
The highlights of RTA Summit 2024 included:
- 43 speakers from companies like Uber, DoorDash, Stripe, Slack, and Atlassian
- 240+ attendees from the real-time analytics community
- 3 keynotes and 1 panel talk from thought leaders at Confluent, Uber, Dialpad, and Microsoft
- 22 breakout sessions on use cases, tech deep dives, and ecosystem
- A pool deck party with fantastic food and drinks, great conversation, a DJ that toured with Pitbull, and a raffle for a PlayStation 5
Kishore’s keynote: Stay ahead or be left behind
The event kicked off with StarTree’s CEO and co-founder Kishore Gopalakrishna speaking about the current state of the industry. His keynote was dedicated to the skeptics of real-time analytics — those who have found issues turning their data into insights in seconds or milliseconds. Kishore talked about the changing data needs of modern organizations. He also covered the latest advancements in Apache Pinot, and announced new pricing and serverless options for StarTree Cloud, as well as the general availability of StarTree ThirdEye.
Read more about Kishore’s talk here, or watch the keynote in full:
Jay’s keynote: Unifying the operational and analytical worlds
On Day 2 the first keynote speaker was Confluent CEO and co-founder Jay Kreps. He referred to the “data mess” found across many organizations as a key driver behind the creation of Apache Kafka. That data mess was also responsible for a lot of developer pain. Solving it has been harder than we thought, but it has led to the creation of multi-subscriber data products, each having a “contract for reliability with the rest of the organization.” In retrospect, this seems obvious, but it hasn’t been easy.

Jay observed this as the natural result of the segregation of the “operational estate” from the “analytical estate” across many organizations. The analytical estate has historically been dominated by batch systems and data products, delivering next-day results. Whereas the rest of the organization is running in real-time. While historically these camps have been partitioned, “never the twain shall meet,” Jay quipped, “I think increasingly in the world that’s not really the case.”
Increasingly the kinds of applications we are building and running now, such as AI, exhibit operational, real-time needs. They are “serving customers, whether external or internal. They have uptime SLAs. They have to be fresh and in sync with the data about the business.”
