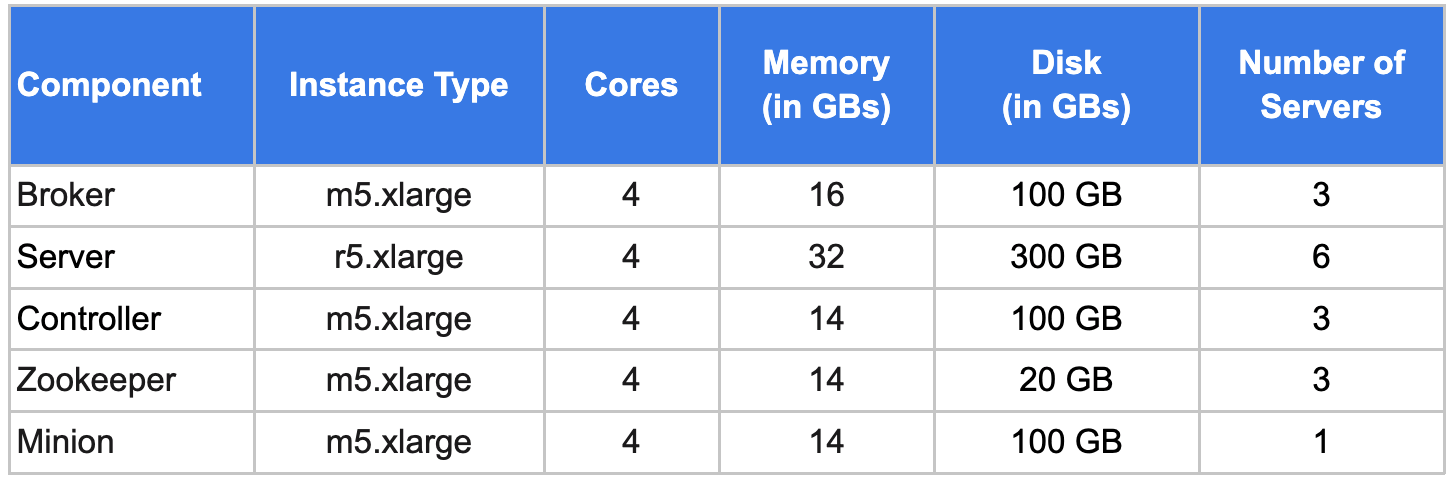
In part 1 of this two-part blog series, we looked at the key factors that a cluster admin needs to consider for the capacity planning of an Apache Pinot™ cluster.
In this part, we will walk you through how you can go about capacity planning for your use case using the key factors described in part 1.
Use Case: ClickStream
The key metrics to support this use case are as follows:
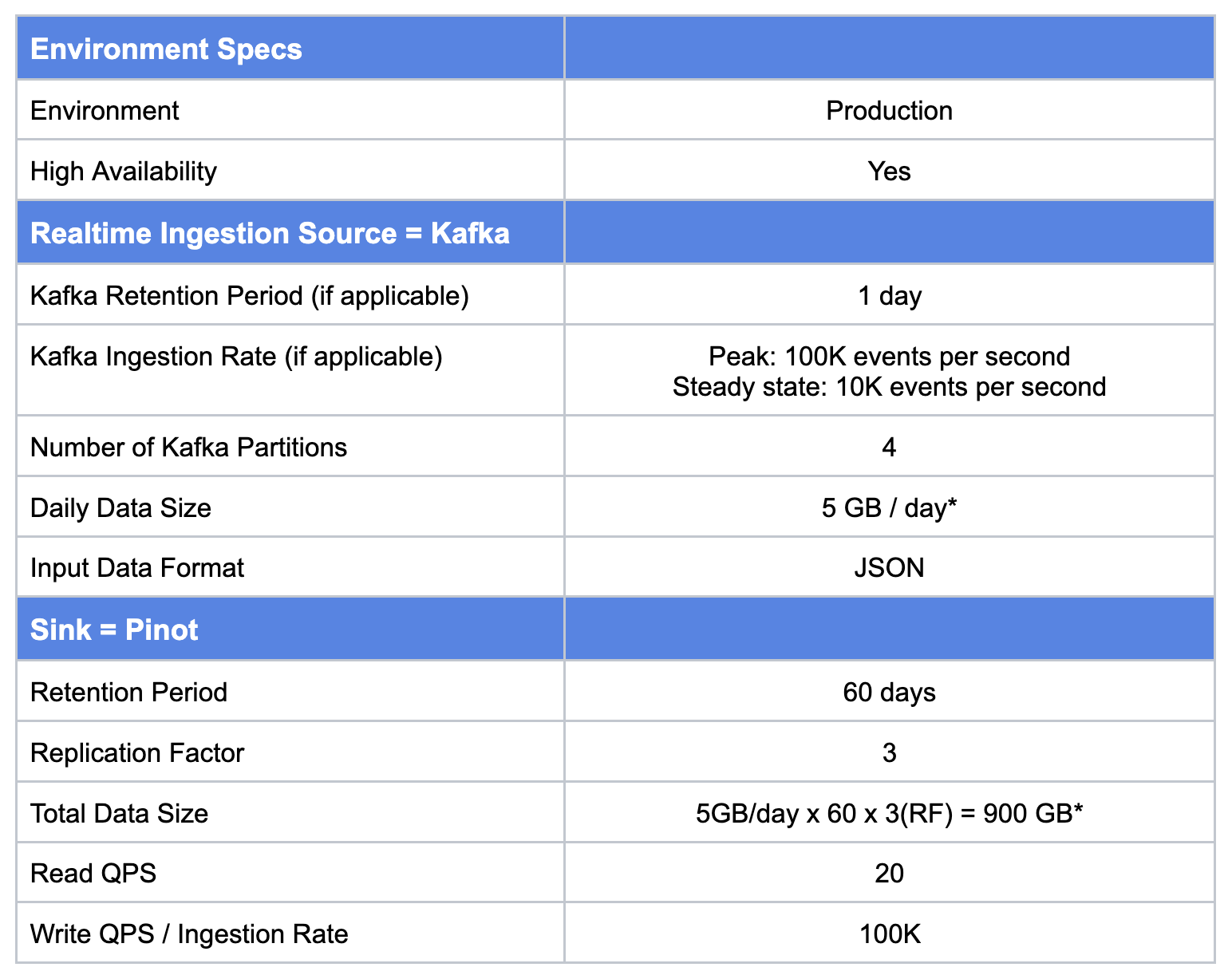
*For this use case, the input data is in JSON format. Pinot, being a columnar OLAP datastore, once the data is ingested in Pinot (and converted into Pinot Segments), the actual size in Pinot will be a lot lower. However, in this example, for the sake of simplicity, we have kept both input and segment size the same.
