Summary
- Major global bank safeguards over 70M transactions annually
- The bank combines the power of StarTree’s real-time analytics platform with Confluent’s data streaming platform for an end-to-end real-time fraud detection architecture
- The bank can now identify and flag potentially fraudulent transactions in as little as 7 ms
- Their real-time data infrastructure now supports >300K queries per day
Scaling payments for 70M transactions annually
A New York City–based global bank provides a payments platform that scales with their customer’s businesses. This platform is responsible for processing over 70 million transactions annually. With this much business at stake, the bank needs to rely on rock-solid technology, which is why they chose StarTree, powered by Apache Pinot, for real-time analytics.
This bank conducts a lot of work as white-label services: consumers deal with their favorite brands, while the bank provides those brands with the APIs and SaaS platform needed to build their payment processing services while securing the platform and its transactions.
The challenge: Proactively stopping fraud
The bank provides payment processing, fraud detection, compliance, and onboarding for small and medium business (SMB) merchants and payment system independent software vendors (ISVs). The critical requirement for its payments use case is quickly spotting and acting on fast-acting fraud vectors. The bank needs to aggregate all of the relevant dimensions — card used, total processing volume, and so on — and identify anything out of the ordinary. Then, they need to determine if anomalies are unusual but acceptable behavior, or, if potentially fraudulent, flag such activities for human investigation.
Payment fraud has been a huge and growing issue for every processor, vendor, and consumer alike. Juniper Research estimated that global merchant losses may total as much as $362 billion between 2023 and 2028. By 2032 the Nilson Report estimates payment fraud in the U.S. alone could exceed $165 billion annually. To counter this, trusted payment providers are waged in a constantly escalating battle of algorithms and advanced methods to detect, deter, and shut down threat vectors as they emerge and evolve.
Facing low throughput and high costs
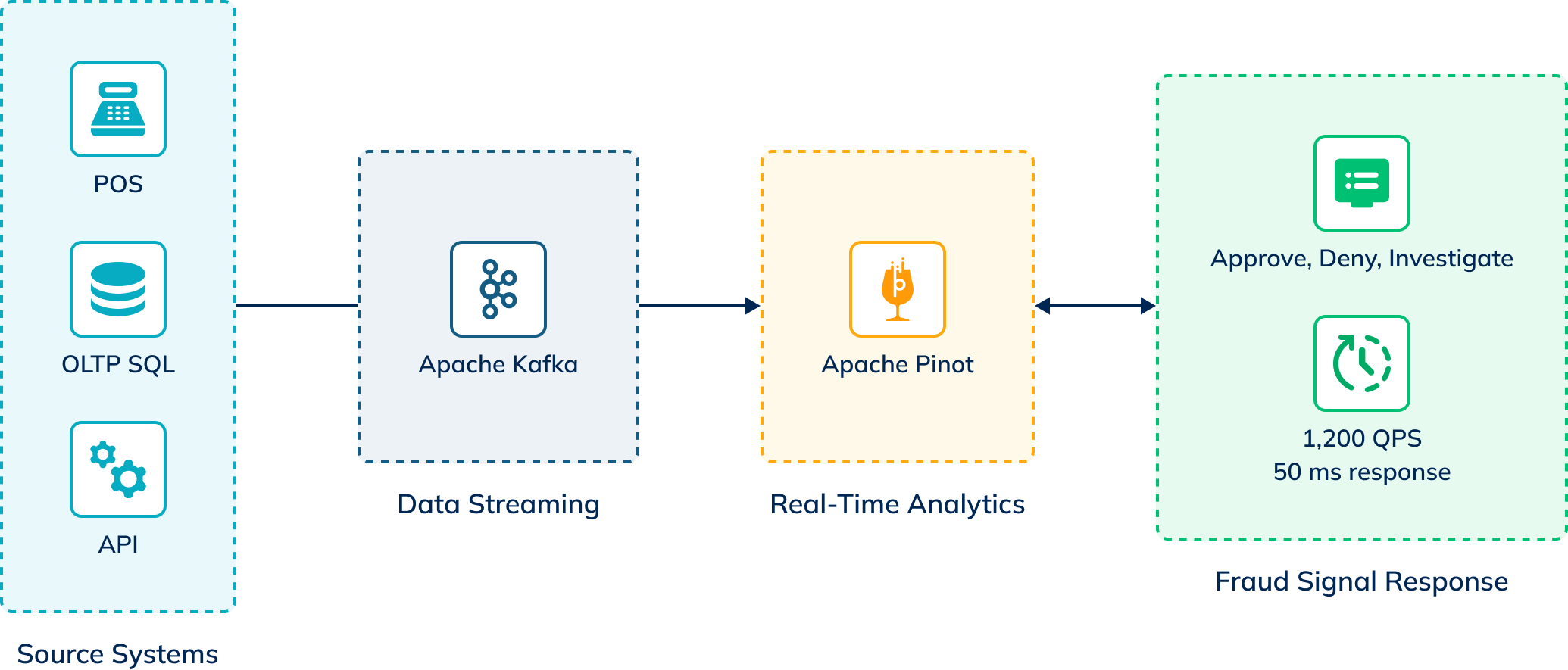
This international bank originally architected its fraud detection system with a combination of MySQL, Airflow, Apache Kafka, and Google Cloud Bigtable, which was adequate when volumes were smaller. On top of that, Google BigQuery was used as a data warehouse to conduct after-the-fact audit trails. MySQL was the database directly populated by customer and vendor Point-of-Sales (POS) payment systems, batch jobs, and external APIs. From there data was fed via Apache Kafka into Bigtable for analysis.
The problem with this architecture was that MySQL and Bigtable are both oriented for Online Transaction Processing (OLTP). Neither was designed for Online Analytical Processing (OLAP) workloads. On a technical level, MySQL and Bigtable are both row-oriented databases (the former SQL, the latter NoSQL). These make individual transactions fast, but range and full table scans of the data set — such as to perform aggregations — are extremely expensive computationally and complex to manage on a database not designed for this sort of work. The computational intensity also increased the associated cloud infrastructure spending.