“Ultimately these worlds are starting to come together, and it’s no longer a one-directional flow from the operational side of the house out into the data warehouse.” Jay proposed that our thinking about data products has to evolve as well. We have to consider Universal Data Products. For example, a Kafka topic, its schema and owner, who is responsible for the structure of the data, and ensures that anybody who subscribes to that feed is well-fed with consistently-produced data feeds as the business evolves.
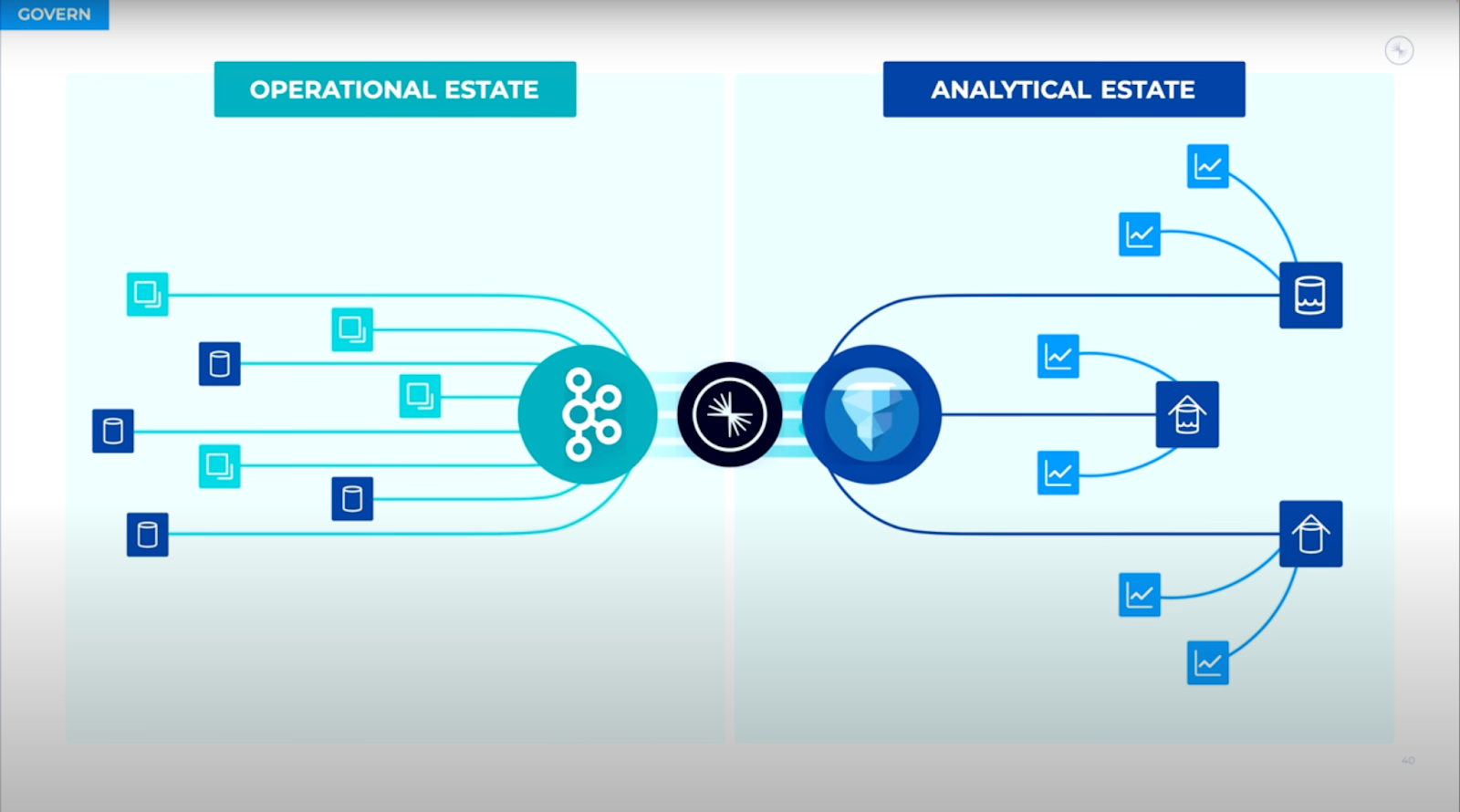
Things are changing, especially as object stores are getting better, faster, and cheaper. Now, with standard open table formats like Apache Iceberg, data-in-motion operational streams like Apache Kafka can more readily integrate with analytical systems. And with stream processing services based on Apache Flink, there are ways to easily transform your operational estate data into formats usable by the analytical estate.
“The point is to open up this data more broadly. And we do that, of course, with these streams in Confluent, but also now with a whole set of open source technologies and commercial offerings that all integrate around Iceberg.” Jay notes that “you’re getting the same well-defined data products that you’re using across the rest of the world. The transformations are done continuously with stream processing so you can have the data land in a format that’s usable. You can eliminate a lot of the painful mapping so you can get out of that rat’s nest of one-off Spark jobs that you had. You have something that does that [work] more systematically.”
Watch Jay’s keynote in full:
Sanjmo’s keynote: Understanding the taxonomy of evolving real-time analytics
Sanjeev Mohan, also known as Sanjmo, is an industry veteran with over 25 years experience as a technology practitioner, principal, analyst, speaker, and author. His most recent work has been around defining a new class of systems known as Unified Real-Time Platforms (URP). Along with his colleagues Roy Schulte and Manish Devgan, Sanjeev has been studying and classifying real-time analytical systems for their breadth and depth of capabilities.
Sanjeev opened with an analogy to the inflection point in the growth of Nvidia, from when it was a video card making company to the powerhouse driving innovation in data sciences and AI. Similarly, Sanjeev believes, “Right now, this is an inflection point for real-time analytics and streaming data.” There are increasing and converging needs for real-time analytics. For user-facing analytics. For better operational decisions. For real-time anomaly detection. For higher levels of customer service. For timely recommendations. And for efficient resource usage and cost optimization.
