
What’s next for Apache Pinot™? At a recent meetup, the Apache Pinot community presented the project’s roadmap for 2023.
The Pinot project was incubated in 2018 but has grown rapidly within the last five years. Ten thousand commits, a thriving community of 3,600 Slack members, 270 contributors, and over 100 production deployments later, the Pinot project continues to expand. The roadmap includes lots of exciting developments, and we wanted to call out some of the most noteworthy features that you can look forward to in the coming months.
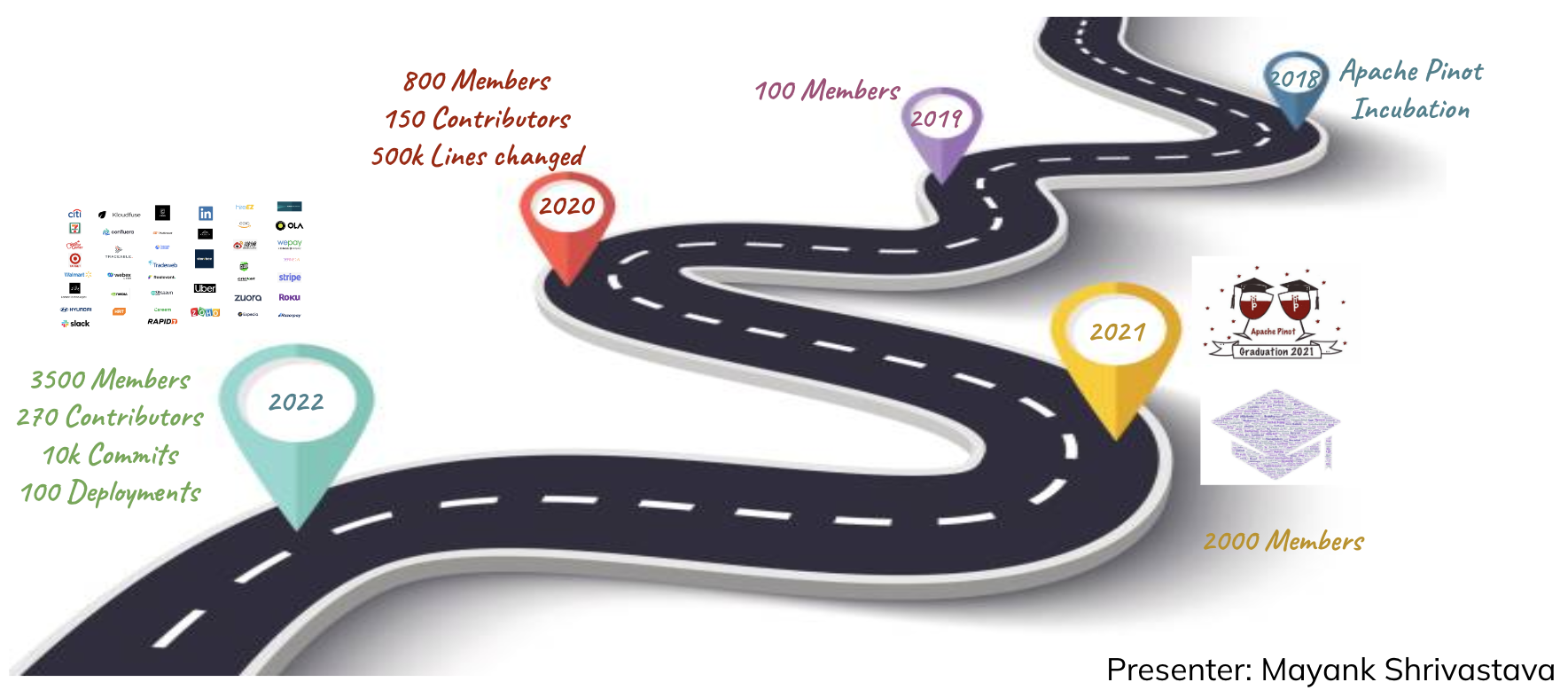
Source: Meetup: Apache Pinot Roadmap 2023 (StarTree, LinkedIn, Uber)
In the roadmap, you’ll find six overall themes: the multi-stage query engine, SQL compatibility, pluggability, ingestion, performance, and operability.
Multi-Stage Query Engine
Version 0.11 introduced the multi-stage query engine (aka the v2 engine). At the moment, it can only be enabled by setting a feature flag. However, this will eventually become the default query engine with full SQL support.
Rong Rong described the work that will be done to enhance the framework.
To enhance the framework, the addition of a pluggable planner extension will let you add customizable planner rules (#9165). This would then enable you to perform context-aware query plan optimization specific to your use cases.
