
We are excited to announce the release this week of Apache Pinot 0.9. Apache Pinot is a real-time distributed datastore designed to answer OLAP queries with high throughput and low latency.
This release is cut from commit 13c9ee9556498bb6dc4ab60734743edb8b89773c and contains the segment merge and roll up task, improvements to the Query Console UI, new SQL functions, as well as bug fixes and performance improvements. You can find a full list of everything included in the release notes.
Let’s have a look at some of the changes, with the help of the batch, realtime, and hybrid QuickStart configurations.
Segment Merge and Roll-up
Seunghyun Lee and Jiapeng Tao operate a large multi-tenant cluster at LinkedIn that serves a business metrics dashboard and noticed that their tables consisted of millions of small segments. This was leading to slow operations in Helix/Zookeeper, long running queries due to having too many tasks to process, as well as using more space because of a lack of compression.
To solve this problem they added the Segment Merge task, which compresses segments based on timestamps and rolls up/aggregates older data. The task can be run on a schedule or triggered manually via the Pinot REST API.
At the moment this feature is only available for offline tables but will be added for real-time tables in a future release. You can also watch a meetup presentation where Seunghyun and Jiapeng explain this feature in more detail.
Query Console UI
This release also sees improvements to Pinot’s query console UI.
Hristo Stoyanov made the SQL editor box expandable, Sanket Shah added tooltips, and Priyenbhai Patel made it possible to execute a query by pressing Cmd + Enter. You can see the changes in the animation below:
New SQL functions
Yupeng Fu added the IN function, which returns a boolean that indicates if a value is contained in a list of values. An example of how to use this function is shown below:
SELECT yearID IN (1871, 1872, 1873) AS earlyYears, count(*) FROM baseballStats GROUP BY earlyYears LIMIT 10Code language: PHP (php)Atri Sharma added the LIKE predicate, which can be used to filter string columns:
SELECT count(*) FROM baseballStats WHERE playerID LIKE 'aa%' LIMIT 100Code language: JavaScript (javascript)Yash Agarwal added the MODE function, which returns the most frequent value from all rows in a column. If we want to find the most frequent yearID before 2012, we could run the following query:
SELECT MODE(yearID) FROM baseballStats WHERE yearID < 2012
We can also pass in an optional second parameter of ‘MIN’, ‘MAX’, or ‘AVG’, which will be used if we have multiple values with the same frequency. In this case, 2007 and 2008 appear the same number of times, so passing in AVG will return the average of those values:
SELECT MODE(yearID, 'AVG') FROM baseballStats WHERE yearID < 2012Code language: JavaScript (javascript)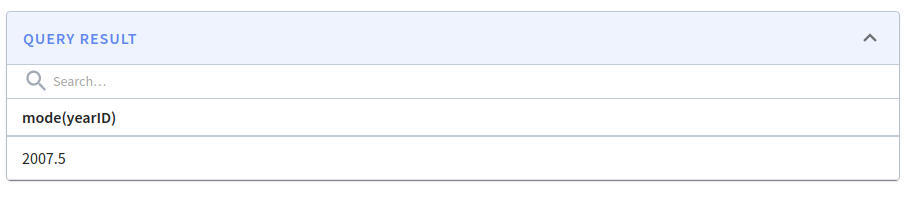
Lakshmanan Velusamy added functions that return serialized/raw values of the PercentileEst (QuantileDigest) and PercentileTDigest (TDigest) data structures. We can return the raw values at the 50th percentile by running the following query:
SELECT PERCENTILERAWEST50(runs), PERCENTILERAWTDIGEST50(runs) FROM baseballStatsThese functions can also be used on multi value columns:
SELECT PERCENTILERAWEST50MV(DivAirportIDs), PERCENTILERAWTDIGEST50MV(DivAirportIDs) FROM airlineStatsNew SQL Geo functions
Xiaotian (Jackie) Jiang added Geo scalar functions that convert from the WKT or WKB format to geometry/geography and from the geometry to WKB format:
SELECT stAsBinary(location), stGeomFromWKB(stAsBinary(location)), stGeogFromWKB(stAsBinary(location)), stGeomFromText(stAsText(location)), stGeogFromText(stAsText(location)) FROM meetupRsvp LIMIT 10
Yupeng Fu added the geoToH3 function, which returns the H3 index address of a given point or lat/long coordinates:
SELECT group_name, group_lat, group_lon, venue_name, stAsText(location), geoToH3(group_lat, group_lon, 6), geoToH3(location, 6) FROM meetupRsvp LIMIT 5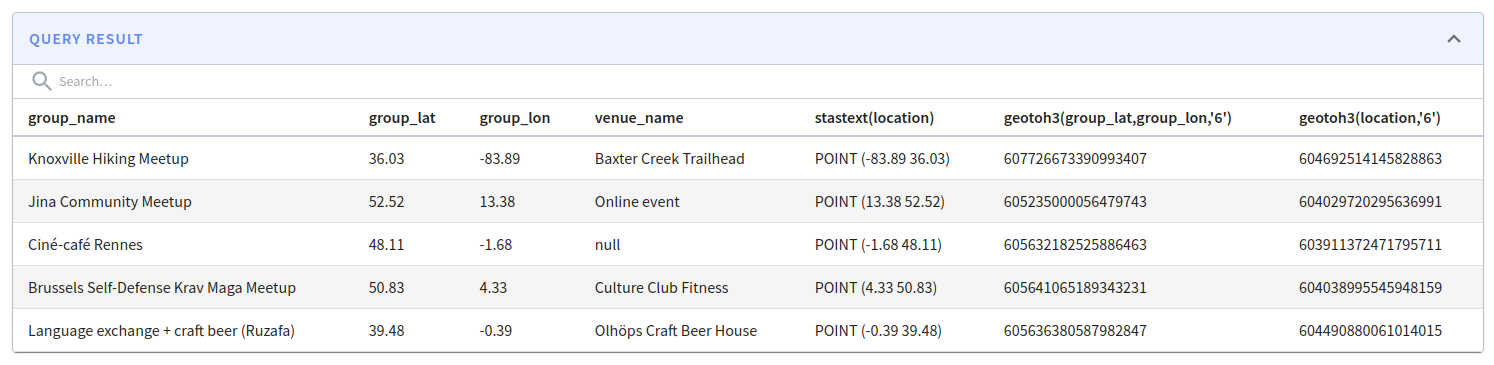
Other features
- Richard Startin added support for the boolean, timestamp, and bytes data types on multi value columns.
- Atri Sharma implemented OR predicates on Star Tree indices. To qualify for execution on a Star Tree node, you can only use one dimension field in an OR predicate. This makes sure that pre-aggregated documents don’t get double-counted when traversing the tree for multiple dimensions.
- Suvodeep Pyne added a flag that lets you skip multiple value splitting when ingesting CSV files.
- Atri Sharma made it possible to execute DISTINCT using a dictionary based plan when the DISTINCT query has a single column, no filters, and the column is dictionary encoded.
Bug fixes and optimizations
- Richard Startin made a series of performance optimisations, including a new range index implementation, which has already been used to bring down the speed of a query from 50ms to 10ms. He also made an internal change to use QueryContext to share objects between segments, which reduces duplicate work and memory usage.
- Rong Rong fixed field config validation on a null index type.
- Xiaotian (Jackie) Jiang fixed the LIKE predicate so that it requires full string matching, making it SQL compliant. He also updated REGEXP_LIKE to have the same behavior with or without the Lucene FST index.
- Xiang Fu fixed the DISTINCT with AS function, which means the following queries now return results: select CAST(runs AS string) as ddd from baseballStats GROUP BY 1select DISTINCT(CAST(runs AS string)) as ddd from baseballStatsselect DISTINCT CAST(runs AS string) as ddd from baseballStats
- Xiaotian (Jackie) Jiang fixed the Star-Tree index map when a column name contained a ‘.’
- Kartik Khare added support for reading streamed data from the lowest partition id in case partition id 0 is not available, which is the case with Kinesis.
Resources
If you want to try out Apache Pinot, the following resources will help you get started:
- Download page: https://pinot.apache.org/download/
- Getting started: https://docs.pinot.apache.org/getting-started
- Join our Slack channel: https://communityinviter.com/apps/apache-pinot/apache-pinot
- See our upcoming events: https://www.meetup.com/apache-pinot
- Follow us on Twitter: https://twitter.com/startreedata
- Subscribe to our YouTube channel: https://www.youtube.com/startreedata