“One of the most important things between last year and this year? It’s not AI. It’s cost optimization.” Economic downturns and headwinds are driving every company to optimize on cost. It’s another area where real-time analytics becomes the lynchpin.
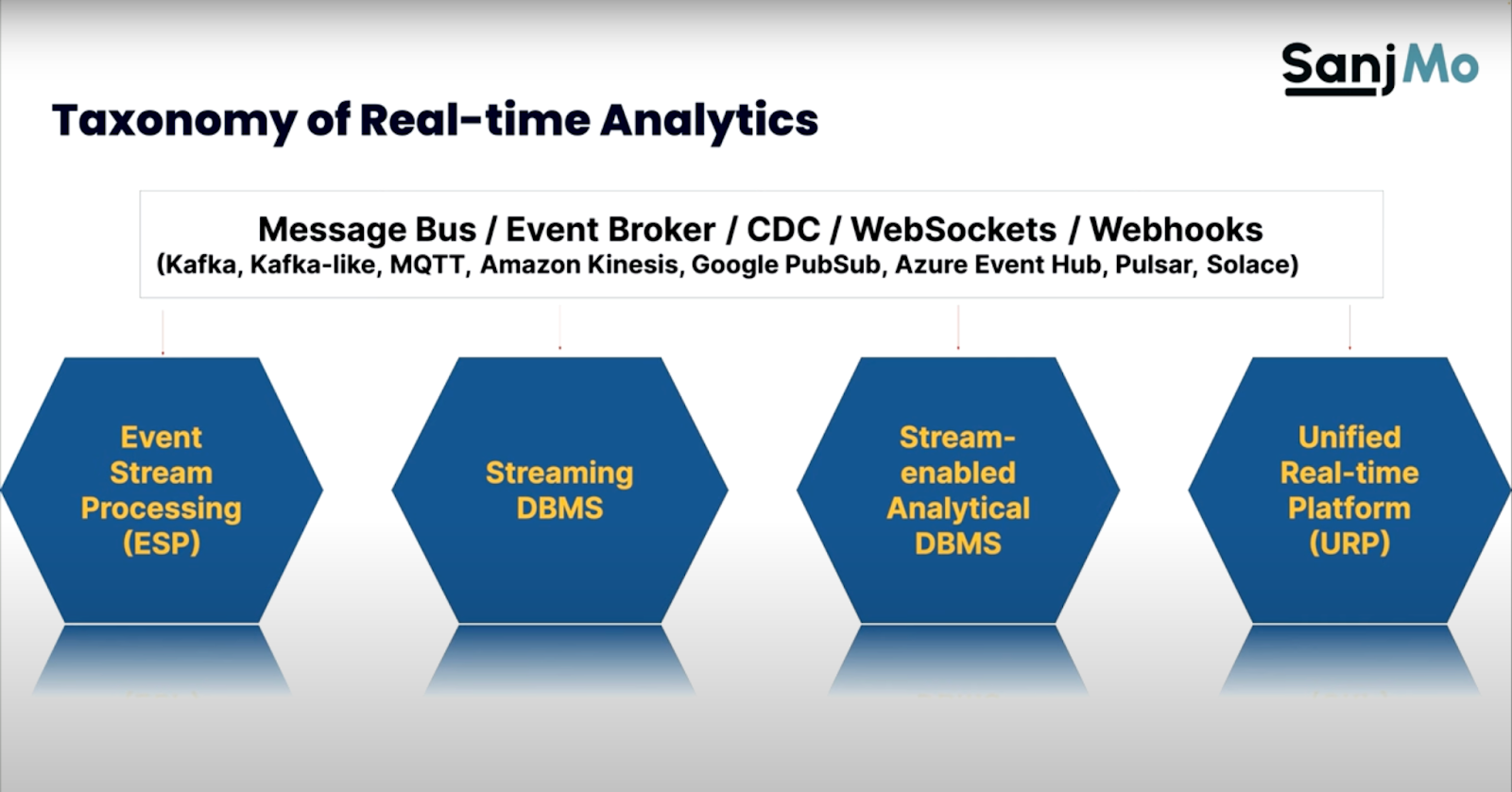
Sanjeev’s perspective defines this breakdown of the real-time analytics landscape:
- Event Stream Processing — Apache Flink and similar services, like Google Cloud Dataflow
- Streaming Databases — including DeltaStream, Materialize, and RisingWave Labs
- Stream-enabled Analytical Databases — such as StarTree Cloud, Imply, Clickhouse, Rockset, and Tinybird
- Unified Real-Time Platforms (URPs) — GridGain, Hazelcast, KX, Timeplus, and others
To Sanjeev, a URP is a scalable all-in-one platform that includes aspects of real-time data streaming, event stream processing, and streaming-enabled data platforms (such as real-time OLAP or OLTP databases). He and his colleagues also acknowledge that many organizations today create customized solutions combining best-of-breed technologies for each of these elemental components.
