
Introduction
In recent years, companies have been investing heavily in building real-time analytical solutions for their customers to drive strong retention, make better day-to-day decisions, and prevent fraud. Huge volumes of data are constantly being ingested into such real-time analytics platforms that serve highly concurrent queries.
The cost of real-time analytics can be quite high if you’re choosing the wrong stack. For instance, many companies are still choosing traditional Online Transaction Processing (OLTP) databases for building analytical applications. In other cases, some engineers choose Elasticsearch for running complex, highly concurrent Online Analytical Processing (OLAP) queries on large-volume datasets. These systems were not built for executing such OLAP queries in an efficient manner, thus driving up the total spend.
StarTree is a leading provider for building such powerful applications on top of its cloud platform. In this blog, we will take a closer look at the various knobs StarTree Cloud offers for lowering the total cost-to-serve for its customers.
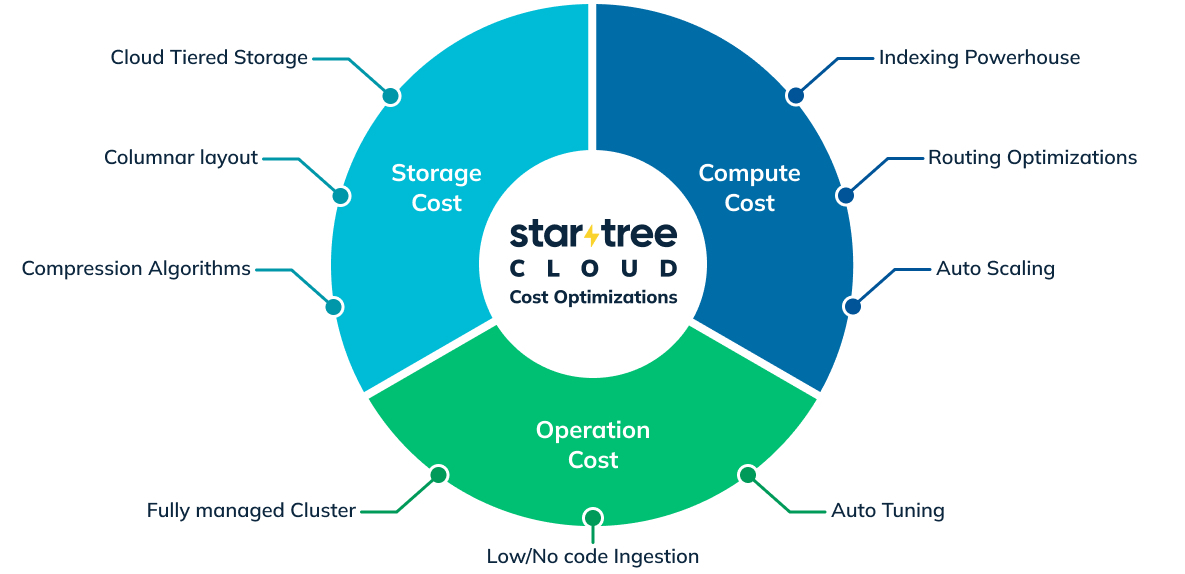
Understanding total cost to serve
The cost of a typical analytics data platform can be broken down into 3 components: storage cost, compute cost, and operational cost.
Storage cost
This refers to the cost of storing and managing the data ingested by the user. Typically users would ingest data from sources such as Apache Kafka or Amazon S3 and store it locally within StarTree Cloud. Cost becomes a concern for high-volume datasets (Terabytes to Petabytes).
Compute cost
This refers to the cost of processing queries as well as other background tasks such as data ingestion, cluster maintenance, data governance, and so on. Although query processing cost is the dominant factor here, it’s also important to optimize for ad hoc ingestion tasks that might be bursty in nature.
Operational cost
This refers to the human cost of deploying, managing, and administering the datasets and clusters. Having a managed service provider will naturally offset most of the administrative cost. However, users still have to handle things like dataset management, data backfills/correction, performance tuning, capacity planning, and so on.
In the following sections, we will go through how StarTree Cloud optimizes each of these components.
How StarTree Cloud optimizes your spend for real-time analytics
StarTree Cloud, powered by Apache Pinot, is the real-time analytics platform for user-facing applications. It’s currently powering critical user-facing applications across various industries including FinTech, AdTech, Social Media, and Delivery and Logistics. Companies have observed tremendous cost savings through this technology. For instance, Uber was able to shave off $2M per year by moving from Elasticsearch to Apache Pinot for just one use case. Stripe, Doordash, Citibank, and many others have adopted Pinot to replace their legacy data stack to realize significant cost savings in terms of infrastructure and operational spend.

