
Since the 0.6.0 release of Apache Pinot, a new feature was made available for stream ingestion that allows you to upsert events from an immutable log. Typically, upsert is a term used to describe inserting a record into a database if it does not already exist or update it if it does exist. In Apache Pinot’s case, upsert isn’t precisely the same concept, and I wanted to write this blog post to explain why it’s exciting and how you can start using it.
Analyzing Stateful Event Streams
Let’s start by imagining an immutable log of events that contain information about the state of an object. The best way to visualize what I’m talking about here is a state machine diagram.
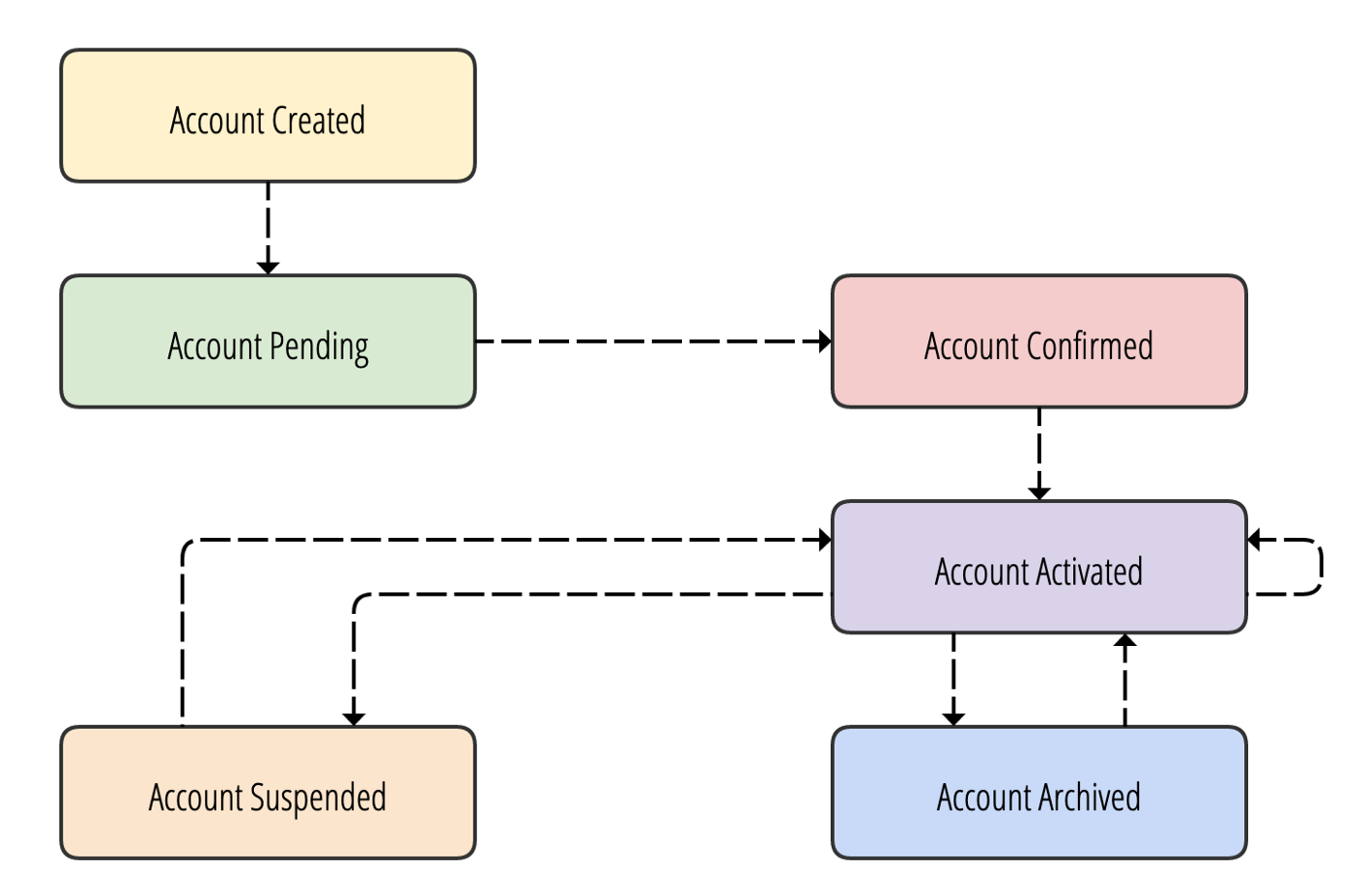
In the diagram above, we have a state diagram of an account object. The account needs to go through a collection of state changes during a customer account’s life cycle. The application will behave differently for each account, depending on the current state of an account. This example extends to various domains, such as order delivery, which I will talk about later.
