
Background
Snowflake is an extremely popular data warehousing technology used primarily for batch analytics. It is highly scalable and can run SQL queries on massive amounts of data in an efficient manner. Although it works well for offline analytics use cases such as data exploration and dashboarding, there are gaps when it comes to real-time analytics. As mentioned in Chinmay Soman’s How To Pick A Real-Time OLAP Platform , user-facing analytics, personalization, and other real-time use cases need the ability to execute tens of thousands of queries per second. A query volume like this is prohibitively expensive when using Snowflake. In addition, data needs to be queried with millisecond latency as it is being generated, which is not currently supported in Snowflake.
At StarTree, we believe Apache Pinot® is a great solution for real-time analytics which can be used in conjunction with Snowflake (or any other warehouse) for bridging this gap. Pinot was purpose-built for serving tens of thousands of SQL queries per second on petabytes of data within milliseconds ( read more here).
In this blog post, we will go over our new StarTree Snowflake connector which makes it easy to ingest data from Snowflake to Pinot in a self-serve manner.
Architecture
The Snowflake Pinot connector ingests data from Snowflake into Pinot through a pull model. It fetches data in batches from Snowflake by executing SQL queries through the Snowflake JDBC driver. This approach is beneficial in a few ways:
- Extraction flexibility : Splitting data extraction into batches provides control over how much data to fetch and can allow parallel ingestion when executing queries across multiple connections. This allows fine-tuning the ingestion rate to a user’s preference, providing a tradeoff between query cost and rate of ingestion.
- Universal language : SQL is a familiar language that allows users to express what data they want to be extracted from their Snowflake table at the row and column level.
- Extensibility : a JDBC-based ingestion framework is extensible to other JDBC compliant databases.
The Snowflake connector is implemented using the Pinot Minion framework. Minion is a native component in Apache Pinot, designed to handle computationally intensive tasks like batch file ingestion, segment creation and deletion, and segment merge and rollup. By leveraging Minion, the Snowflake connector decouples the Snowflake data ingestion from critical Pinot components which serve queries at low latency. Reference the blog, No-Code Batch Ingestion, which does an excellent job of introducing the Minion framework. In the next section, we will dive deeper into how the connector generates and executes ingestion tasks within Minion.
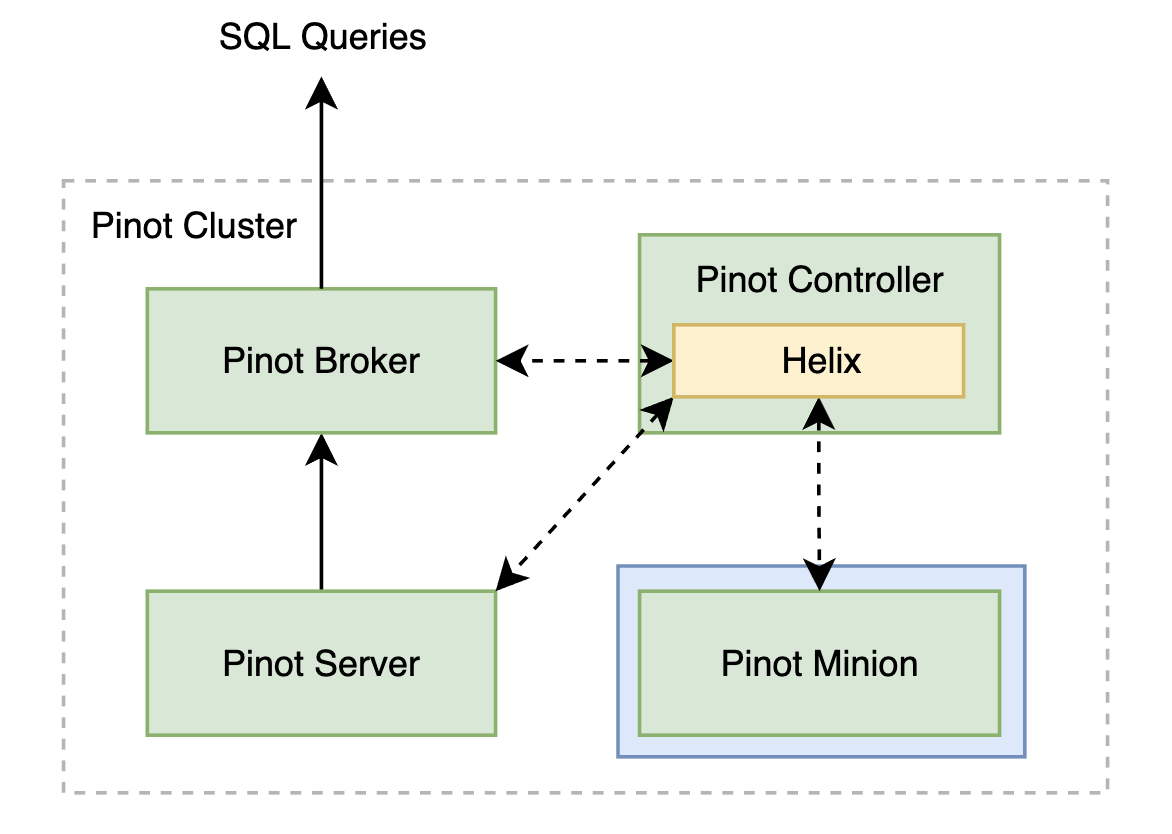
Figure 1: Minion within a Pinot cluster referenced from No-Code Batch Ingestion blog
StarTree Snowflake Connector
To use the Snowflake Connector, start by setting the following task configuration into the Pinot table config (Figure 2). We will introduce these properties as we walk through how the Snowflake Connector works. You can view the full list of Snowflake task configs here along with their description.
