
Read Real-time Analytics with Presto and Apache Pinot — Part I
This blog post is the second part of a two-part series on using Presto with Apache Pinot. You can find the first part here on how analytics systems make trade-offs for latency and flexibility.
Achieve the best of both: Presto Pinot Connector
Continuing from the first part of this series, we’re now going to focus on a Presto Pinot Connector. The diagram below shows the latency versus flexibility tradeoff between Presto and Pinot.
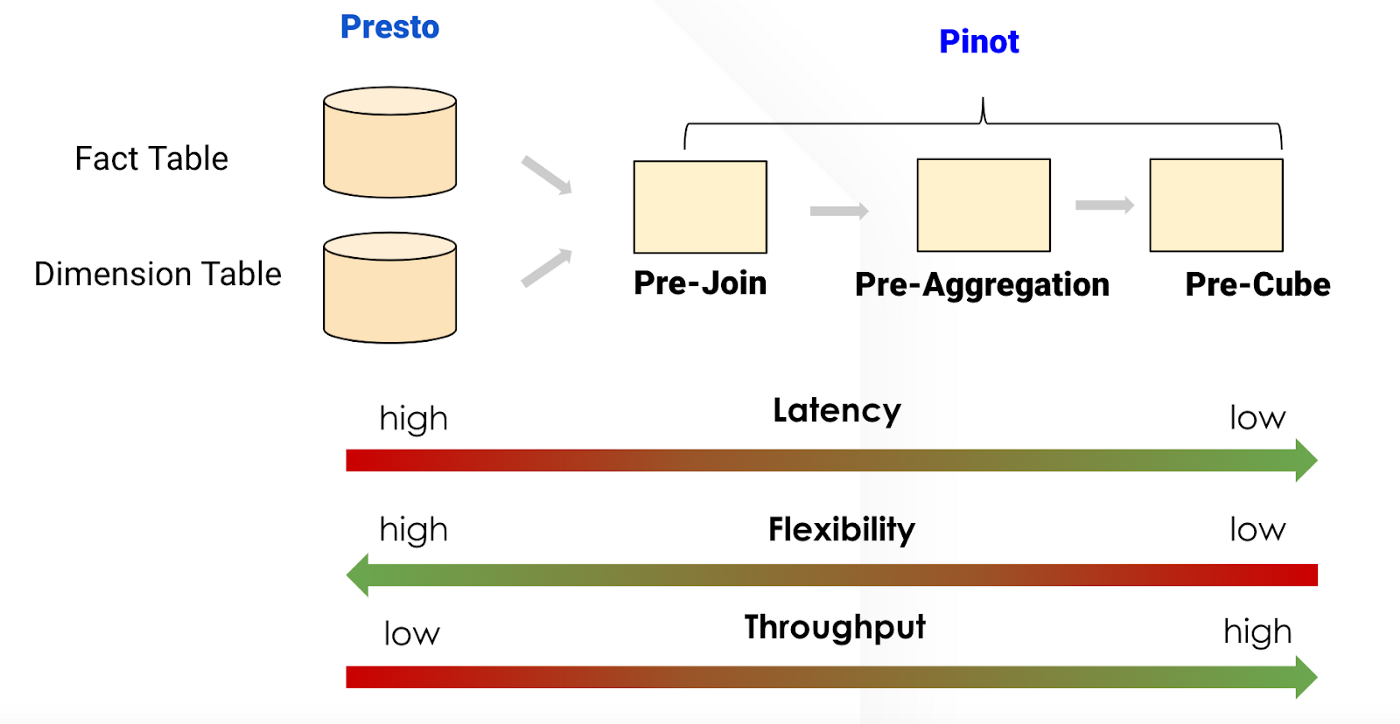
In Presto, users are getting excellent flexibility: Full-SQL support, ability to do multi-way JOINs. However, it may take seconds to minutes for a query to return from the latency perspective, depending on the data volume.
On the other side of the world, Pinot users can store from raw data to pre-joined/pre-aggregated, even pre-cubed data along with advanced index technologies to speed up queries. Pinot query engine optimizes for those analytical query patterns, like aggregations/group-by. Pinot gives the flexibility of slicing and dicing while maintaining a low query latency. However, Pinot isn’t flexible enough due to the lack of full SQL support.