Iteration #1: Throughput
Let’s start with the Throughput requirement for this use case.
We will go with the assumption that we have a typical analytical use case targeting a certain concurrency(Queries per second) and have a target SLA in mind and we do NOT know much about other complementary KPIs, such as query patterns and query selectively at this point. We will introduce those additional KPIs in the subsequent iterations.
- Read QPS = 20
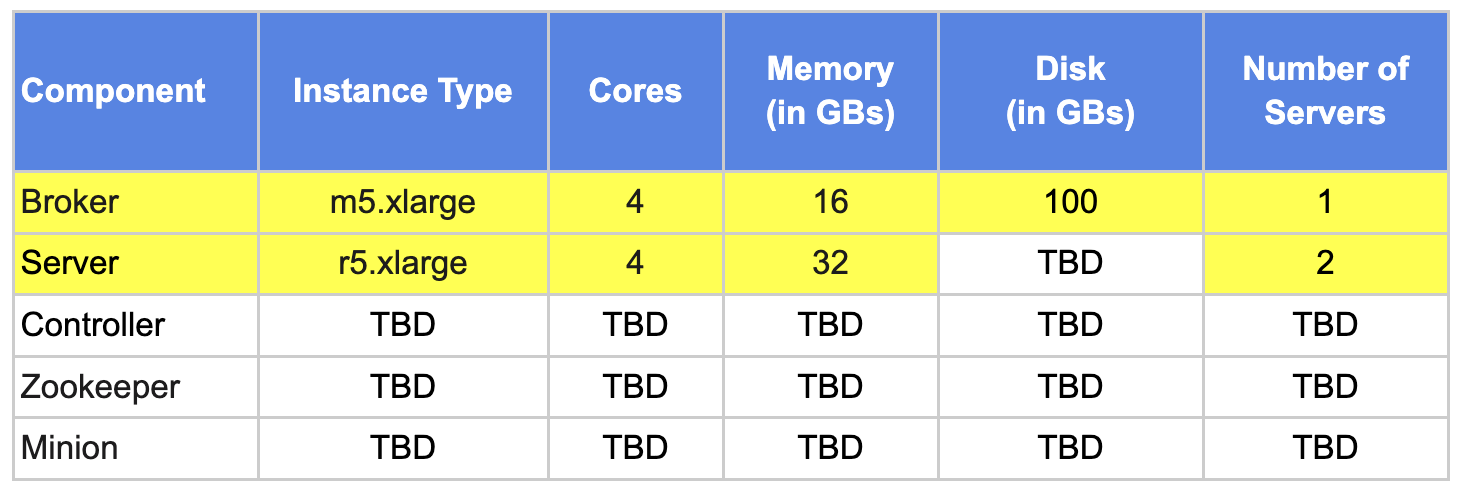
Broker: To support a Read QPS of 20, we will start with ONE instance of 4 core, 16GB RAM instance.