"task": { "taskTypeConfigsMap": { "SqlConnectorBatchPushTask": { "sql.snowflake.user": "startree", "sql.startTime": "2022-02-06T12:00:00.123Z", "sql.timeColumnFormat": "yyyy-MM-dd'T'HH:mm:ss.SSS'Z'", "sql.timeColumnName": "timeColumn", "sql.snowflake.password": "verysecret", "sql.snowflake.account": "account123", "schedule": "0 20 * ? * * *", "sql.bucketTimePeriod": "1d", "sql.snowflake.db": "STARTREE_SNOWFLAKE_DB", "sql.queryTemplate": "SELECT * FROM myTable WHERE timeColumn BETWEEN $START AND $END", "sql.className": "ai.startree.connectors.sql.snowflake.SnowflakeConnector", "sql.snowflake.schema": "PUBLIC" } } }Code language: JavaScript (javascript)Copy
Figure 2: Example StarTree Snowflake connector task configuration within the Pinot table configuration
Task Generation
Now that the Pinot table config contains the Snowflake ingestion task config, the Pinot controller will take care of scheduling Minion tasks. As shown in Figure 1, the Pinot controller plans the individual Minion tasks to be submitted to Helix when the ingestion job is first scheduled. The templatized SQL query ( sql.queryTemplate ) specifies the source table in Snowflake and a time range filter using the BETWEEN operator. This lets the query be broken into smaller time ranges, which can be executed independently across Minion tasks. The time range of each smaller query is determined by the configured time bucket property ( sql.bucketTimePeriod ). The example below (Figure 3) shows a query broken down into 1 day bucket time periods based on the time column.

Figure 3: Example of how the task generator maps a SQL query to multiple queries with 1-day time buckets
The smaller queries are mapped to individual Minion tasks that are submitted to the Helix task framework. Next, the tasks are picked up by a Minion task executor which handles the data ingestion from Snowflake.
Breaking ingestion into chunks not only allows for the workload to be parallelized but also provides for more granular recovery in case a task fails. The task generator references metadata in Zookeeper to know which time buckets have already been ingested. As a result, we are able to identify any time bucket gaps and queue them for re-ingestion.

Figure 4: Snowflake SQL ingestion through Minion framework
Task Execution
When a Minion executor picks up a queued task from Helix, it queries Snowflake through JDBC using the SQL template and assigned time bucket. After establishing a JDBC connection, the Minion task executor executes the query and iterates through the JDBC ResultSet, which is converted into a Pinot segment. Finally, the Pinot segments are pushed to the Pinot controller, which orchestrates the segments to be served and queried.
Scheduling and incremental ingestion
Pinot uses Quartz scheduler to periodically run the Snowflake ingestion. The ingestion schedule can be defined as a cron expression in the task configuration. Each time the ingestion job runs, it will attempt to ingest new data available in the Snowflake table since the last checkpoint (i.e. since the last run). Using the figure below as an example, let’s say data was ingested up to day 2 in a previous ingestion run. The next time the job is scheduled, the task generator will see that data was ingested up to the checkpoint (day 2) and will schedule new tasks to ingest data up to the current day.

Figure 5: Ingestion job configured with 1-day bucketTimePeriod before and after ingestion
A delay from scheduled ingestion time can be configured if ingesting data up to the current time is undesired. For example, if data for the current day has not yet been propagated to the upstream Snowflake table, then that day should not be ingested into Pinot since it is incomplete. The image below illustrates how data is ingested with a daily schedule using the ‘sql.bucketTimePeriod’ and ‘sql.delayTimeLength’ configurations.
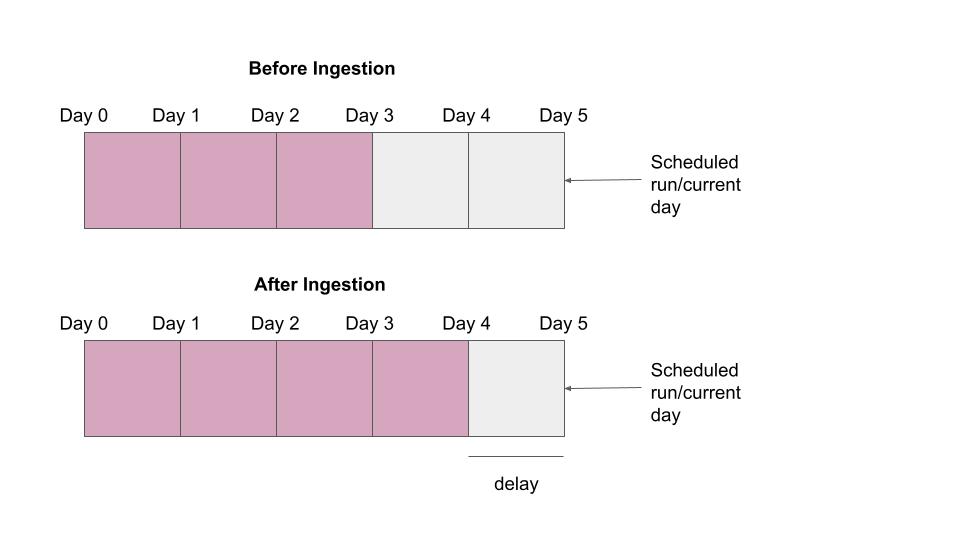
Figure 6: Ingestion job configured with a 1-day time bucket and 1-day delay before and after ingestion
Using these scheduling knobs, users can configure the connector to ingest new data continuously as it is written to the upstream Snowflake table. Depending on the users’ ingestion schedule and the amount of data to ingest, Minion workers can be scaled up or down to finish ingestion within the desired time frame.
Try it out now in StarTree Cloud