The needs to accelerate Presto query speed and support more functionality for Pinot users are a perfect match. This is the primary motivation for the birth of the Presto Pinot connector. This complete system covers the ENTIRE landscape of analytics, and we can leverage the best part of Presto and Pinot. This new solution enables Uber’s operations teams with basic SQL knowledge to build dashboards for quick analysis and report aggregated data without spending extra time working with engineers on data modeling or building data pipelines, leading to efficiency gains and resource savings across the company.
Since then, the Presto and Pinot community has contributed many features to make the solution flexible and scalable.
E.g.,
- Array type support and functions pushdown
- Timestamp/date-type inferral and predicate pushdown
- Support Pinot gRPC server for segment level queries
Chasing the light: Aggregation pushdown
To fully understand Pinot’s power, we implemented the aggregation pushdown feature, which allows the Presto Pinot Connector to do best-effort push down for aggregation functions that Pinot supports, e.g., count/sum/min/max/distinct/approximate count, etc.
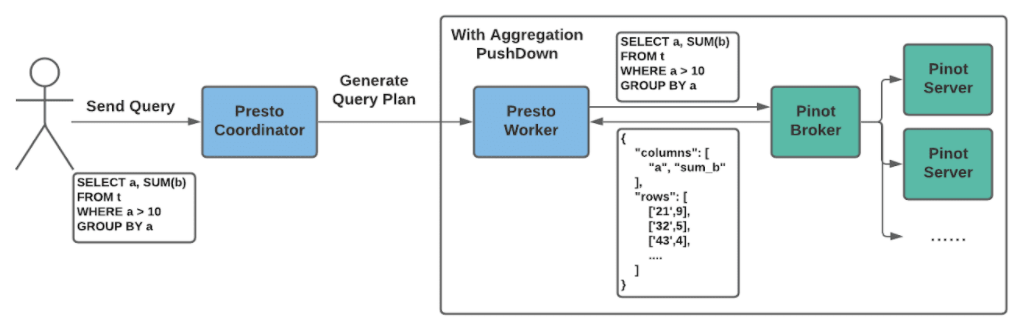
The graph above describes how Aggregation pushdown works.
- Presto Coordinator gets the query and parses it to a query plan.
- Presto Pinot Connector implements a plan optimizer that figures out that this query is an aggregation (group by) query and pushdown-able to Pinot. Presto query plan optimizer rewrites the query plan with the pushdown-able mark.
- During the physical plan execution phase, Presto creates only one Split containing the Aggregation (group by) query and Pinot broker endpoint.
- One Presto worker gets the Split and queries the Pinot broker set inside the Split to ask the aggregation group by results.
- The Pinot response is wrapped as a PinotBrokerPageSource and processed by the Presto worker for further executions.
In this case, Pinot saves data transmission and computation time from Presto, which significantly reduces the query response time. In general, we see about 10 to 100 times latency improvement here.
No compromise on flexibility: Streaming Connector
A natural follow-up question is, how about those queries that cannot be pushed down to Pinot for processing. The answer is also very straightforward. We fetch all the requested columns data from Pinot and let Presto do the hard work.
Since the data volume might be huge, it’s not scalable to query the Pinot Broker for that. So we need to go one step further into all Pinot servers and query Pinot segments for the data we want.