Server: To support a Read QPS of 20, we will start with ONE instance of 4 cores, 32GB RAM instance.
- Write QPS or Ingestion Rate defines the rate of ingestion from the streaming data source and corresponding resource requirements on the Pinot server side : 100K (peak), 10K (steady state)
- Number of kafka partitions = 4
Server: To support a Write QPS of as high as 100K with 4 kafka partitions, we would need 4 cores for that many kafka consumers in the cluster. ONE instance of 4 core, 32GB RAM servers would be able to accommodate this requirement.
For Read and Write QPS requirements combined, we would need TWO 4 Core, 32GB RAM Servers.
Iteration #2: Total Data Size
Let’s calculate the total data size required for this use case.
- Daily Data Size = 5 GB / day.
- Retention Period (in days) = 60 days
- Total Unique Data Size = Daily Data Size Retention Period (in days), i.e. 5 GB * 60 = 300 GB
Taking into consideration a few additional factors such as future data growth over the foreseeable future (few months to 1 year), it is best to plan ahead and add more safety buffers during this planning phase. Particularly because disk storage is relatively cheaper than compute. This buffer also helps with keeping the disk utilization optimal.
Important Note: Apache Pinot runs as a Fully Managed service in StarTree Cloud’s offering. In addition with the introduction of the Tiered Storage feature in StarTree you can now have compute only nodes in the Pinot cluster and storage entirely backed by cloud object store (for e.g Amazon S3).
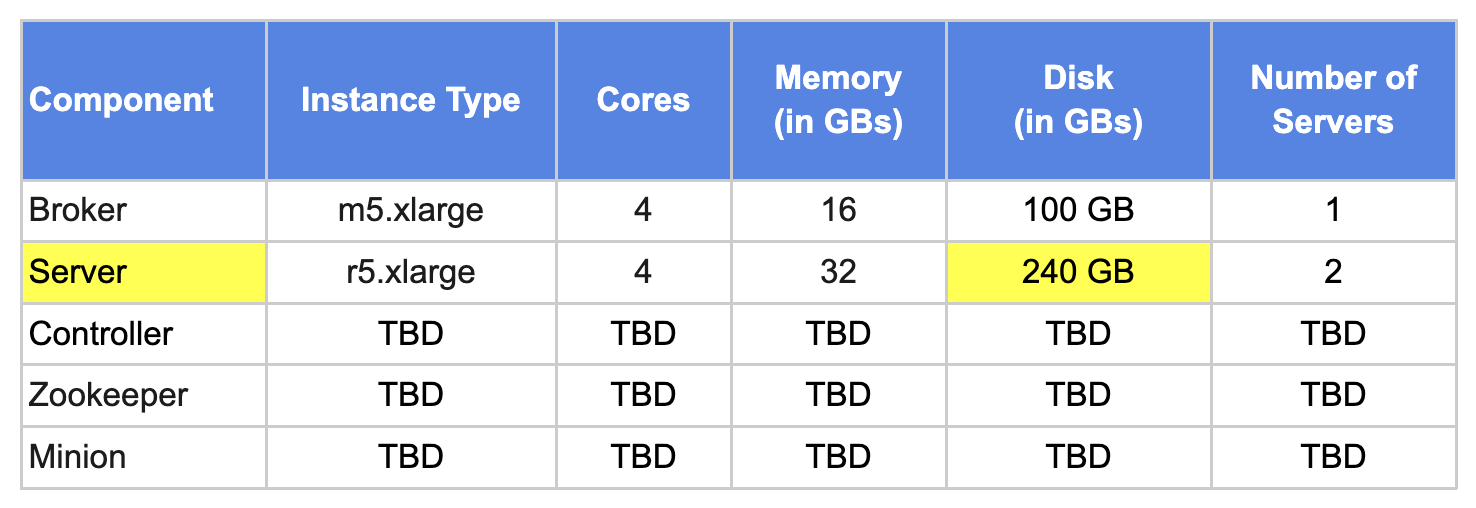
To support this use case, let’s add a safety buffer of 60% for future data growth. So total disk storage required = 300 GB + 60% = ~ 480GB .
