Within Dialpad, the Data Platform Team is responsible for creating features that developers can build off of with ease. Their broad charter requires them to take care of how and where data is stored, how it’s formatted, and who has access. While this involves a lot of traditional data engineering tasks, it also includes policy-level aspects such as governance and compliance, as well as deeply technical aspects such as distributed systems and database engineering.
Their responsibilities span answering to both internal and external customers. Within Dialpad, their primary focus is supporting the data science teams in the AI organization using the platform for machine learning, model training for natural language processing (NLP), as well as labeling and annotating data.
For external customers, consider the case of Dialpad’s Ai Contact Center, which is their Call Center as a Service offering. The managers of customer call centers have dashboards and charts pulling metrics directly from the Dialpad data platform.
The platform also provides AI-generated scorecards for every customer conversation, so managers can easily coach their sellers and support agents. All of these are available to the manager in an Ai Coaching Hub, which can help in onboarding new agents and build better customer experiences.
Dialpad proactively surfaces real-time insights for call center managers such as queue times, handle times and hold times. This allows for down-to-the-minute decision-making for how to reassign and repurpose agents. AI-powered live sentiment analysis powers management dashboards that can also show which agents may need immediate assistance or intervention handling problematic situations. A really popular capability right now in Dialpad is coachability — finding coachable moments in calls, and finding the agents that require the most coaching.
Another body of data revolves around customer satisfaction, which can be submitted as scorecards by the customers themselves as well as scored by AI. For example in human psychology most customers bias towards rating their experience at the extreme ends of satisfaction and dissatisfaction — a bimodal distribution. Neutral experiences hardly ever trigger a customer satisfaction survey result. To drill deeper, Dialpad uses its own AI customer satisfaction (CSAT) system to look deeper into interactions and infer its own scoring.
The Challenge: Real-Time Call Center Management
Dialpad was using another closed-source, proprietary database to handle much of the work focused on data warehousing connected to Google Pub/Sub. However this system was not adequate for the task of real-time, user-facing analytics — ingesting streaming data, dealing with rapid changes and creating results all within sub-second latencies. It was designed to provide internal insights into data, but was unsuitable to supporting an unbounded number of external customer queries on top of that.
Performance suffered as the result of the volume of queries. Even establishing a hard cap on the number of queries — 100 QPS — did not resolve the issue. Queries regularly exhibited P95 latencies exceeding 30 seconds, and sometimes over a minute. This was far too slow for the real-time conditions of call center management, and not scalable to the high query concurrency of user-facing analytics. This intrinsically limited Dialpad’s ability to create new products and features that relied on real-time metrics.
Solution: An End-to-End Real-Time Analytics Architecture
Dialpad required four core capabilities in any replacement system:
- Focus on streaming data
- Support for upserts
- Flexible indexing capabilities
- Open source core backed a strong sponsoring company
The focus on streaming data and the need for upserts were necessities for real-time management of call centers, agents, and all relevant information about their customers and their needs. Flexible indexing was also a strong requirement due to the multivariate ways Dialpad needs to analyze data. The last point was a philosophical stance of the company to support open source, and to support the vendor standing behind it.
Dialpad turned to StarTree Cloud, powered by Apache Pinot, which was designed specifically for the scale and speeds required by these kinds of use cases. As well, Dialpad implemented Confluent Cloud for fast and scalable data streaming. Confluent was easy to get started with and worked out of the box. The Dialpad team was especially impressed by the strong support by Confluent for its Terraform provider which helped them get off the ground quickly.
Combining the power of StarTree Cloud and Confluent Cloud provided Dialpad with an end-to-end solution perfect for producing data insights from their customer engagement platform. Heavily weighing in the decision was the ease-of-deployment for both StarTree and Confluent on Google Cloud. StarTree makes this easy with a Bring Your Own Cloud (BYOC) deployment option.
Dialpad still uses Google Pub/Sub to ingest streams of events from an array of distinct producers, including the tens of thousands of live agents using the Dialpad app. From there, Dialpad takes data for live analytics through Google Dataflow, and, using Apache Beam, populates data into topics in Confluent. Confluent then passes data into StarTree Cloud. The new architecture has reduced average end-to-end ingestion latencies from over one minute down to an average of 500 ms, down to as low as 10 ms, greatly improving data freshness. While there are still cases where data can take 30-60 seconds for ingestion, these are situations where Dialpad is intentionally waiting to deduplicate and denoise events — resulting in higher data quality. As well, Beam performs enrichment and pre-materialization of select columns, rather than performing query-time computation.
Dialpad is using the partial upsert functionality of Apache Pinot because data is incomplete at first as it populates into StarTree Cloud. Over time subsequent upserts fill in the blanks by adding in additional columns as data becomes available. Dialpad also uses the offlines table feature of Apache Pinot to ingest data from the data warehouse to combine with the live stream data in a hybrid table for a complete picture of customer call center activity.
Dialpad also uses a number of indexing capabilities within Apache Pinot: full-text search based on the embedded Apache Lucene engine, JSON indexing, and range indexing.
For future use cases the Dialpad Data Platform Team is also interested in timestamp indexes, because so much of their data is time-series oriented, related to calls and meetings. They are also looking at the star-tree index unique to Apache Pinot, because that can help quickly narrow down the result sets they need to analyze. Dialpad already plans to expand their existing datasets, add new datasets, plus expand the range of queries and use cases they support.
