
A while back, I was brought in to help with a large company with performance related to a database. Someone in the company had created a table based on ingesting data from an API. The table had grown very large, and the queries did not perform well. It turns out that the table was created with zero keys and/or indexes. Zero. Zilch. Fortunately, we resolved the issue with the addition of some indexes. The query that used to take several minutes to run now takes 1-2 seconds. Problem solved!
This extreme example shows why indexes matter, especially when dealing with large datasets, and Apache Pinot™ offers a variety of them.
What Is a Database Index?
A database index is a data structure that enhances the speed and efficiency of data retrieval operations in a database system. It acts as a roadmap or a quick reference guide, allowing the database management system (DBMS) to locate data more rapidly.
Why Is Indexing Used in a Database?
Primarily, an index speeds up data retrieval. By creating an index on one or more columns of a table, the database can locate specific data much faster than scanning the entire table. It works similarly to an index in a book, where you can quickly find relevant information by referring to the index rather than flipping through the entire book.
If you needed to find a particular sentence in a book without an index, you would have to read the book in its entirety, page-by-page, line-by-line, until you found the relevant sentence. And then you still have to scan the whole book anyway just to check if that exact sentence might have occurred anywhere else. This is what a database without an index is like, except with databases, we never look for only one sentence. The method for reading everything in a database until you find what you’re looking for is called a table scan , and it’s not very efficient. Reading the index and going directly to the page with the desired information reduces the number of pages you need to read.
For high-performance OLAP (online analytical processing), databases such as Pinot indexes play an essential part in data retrieval. This, in part, explains why Pinot supports a variety of index types and has created some new indexing paradigms, which we’ll explore in more detail.
Index Structure
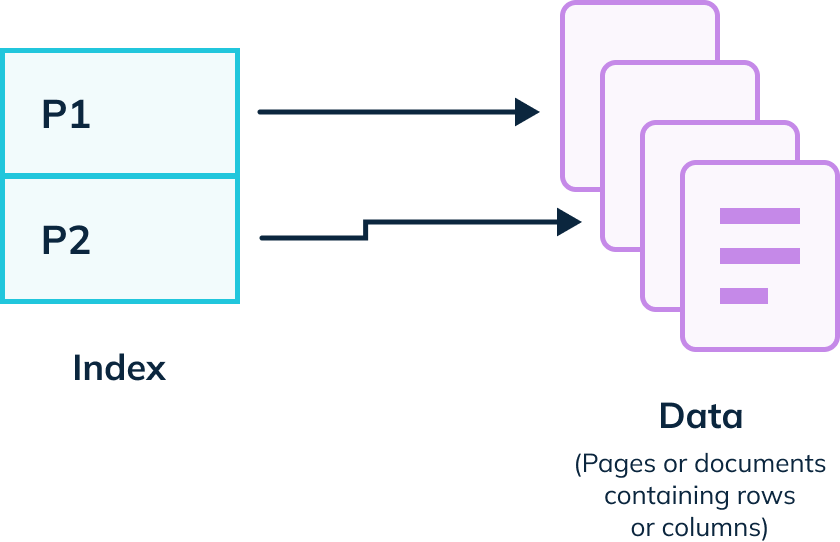
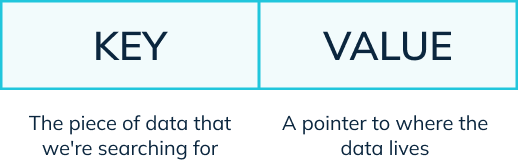
A database index is typically implemented as a separate data structure from the actual table. The index structure consists of one or more columns (or expressions) from the table and their corresponding sorted values. Each entry in the index contains a key value and a pointer to the actual location of the data in the table.
In reality, the structure proves more complex, resembling more of a tree. Regardless, we want to avoid table scans and shorten the time it takes to get to the page that we want to access.
Types of Indexing
Utilizing different index types as appropriate will help you find what you’re looking for most effectively because each one optimizes for varying conditions.
One way to look at different types of indexes is through how something is searched. Let’s look at some techniques.
Tree, Hash, and Bitmaps
Tree Indexes
While Key-Value pairs make sense, sometimes finding a key in a large dataset itself becomes complicated. Trees solve this problem by chunking groups into tree structures, thus reducing the hops needed to find any leaf node. This is especially useful in equality or range searches.
An equality search follows the pattern select x where field1=20.
A range search follows the pattern select x where field1 between 15 and 25.