With 2 servers, that would be ~240GB per server.
Iteration #3: Number of tables and segments
- # of tables: For this use case, we expect to have only ONE hybrid Pinot Table.
- # of segments: Pinot segments are generally sized anywhere between 100MB to 500MB. Ideal Pinot Segment size is somewhere between 300MB to 500MB.
Consider the following three options:
- Segment size = 100MB, total # of segments = ~9K
- Segment size = 300MB, total # of segments = ~3K
- Segment size = 500MB, total # of segments = ~1.8K
Considering the above options, total # of segments is only in thousands, ONE controller with 8 cores and ~30 GB RAM (or even 4 cores and 14 GB) should be able to handle this table and desired segment count.
Likewise, for zookeeper sizing, ONE zookeeper instance with 8 cores (or even 4 cores and 14 GB RAM) should be able to handle the workload.
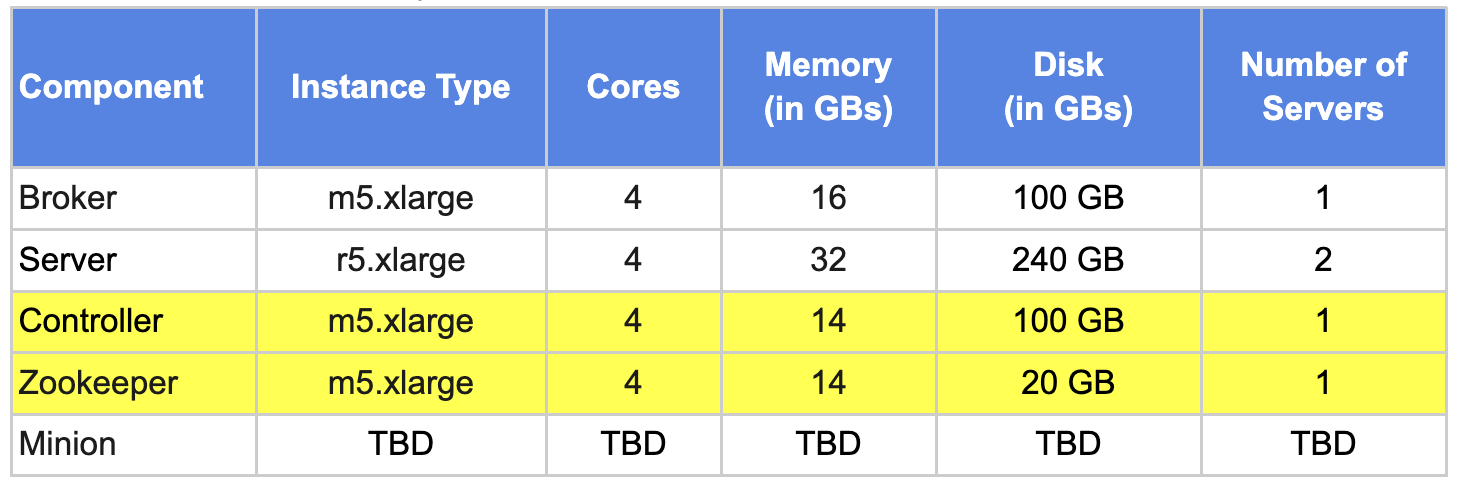
Iteration #4: Minion for backfill, upsert requirements (Optional)
We saw in part 1 of the blog that a Minion can be scaled in and out on demand. This use case requires minion support to run periodic backfill jobs. These jobs run once every week and there are times when this job has to be run on an ad-hoc basis too.
To accommodate this special requirement, we will add one Pinot minion instance with 4 cores, 14 GB RAM.
