
Capacity planning for a pinot cluster is one of the critical tasks and it can have a drastic impact on performance , reliability, and cost associated with an Apache Pinot™ cluster. It is mundane , iterative and a manual task . A Pinot cluster comprises the following 4 core components – Controller, Zookeeper, Broker, Server and optionally Minion nodes.
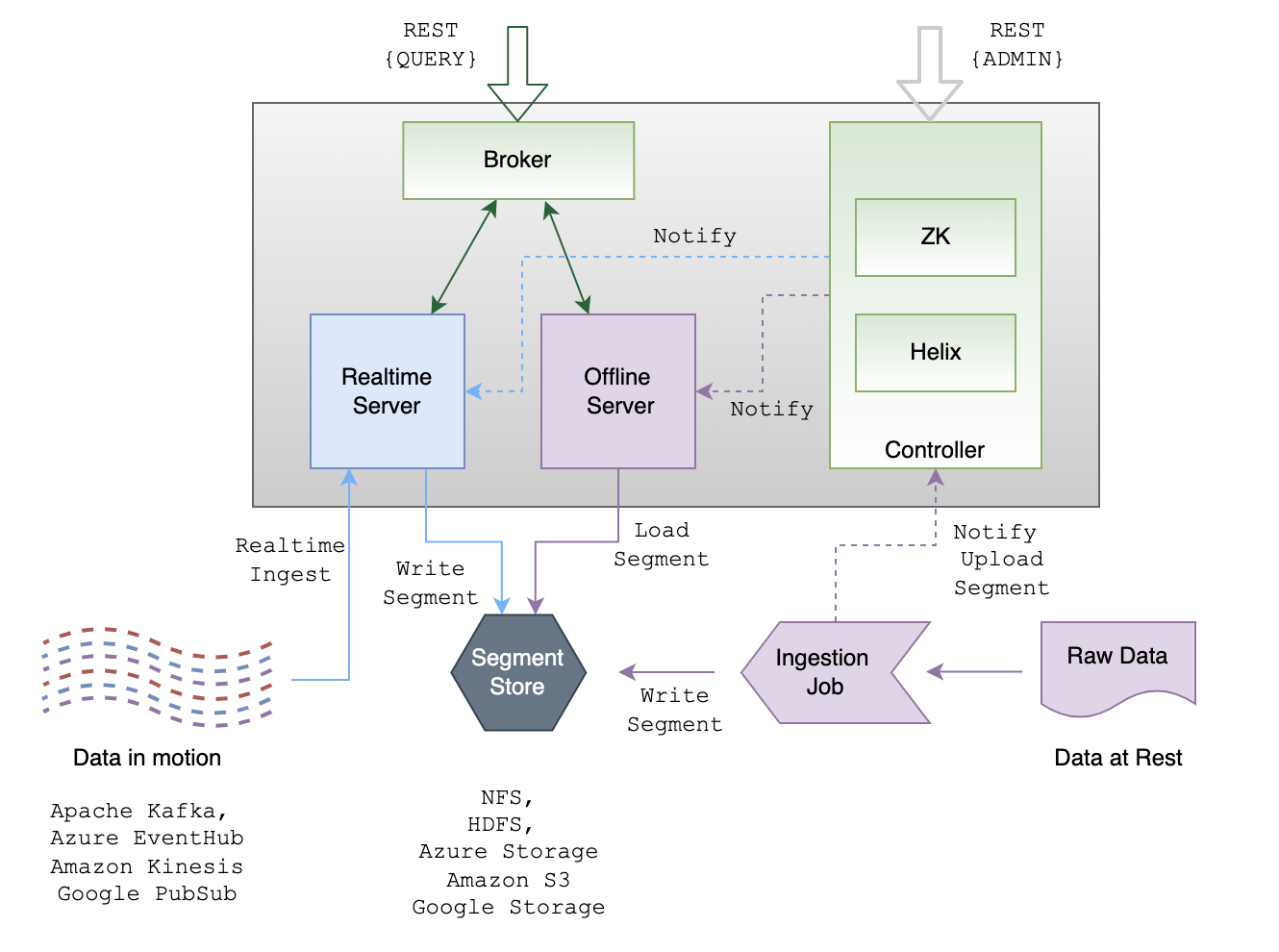
Oftentimes, the use case query / workload patterns are not known upfront. This two-part blog series will provide a systematic framework to develop an initial pinot cluster size for your use case. Without knowing much about the workload this is more of an empirical formula and the actual size could vary based on workload. In this part 1, we will look at the key factors that a cluster admin should consider for capacity planning of a pinot cluster.
