
In this blog post, we’re going to analyze the Chicago Crimes dataset with Apache Pinot. We’ll learn how to build a table and schema, write an ingestion job to get the data into Pinot, and finally build a Streamlit app to explore the data.
All the code used in this post is available in the StarTree pinot-recipes/analyzing-chicago-crimes GitHub repository if you want to follow along at home.
What is the Chicago Crimes dataset?
The Chicago Crimes dataset is an open dataset from the Chicago Data Portal that contains reported incidents of crime that occurred in the City of Chicago from 2001 until today. It contains details of the type of crime, where it was committed, whether an arrest was recorded, which beat it occurred on, and more. At the time of writing, there are just over 7 million records in this dataset.
A screenshot of the data is shown below:
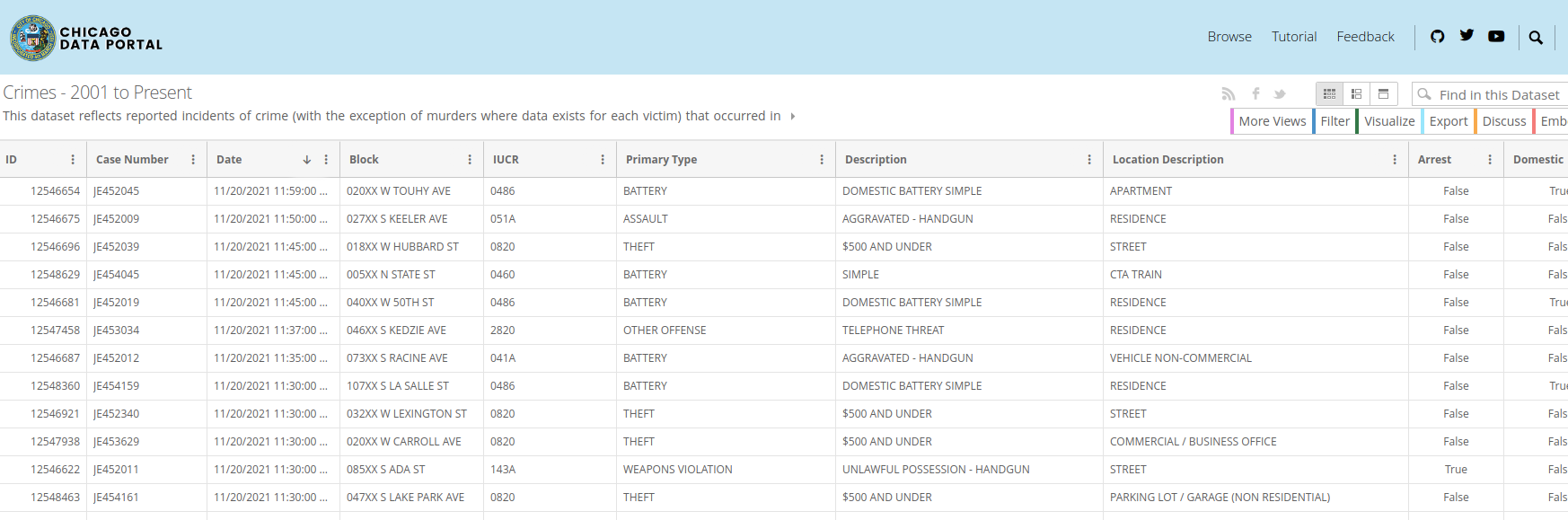
Why is this an interesting dataset for Pinot?
When I first started playing around with Pinot about 6 months ago, I asked (my now colleague) Neha Pawar how I would know whether a dataset was a good fit for Pinot. Neha suggested the following rules of thumb:
- Data coming from real time streams of events, such as Wikipedia, GitHub, Meetup, or more. This is the use case for the majority of Pinot users.
- Data sets where the query patterns are of an analytical nature e.g. slicing and dicing on any columns.
The Chicago Crime dataset is static, but it has a lot of different columns that we can filter and aggregate against, so it should be a fun one to explore.
Getting the data into Pinot
Since all the data is in a CSV file, we will import it into an offline table using a batch ingestion job. Data is stored in segments (think partitions in a relational database) and a table is made up of many segments. Each table is associated with a schema and we could use the same schema for multiple tables if we so wanted. The diagram below shows how these components are related to each other:

Now we need to define a schema. A schema defines the fields in our table and their data types. We also need to decide which category each field will belong to. There are three categories:
- Dimension – These columns are used in slice and dice operations (e.g. GROUP BY or WHERE clauses)
- Metric – These columns represent quantitative data and would usually be used in aggregations (e.g. SUM, MIN, MAX, COUNT)
- DateTime – These columns represent date or time data.
The Chicago Crimes dataset doesn’t have any columns that contain quantitative data, so the majority of our columns are going to be Dimensions. The Date field is an exception, it will have the DateTime category.
When ingesting data, Pinot assumes that the schema column names match the names of fields in the data source. This means that most of the time we don’t have to write any mapping logic. In this case, however, our CSV file has fields that contain spaces in their name. Schema column names can’t contain spaces, so we’ll need to create a column name without a space and then write an ingestion transformation function in the table config to map the data across.
Schema
We’re going to use the following schema:
{ "schemaName": "crimes", "dimensionFieldSpecs": [ { "name": "ID", "dataType": "INT" }, { "name": "CaseNumber", "dataType": "STRING" }, { "name": "Block", "dataType": "STRING" }, { "name": "IUCR", "dataType": "STRING" }, { "name": "PrimaryType", "dataType": "STRING" }, { "name": "Arrest", "dataType": "BOOLEAN" }, { "name": "Domestic", "dataType": "BOOLEAN" }, { "name": "Beat", "dataType": "STRING" }, { "name": "District", "dataType": "STRING" }, { "name": "Ward", "dataType": "STRING" }, { "name": "CommunityArea", "dataType": "STRING" }, { "name": "FBICode", "dataType": "STRING" }, { "name": "Latitude", "dataType": "DOUBLE" }, { "name": "Longitude", "dataType": "DOUBLE" } ], "dateTimeFieldSpecs": [ { "name": "DateEpoch", "dataType": "TIMESTAMP", "format" : "1:MILLISECONDS:EPOCH", "granularity": "1:MILLISECONDS" } ] }Code language: JSON / JSON with Comments (json)For the columns with spaces, we’ve created a column name that doesn’t have those spaces in the schema. We’re not going to store the Date in its current format, instead, we’ll write a transformation function to convert it into an epoch. We’ll handle column name mapping and date parsing in the table config in the next section.
Table
Next, we’ll define our table config, as shown below:
{ "tableName": "crimes", "tableType": "OFFLINE", "segmentsConfig": { "replication": 1, "schemaName": "crimes" }, "tenants": { "broker":"DefaultTenant", "server":"DefaultTenant" }, "tableIndexConfig": { "loadMode": "MMAP", "sortedColumn": ["Beat"], "rangeIndexVersion": 2, "rangeIndexColumns": ["DateEpoch"] }, "ingestionConfig": { "batchIngestionConfig": { "segmentIngestionType": "APPEND", "segmentIngestionFrequency": "DAILY" }, "transformConfigs": [ {"columnName": "CaseNumber", "transformFunction": ""Case Number"""" }
Code language: JSON / JSON with Comments (json)