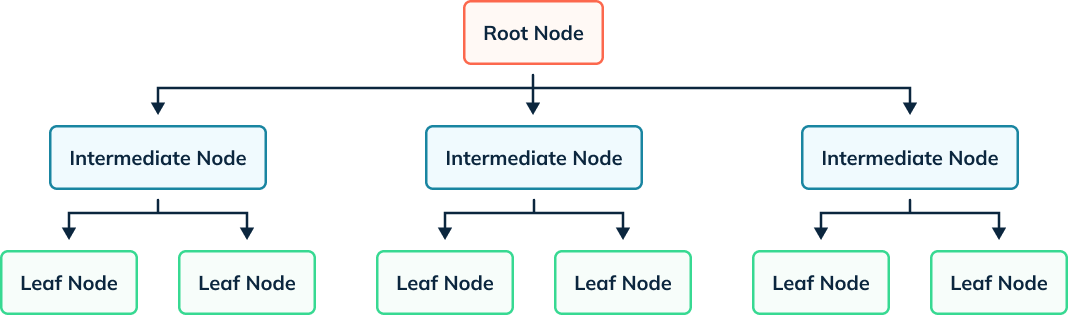
Most Pinot Indexes can be seen as tree-type Indexes. The exceptions would be Bloom Filter and Bitmap Inverted Index.
Hash Index
A hash index uses a hash function to map the index keys to specific locations in the index structure. It works well for equality-based searches but not for range queries. Hash indexes are faster than Tree indexes for exact matches but do not perform well with partial matches or ordered retrieval.
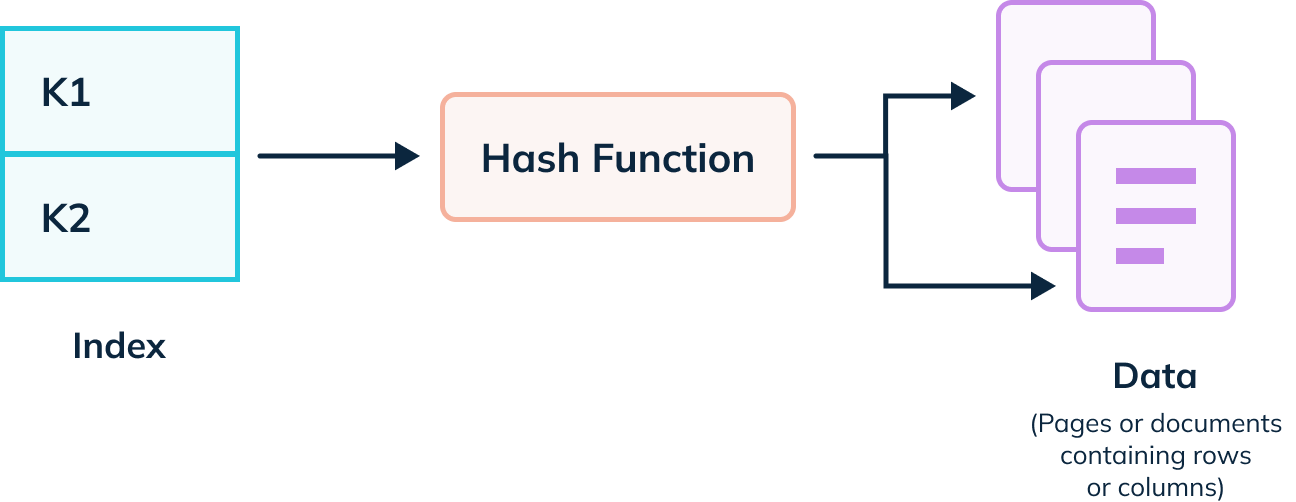
Pinot implements a Bloom filter. While this is not a hash index, it uses a function to filter out segments that do not contain the value being searched.