Key Factors:
The key influencing factors to be considered for capacity planning are as follows:
1. Throughput
This is the read and write QPS (queries per second) requirement of your use case. In other words, this is the total number of concurrent queries that Pinot cluster will be serving at any given point of time and the number of events to be ingested in real time
Throughput is the primary factor for determining the total number of cores needed in the server and broker components for your use case.
1. Read QPS: Total number of read queries expected per second.
Read QPS helps determine the number of cores needed in the Server (data serving and processing) and Broker (query scatter/gather) components.
For a pinot cluster that serves applications / user facing analytics use cases, read QPS is typically very high (in hundreds or thousands or even much higher). Whereas for internal/dashboarding/reporting use cases, read QPS is typically in single or low double digits, given that these queries are generated by manual(or scheduled) action and not by a data driven application.
2. Write QPS: Real-time Ingestion / event rate per second.
This is generally used in the context of data being ingested from a real time streaming source (for e.g Kafka, Kinesis, or PubSub). Write QPS primarily helps determine the number of cores needed in the Server component to support real time ingestion needs of your use case.
3. Number of streaming partitions: Total number of partitions on the streaming data source (for e.g Kafka topic) from where the data will be ingested into Pinot.
This determines the degree of parallelism during real time ingestion.
Number of stream partitions helps determine the total number of cores in the server component that will be utilized for consuming data and generating real-time pinot segments.
2. Data Size
This is the total amount of data that you want to store in your Pinot cluster.
This primarily helps determine the total persistent disk storage (EBS/SSD/HDD) and total number of cores required in the server component for your use case.
This is one of the key driving factors in selecting the number and compute capacity of server instances .
1. Daily Data Size: Total amount of data anticipated to be ingested into the Pinot cluster per day.
2. Retention Period (in days): Total time (typically, number of days) the data needs to be retained in Pinot.
Note: With the introduction of Tiered Storage in the StarTree Cloud offering, you can now have infinite cloud storage and retention could simply be the amount of hot data that needs to be kept local to compute.
3. Replication Factor (RF): Total number of copies per segment to be maintained in the cluster.
Total Data Size = Daily Data Size Retention Period (in days) RF
3. Types of workloads/queries
Types of workloads / queries are another important contributing factor in selecting the number and compute capacity of Server and Broker components. For e.g: typical analytics use cases requiring aggregate metrics pull only a small amount of data whereas reporting use cases could pull relatively large amounts of data per query. Hence, sizing for each of these use cases could be drastically different.
4. Number of tables and segments
The number of Pinot tables and segments primarily helps determine the number of cores needed in the Controller and Zookeeper components.
This helps in selecting the number and compute capacity of Controller and Zookeeper components.
5. Minion
Pinot provides Minion tasks to support scenarios such as bootstrapping initial data, backfilling historical data, periodically ingesting batch data from an offline data source, managed offline flows, upserts to accommodate GDPR requirements, and such.
Sizing of the minion component would vary depending on the number of minion tasks, SLA requirements of the minion tasks, and the amount of data that needs to be ingested, upserted, or purged.
Given the periodic nature of minion tasks, Pinot minions can be scaled in and out on demand. Some form of autoscaling for Pinot Minion nodes can help optimize compute costs.
6. Environment
All factors that we looked at so far are use case based. Our next and final step / iteration is to apply environment-related factors.
Determine whether the cluster you are sizing for is for a production or non-production environment.
1. High Availability for Compute: For production environments, you may want to ensure high availability to avoid/minimize any downtime. A cross availability zone deployment with replication can help achieve that.
It’s recommended to deploy your Pinot Cluster across at least two AZs. This mitigates the risk associated with single AZ failures.
2. High Availability for Data – Replication Factor: You also want to make sure that there is sufficient replication of pinot segments (data) in the cluster. For production environments, a minimum recommended replication factor is 3. Generally, a higher replication factor helps serve SLA bound high throughput requirements by distributing workload more evenly across data processing nodes (servers).