Running computationally intensive aggregations against a transactional database resulted in significant performance degradations of latency and throughput. In an ever-evolving threat environment, relying solely on OLTP-oriented systems limited which specific features the bank could employ to detect fraud, and also limited the look-back period they could maintain.
The solution: Monitoring fraud in real-time
The bank sought to move its fraud detection system to an analytics-oriented database: StarTree, powered by Apache Pinot. Apache Pinot is a column-oriented OLAP database designed for real-time analytics and fast aggregations. Column-oriented databases allow for speed and efficiency of large scans of data and allow the data itself to be efficiently compressed, reducing both memory and disk use.
The bank integrated StarTree’s technology with that of Confluent, a re-architected cloud-native version of Apache Kafka, the leading data streaming technology. Using a Change Data Capture (CDC) connector for MySQL, the bank can easily and quickly establish Kafka topics of updates from the source transactional database and deliver them to StarTree as the downstream analytical database, allowing for seamless, secure, and reliable end-to-end data integration.
Within Apache Pinot, the bank stores individual transactions with related data from enrichment. This data is used when aggregations need to be done across different time frames. On top of that, other tables are used to explore data relationships between business entities for more contextual analysis.
After the migration, the bank’s fraud signals saw P99 query latencies dropping from 300 milliseconds on Bigtable to only 50 milliseconds using StarTree. Average P50 queries on StarTree dropped to as low as 7 milliseconds. If any fraudulent activity is flagged, the bank can now take appropriate action in milliseconds. At bursts of up to 1,200 queries per second (QPS), and a total of over 300,000 queries per day, the bank can now reliably meet their requirements with room to grow.

These performance improvements were accomplished through the use of an inverted index. The bank is also looking to employ the star-tree index, unique to Apache Pinot, which should provide even greater performance benefits.
The bank now has far greater flexibility and capacity to extend their analytics, adding new dimensions to their queries. We now have better performance, better TCO, freedom from limitations, greater ease-of-development, and quicker time-to-market for changes to our feature store.
Discover the power of Apache Pinot and Apache Kafka
If you believe your own use case bears more than a passing resemblance to this bank’s, you are not alone. There is a growing movement in the industry to offload OLTP systems and move analytical workloads to designed-for-purpose real-time OLAP databases.