Dialpad has a deep commitment to open source — and in particular Apache Pinot — not just as a user or consumer, but as a contributing organization. In the words of Engineering Manager Evan Galpin, “That’s one of the great things about open source. You have that opportunity to own your own destiny from that perspective. We are an atypical use case and we have added some features to help support that. We have the multiple producer groups all producing part of the row, and we added this feature to the multiple comparison column so that we can keep all of those ordered correctly even though they are distinct from one other. Without open source we’d be one company out of thousands. A vendor could say, ‘Yeah, that’s low priority, because we don’t need it for everyone.’ But because it’s open source we can do it.”
Discover the Power of StarTree Cloud and Confluent Cloud
If you believe your own use case bears more than a passing resemblance to Dialpad’s, you are not alone. There is a growing movement in the industry to offload data warehouse systems and move analytical workloads to designed-for-purpose real-time OLAP databases.
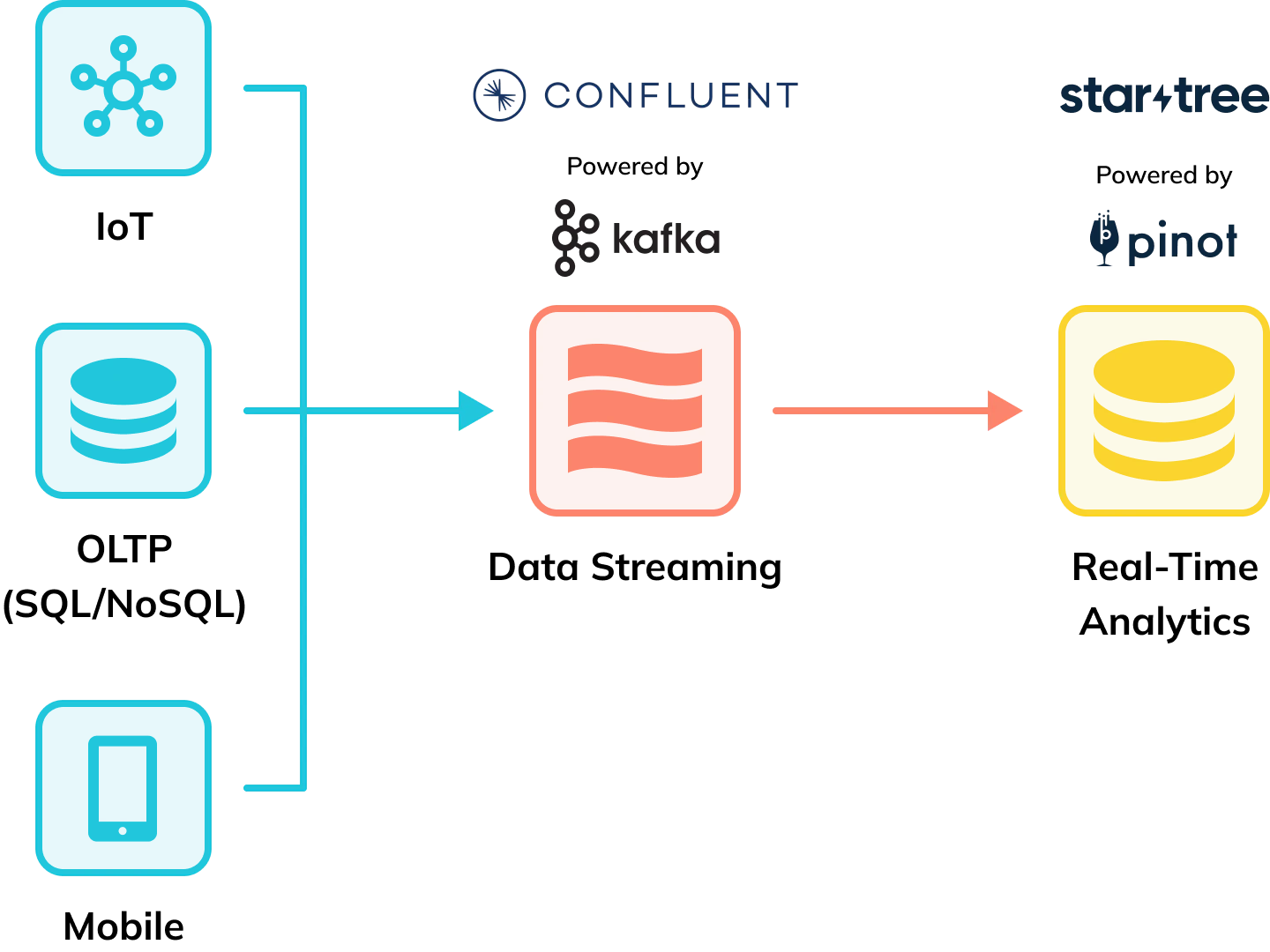
This is where StarTree Cloud shines. It is built for real-time, user-facing analytics — allowing sub-second queries with high concurrency against even petabyte-scale data. Plus, the easiest and most reliable way to interconnect such systems is with a fully-managed data streaming solution like Confluent Cloud.
Whether your data sources are IoT enabled devices, SQL or NoSQL databases, web apps, mobile devices, or other end-points, you can flow it all into Confluent topics, which can then be immediately ingested and indexed in StarTree Cloud. You can also combine the power of real-time data with data found in your data warehouses to create hybrid tables, such as by using our Delta Lake connector.
| If you are interested in powering your business, learn more about the partnership between Confluent and StarTree. | If you are interested in understanding the underlying technology, learn more about combining Apache Kafka and Apache Pinot. |
Try Apache Pinot on StarTree Cloud
The quickest way to experience the power of Apache Pinot is with StarTree Cloud. Request a Trial to get started with a no-commitment trial account to explore and test. When you’re ready to move into production, you can move into one of our cost-effective packages just right for your business.
