernetes cluster. This can be done in a given cloud provider (eg: Amazon EKS) or in a self-managed Kubernetes cluster on baremetal.
StarTree enhances Apache Pinot with features that make it more powerful while lowering costs.
Interactive queries on the data lake
StarTree’s “Precision Fetch” leverage Pinot’s indexing capabilities for fast, interactive queries on data stored in Pinot (or Iceberg) on cloud object storage. This capability is highly performant as it is able to fetch only the data needed for the query.
Precise fetch makes it possible to store historical data more affordably – while maintaining interactive query response times.
Upserts that scale
Upserts in open-source Apache Pinot are limited by the memory overhead needed to handle the primary key map. This puts a limit on how far you can push upsert functionalities.
StarTree Cloud has addressed this limitation to allow updates to billions of primary keys per server—without compromising speed or concurrency. This makes real-time, mutable datasets possible at scale.

Data management made simpler and more flexible.
Automate operations on StarTree Cloud
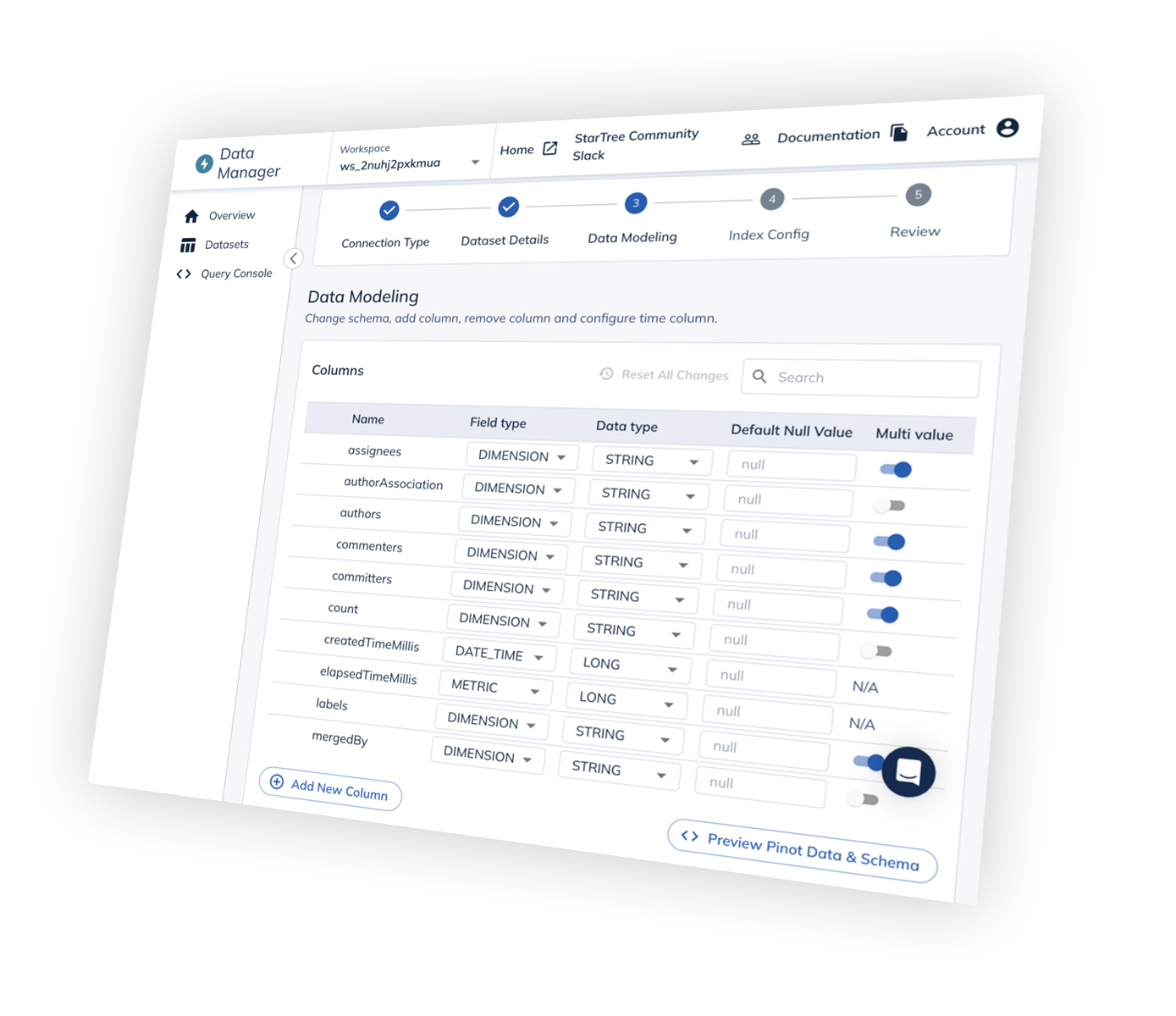
Performance Manager
Schema Evolution
Data Backfill
Dynamic Autoscaling
StarTree enables you to dynamically scale and optimize resources with Minion Autoscaling to avoid paying for idle infrastructure while maintaining performance under load.
Role Based Access Control
Improved Query Console
Ready for AI and modern workloads
Query data in Iceberg
Query external tables directly. StarTree can now serve low-latency and high concurrency analytics from the data lake, and without moving data or stitching together more pipelines.
MCP Server for Apache Pinot
MCP provides a standardized interface for AI models to interact with your data. StarTree’s MCP Server enables AI applictions to get instantaneous responses to queries on rapidly changing data – critical for maintaining AI agent context and fluid interactions
Vector auto-embedding for building real-time RAG.
Apache Pinot added support for vectors in 2024. This enables AI models to reason over live data instead of stale snapshots. And with vector auto embedding, StarTree makes that power easier to harness. Generate, ingest, and index vector embeddings in a fully integrated workflow, bypassing the need for complex, stitched-together pipelines.
Grafana integration to support observability
StarTree offers seamless integration with Grafana for data visualization and monitoring. This integration allows users to leverage Grafana’s dashboards to interactively visualize data stored and analyzed by Pinot.
Your data remains private and secure