It also covers unified runtime operators. Currently, several implementations of runtime operators, runtime plan expressions, and serialization formats exist. The plan is to unify them into just one implementation to improve the OSS user/developer experiences and reduce maintenance overhead.
Rong also described plans to implement pipeline scheduling and the capability to execute query stages concurrently as well.
Ankit Sultana presented co-located joins (#8951). Co-located joins will enable you to reduce shuffles, which the multi-stage engine must perform in some cases. They will make it possible to run queries that have very large query plans with less fan-out to multiple Pinot servers. Faster queries and the ability to run more of them concurrently will result.
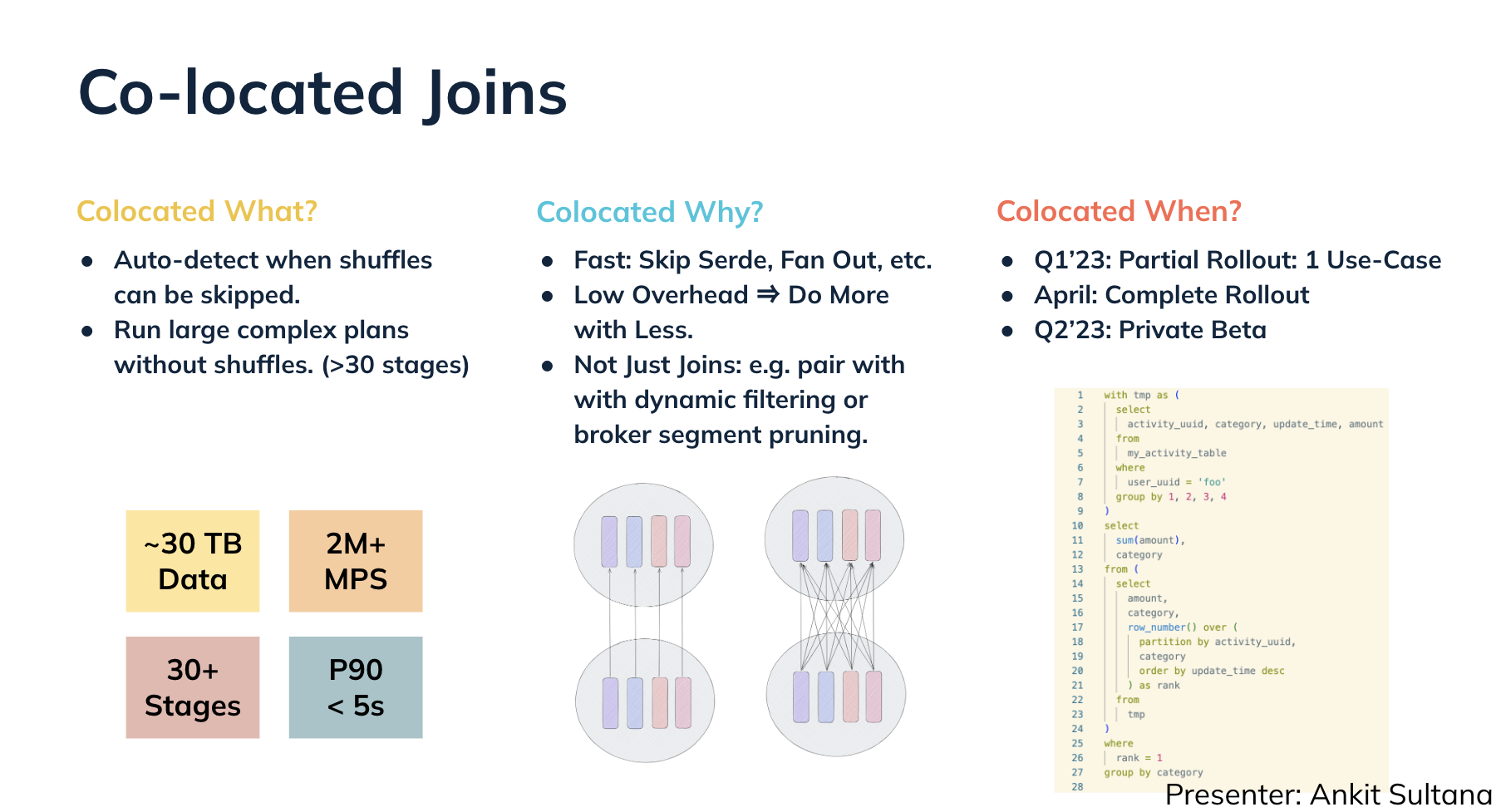
Jackie Jiang told us about local joins, where the goal is to push co-located joins to the projection layer where additional optimizations are possible. This should make the multi-stage engine as performant as the existing single-stage engine by pushing down filters and reducing the number of documents in need of projection.