Figure 1: Uber saw significant savings and reduction in infrastructure footprint by migrating from Elasticsearch to Apache Pinot.
Let’s take a look at the details of how we can optimize cost across the 3 categories mentioned above.
Lowering storage cost
StarTree Cloud is built on top of Apache Pinot, which is an open source, distributed, columnar OLAP store. One of the key design principles of both these technologies is storage efficiency. Here’s how StarTree Cloud and Apache Pinot help lower the storage costs:
Columnar storage
Apache Pinot is a columnar database, which stores the incoming data in a column-wise fashion rather than row-wise. This means that all values in a column are stored together, making it easier to compress similar values.
Compression algorithms
Compression algorithms like Dictionary encoding and Run-Length encoding go hand in hand with columnar representation, wherein repeated values are represented in a more concise form and only unique values are stored in the underlying storage in the raw form. This greatly reduces the on-disk footprint needed to store user data.
Tiered storage
In addition to reducing the storage footprint, StarTree further provides a way to reduce overall storage cost via tiered storage. Users can choose costly high I/O, SSD-based server nodes for fresh data (say last 3 days) and cheaper server nodes (with spinning disks) for less frequently used data. In addition, StarTree also provides a way to offload historical data (say beyond 7 days) into cloud object storage (eg: Amazon S3) while retaining the ability to query it seamlessly along with the local datasets. Please refer to this blog to learn more about tiered storage.
All these techniques help in reducing how much data needs to be managed locally and also tune the hardware SKU to lower overall storage costs. In a recent study, the Cisco Webex team was able to shrink their infrastructure footprint by more than 500 nodes by switching to Apache Pinot.

Figure 2: Cisco Webex shrank their infrastructure footprint by >500 nodes after switching from Elasticsearch to Apache Pinot.
Lowering compute cost
As mentioned previously, compute costs can be attributed to query processing as well as other background functions. Let’s take a look at how to optimize each of these in detail.
Optimizing query processing cost
The compute cost in this case is directly related to the amount of work needed to be done for executing queries. This includes scanning of data from the local disks, shuffling of data over the network, and of course the in-memory computation for generating a result. Query optimization within Apache Pinot attempts to minimize this work done, and hence overall resource consumption. You can reduce query processing costs via the following optimizations:
- Indexing powerhouse: StarTree provides a range of indexing strategies to minimize the data scans needed.
- Query Pruning: This involves leveraging the metadata to minimize how many data chunks or segments need to be processed for a given query.
- Routing optimizations: Partitioning and co-locating related data segments on the same node helps in minimizing the query fanout and data shuffle costs.
- Flexible scaling: StarTree’s distributed architecture makes it very easy to independently scale the query processing nodes (brokers) from data nodes (servers). This becomes especially important when using cloud tiered storage, wherein we can easily scale the compute nodes responsible for processing data in the cloud store.
We benchmarked the impact of star-tree index on the query performance and resource consumption. This study shows using such advanced indexes allows you to increase query throughput by 5x or more using the same resources. In addition, server utilization dropped from 100% to 20%, meaning it still has reserve capacity. These optimizations ensure that the cluster cost doesn’t grow linearly with the organic growth.