3. Segment Replica Groups: Replication Factor, coupled with replica group segment assignment makes Pinot inherently support linear horizontal scaling and improves query performance. For production use cases, at least 2 replica groups are recommended. For extremely high Read QPS requirements, a higher number of replica groups will help improve performance.
Sizing:
In this section, we will cover the sizing of individual pinot components using key influencing factors defined in the previous section. We will use AWS instance types for compute capacity as a reference. Equivalent node types in another cloud provider or on-prem environment should provide similar performance characteristics.
1. Broker:
For selecting the number and type of broker instances, Read QPS is the key driving factor .
Typically a broker node with 16 CPU cores and 64 GB memory can support up to 1000 qps for the standard analytical queries. For the not so optimal case, it can support a few hundred qps as long as most work is done on the server side.
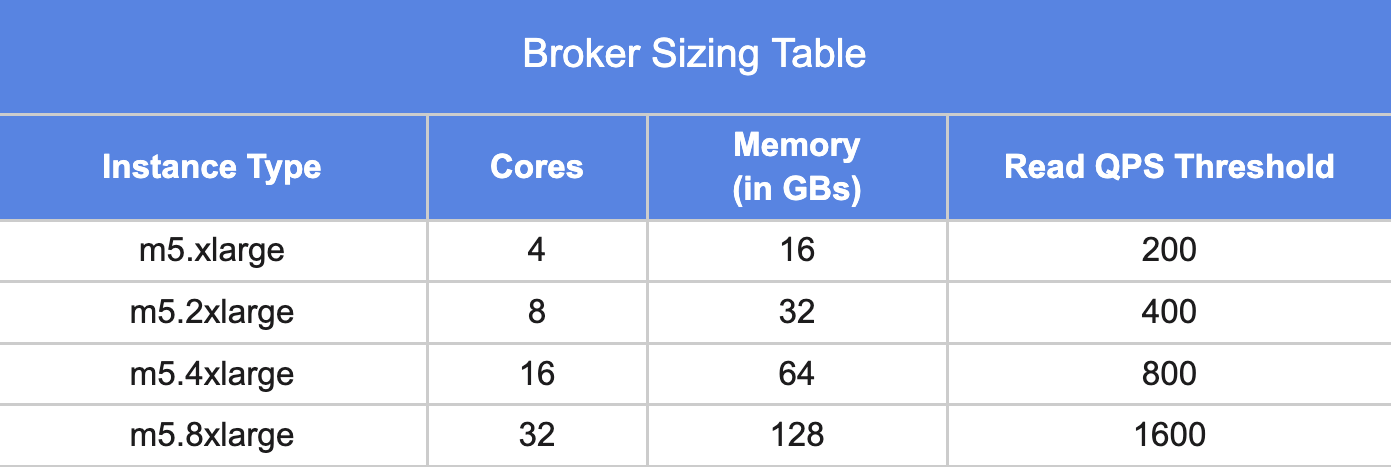
The above table could be used as a starting point for sizing brokers.
2. Server:
For selecting the number and type of server instances, Read QPS is the primary factor and Write QPS and Number of Kafka partitions are the secondary factors. In addition to these, Total Data Size (amount of data to be stored locally) is also another factor that impacts server sizing.
In general, a server with 16 cores and 64GB memory can be pushed up to around 1000 qps for the optimal case. Your mileage may vary depending on the workload and the amount of data the queries are processing.
The table below provides a good starting point for sizing of the server component.