Although you can set up the Snowflake ingestion by manually creating the Pinot schema and Pinot table config ( see StarTree docs), StarTree’s Data Manager makes it easier. The Data Manager flow will help you locate your data in Snowflake, model your Pinot schema, and schedule your Snowflake ingestion job (Figure 7 and Figure 8). This is the quickest way to import your data from Snowflake and start querying it in Pinot. We encourage you to try it out!
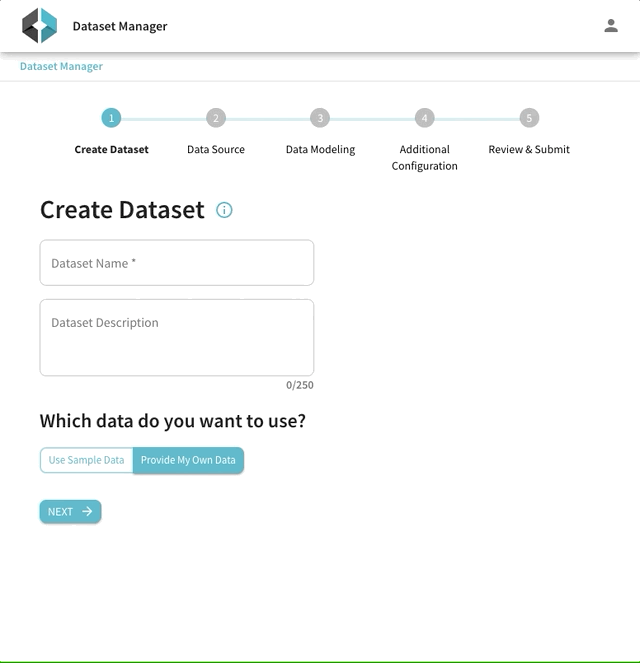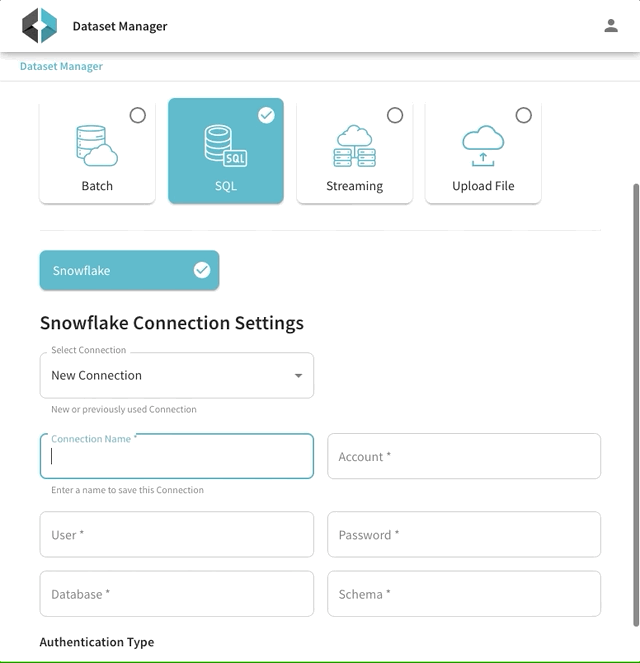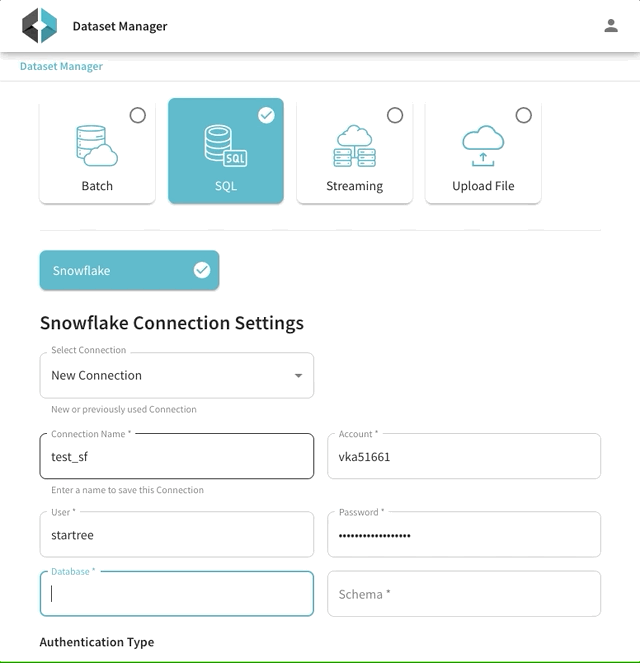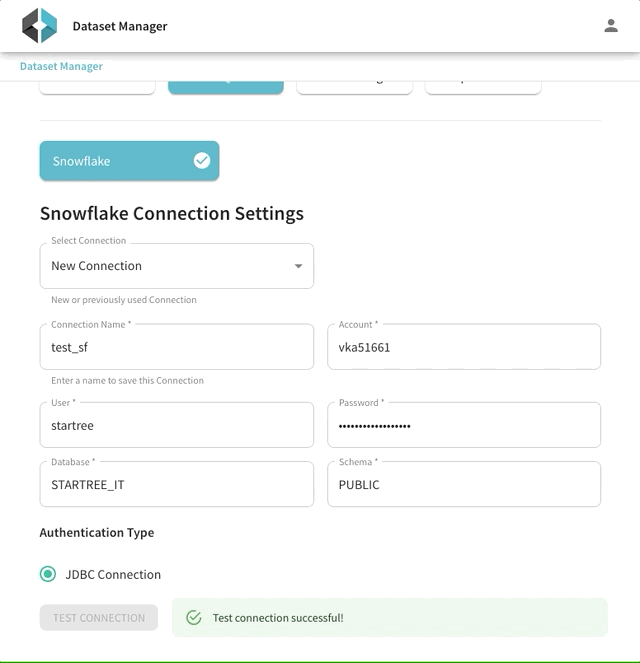
Figure 7: StarTree Data Manager makes it easy to test your Snowflake connection

Figure 8: StarTree Data Manager will help you locate your Snowflake table and will infer your Pinot table schema
Future of SQL Based Ingestion
The first version of the Snowflake SQL connector is now available in StarTree Cloud. We would love to get your feedback!
This connector unlocks a new JDBC SQL-based model of ingestion that will be applied to other data warehouse systems. Stay tuned for the upcoming Google BigQuery connector release and more!