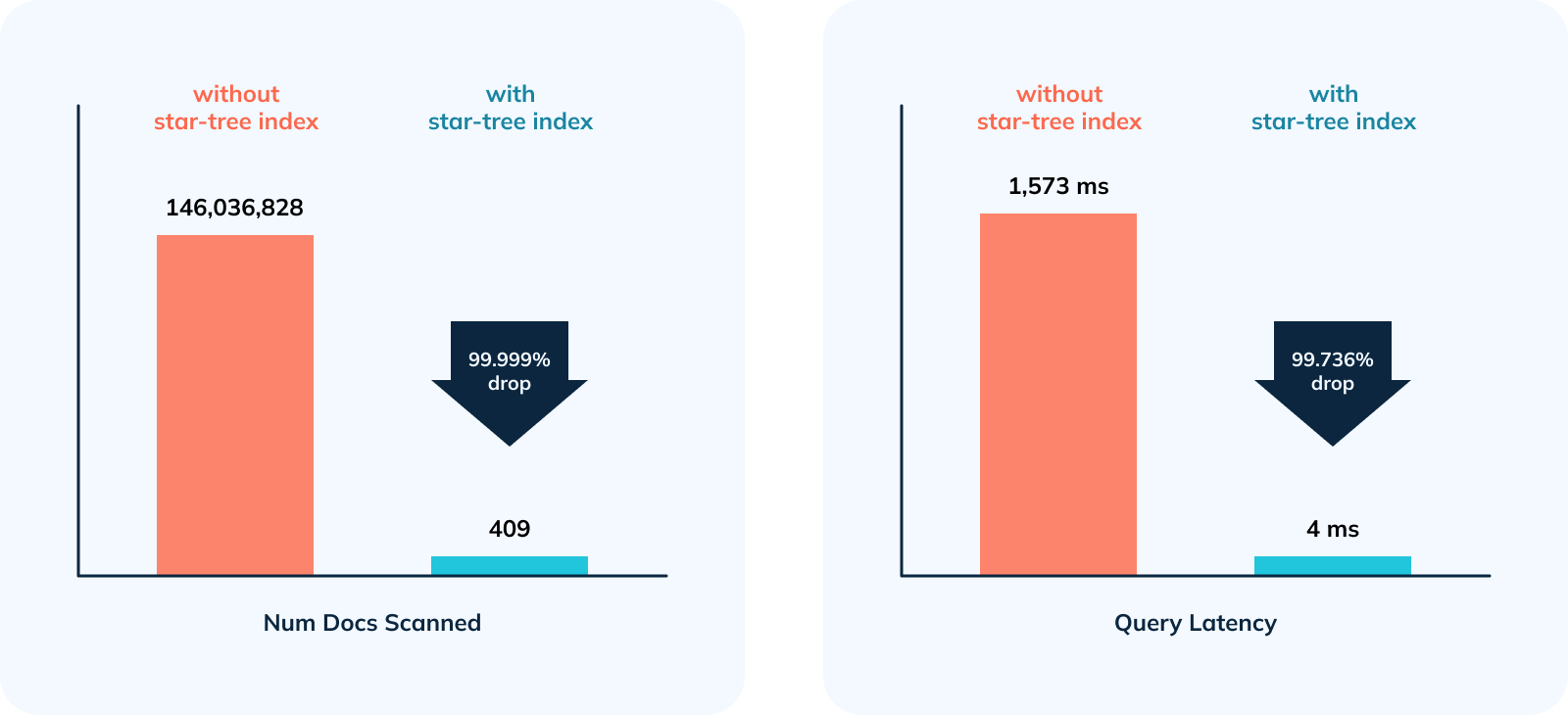
Figure 3: Number of documents scanned and query latency reduced significantly with star-tree index.
The second part of our benchmarking series showed how the Pinot server utilized only 20% of CPU with startree-index. In theory, the scenario we tested could handle roughly 5x more throughput assuming the query pattern remained the same.
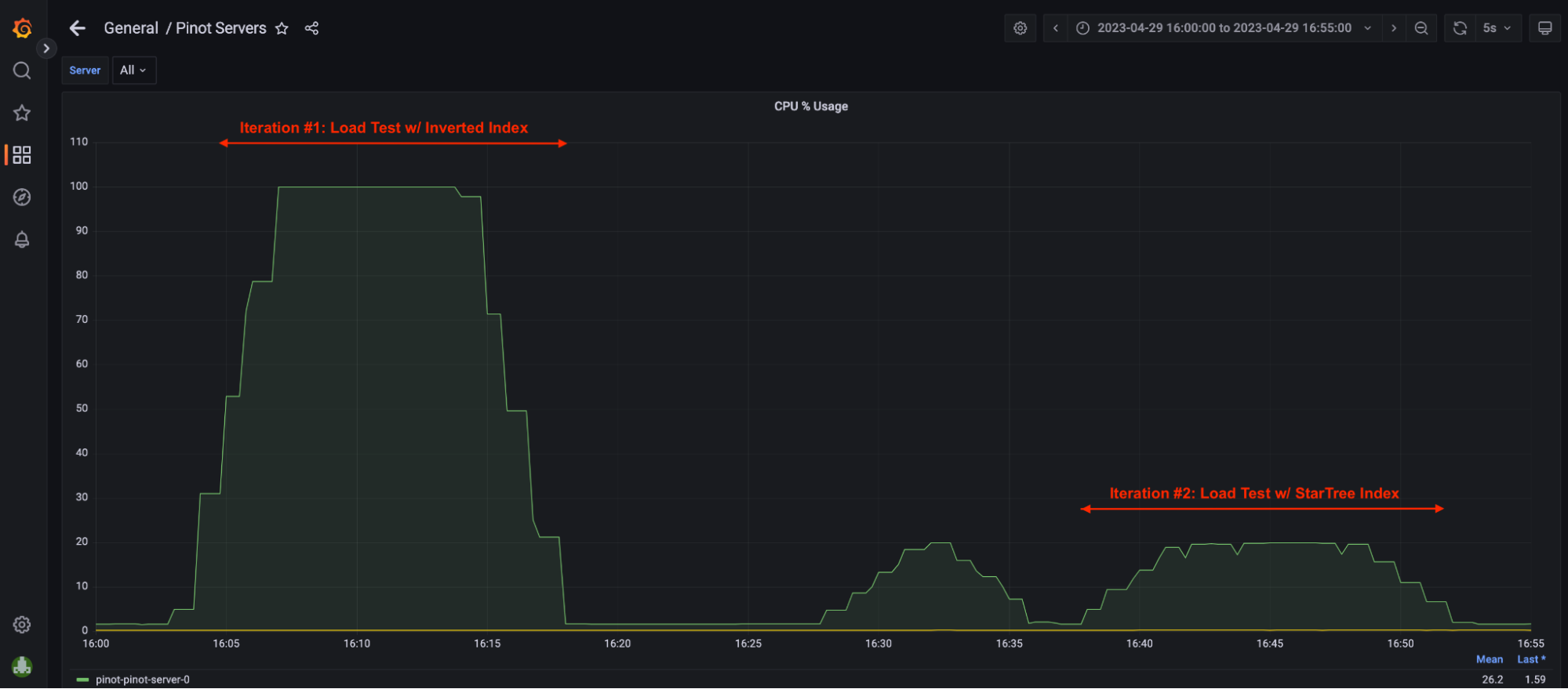
Figure 4: Graph showing CPU utilization in the presence of star-tree index.
Optimizing other ad hoc processing
In addition to query processing, data ingestion also accounts for a large portion of the compute cost. StarTree provides this capability out of the box using the Pinot Minion framework. Users can schedule a periodic job to ingest data from sources such as Amazon S3 or Snowflake. The Pinot Minion framework can also be used for more advanced data management tasks such as data backfills, compaction, repartitioning, resorting, and rollups to higher time granularity.
Here are the key features that optimize overall compute cost for such tasks:
- Autoscaling : StarTree users can start with just 1 minion, which can automatically be scaled based on when a minion job runs and the amount of work that needs to be done. Naturally, this avoids always-on compute and is tremendously beneficial in saving costs. Learn more about how StarTree Minion Autoscaling works in practice.
- Checkpointing : StarTree ingestion tasks are routinely checkpointed. This means in the case of failures, these tasks automatically resume from the last known checkpoint, thereby avoiding the need to run the same job all over again.
In several production use cases, minion autoscaling has resulted in more than 50% compute cost savings, especially for daily ingestion of 10s of Terabytes.
Lowering operations cost