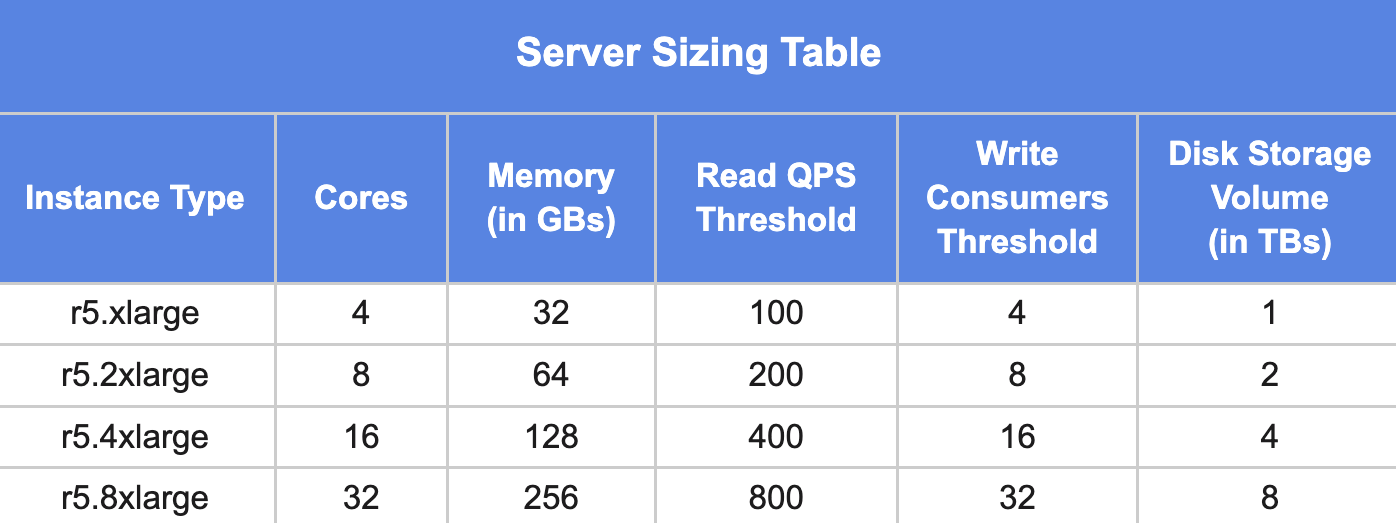
Note: Write Consumer Threshold is the ideal number of stream consumers at Pinot level for the given instance profile. It is recommended to keep a 1:1 ratio of the number of pinot consumers and the number of physical cores.
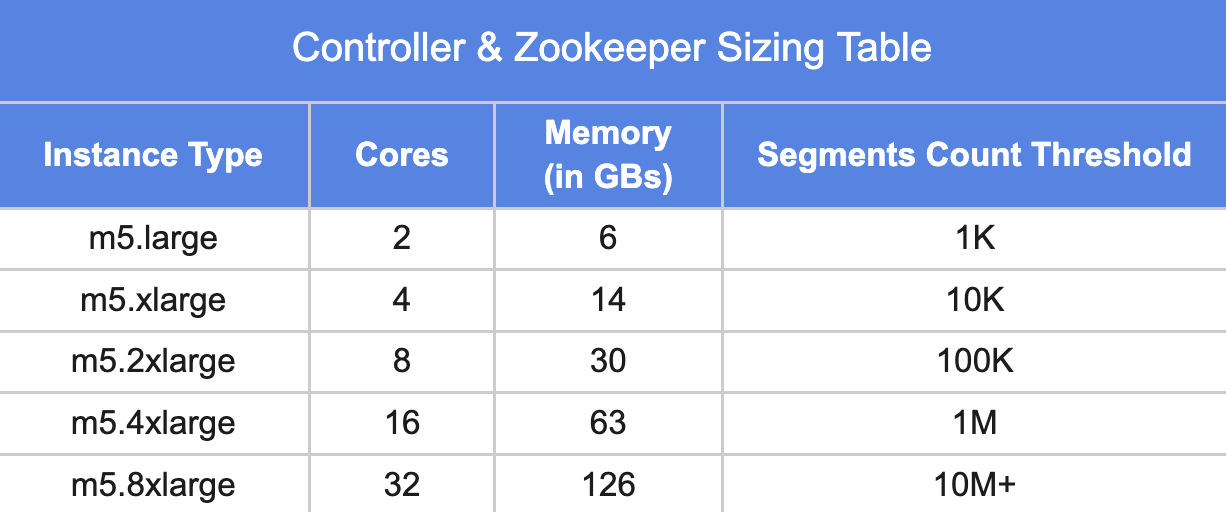
3. Controller and Zookeeper:
A controller with 16 cores and 64GB memory is generally good for a large number of tables with hundreds of thousands of segments (across all tables).
The following table provides a good starting point for sizing controllers.
Apache Pinot is designed to run at any scale and comes with a lot of advanced features that can help with query performance and throughput . Depending on how these configs are applied, they can also influence the sizing requirements for the Pinot cluster.
In part 2 of this blog, we walk you through a real-world example of capacity planning for a pinot cluster.