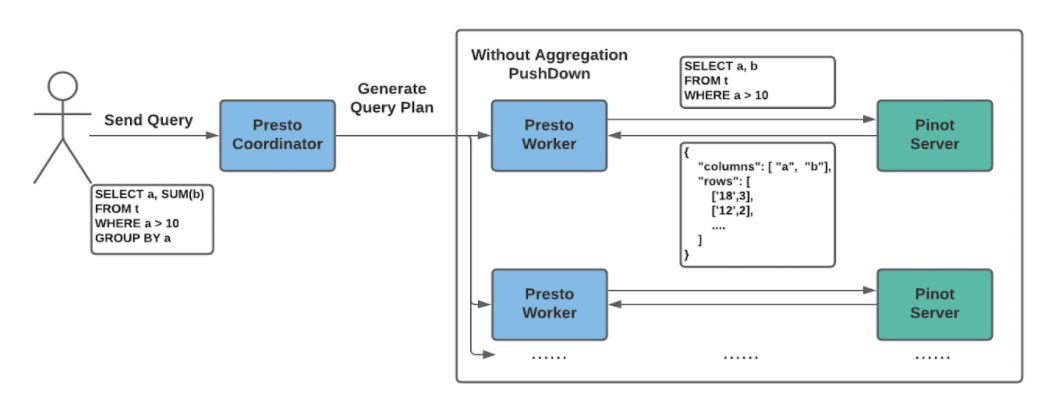
Above is an example when turning off the aggregation push down feature.
- Presto Coordinator gets the query and parses it to a query plan.
- The plan optimizer decides that this query cannot be pushdown, then it fetches the Pinot routing table for generating the Presto Pinot splits.
- Assuming we have 100 Pinot segments with the config of querying 10 Pinot segments per Presto split. Each Presto query will generate 10 Presto query splits, and each Presto split contains 10 Pinot segments to query.
- Presto workers get the splits and query the corresponding Pinot Servers based on the routing table. Typically the queries are selecting some columns with certain predicates.
- The Pinot response is wrapped as a
PinotSegmentPageSourceand then processed by the Presto worker for further executions.
The first iteration of wiring Presto to Pinot isn’t efficient as Pinot needs to cache all the query responses then send it back in one data chunk. The performance was acceptable when the query is scanning a small data size. However, it becomes a problem for large table scanning, as it quickly eats up server memory and often causes GC on Pinot Servers.
To make memory usage more sustainable, the community has made two significant changes on both Presto and Pinot sides.
- Apache Pinot has implemented a gRPC based streaming query server [ 1] [ 2], which allows users to query Pinot in a streaming fashion.
- The new Presto Pinot Connector has implemented the streaming client [ 3] and allows Presto to directly fetch data from Pinot Streaming Server chunk by chunk, which smooths the memory usage.
Presto Pinot Connector Query Performance
Benchmark Setup
We’ve performed benchmarking on Presto Pinot Connector using AWS m4.4xlarge machines.
- 3 Pinot Controllers, each on the container with resources of 4 cores, 16GB memory
- 5 Pinot Brokers, each on the container with resources of 4 cores, 16GB memory
- 4 Pinot Servers, each on the container with resources of 15 cores, 54GB memory
- 1 Presto Coordinator, each on the container with resources of 4 cores, 16GB memory
- 4 Presto Workers, each on the container with resources of 4 cores, 16GB memory
The table contains 1 billion randomly generated records of complexWebsite (schema, table config) data sets.
Benchmark results on Aggregation queries
Below tests are based on the query pattern:
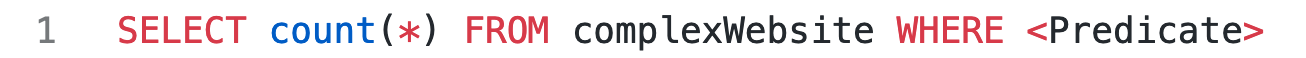
We can match different numbers of rows based on the predicates.

Below is the latency graph for high selectivity predicates. Since each query scans small data, the Pinot and Presto query engine contribute most to the latency number.
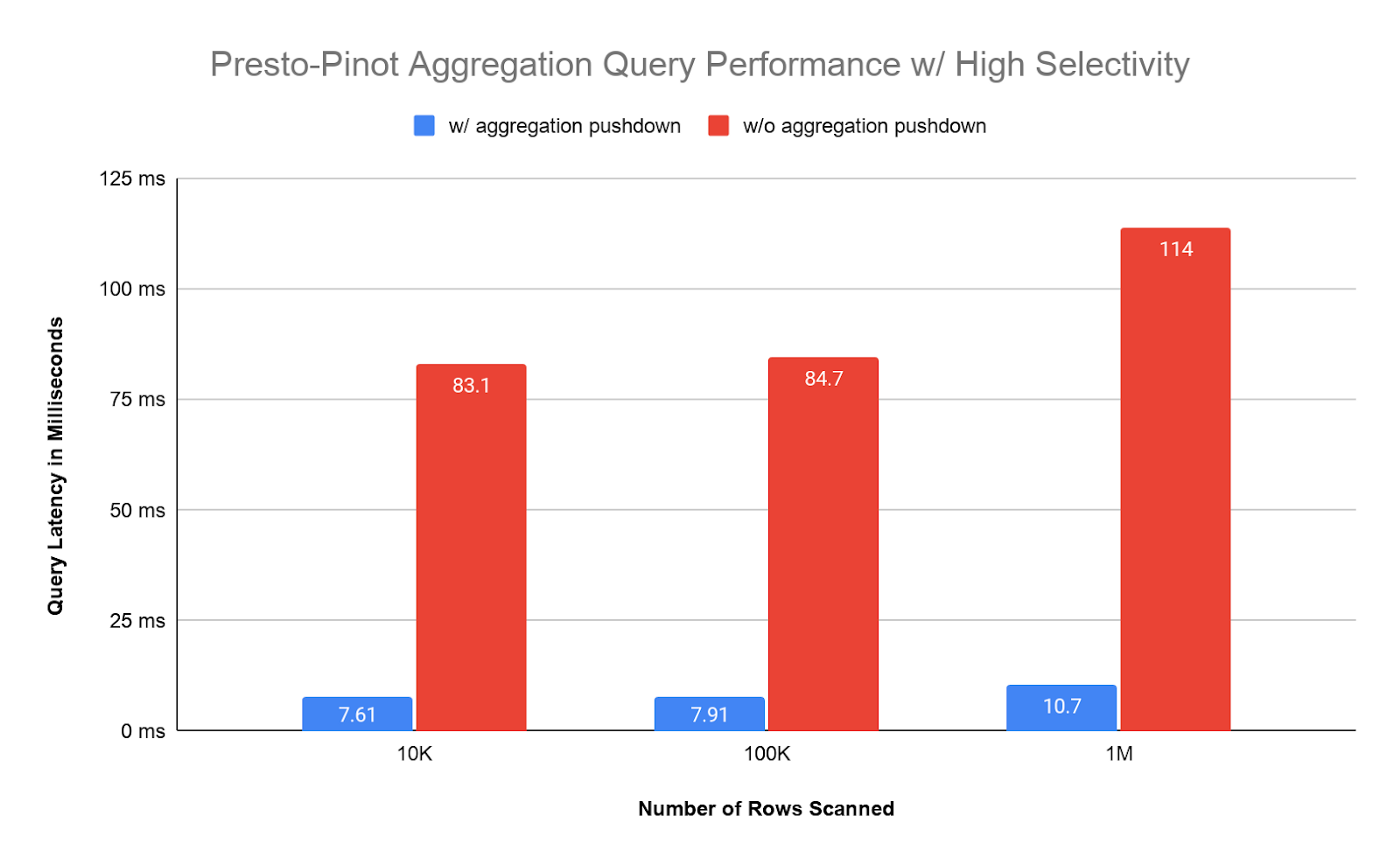
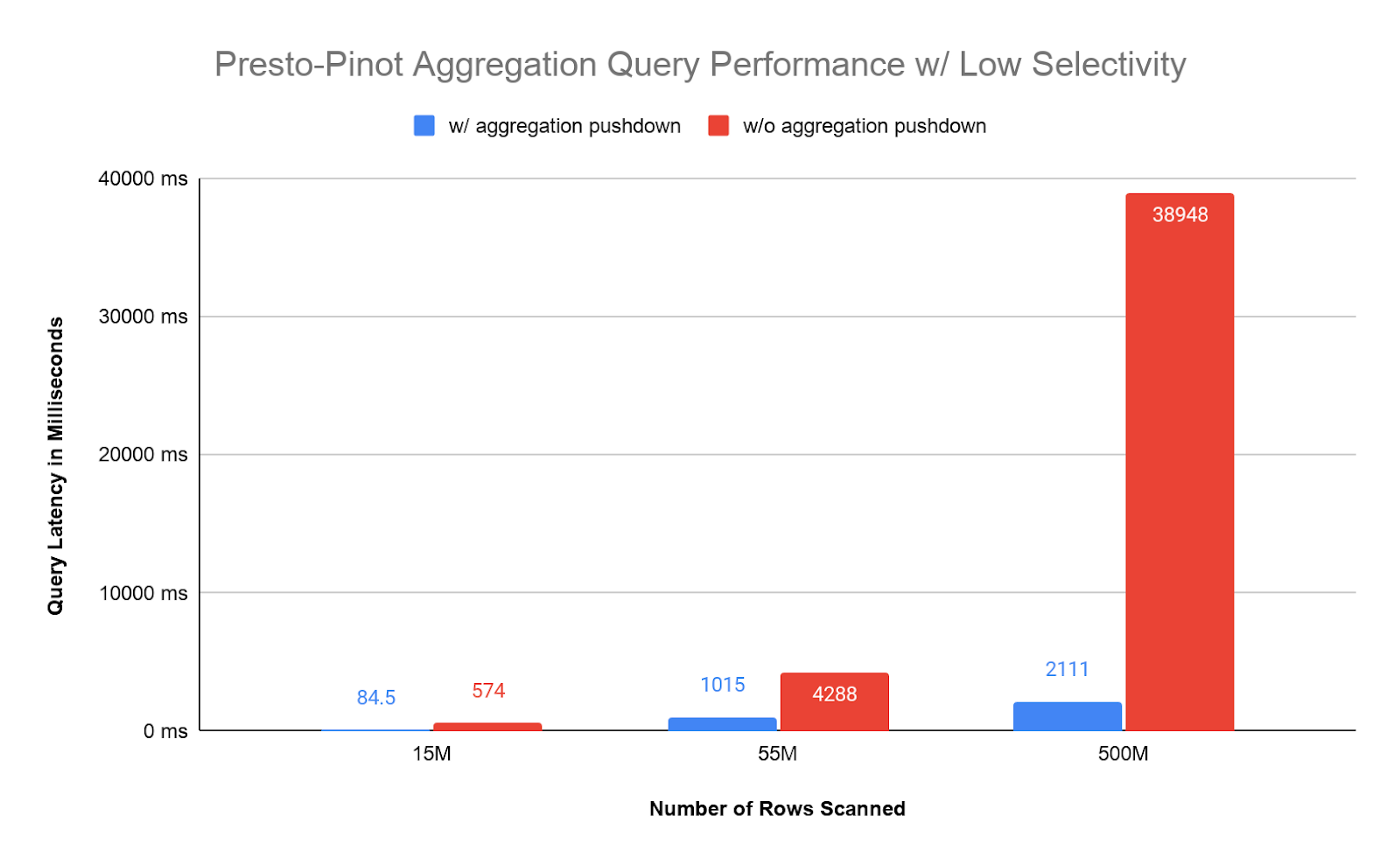
Below is the latency graph for low selectivity predicates. Queries need to scan more data, and the latency is proportional to the number of documents scanned. For a large data scan, Presto requires to fetch all the data needed from Pinot to process. The extra costs and time consumption are on Pinot data serialization, network transfer, and Presto data deserialization.
Benchmark results on Aggregation Group By queries
Below tests are based on the query pattern:

We can match different numbers of rows based on the predicates.
The latency trends are similar to aggregation only queries.

Compared to Presto, for scanning large amounts of data, Pinot latency increases are in a much lower ratio. From 55 Million rows to 500Million rows, Pinot latency increases 2.2 times while Presto increases 6.3 times.
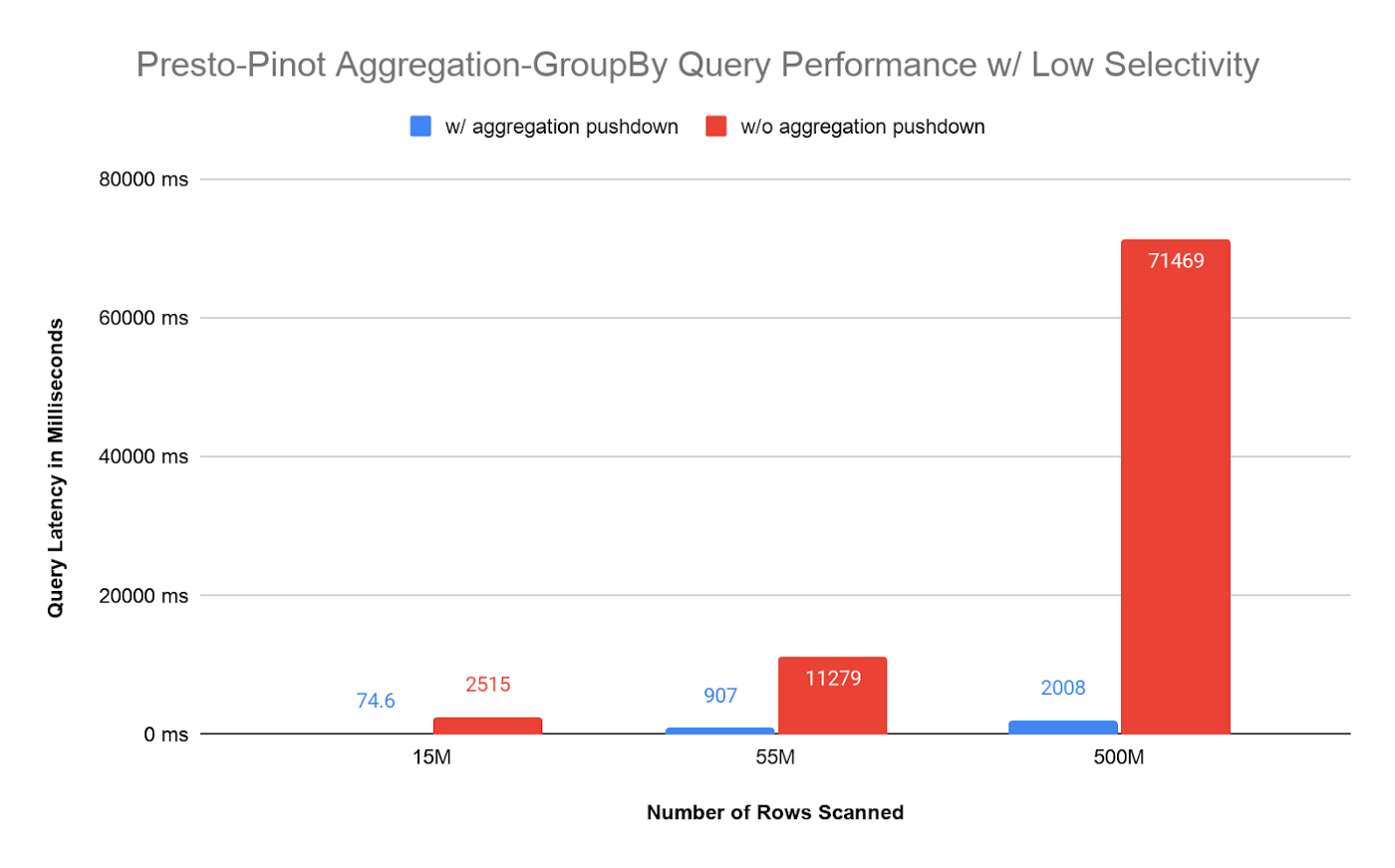
The above latency graph shows that aggregation pushdown opens up the gate for analytics and fully allows our users to enjoy real-time analytics with flexible query capability.
Resources
Please refer to Pinot Kubernetes Quickstart for deploying Presto and Pinot in practice. Please also refer to Real-time Analytics with Presto and Apache Pinot — Part I for background information.
- Please visit the Apache Pinot Website and Documentations for more information and tutorials.
- Please join Apache Pinot Slack for news, questions, and discussions.
- Please join Apache Pinot Meetup Group for future events and tech talks!
- Follow us on Twitter: https://twitter.com/startreedata
- Subscribe to our YouTube channel: https://www.youtube.com/startreedata
Thanks to Chinmay Soman.