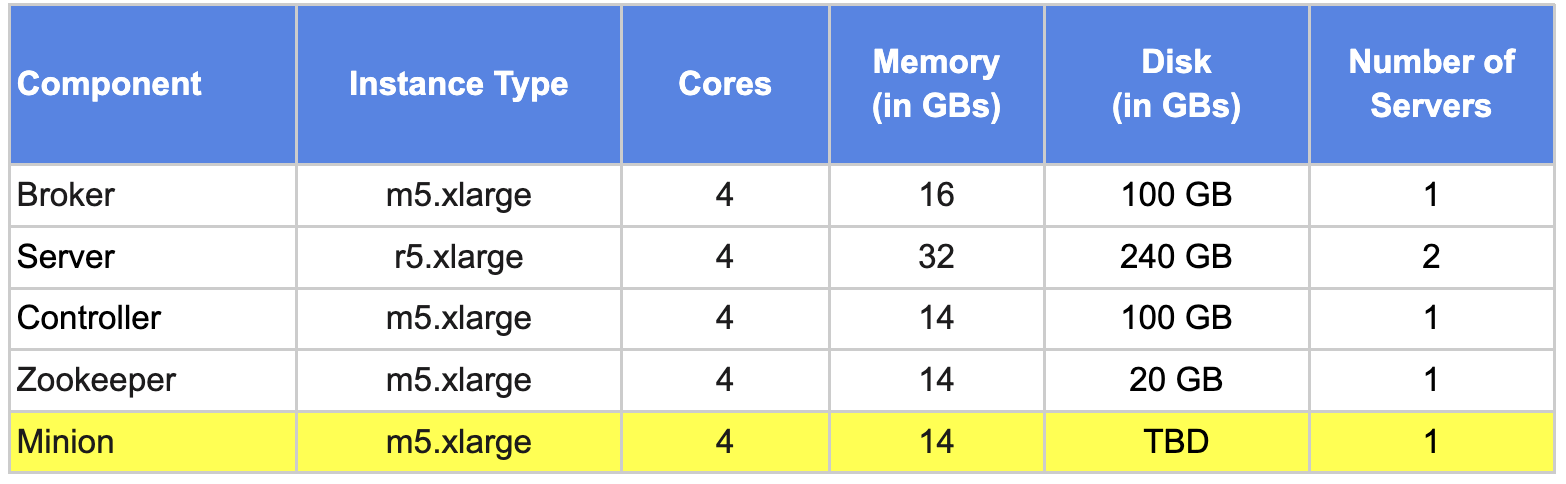
Iteration #5: Environment
- High Availability for Compute
Since this is a production cluster, we need to have at least three replicas of each compute component. This is to ensure that you have redundant (but sufficient) capacity and the cluster is fully functional during catastrophic events such as availability zone failure or single/multiple node failure.
Actions:
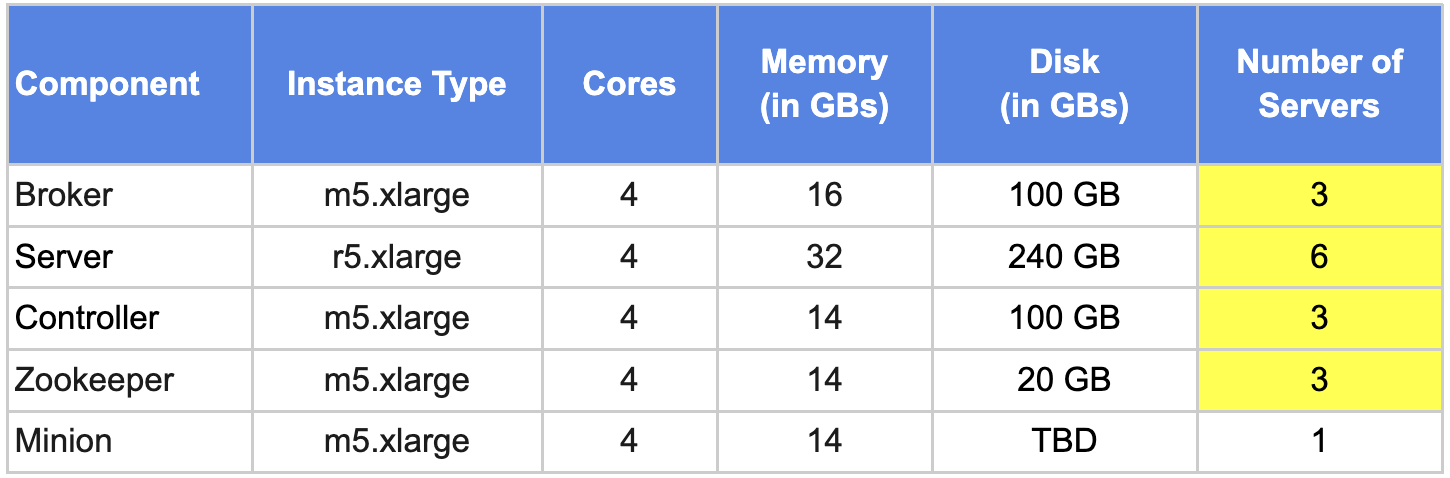
- Increase # of brokers, controllers and zookeepers from 1 to 3.