Robust Authentication & Authorization

Encryption of data at rest and in transit

Networking Security

Audit trails and data loss prevention
Real-time use-cases thrive on StarTree
How Primer.AI improved performance and ROI by moving from OSS Apache Pinot to StarTree Cloud
Should you manage OSS Apache Pinot yourself, or turn to professionally managed Apache Pinot on StarTree Cloud? This was the question Primer.ai asked themselves when their customer base and platform usage grew, and they started to encounter scaling challenges.

Scaling Real-Time Analytics at Angel One with Apache Pinot
Angel One, a prominent Indian financial services platform, has successfully leveraged Apache Pinot to handle high-capacity loads and deliver ultra-fast query times across its diverse business verticals. By implementing Pinot, Angel One has resolved previously difficult analytical challenges, enabling real-time …
Enhancing Last Mile Delivery with Apache Pinot at Walmart
Overview Walmart’s last-mile delivery lifecycle is highly complex, involving 20 to 30+ microservices. Because each microservice maintains its own state of a given entity (such as a customer’s order), tracking the complete life cycle of an order as it moves …
How does open-source Pinot compare with StarTree?
Managed ServiceFeature |
Open Source Apache Pinot |
StarTree Cloud Adds… |
Operations & Management |
Users manage cluster tuning, scaling, upgrades, monitoring |
Fully managed by Pinot creators; automated lifecycle mgmt |
Support |
Community-based support |
Proactive monitoring and management by the largest team of Pinot committers/PMCs, with enterprise-grade SLAs.
More |
System Observability |
Limited |
Out of the box support for system metrics (Grafana), logs (Loki) and query debuggability (Loki + StarTree
Query Console)
|
Value-Add FeaturesFeature |
Open Source Apache Pinot |
StarTree Cloud Adds… |
Minion Auto Scaling |
Not available |
Automated background tasks (compaction, rebalancing, indexing) without query impact.
More
|
Precise Fetching |
Not available |
Retrieves only needed data from S3, delivering sub-second queries while cutting compute/storage costs.
More
|
AZ-Aware Kafka Ingestion |
Custom Setup |
Out of the box setup to reduce cross-AZ traffic costs during ingestion |
AZ aware HA setup |
Custom setup |
Out of the box support for multi-zone deployments for HA deployments.
More
|
Scalable Upserts |
Limited to in-memory |
Enterprise-grade off-heap upserts with high-concurrency and fast updates.
More
|
Advanced Indexes |
Core indexes only |
Sparse Index (efficient selective queries); Composite
JSON Index (nested queries)
|
ML-Driven Query Optimization |
Manual tuning required |
Automated index selection and query tuning.
More |
Automated Data Backfill |
Manual |
Detects and fills data gaps without pipeline disruption.
More |
Security |
Basic controls |
Role-based access control, encryption, SSO (OIDC), SOC2/ISO/HIPAA compliance, audit logs and AWS secrets manager support. More
|
Data onboarding Wizard |
Limited |
Intuitive UI based wizard for onboarding new datasets with automated schema inference, data preview and data
modelling support
|
IntegrationsFeature |
Open Source Apache Pinot |
StarTree Cloud Adds… |
Apache Iceberg |
Not built-in |
Precision fetch enables low-latency queries directly on data in Iceberg/Parquet without pipelines/duplication. More
|
Delta Lake |
Not built-in |
Native Delta Lake connector.
More |
Snowflake |
Not built-in |
Native Snowflake connector.
More |
Grafana |
Not built-in |
Native plugin + PromQL-style queries for observability.
More |
Model Context Protocol (MCP) |
Not available |
Secure, real-time LLM/AI agent access to Pinot data.
More |
Vector Embedding Hosting |
Not available |
Hosts embeddings for semantic search & RAG use cases. More |
AWS Graviton Support |
Not optimized |
Cost-efficient compute with ARM-based Graviton processors. More |
| ||||||||
Request a Trial
The best way to discover real-time analytics with Apache Pinot is to try it yourself – and there’s no easier way than StarTree Cloud.
