
In this blog post, we’re going to explore an exciting new world of real-time analytics based on combining the popular CDC tool, Debezium, with the real-time OLAP datastore, Apache Pinot.
Self-service analytics
Self-service analytics is a term that I came up with to describe building analytics applications using CDC (change data capture) instead of having to integrate directly with operational datastores. The problem here for organizations is that as the business scales, so too does the complexity in the number of applications and databases. By adding new features to applications, the only way to build faster is to decentralize control over the infrastructure and application architectures so that self-service teams waste less time waiting on other teams.
Debezium
Debezium is an open source project sponsored by RedHat that focuses on making CDC as simple and as accessible as possible. From the Debezium website:
Debezium is an open source distributed platform for change data capture. Start it up, point it at your databases, and your apps can start responding to all of the inserts, updates, and deletes that other apps commit to your databases.
There’s no marketing going on in the statement above — because this is precisely what Debezium does, and it does it quite well. At first glance, it can be like eating an elephant in a single bite, but the basics of Debezium are fairly straightforward. I find that the first barrier to entry with CDC use cases, for microservices specifically, is that the patterns and practices are sound but the use cases are not entirely well understood.
Here are three of the most valuable use cases that I’ve identified so far. There are certainly more, but these are the least specific ones with a wide range of applications for microservice architectures.
- Change data analytics (simple audit)
- Event sourcing (query a master view of distributed domain data)
- Internal/external dashboards (transform domain data into analytical insights)
In this blog post, I’m going to discuss the first two points above and then dive into an open source example.
Change data analytics
Distributed systems can routinely require a lot of coordination between teams to make sure that data inconsistencies do not leave a customer or user of an application in a state of “internal server error” limbo. If you’ve ever been the victim of a strange technical support issue, for example, not being able to create a new online account for your cellular service because an old account had already used your phone number and e-mail — issues like this are enough to make your head spin.
The problem here is that a data inconsistency issue must be diagnosed at the database level since there isn’t good precedence for these kinds of “edge cases” for new microservice migrations. These kinds of issues may require you to go through multiple tiers of technical support representatives that can’t seem to figure out what’s going on. Eventually, they might tell you that a resolution is not possible without engineering support. That’s when a support engineer must debug the data inconsistencies tied to your phone number and/or e-mail address.
The example below is a change data event generated by Debezium for updating a customer record in a MySQL database for accounts.

In the change event example above, you can get an accurate understanding of what happened at the database level with a customer’s account. The problem is, you need a database of these changes to be able to query the log. By loading the change events into Apache Pinot using Debezium and Kafka, you’ll be able to query every database change for customer accounts in real-time.
Now, instead of having to go into each separate system of record to figure out where a data inconsistency exists, a support engineer simply needs to query all changes to any account tied to an email or phone number. This is valuable for being able to identify and prevent similar defects in the future and gives development teams a way to see beyond their own microservice’s datastore.
Event sourcing
What’s great about event sourcing is that it becomes a time machine for understanding the state of an application or feature at a specific point in the past. Version control systems are an excellent example of how event sourcing can be valuable from the perspective of an application feature.
The benefits you get from event sourcing should be weighed against the potential costs of additional application complexity. By using a tool like Debezium to capture change data events from your application’s database, event sourcing becomes much easier to scale across development teams, making sure developers don’t need to do the extra heavy lifting in their application’s source code.
When you’re ingesting your database’s change events into a sink that can reliably hold a log of every record change, those records can be rematerialized later on for new features and applications. By using an OLAP datastore like Apache Pinot, you can create event-sourced projections across an entire domain, joining records together across the boundary of different datastores. Pinot is the perfect tool for this because the large data volume for database change events is not well-suited to be queried by operational datastores or relational databases.
Querying Change Data with Pinot
Let’s picture for this example that Debezium streams change data events from multiple different databases of different formats — from NoSQL to RDBMS — into numerous Kafka topics that get ingested into Pinot. Doing something like this would typically not be very easy in practice, but both Debezium and Pinot decouple their respective responsibilities here by working tremendously well with Kafka.
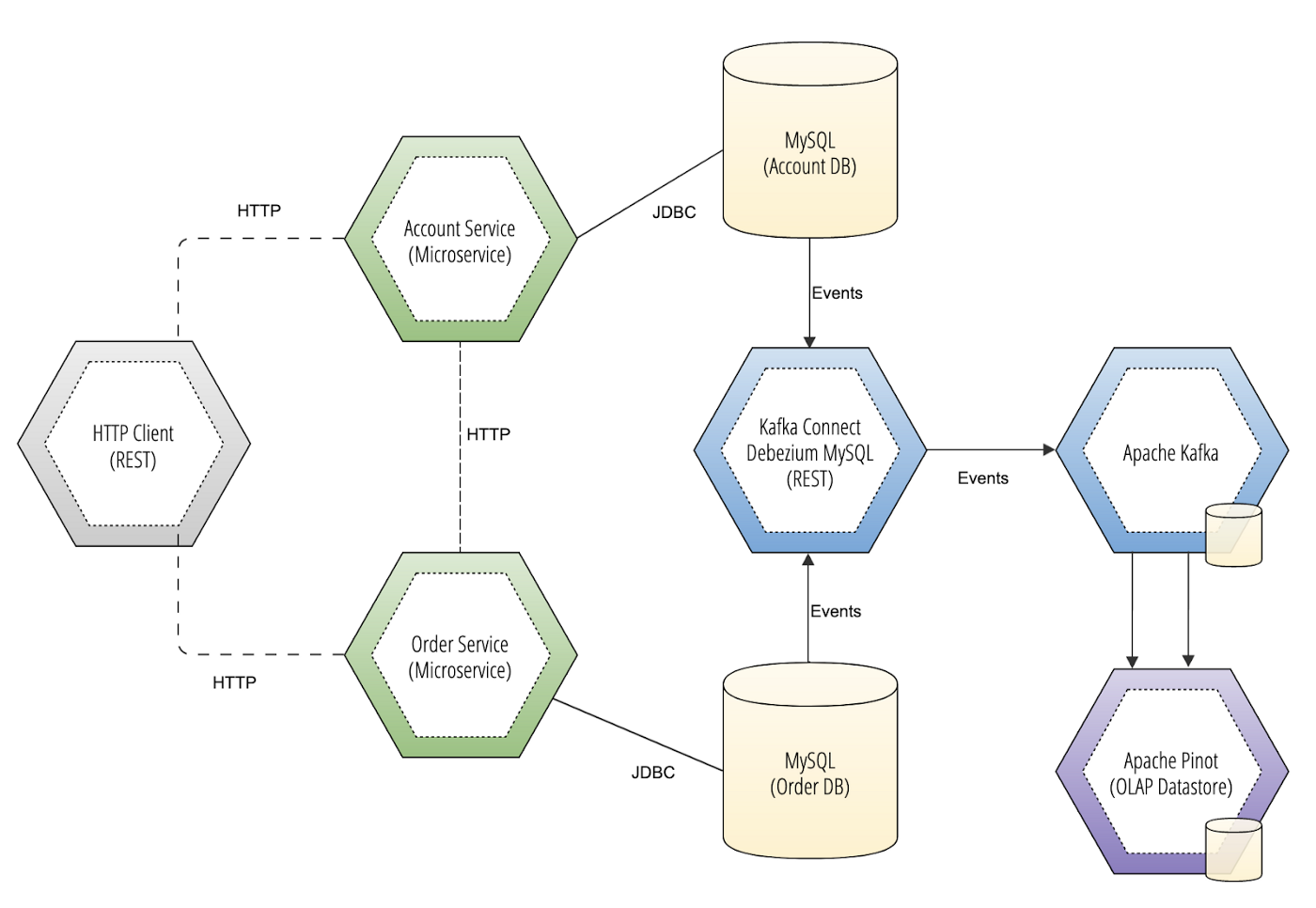
On both sides, you point to Kafka to replicate a queryable representation of change data events that give you a way to query database records in near real-time without ever needing to connect to a system of record.
Running the example
Now that we’ve talked about the reason why you would use Debezium and Pinot together for a variety of use cases, let’s spin up a working example. The example I’ll focus on is a simplified microservice architecture from the example I mentioned earlier.
The key focus of this starter exercise is to understand how simple it is to move change data events from MySQL to Pinot using Debezium and Kafka Connect. The GitHub repository for this exercise can be found here.
First, start up the Docker compose recipe. The compose file contains multiple containers, including Apache Pinot and MySQL, in addition to Apache Kafka and Zookeeper. Debezium also has a connector service that manages configurations for the different connectors that you plan to use for a variety of different databases. In this example we use MySQL.
$ docker-compose up
Run the following command in a different terminal tab after you’ve verified that all of the containers are started and warmed up. You can verify the state of the cluster by navigating to Apache Pinot’s cluster manager at http://localhost:9000.
$ sh ./bootstrap.sh
Now, check out the Pinot query console (http://localhost:9000/#/query) and run the following SQL command (you can get the SQL query from the GitHub repository).
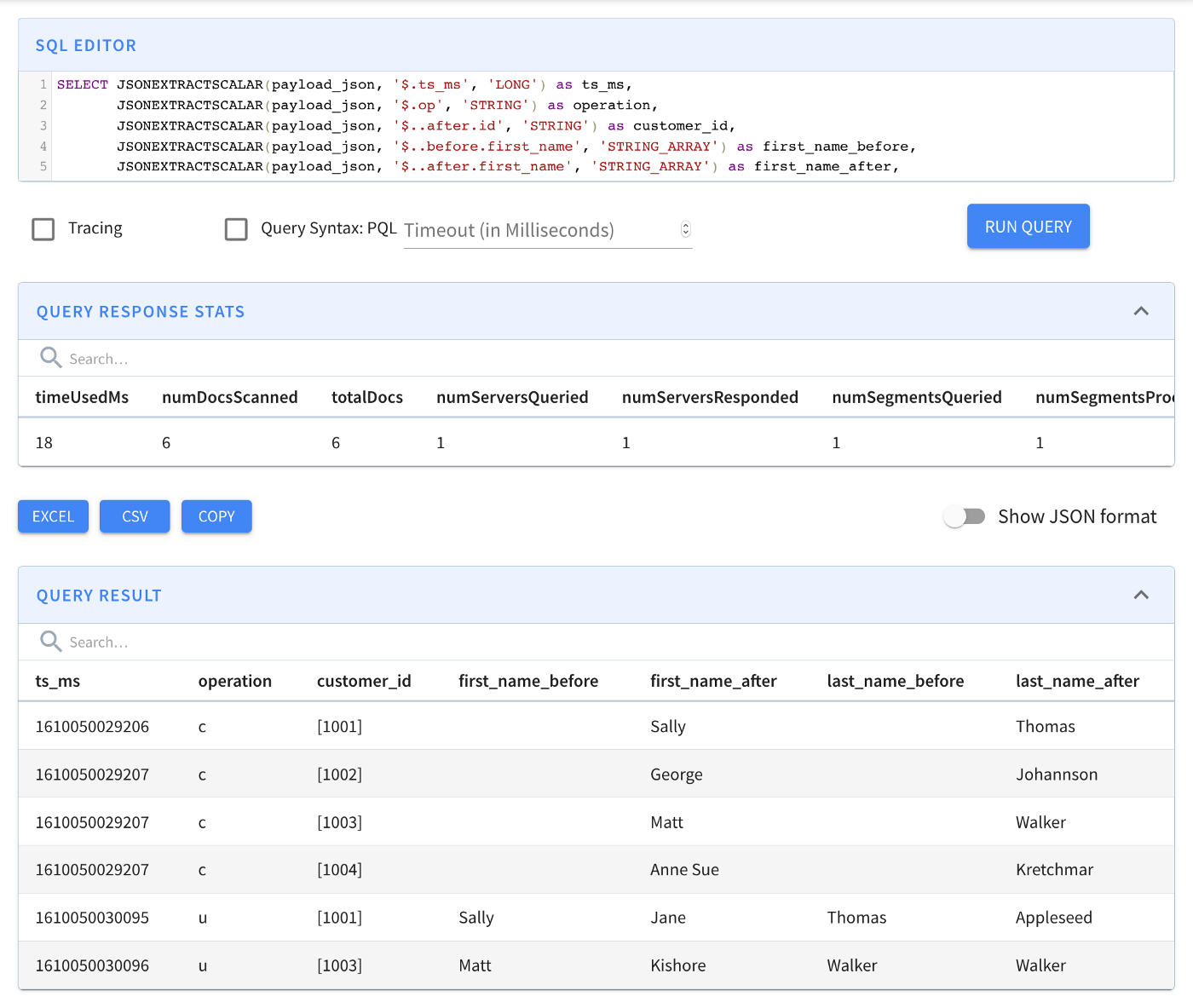
In the results shown in the image above, you can see a list of database record changes for a customer’s first and last name. The second column is the type of operation, which in this example, is either created or updated. Then we have the customer’s id followed by the before and after state of the customer’s first and last name.
Conclusion
Apache Pinot and Debezium are examples of two great open source tools that work together seamlessly to solve a variety of challenging use cases. This blog post is what I hope to be a first in a series of articles that dive deeper into the use cases that I mentioned earlier.
If you have any comments or questions, please drop your thoughts below, or join Apache Pinot’s community Slack channel.
More Resources:
- See our upcoming events: https://www.meetup.com/apache-pinot
- Follow us on Twitter: https://twitter.com/startreedata
- Subscribe to our YouTube channel: https://www.youtube.com/startreedata