- Increase # of server instances from 2 to 6(to support 3 replicas).
Iteration #5a: Pinot Capacity Planning Table
- High Availability for Storage
For production environments, an ideal replication factor is 3.
Replication Factor:
- Replication Factor = 3
- Total Unique Data Size = 480 GB
- Total Data Size = Total Unique Data Size Replication Factor, i.e. 480 GB * 3 = 1460 GB.
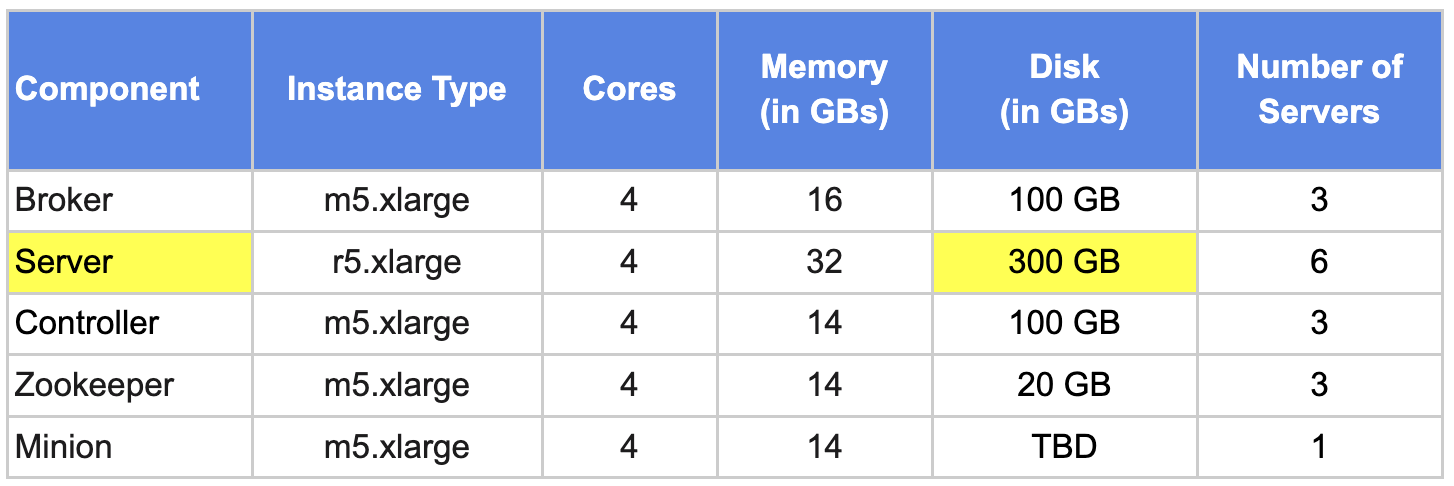
Taking into consideration the replication factor of 3, we would need to plan storage capacity for a total of 1460 GB data. With a total of 6 servers, that would be ~244 GB per server. Let’s round it up to 300 GB.
Iteration #5b: Pinot Capacity Planning Table
Replica Groups:
With the replication factor = 3, let’s also go with 3 replica groups that give higher scalability and performance. To accommodate this requirement, we would need to ensure that we have THREE distinct server groups that host one copy of all unique Pinot segments (480 GB).
The current size already accommodates this requirement by having THREE server groups of two servers each supporting up to 600 GB of unique pinot segments, corresponding config to enable this feature can be referred from this link.
Summary:
Use Case KPI Requirements:
- Read QPS = 20
- Write QPS = 100K (Peak), 10K (Steady)
- Kafka Partitions = 4
- Daily Data Size = 5 GB / day
- Retention Period = 60 days
- Replication Factor = 3
- Periodic backfill / updates = Yes
Final Pinot Cluster Specification: