
Starting today, developers using StarTree can seamlessly ingest data from DynamoDB and over 150 other data sources through Estuary Flow. This powerful integration enables the creation of real-time analytics applications by capturing change data from databases like DynamoDB, MongoDB, and PostgreSQL. With Estuary, DynamoDB change events are captured and sent to StarTree via a Kafka-compatible endpoint, ensuring smooth and real-time ingestion.
This integration is especially valuable for those dealing with multiple data sources, as Estuary’s Kafka API support allows it to function like a Kafka cluster, enabling easy connectivity to StarTree Cloud. By integrating Estuary Flow with StarTree, you unlock the full power of Apache Pinot’s real-time analytics engine, purpose-built for delivering user-facing analytics with sub-second query performance. This ensures that your data is always up to date without manual intervention, enabling you to serve live dashboards, personalized recommendations, or real-time insights directly to your end users.
The high-level flow: From data source to insight
Capturing real-time changes from databases like DynamoDB, MongoDB, PostgreSQL, Oracle, and others often requires complex setups and additional infrastructure. Estuary Flow simplifies this process with its extensive range of connectors and its Kafka API compatibility layer called Dekaf. Dekaf allows you to read data from Estuary Flow collections as if they were Kafka topics and also provides a schema registry API for managing schemas.
For example, you can stream change data capture (CDC) events directly from your data sources into StarTree without the need to deploy and manage your own Kafka cluster. This reduces complexity and lowers initial investment, enabling you to focus on analyzing your data rather than managing data pipelines.
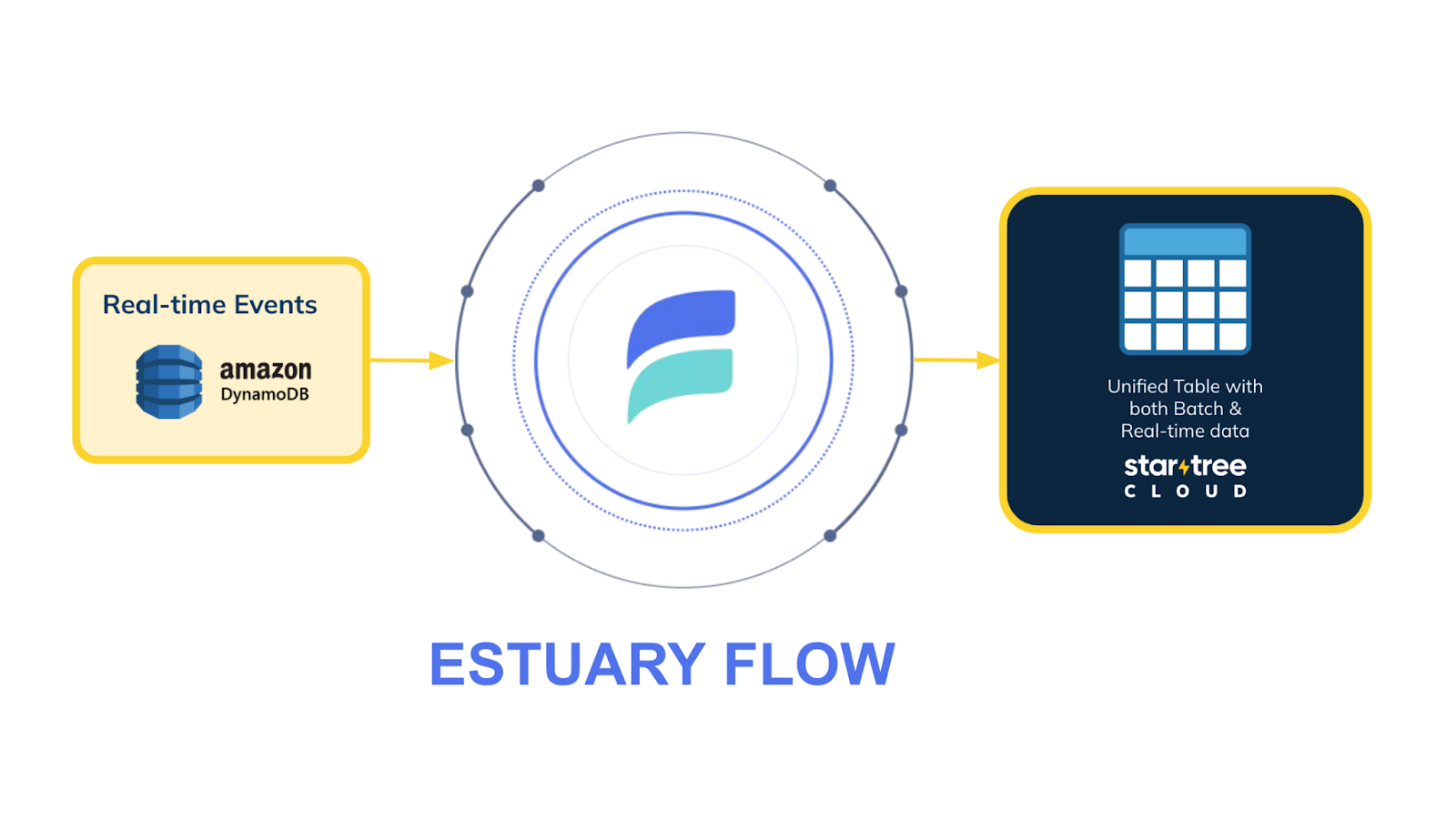
Here’s how it works:
- Connect to your data sources with Estuary Flow: Utilize Estuary’s connectors to capture CDC events in real time from your databases.
- Leverage Dekaf as your Kafka-compatible endpoint: Dekaf acts as a built-in Kafka endpoint, allowing StarTree to read data directly from Estuary Flow collections.
- Ingest data directly into StarTree: StarTree connects to Estuary Flow using its native Kafka data source capabilities, ensuring smooth and real-time data ingestion.
- Achieve real-time insights with low latency: With data flowing seamlessly into StarTree, powered by Apache Pinot, you can run sub-second queries and deliver real-time analytics to your users efficiently.
This integration enables you to build robust, user-facing analytics applications with a simplified architecture, allowing you to get started faster without dealing with too many architectural components. By combining Estuary Flow and StarTree, you can quickly scale your analytics capabilities to meet the demands of modern, data-driven applications.
Why this integration matters: Key benefits for you
Integrating Estuary Flow with StarTree offers several compelling advantages that can enhance your data analytics capabilities:
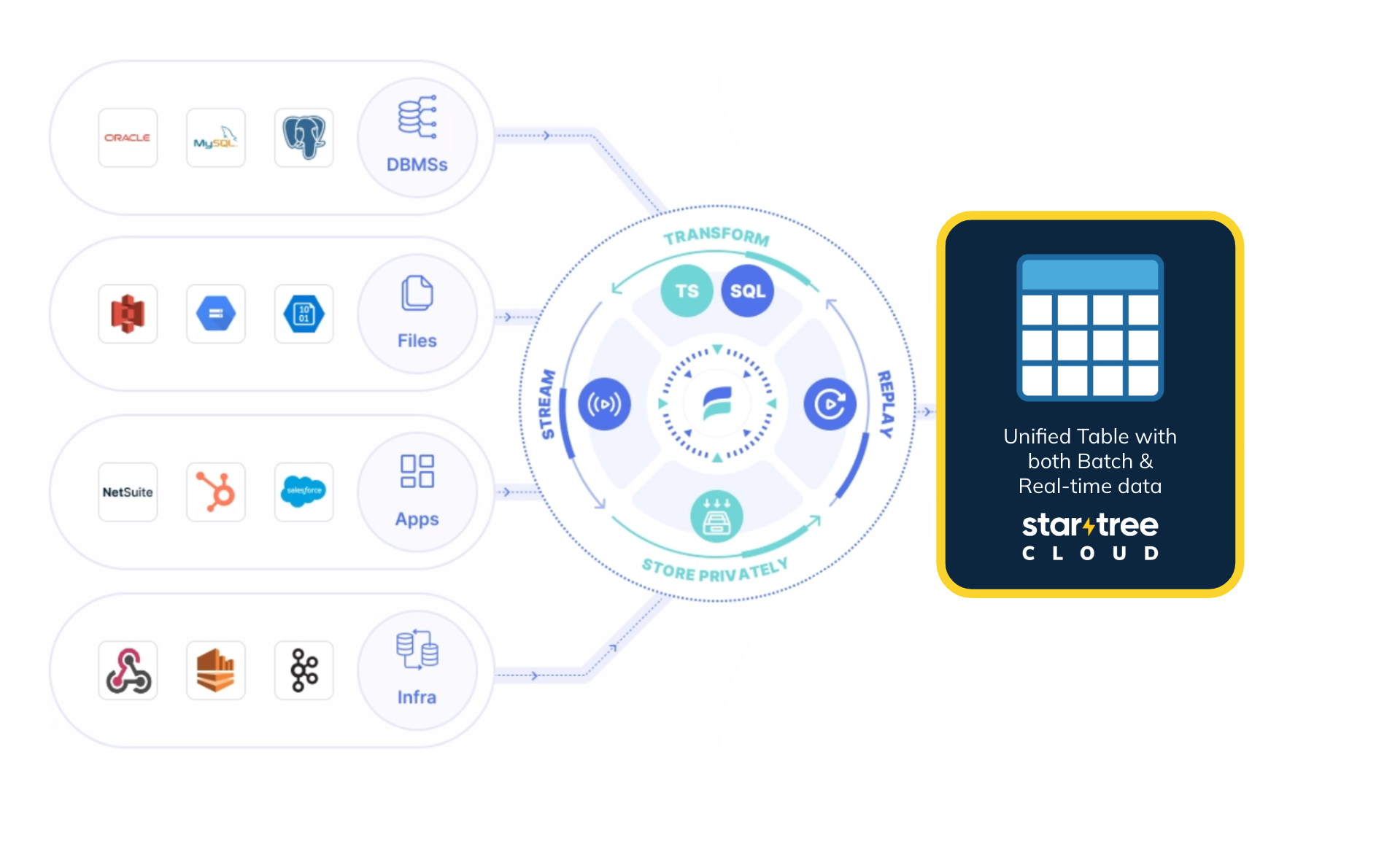
1. Simplified architecture for quick deployment
With Estuary Flow’s extensive range of connectors and its Kafka API compatibility layer, Dekaf, you can establish real-time data pipelines without the complexity of managing multiple architectural components like separate Kafka clusters. This streamlined approach allows you to get started faster, reducing time-to-value for your analytics projects.