Watch Sanjeev’s keynote in full:
Panel: Industry leaders discussed their experiences with real-time analytics
Leaders from Uber, Microsoft, Confluent, and Dialpad shared what led them to adopt real-time analytics technologies, the business outcomes they achieved, and what the future of this space looks like. Hosted by Tim Berglund, StarTree’s VP of Developer Relations, the panel included:
- Dipti Borkar, Vice President & GM, Microsoft
- Kranti Parisa, VP of Product Engineering, Dialpad
- Mingmin Chen, Director of Engineering, Uber
- Shaun Clowes, Chief Product Officer, Confluent

Shaun Clowes (Confluent) weighed in on the current state of a real-time analytics “stack,” saying there are hundreds — if not thousands — of applications that organizations are currently juggling. Meanwhile, Kranti Parisa (Dialpad) discussed the integration of AI with real-time analytics, saying, “You have to know the data to do a better job at automation.”
Watch the full panel for more great insights:
Sessions at a glance
This year’s speakers covered a range of topics, from their use cases with Apache Pinot to their real-time architecture, and from best practices to tech deep dives. Here’s a quick recap of the keynotes and breakout sessions, all of which are available for on-demand viewing here.
Use case sessions
- Real-time ML modeling with Datasketches and Apache Pinot: Caner Balci and Jia Li (Uber) shared how they use Pinot as a datasketch store for ML model monitoring
- Operating Pinot at scale: David Yang (Stripe) discussed operational lessons from running Pinot in production while maintaining SLAs and keeping clusters stable
- Automating real-time pipelines at DoorDash: Varun Narayanan Chakravarthy, Chen Yang, and Basar Hamdi Onat (DoorDash) shared their learnings on maintaining their 2,500 real-time pipelines
- Internal analytics at Slack with Apache Pinot and Tableau: Jessica Stewart (Slack) shared how Slack introduced Pinot to power Tableau dashboards for internal users
- Getting user-facing analytics right for Web3 at scale: Sidney Zhang (Magic Eden) and Xiang Fu (StarTree) discussed how Magic Eden uses Pinot to power user-facing analytics for their Web3 applications
- Top applications for real-time analytics: Tim Veil (StarTree) covered 6 common use cases for real-time analytics and their impact on various industries such as IT and FinTech
- Using Pinot to power AdTech analytics dashboards: Hyun Min Choi (Moloco) covered how Moloco runs batch pipelines using Apache Pinot
- Evolution of OLAP at Uber: Yupeng Fu (Uber) discussed Uber’s journey with Apache Pinot and migration from other technologies including Elasticsearch and ClickHouse
- Real-time anomaly detection at DoorDash: Will Gan (DoorDash) and the StarTree team shared an in-depth case study of how DoorDash uses StarTree ThirdEye anomaly detection to serve their API partners
- Building an observability platform with Pinot: Neha Pawar (StarTree) discussed the observability ecosystem and how Pinot can be used to power observability platforms like Grafana
- Real-time analytics for mobile app crashes: Ujwala Tulshigiri (Uber) covered how Uber uses Pinot to power their in-house analytics tool for mobile app crashes

Will Gan from DoorDash and members of the StarTree team shared how DoorDash uses StarTree ThirdEye anomaly detection during RTA Summit 2024.