The primary goal of StarTree Cloud is to provide a fully managed experience for the users of Apache Pinot. You can easily provision a shared or dedicated workspace depending on your needs and focus on building analytical applications without worrying about the underlying infrastructure. Here are the ways in which StarTree Cloud reduces the overall operational overhead:
- Cluster management: StarTree Cloud fully automates initial provisioning, capacity planning, scalability, and enterprise-grade security.
- Ingestion: StarTree’s Data Manager provides a low-/no-code utility for ingesting data from various sources like Kafka, S3, or Snowflake and performs iterative data modeling before finalizing your schemas.
- Data operations: StarTree provides out-of-the-box support for various data management operations such as schema evolution, data backfills, and correction.
- Performance Manager: Developers spend quite a lot of time tuning their query performance by doing various things such as adding indexes, data partitioning, using derived columns in the data model, and so on. Performance Manager will automatically suggest the right optimization for a given query — thus saving valuable developer time.
- Anomaly detection: You get access to StarTree ThirdEye for identifying anomalies in your business metrics and data quality within seconds. In addition, users can slice and dice this data to identify the root cause of such anomalies via automated hints provided by the system.
Putting it all together
The real-time data needs of every company will keep growing in the near future (often exponentially). Choosing the right technology that can scale with this explosive growth without causing the costs to skyrocket is crucial. In this blog we saw how StarTree Cloud optimizes all 3 components of the cost model and provides a compelling platform for your current and future needs.
Next steps
Ready to take StarTree Cloud for a spin? Get started with a fully-managed serverless environment using a StarTree Cloud Trial. Or Book a Demo If you have specific needs or want to speak with a member of our team