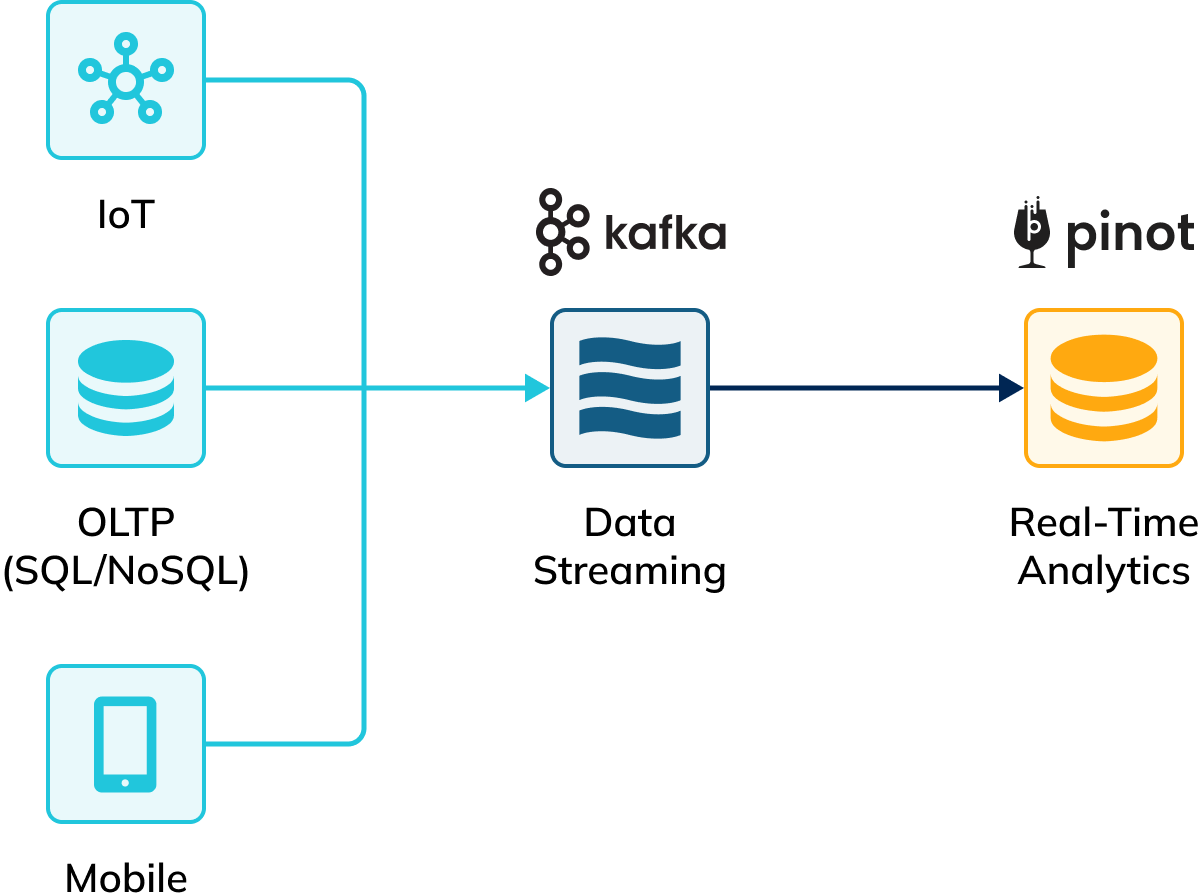
This is where StarTree shines. It was built for real-time, user-facing analytics — allowing sub-second queries with high concurrency against even petabyte-scale data. It seamlessly integrates data from Confluent, which is compliant with the Apache Kafka protocol.
Whether your data sources are IoT enabled devices, SQL or NoSQL databases, web apps, mobile devices, or other end-points, you can flow it all into Kafka topics, which can then be immediately ingested and indexed in StarTree. You can also combine real-time data with data from data warehouses to create hybrid tables.
Learn more about the partnership between Confluent and StarTree.
Try Apache Pinot on StarTree Cloud
The quickest way to experience the power of Apache Pinot is with StarTree Cloud . Request a Trial to get started with a no-commitment trial account to explore and test. When you’re ready to move into production, you can move into one of our cost-effective packages just right for your business.