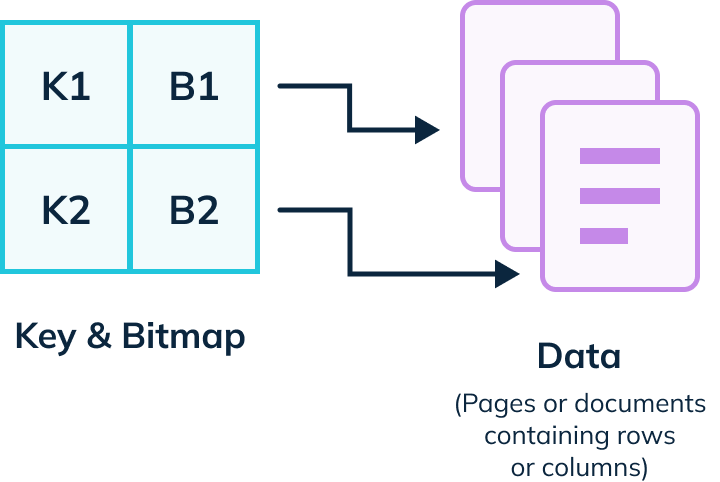
Bitmap Index
A bitmap index represents the values of the indexed column(s) as a bitmap for each distinct value. It works effectively for low-cardinality columns (columns with few distinct values) and enables fast operations for Boolean queries. Bitmap indexes are commonly used in data warehousing scenarios.
Pinot implements a Bitmap inverted index, described later in this blog.
Clustered vs. Non-clustered.
One way to view indexing is from the lens of how the data is structured. Clustered vs. Non-clustered is one example of it.
Clustered Index
Unlike other indexes, a clustered index does not exist as a separate data structure but orders the actual data stored in the database. A clustered index determines the physical order of data in a table. Each table can have only one clustered index. The leaf nodes of the clustered index contain the actual data, making it optimal for retrieving entire rows. Clustered indexes prove particularly useful for range-based queries.
In Apache Pinot, you have the option to explicitly specify a sorted column for real-time tables. This is the closest to a Clustered Index in the Pinot platform.
Non-Clustered Index
A non-clustered index functions as a separate structure from the table that contains the indexed columns and their values. Non-clustered indexes have their own leaf nodes, which contain the index key values and pointers to the actual data rows. They improve search performance for specific columns but do not determine the physical order of the data. All Pinot indexes other than Sorted Index are non-Clustered.
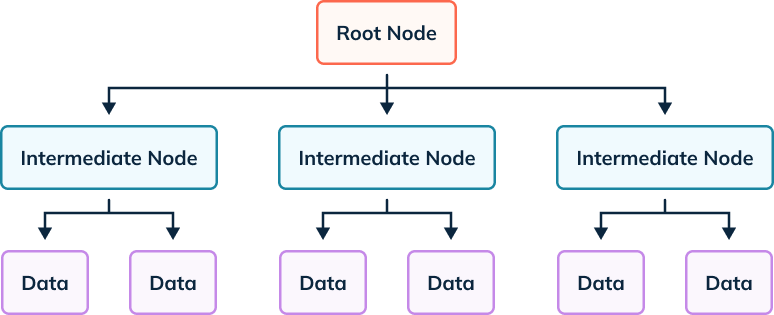
Pinot Index types
Now that we have a general idea of how indexes work let’s look at how Pinot implements indexes. One of the optimizations of Pinot is the distributed nature of both compute and file systems. What follows is a set of indexes that Pinot implements and what is the secret sauce of why Pinot is capable of low latency and high query performance even with highly concurrent workloads.
Forward Index
A forward index lists values per page or document, similar to a table of contents or a DNS table. Constructing a forward index scans each page or document and collects all related values listed on that page.
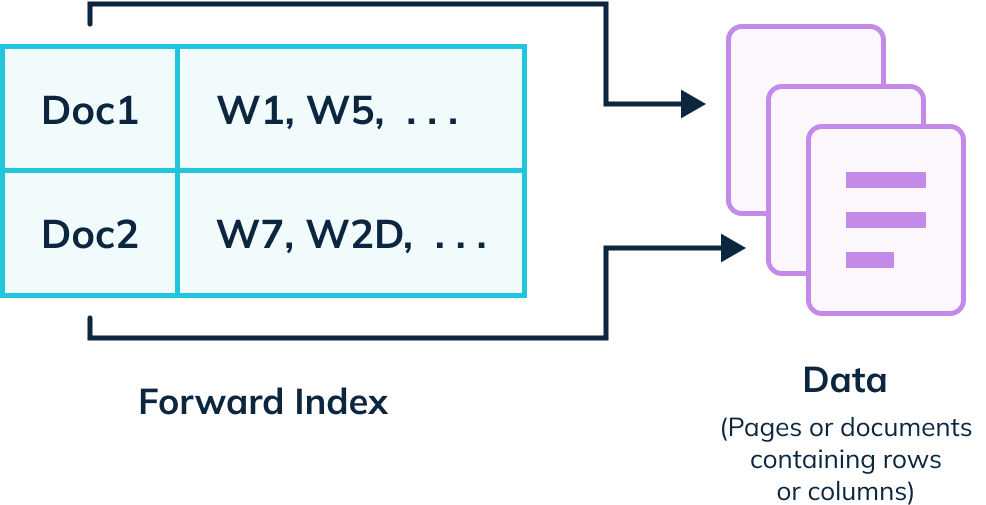
Apache Pinot supports three kinds of forward indexes:
- Dictionary-encoded forward index: Each unique value from a column gets assigned an ID, producing a dictionary that maps the ID to the value. The forward index stores bit-compress IDs instead of the values
- Sorted forward index: This builds a dictionary mapping from each unique value to a pair of start and end document IDs and a forward index on top of the dictionary encoding
- Raw value forward index: This is the traditional forward index, where Apache Pinot builds a forward index of the column’s values
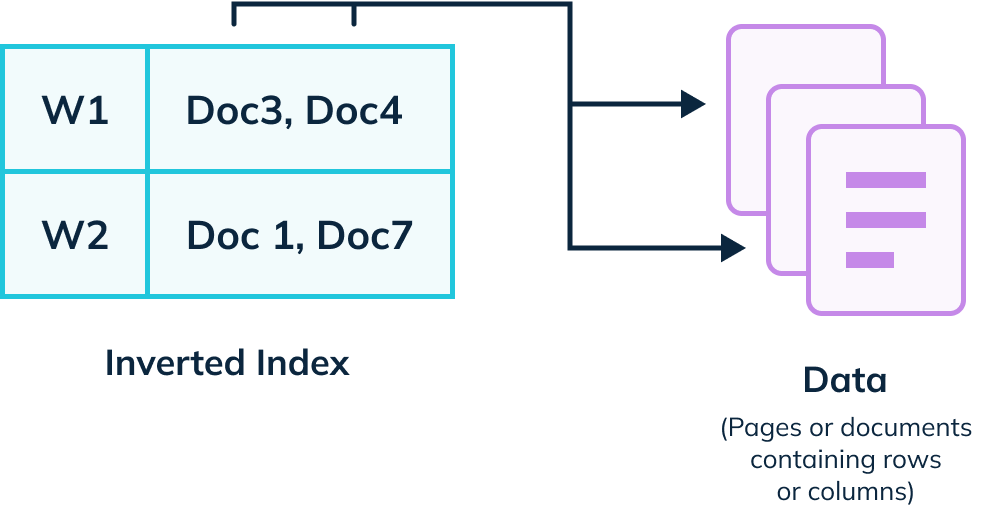
Inverted Index
An inverted index is a data structure that stores mapping from values to documents or sets of documents i.e., directs you from the value to the document.
Pinot maintains a map from each value to a bitmap of rows, which makes value lookup take constant time. If you have a column frequently used for filtering, adding an inverted index will improve performance greatly. You can create an inverted index on a multi-value column.
Sorted Inverted Index
Pinot supports a sorted inverted index, where instead of storing each doc, Pinot stores start and end document IDs, thus reducing the index size. A sorted index performs much better than an inverted index, but it can only apply to one column per table.
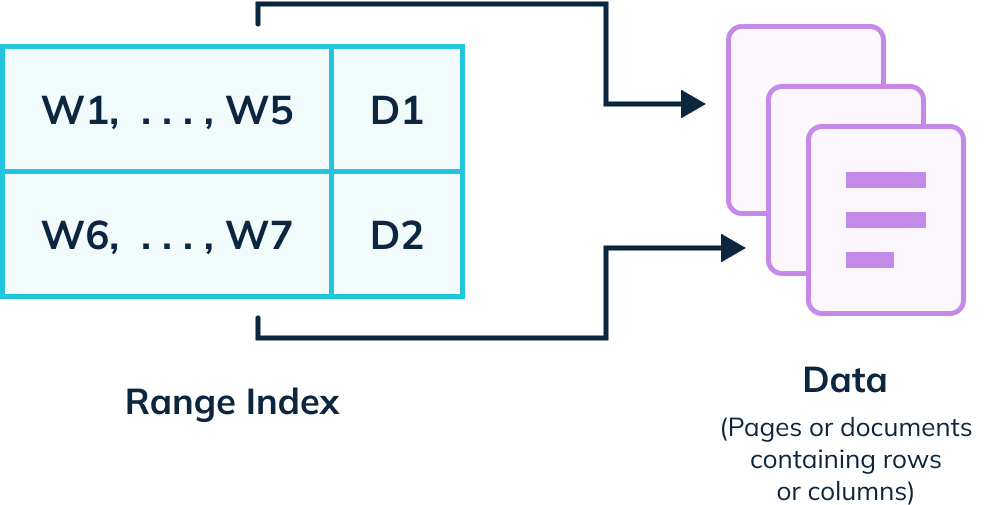
Range Index
Another type of inverted index, range indexing, allows you to get better performance for queries that involve filtering over a range.