Architecture sessions
- Architecting a real-time API usage analytics platform: Dunith Dhanushka (Redpanda) shared how to transform your APIs into business gold with Redpanda, Apache Flink, and Pinot
- Pragmatic guide for modern data movement platforms: Sharon Xie (Decodable) covered the evolving landscape of data movement technologies, including ELT, ETL, event streaming, stream processing, and Change Data Capture (CDC)
- The API cost of running Presto in the cloud at scale: Hope Wang and Bin Fan (Alluxio) analyzed the challenges of a large cloud deployment of Presto
- Querying real-time data using SQL: Jove Zhong and Gang Tao (Timeplus) discussed how to query streaming data on Kafka / Pulsar with SQL
- Bridging stream processing and real-time OLAP: Yingjun Wu (RisingWave) dove into how stream processing and OLAP can work together
- Building a voice-to-text streaming pipeline: Felipe Hoffa (Snowflake) demoed how to use Snowflake alongside streaming data
- Micro-service architecture for real-time data processing: Khushbu Agrawal and Manu Gupta (Atlassian) discussed how Atlassian built out data micro-services to integrate data from various sources

Sharon Xie from Decodable discussed the evolving landscape of data movement platforms during RTA Summit 2024.
Technical deep dives
- Serverless Apache Pinot with StarTree: Neha Pawar and Chinmay Soman (StarTree) introduced the concept of “workspace”, which allows StarTree Cloud to provide isolation on a single cluster with shared infrastructure
- Multi-stage JOINs with Pinot: Xiaotian Jiang and Rong Rong (StarTree) covered Pinot’s new multi-stage query engine
- Real-time IoT analytics with Apache Pulsar and Pinot: David Kjerrumgaard (StreamNative) demonstrated how to implement an IoT analytics pipeline with Pulsar’s native MQTT support
- Beyond tiered storage with serverless Apache Kafka: Richard Artoul (WarpStream Labs) did a deep dive into building a Kafka protocol-compatible system with zero local disks

Neha Pawar and Chinmay Soman from StarTree introduced serverless Apache Pinot with StarTree during RTA Summit 2024.
Training day: Uncorking analytics with Apache Kafka, Apache Flink, and Apache Pinot
New for this year’s event was an initial day of software training for practitioners. StarTree and Confluent partnered to present an all-in-one course combining the power of data streaming, stream processing, and real-time analytics — Apache Kafka, Apache Flink, and Apache Pinot. Hosted by StarTree’s Viktor Gamov and Confluent’s Upkar Lidder, the all-day session took users through the what, the why, and the how-tos, combining these three technologies into an effective real-time data pipeline.
All work was done locally in Docker Desktop, using a Github repository with all necessary Makefiles, Dockerfiles, and Python scripts. After an introduction to the technologies involved, users learned how to set up local clusters in their laptops, ingest data and perform queries with Apache Pinot. Then, from there, how to integrate it with Apache Kafka topics and how to enrich data using Apache Flink. After a long and informative day, attendees were able to share their new skills certification on LinkedIn.
Thank you to our sponsors and community
Thank you to all of this year’s sponsors for helping make Real-Time Analytics Summit a success! We’d like to give a shout-out to all our Gold and Silver sponsors:
- Gold sponsors: AWS, Confluent, GridGain, Lenses, Materialize
- Silver sponsors: DeltaStream, Imply, meshIQ, RisingWave
We’d also like to thank the Apache Pinot and real-time analytics communities for their support. In addition to the Pinot community, the event was well-attended by open source partners and friends representing Apache Kafka, Apache Pulsar, Apache Flink, Apache Druid, RisingWave, Presto, and more.

All session content available on-demand
All RTA Summit session videos are now available on-demand — you can watch them here. In the coming weeks, we’ll also do more deep-dive blogs on some of the amazing talks held over the course of the event.