Now, as far as analytics is concerned, we need to performantly query a collection of events emitted by the application that manages the state of each account. Every time the state of an account object changes, we will emit an event that contains information about the state change of the account and a copy of its fields at the time of the event.
Partitioning Event Streams in Kafka Topics
The diagram below shows a topic in Apache Kafka that models what a stream of state transition events looks like for an account.
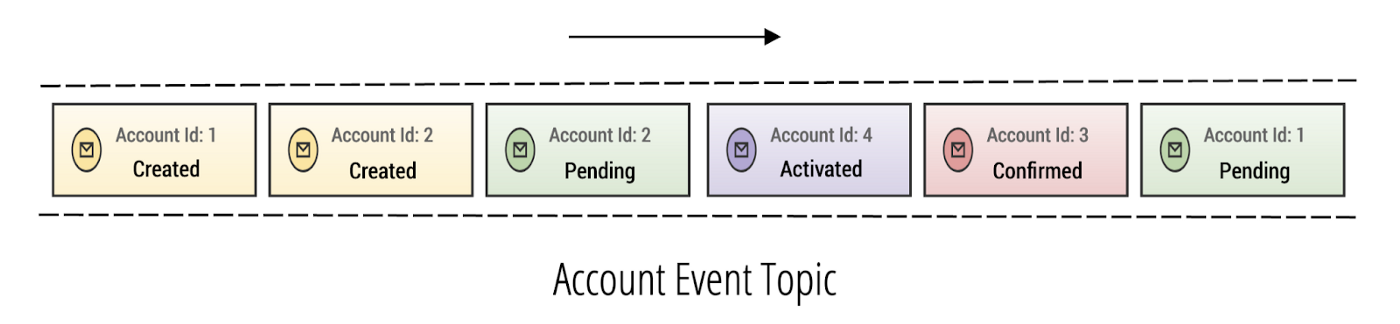
Here, we see our hypothetical account event topic. Each one of these events represents the state transitions that are happening for many different accounts. The problem is that they are all lobbed in together in a single stream. Since it is not practical to have many different topics for each account, we need to find a way to partition each event by its account id. The abstraction we want to query by is represented by the diagram below, which shows a log of events partitioned by account.