2. Real-time data ingestion from multiple sources
Capture change data capture (CDC) events in real time from a variety of databases such as DynamoDB, MongoDB, PostgreSQL, Oracle, and more. This ensures that your analytics are always up to date, providing timely insights that can drive better decision-making.
3. Cost-efficient architecture
The combined solution of Estuary Flow and StarTree results in a cost-effective architecture. Estuary simplifies the integration process by eliminating the need for an additional Kafka cluster, reducing both infrastructure costs and operational overhead. Apache Pinot, which powers StarTree, is renowned for its cost efficiency, delivering high-performance analytics without the high costs typically associated with real-time data processing. This means you can build scalable analytics solutions that are friendly to your budget.
4. Low-latency analytics with Apache Pinot
By streaming data directly into StarTree, powered by Apache Pinot, you can execute sub-second queries and deliver real-time insights to your users. This is especially beneficial for user-facing analytics applications that demand immediate data visibility and responsiveness.
5. Scalability and flexibility
The integration is designed to scale with your needs. As your data grows, both Estuary Flow and StarTree can accommodate increased throughput without significant changes to your setup. Apache Pinot, the engine behind StarTree, is renowned for powering hyper-scale use cases at leading companies like LinkedIn, Uber, and Stripe. This proven scalability ensures that you can handle massive volumes of data and high query loads without sacrificing performance. This flexibility allows you to adapt quickly to evolving business requirements without incurring substantial additional costs, ensuring your analytics infrastructure can grow alongside your business.
6. Reduced operational overhead
By minimizing the number of components you need to manage, you reduce operational complexities and potential points of failure. This lets your team focus on analyzing data and extracting insights rather than handling and maintaining
7. Accessible entry point with StarTree Cloud
StarTree Cloud is available for as a trial to test your analytics applications at no cost. This provides an accessible entry point for businesses of all sizes to leverage powerful real-time analytics capabilities without immediate financial commitment.
By harnessing these benefits, you can build robust, user-facing analytics applications that provide real-time insights—all while keeping your architecture streamlined, efficient, and cost-effective. The combination of Estuary Flow’s simplified data ingestion and Apache Pinot’s renowned cost efficiency ensures that you can deliver high-performance analytics solutions without overextending your resources.
Getting started: Integrating Estuary Flow Dekaf with StarTree
In this section, we’ll walk you through the process of integrating DynamoDB with StarTree Cloud using Estuary Flow’s Dekaf endpoint. The setup involves three main steps:
- Setting up your DynamoDB table
- Configuring Estuary Flow to capture DynamoDB changes
- Connecting StarTree Cloud to Estuary Dekaf
Let’s get started.
Step 1: Preparing your DynamoDB environment
Before proceeding, ensure you have the following from your DynamoDB setup:
An existing DynamoDB table: The table you want to capture data from.
DynamoDB Streams enabled: DynamoDB Streams must be enabled on your table to capture data changes.
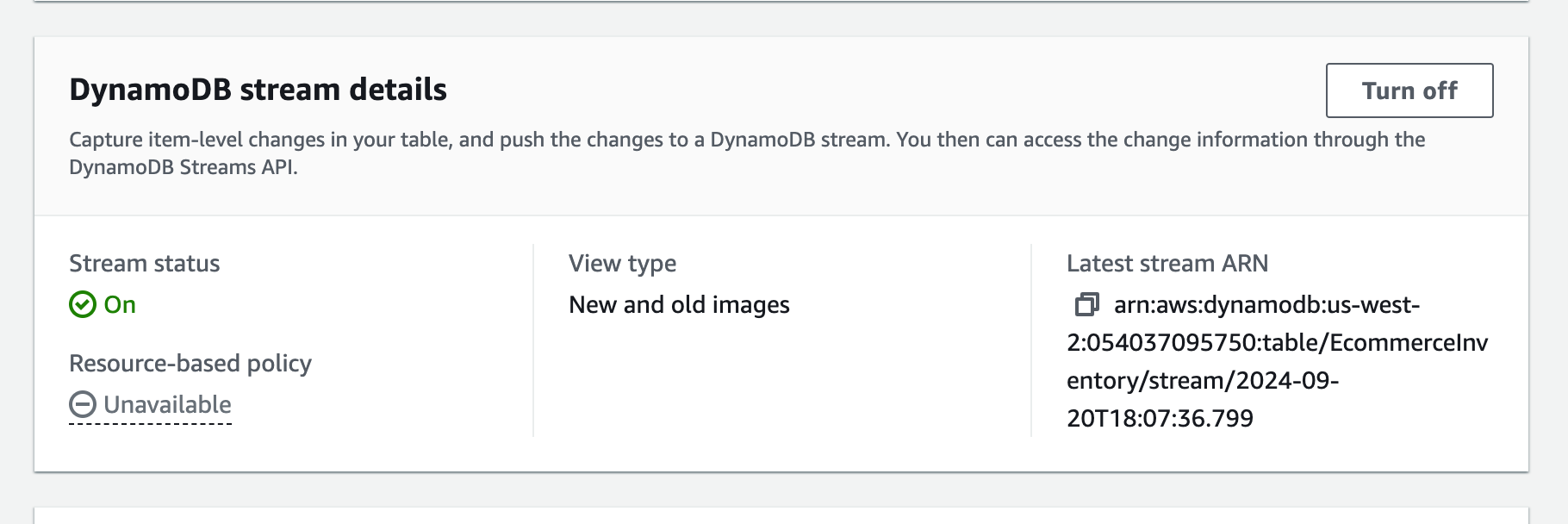
Stream view type: Choose an appropriate view type (e.g., “New image”, “Old image”, “New and old images”).
AWS credentials with proper permissions:
Access Key ID and Secret Access Key with permissions to read from DynamoDB and DynamoDB Streams. These credentials can be obtained from the AWS IAM service.
AWS region: The region where your DynamoDB table is located (e.g., us-west-2).
Enabling DynamoDB Streams:
Step 2: Configuring Estuary Flow to capture DynamoDB changes
Now, set up Estuary Flow to capture changes from your DynamoDB table.