Text Index
In traditional text search use cases, the majority of text searches belong to one of three patterns: prefix wildcard queries (like pino*), suffix wildcard queries (like *inot), and term queries (like Pinot).
In Pinot, native text indices are built from the ground up. They use a custom text-indexing engine, coupled with Pinot’s powerful inverted indices, to provide a fast text search experience.
JSON Index
JSON string can represent the array, map, or nested field without forcing a fixed schema. Its flexibility comes with a cost, though, as filtering on JSON string columns runs very expensive. The JSON index was designed to accelerate the filtering of JSON string columns without scanning and reconstructing all of the JSON objects.
Geospatial Index
In Pinot, you can use the geospatial index to optimize lookups based on geospatial data. This includes geospatial data types, such as point, line, and polygon; geospatial functions for querying spatial properties and relationships; and geospatial indexing, used to process spatial operations.
Timestamp Index
Pinot provides a timestamp index type for optimizing queries based on time series data. This data type stores value as a millisecond-long epoch value internally. Typically for analytics queries, you don’t need this low level of granularity, as scanning the data and time value conversion can result in costly implications given the big size of data. The time series index optimizes these queries.
Bloom Filter
A Bloom filter is a space-efficient probabilistic data structure that is used to test whether an element is a member of a set. IN Pinot, Bloom filter helps prune segments that do not contain any record matching an equality predicate.
Example:
Select count(*) from baseballStats where playerID = 12345
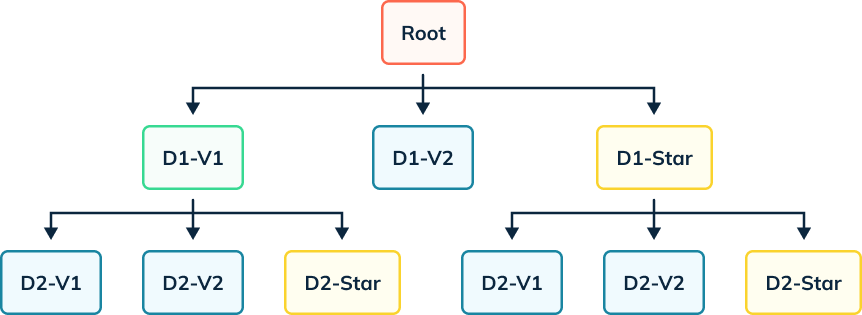
Star-tree Index
Unlike other index techniques that work on a single column, the star-tree index, built on multiple columns, utilizes pre-aggregated results to significantly reduce the number of values to process, resulting in improved query performance.
Unlike other OLAP databases, instead of pre-aggregating all of the data, the StarTree index only pre-aggregates parts of the data based on usage patterns. My colleague Sandeep Dabade has written a great series of articles that deep dive into the StarTree index if you’d like to learn more.
Indexing Trade-Offs and Considerations
As wonderful as indexes are, they don’t come without a few trade-offs.
Performance
Indexes improve read performance by reducing the number of disk accesses required to find data. However, they can slightly impact write performance as each modification to the table needs to update the associated index entries. Pinot overcomes this because it’s distributed, and each server maintains its subset of segments for write.
Storage Overhead
Indexes consume additional storage space as they create separate data structures. The amount of storage overhead depends on the size of the table, the number of indexed columns, and the index structure. Pinot uses compression to improve data storage usage.
Maintenance Overhead
Indexes require maintenance as table data changes. Frequent updates or insertions can impact the overall system performance due to the associated index maintenance operations. Once again, the distributed nature of Pinot minimizes some of this overhead.
Conclusion
As a crucial component for optimizing data retrieval operations, database indexes provide a way to quickly locate specific data in a table, thus enhancing query performance. Apache Pinot has created a robust real-time OLAP database that supports a variety of indexes to optimize any workload. If you would like to learn more, check out the quick start and join us on Slack for help with any questions that pop up along the way.