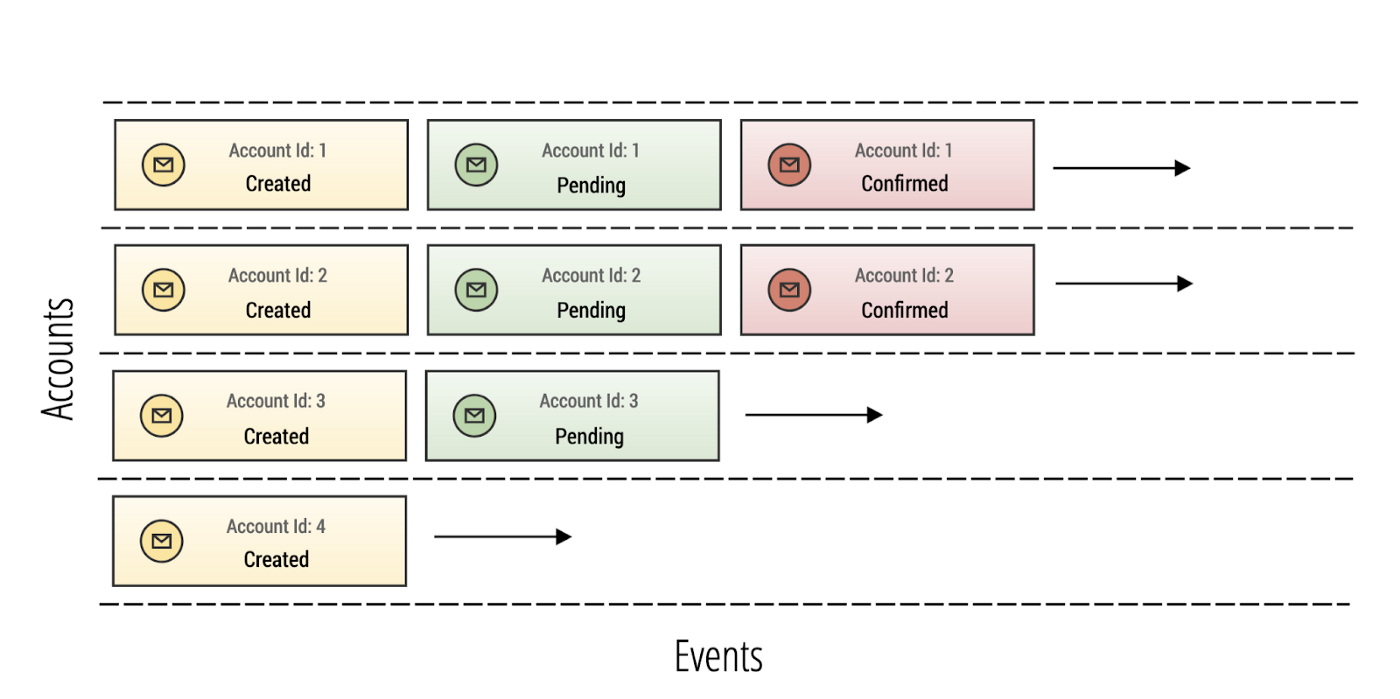
Partitioning a topic by a primary key is a feature that is available in Apache Kafka. The purpose of doing this is simple in theory. We want to quickly index all events in a topic by a primary key, which allows us to query each log of events for each account performantly.
Understanding Upsert in Apache Pinot
By default, Apache Pinot does allow you to query all events ingested from a Kafka topic by a particular primary key (we call it a dimension). But the problem with this kind of query is that you will get back all of the state changes for all accounts. In some cases, we need to get back the most up-to-date version and state for each account.
Apache Pinot is not a traditional database, which is why it’s essential to understand why and when to use upsert. Pinot is an immutable datastore, which means that there is no genuine concept of upsert as you stream data into it from Kafka. For the upsert implementation, it’s essential to understand that an individual record is not updated via a write; instead, updates are appended to a log and a pointer maintains the most recent version of a record.
It’s still possible to retrieve all the events of a partitioned event log by a primary key at query-time by turning off upsert. In the next blog post, I will focus on taking the basics we learned here and applying them to an order delivery service similar to UberEats or Instacart. In that example, we’ll see the actual implementation details for enabling upsert for an application.
Conclusion
My goal for this blog post was to explain “the why” for Pinot’s upsert feature. If you’re looking to get started with implementing it in your application, please head on to our documentation to get started.
In an upcoming blog post, I will be focusing more on “the how” for implementing upserts in an order delivery service application. If you’re interested in checking out the active development on this new Pinot example application, take a look at this GitHub project, and feel free to reach out with any questions.
If you’re interested in learning more about the implementation details behind upsert in Pinot, Yupeng Fu’s talk is an excellent resource.
More Resources:
-
Join our Slack channel: https://communityinviter.com/apps/apache-pinot/apache-pinot
-
See our upcoming events: https://www.meetup.com/apache-pinot
-
Follow us on Twitter: https://twitter.com/startreedata
-
Subscribe to our YouTube channel: https://www.youtube.com/startreedata