1. Access the Estuary Flow Console
Sign up for Estuary Free Trial here and Log in to your Estuary Flow account, Navigate to the “Sources” section:
2. Create a new Capture
Click on “Add Source” or “Create Capture”. From the list of available sources, select “DynamoDB:
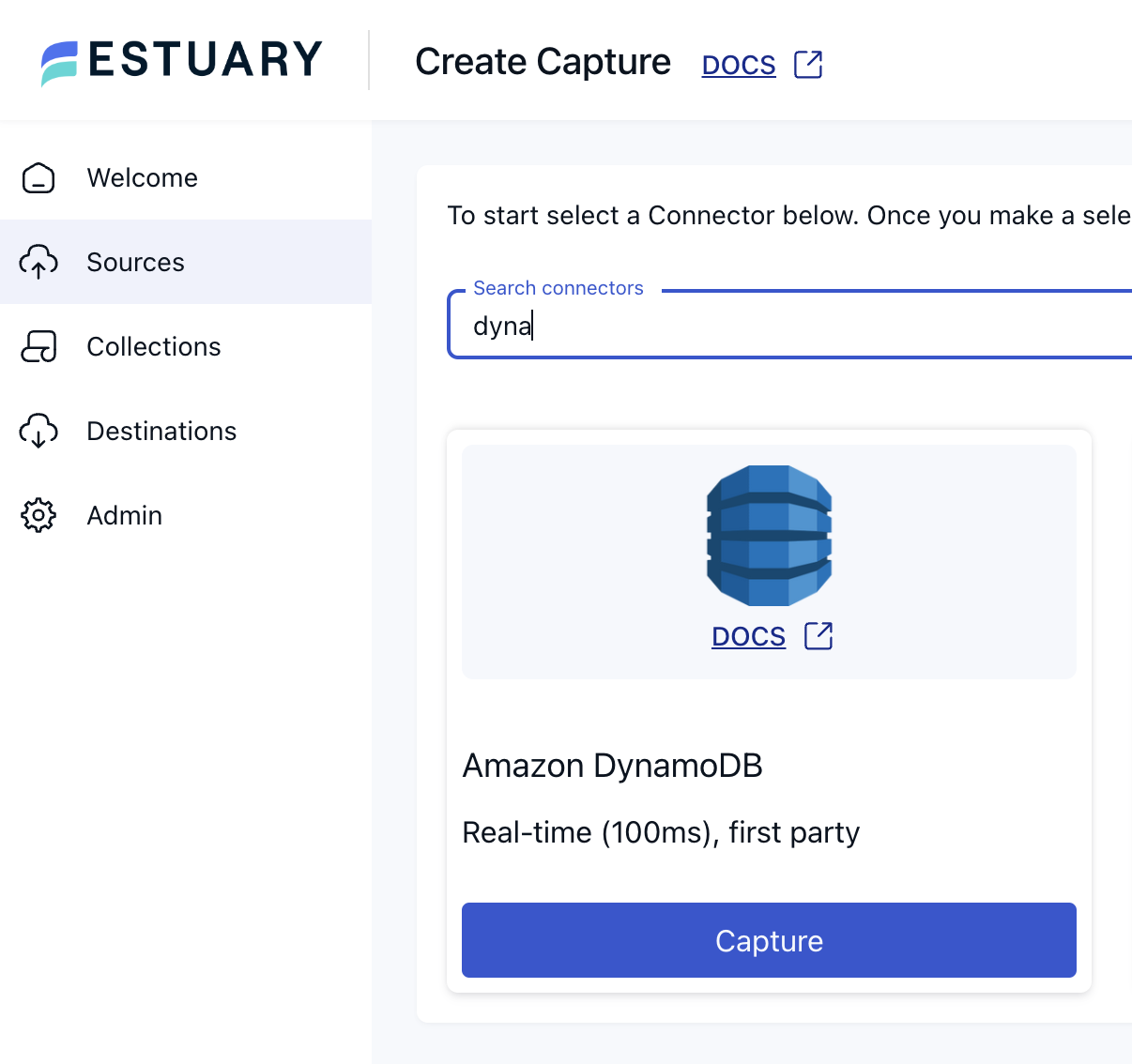
3. Configure the Capture
- Capture name: Enter a descriptive name, e.g., DynamoDBOrdersCapture.
- AWS Access Key ID: Enter your Access Key ID.
- AWS Secret Access Key: Enter your Secret Access Key.
- AWS region: Specify the region of your DynamoDB table (e.g., us-west-2).
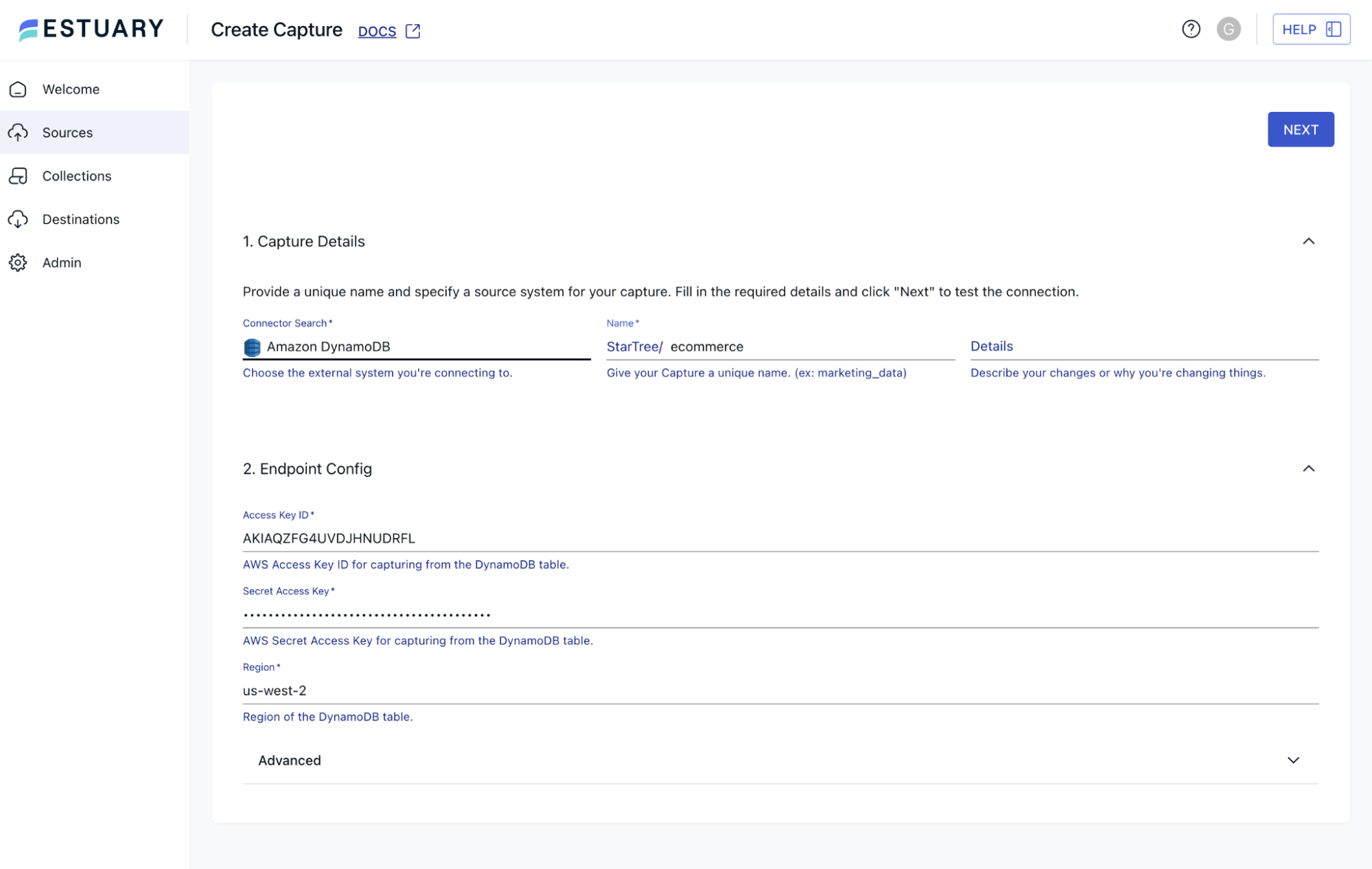
Then proceed to configure Output collections; here all you need to do is verify the Dynamo table you want to ingest:
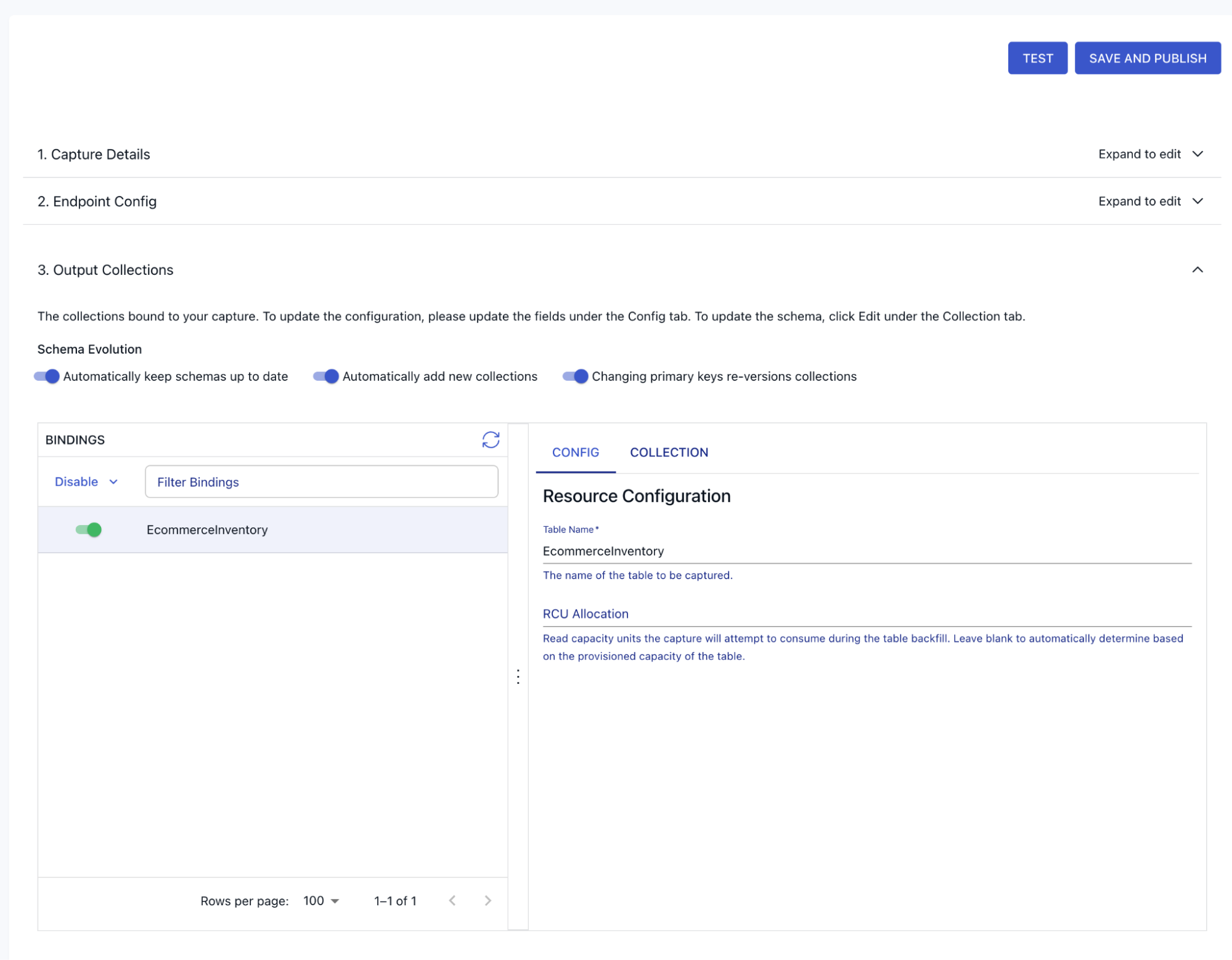
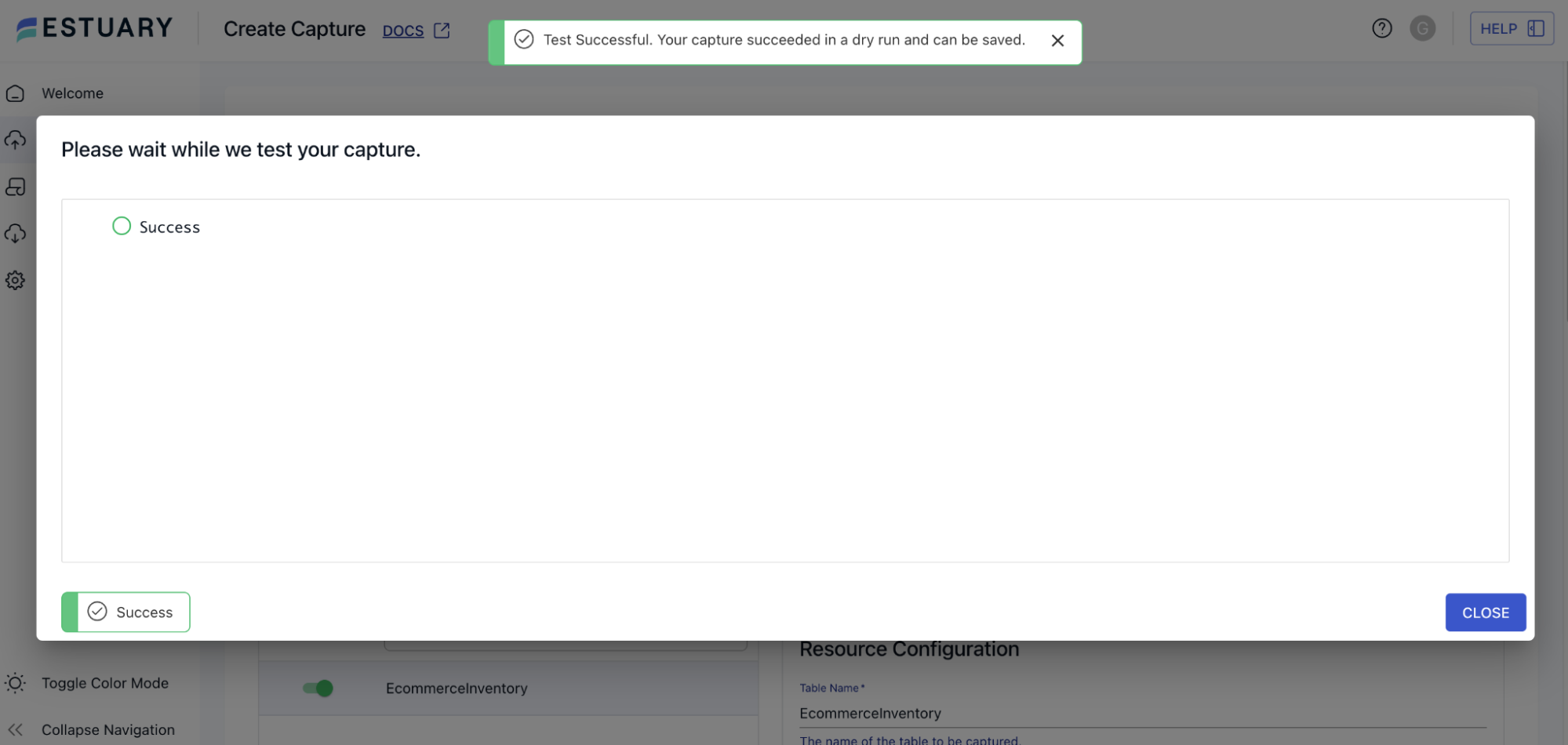
4. Test the connection
Click “Test Connection” to ensure Estuary can access your DynamoDB table and streams.
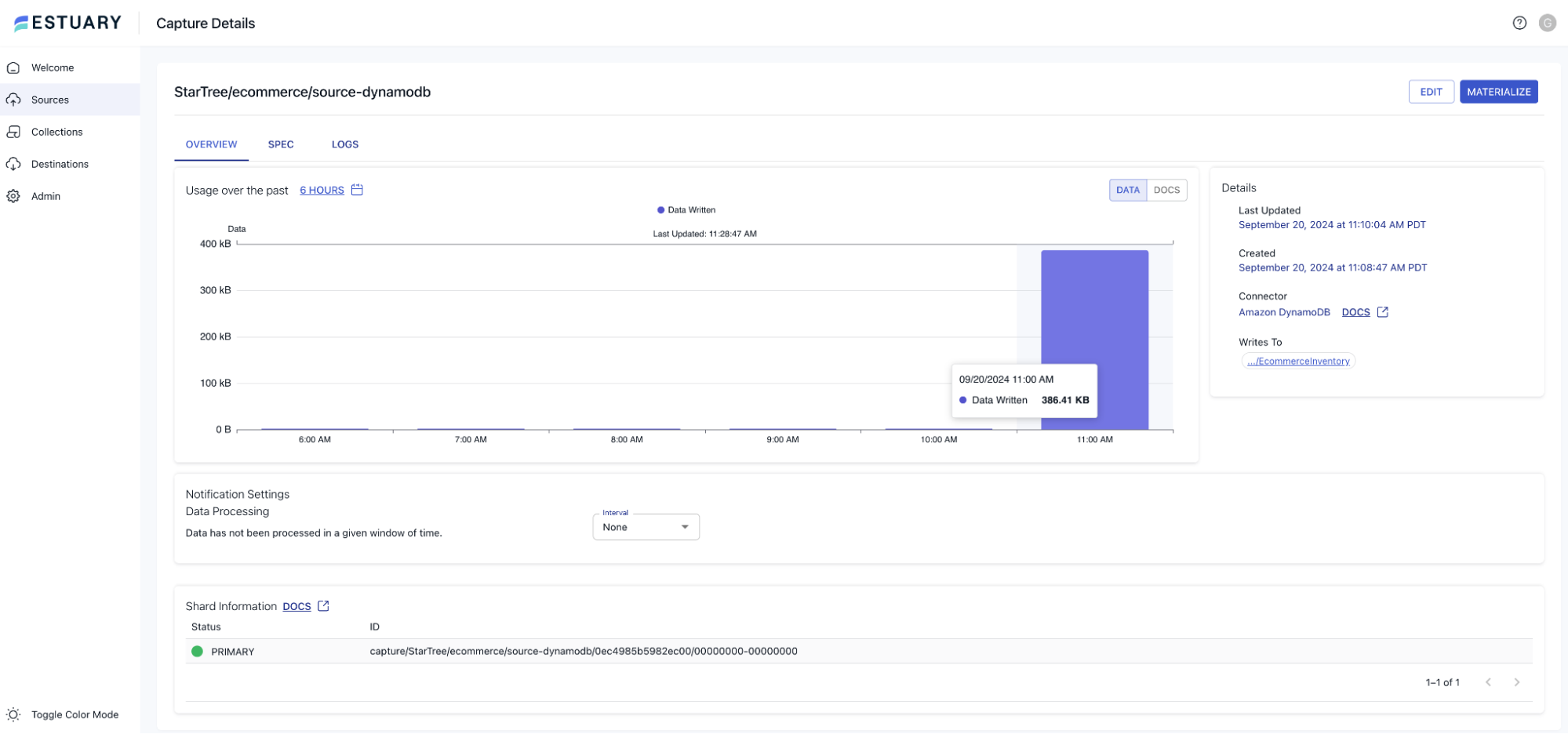
5. Complete the Capture Setup
Review the configuration, click “Create Capture”. Estuary Flow will start capturing changes from your DynamoDB table:
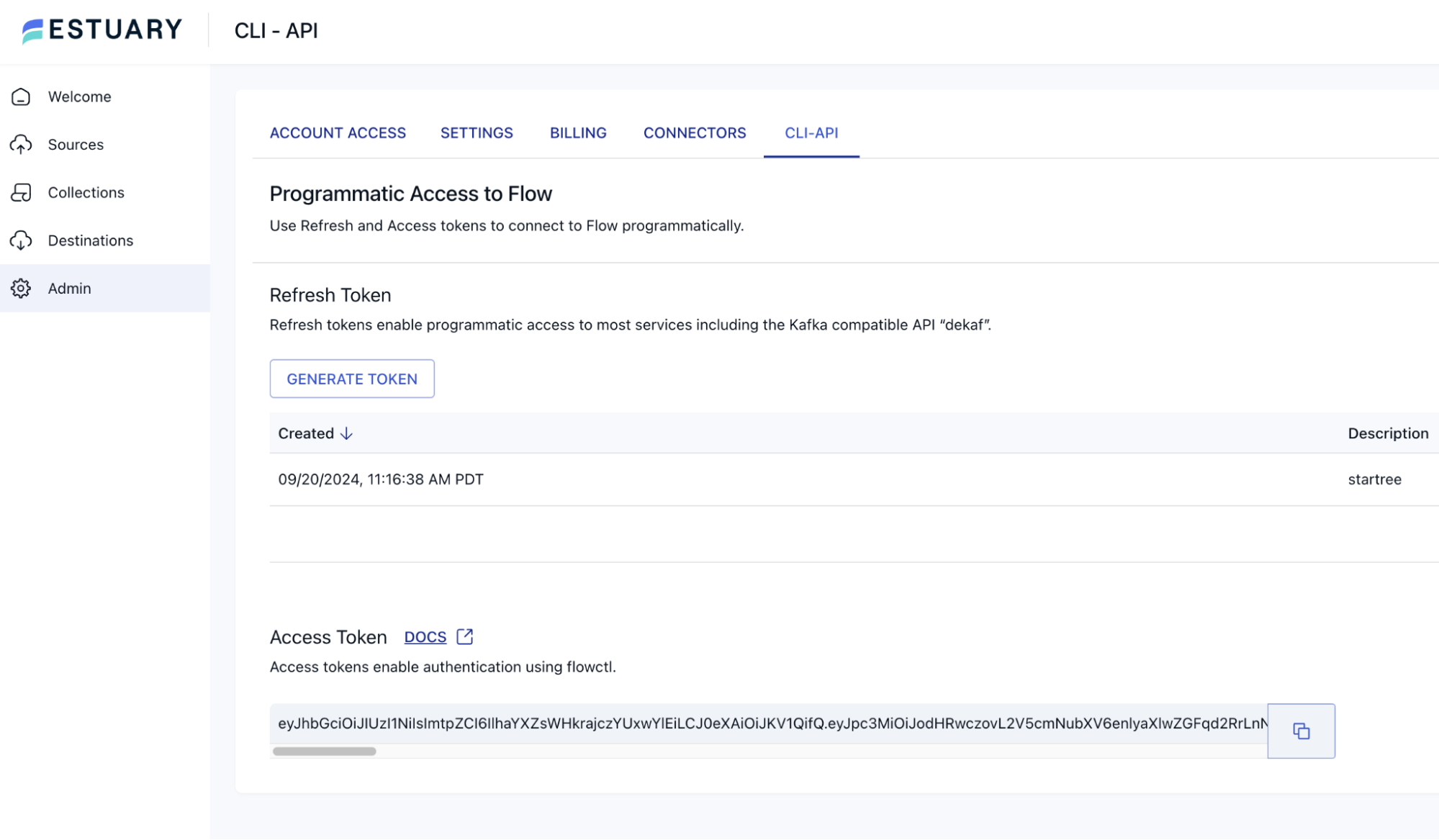
6. Generate a Dekaf access token
You’ll need an access token to allow StarTree Cloud to connect to Estuary’s Dekaf endpoint.
In the Estuary Flow console, navigate to the “Admin” section. Click “Generate New Token”, Provide a name for the token, e.g., StarTreeAccessToken. Copy the generated token and keep it secure.
Step 3: Connecting StarTree Cloud to Estuary Dekaf
Configure StarTree Cloud to ingest data from Estuary’s Dekaf endpoint. Sign up for StarTree Cloud Free Tier.
Configure StarTree Cloud to ingest data from Estuary’s Dekaf endpoint.
1. Access StarTree Cloud
Log in to StarTree Cloud and Navigate to the “Data Manager” section.
2. Add a new data source
- Click on “Add Data Source”.
- Select “Apache Kafka” as the data source type.
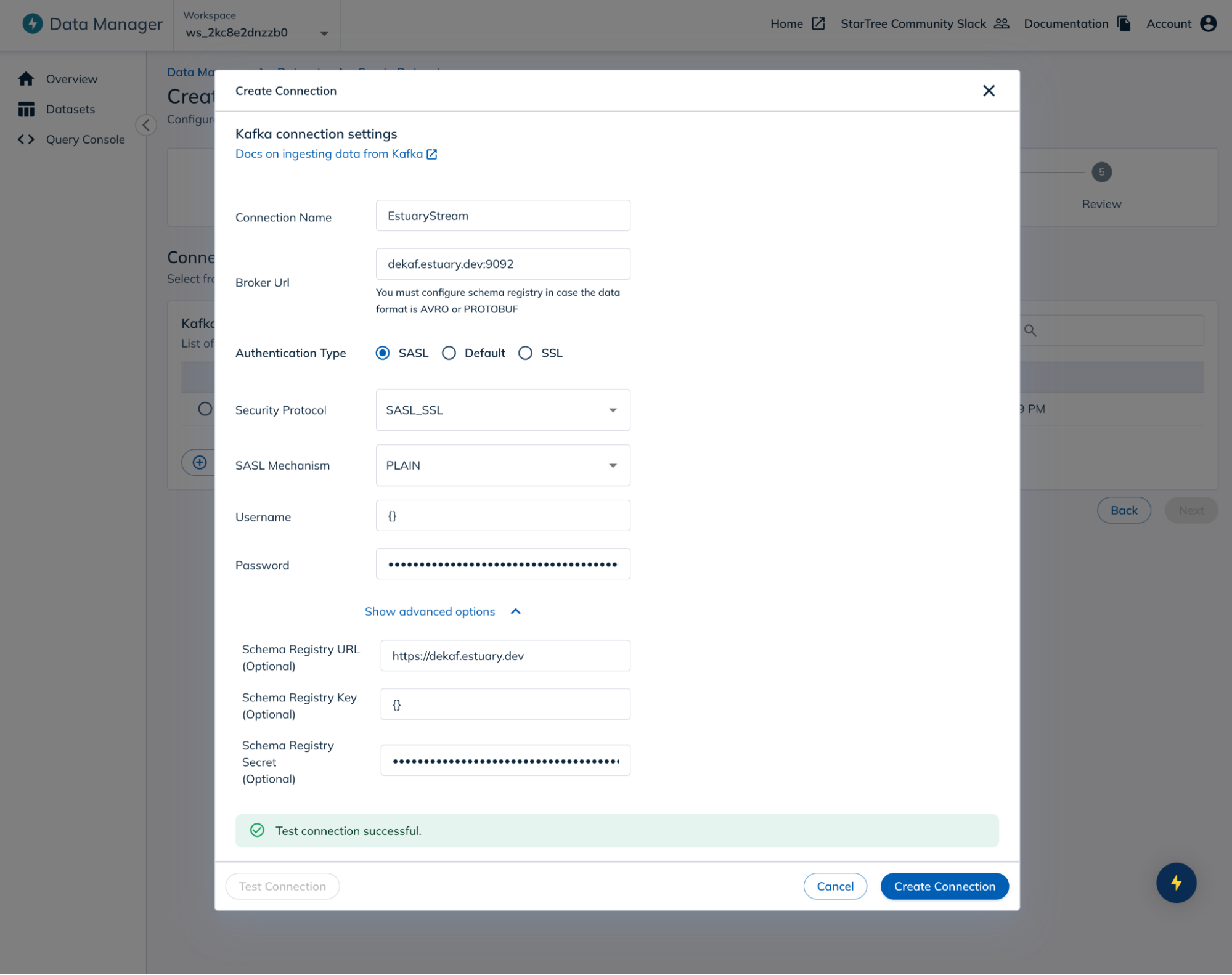
3. Configure the Kafka connection
- Bootstrap Servers: Enter the Dekaf endpoint URL provided by Estuary.
- Security Protocol: Select “SASL_SSL”.
- SASL Mechanism: Choose “PLAIN”.
- Username: Enter {} (empty curly braces).
- Password: Paste the Dekaf access token you generated in Estuary.
- Schema Registry URL: Enter the Dekaf Schema Registry endpoint URL provided by Estuary.
- Schema Registry Key: Enter {} (empty curly braces).
- Schema Registry Secret: Paste the same Dekaf access token you generated in Estuary.
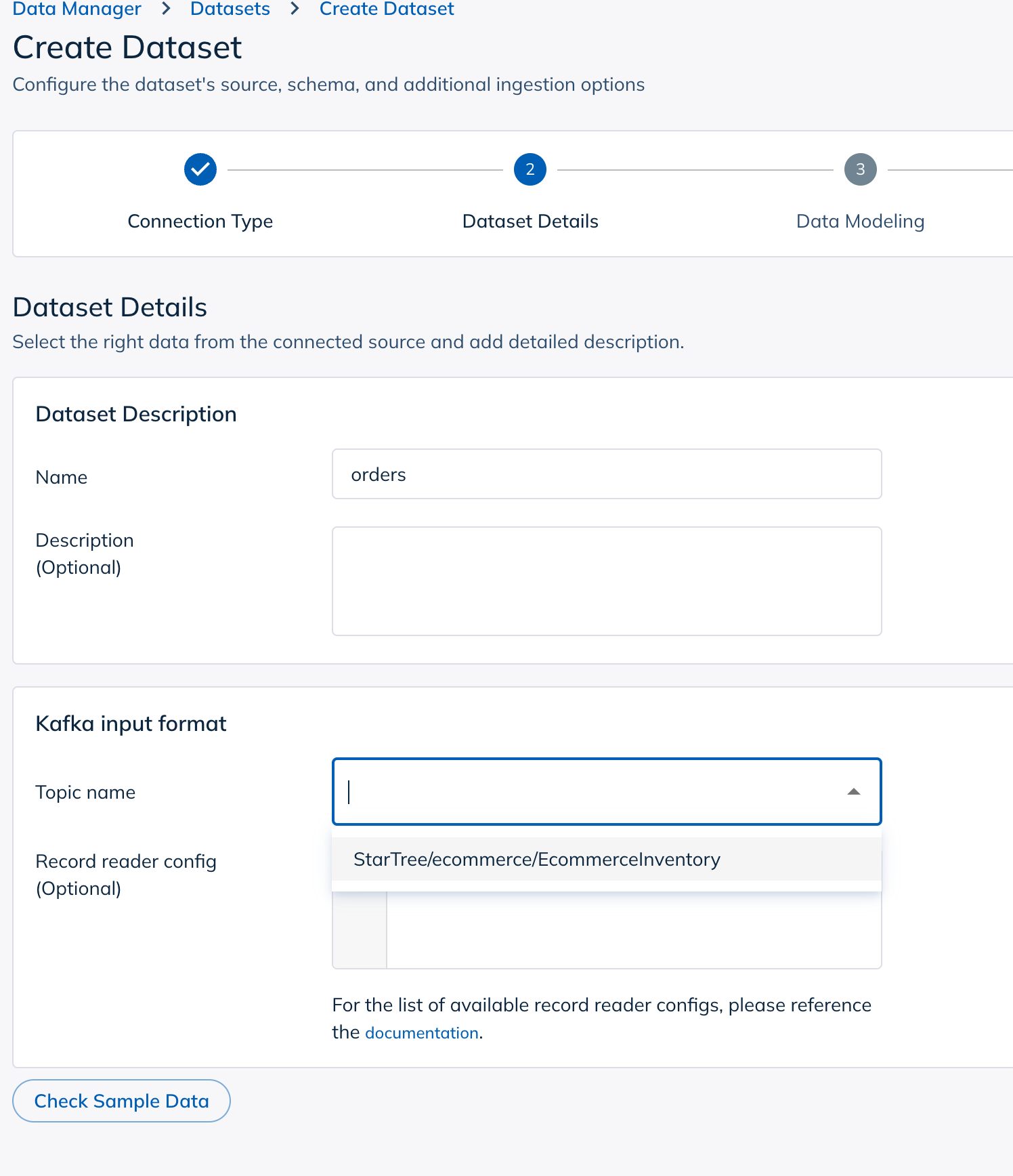
4. Select the topic
- Click “Next” after configuring the connection.
- StarTree will retrieve available topics from Dekaf.
- Select the topic corresponding to your Estuary capture (e.g., EcommerceInventory).
5. Define the schema and transformations
- Map incoming fields to your StarTree schema.
- Add any necessary transformations or calculated fields.
- Review and adjust field data types as needed.
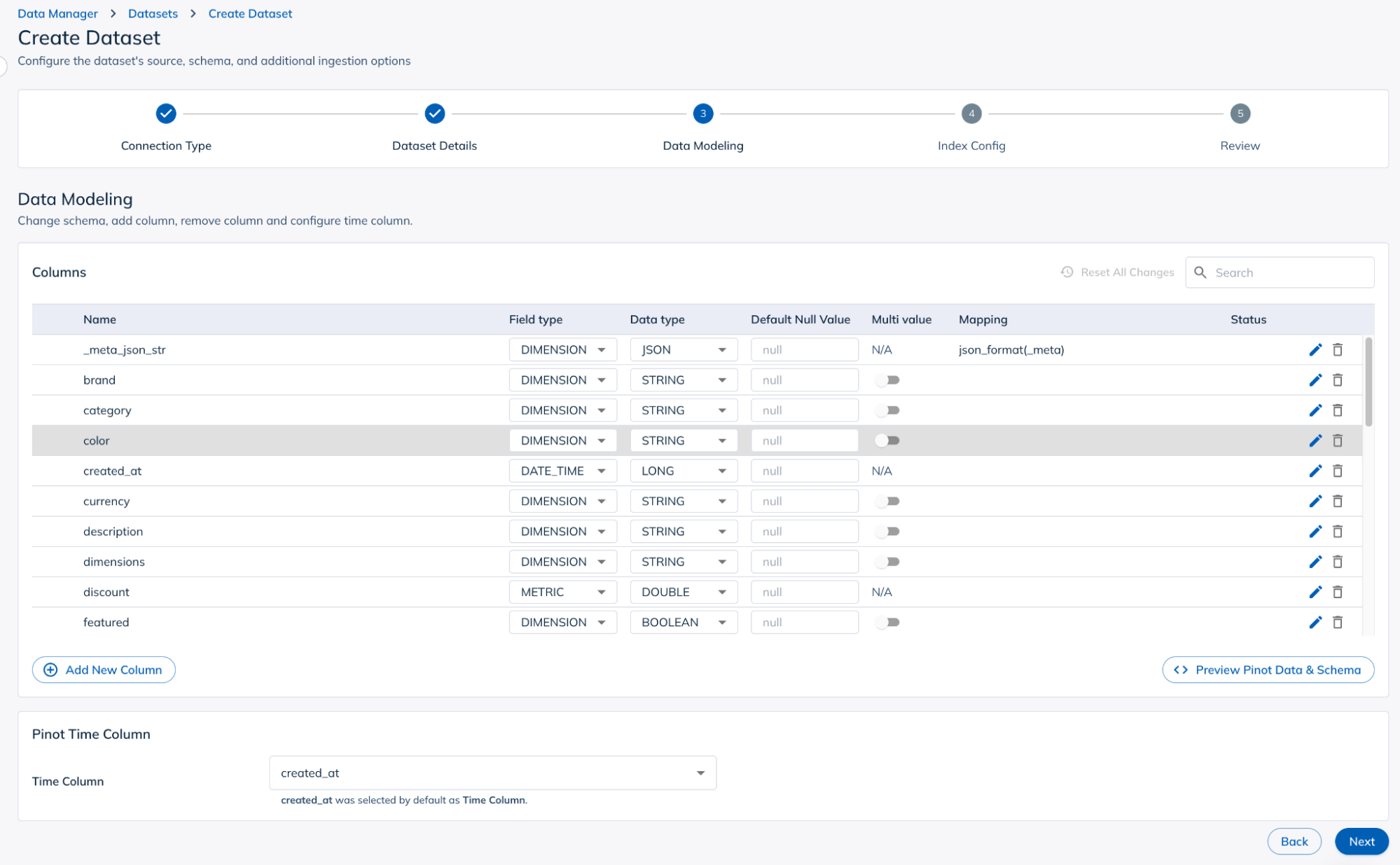
6. Configure indexes
Choose indexes that best suit your data and query patterns to optimize performance. StarTree offers a variety of indexing options designed to deliver sub-second response times across a wide range of workloads and datasets.
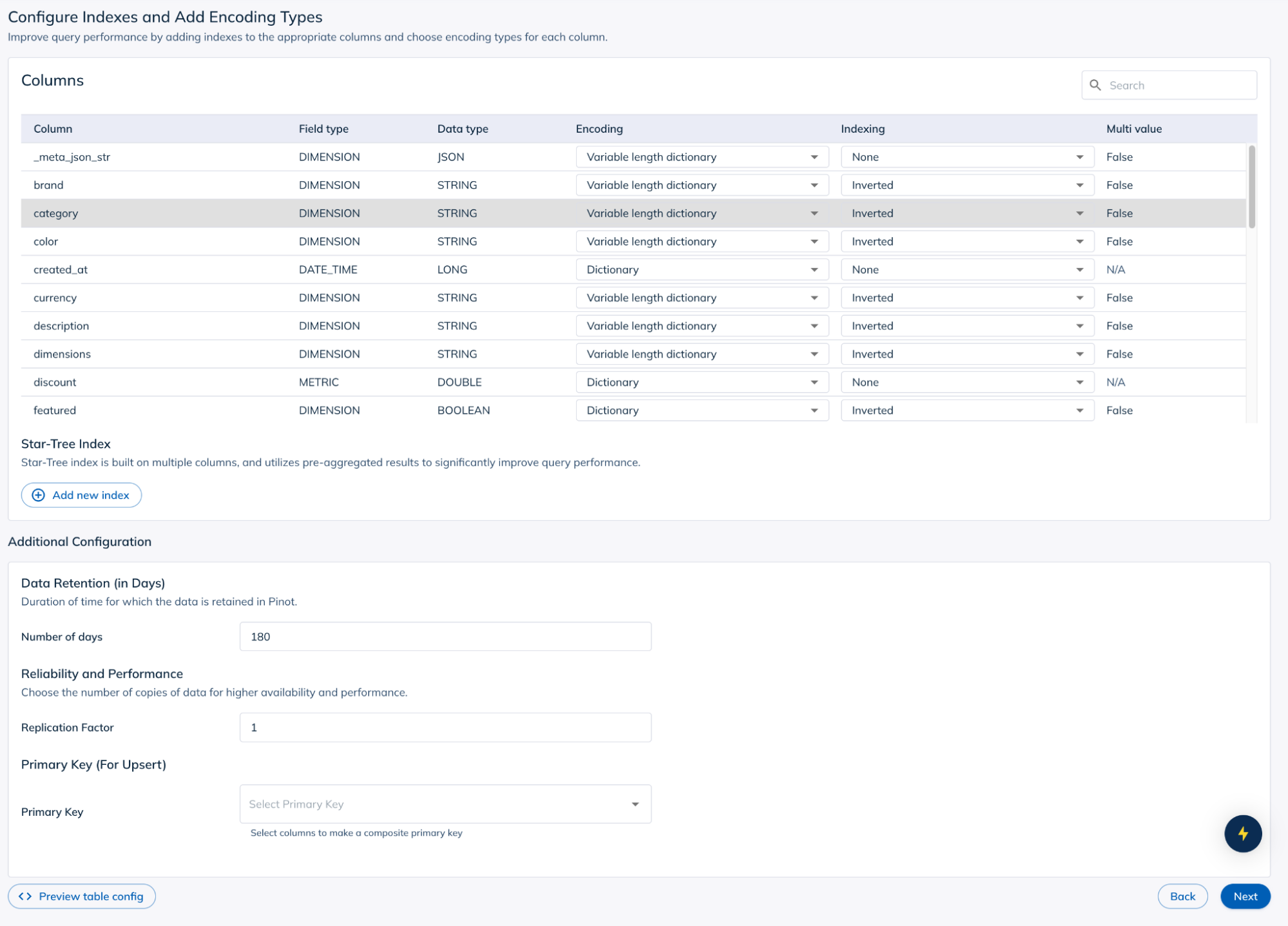
7. Complete the data source setup
- Review all settings.
- Click “Create Data Source”.
- StarTree will begin ingesting data from Estuary Dekaf.
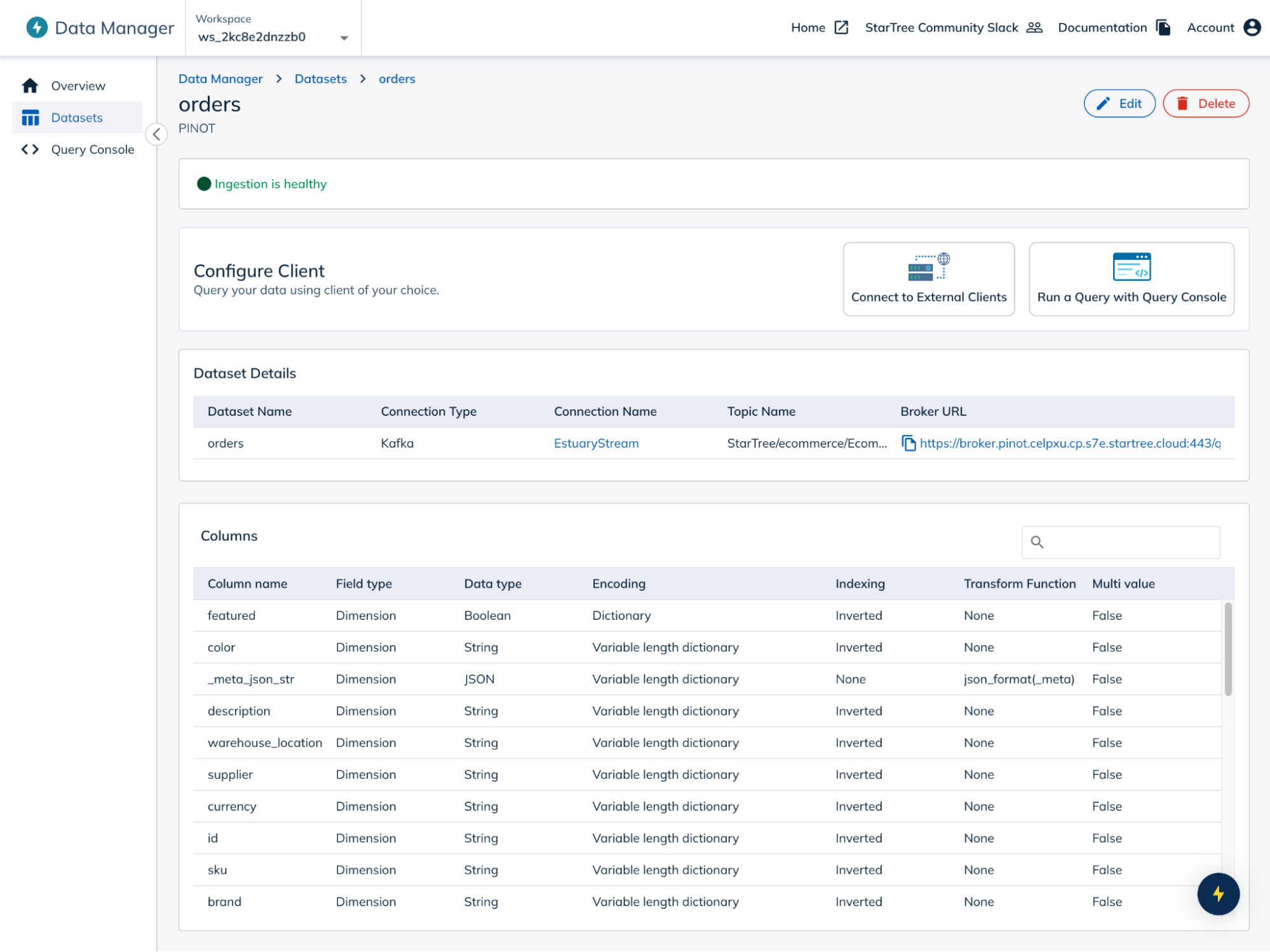
8. Verify data ingestion
- In “Data Manager”, check the status of your data source.
- Ensure the ingestion status is “Healthy” or “Active”.
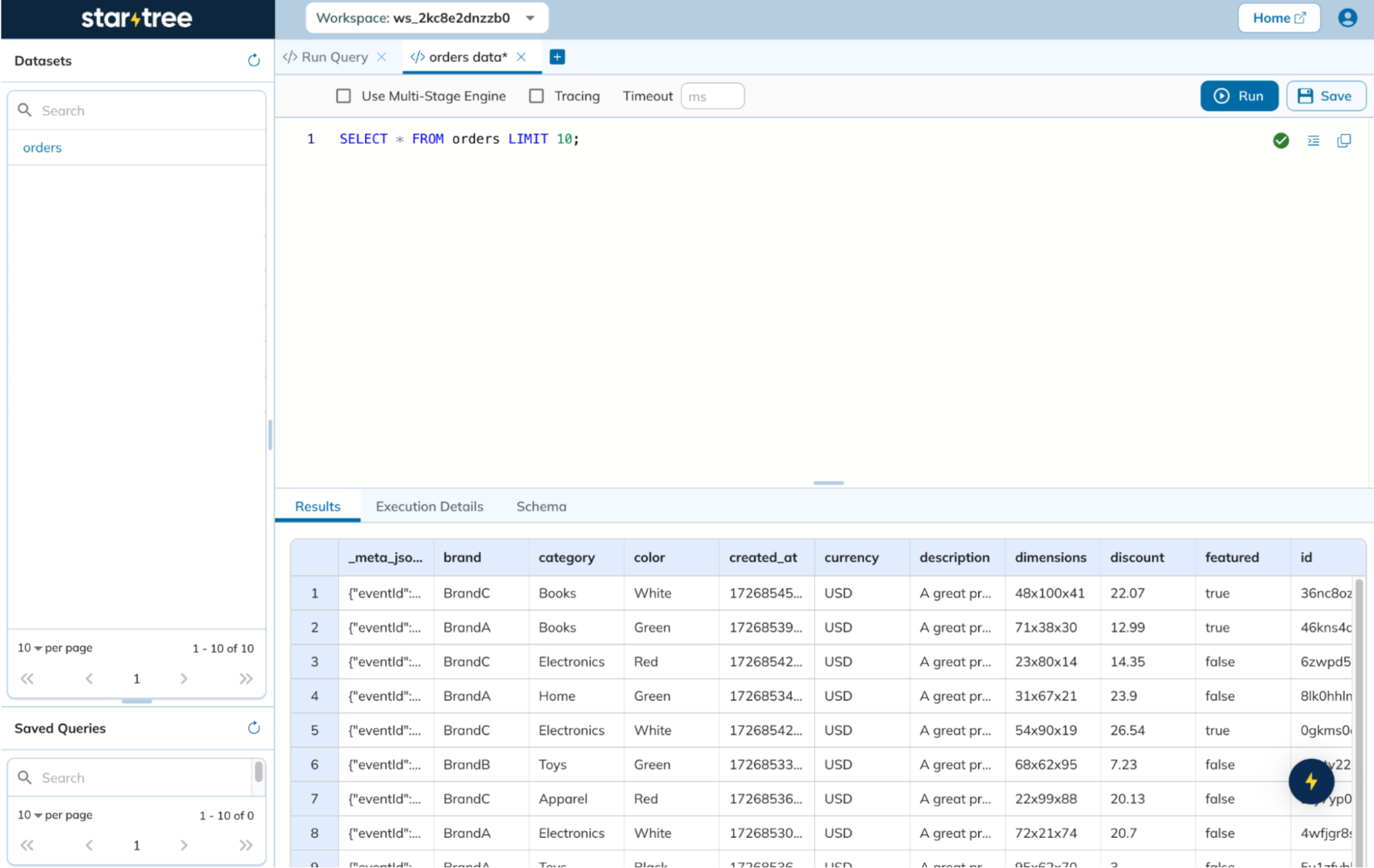
9. Query the data
Navigate to the “Query Console” in StarTree Cloud.Run sample SQL queries to verify data ingestion and query functionality.
10. Connect external applications (optional)
Go to “Connect External Clients”, Use provided REST endpoints or JDBC connections or choose to Integrate tools like Apache Superset for data visualization.
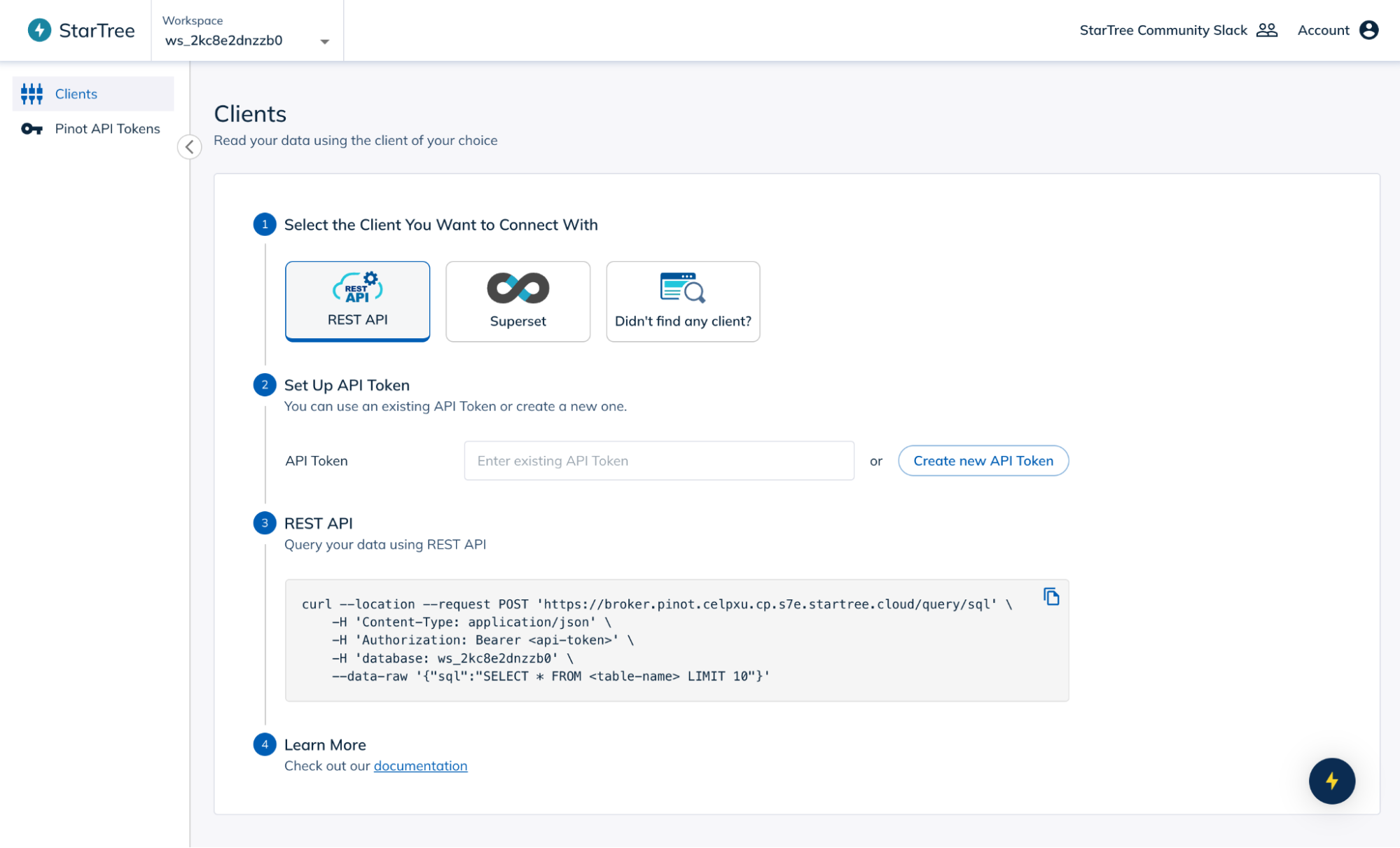
You’re all set!
You’ve successfully integrated your DynamoDB table with StarTree Cloud using Estuary Flow’s Dekaf endpoint. You can now build powerful, real-time analytics applications on top of this data pipeline.
Integrating Estuary Flow with StarTree Cloud offers a streamlined and efficient pathway to harnessing real-time analytics. By simplifying the data pipeline—eliminating unnecessary components and leveraging Estuary’s Dekaf endpoint—you can ingest data from DynamoDB and over 150 other sources with ease. Powered by Apache Pinot, StarTree enables sub-second query responses, allowing you to build robust, user-facing analytics applications that scale with your business needs. This integration not only reduces complexity and costs but also accelerates your ability to derive actionable insights.
For more information, check out the official Dekaf launch announcement on the Estuary blog and the integration docs page.