SQL Compliance
Yao Liu presented SQL type compliance. A big part of the effort here involves improving null support (see design doc and #10252), which will make support-connector-generated SQL, such as Tableau, possible. After that’s done, type-safe function invocation comes next.
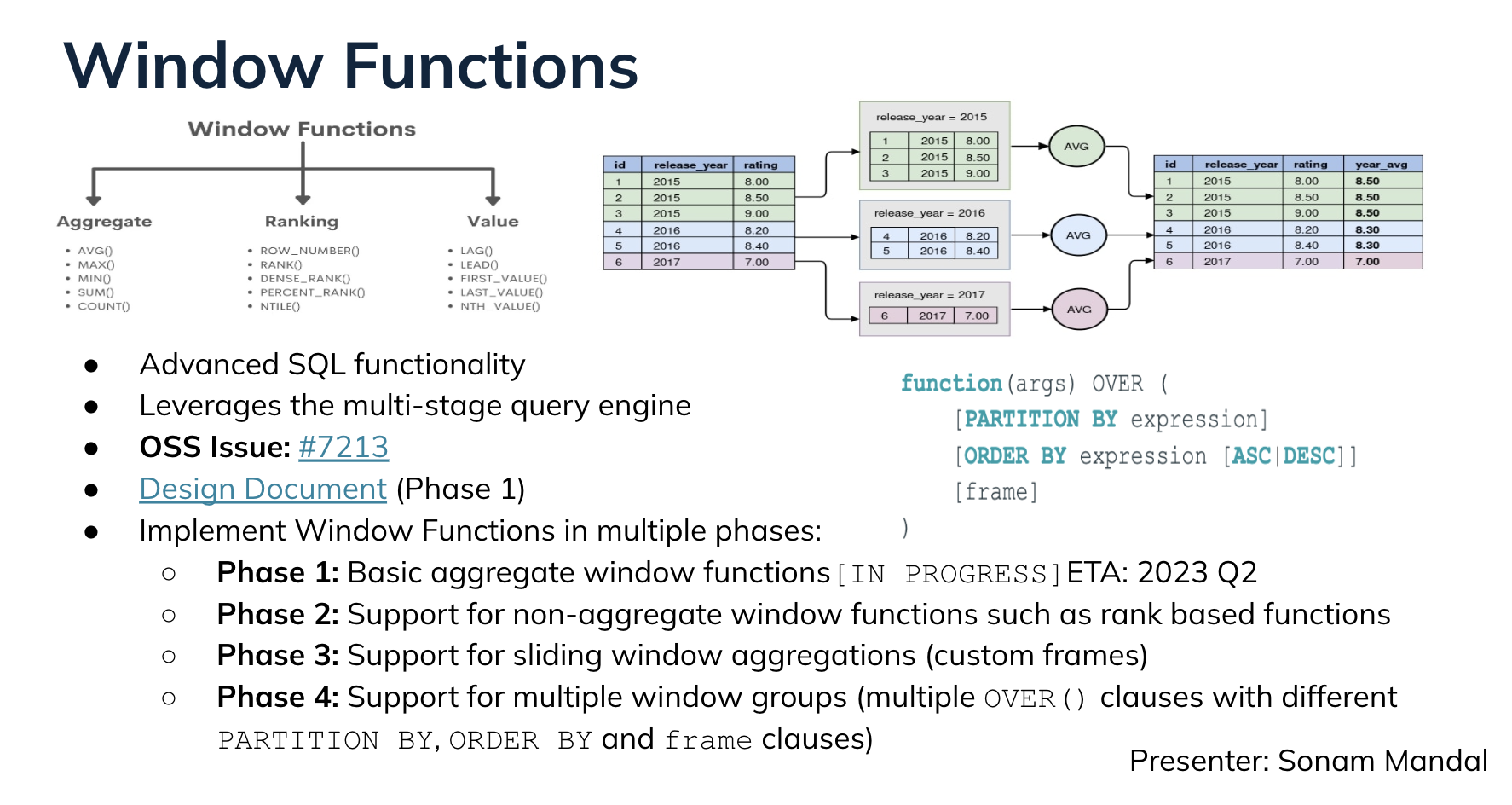
Sonam Mandal described the work being done to add support for window functions (see design doc and #7213) starts with basic aggregate window functions before moving on to non-aggregate functions, sliding windows, and multiple window groups.
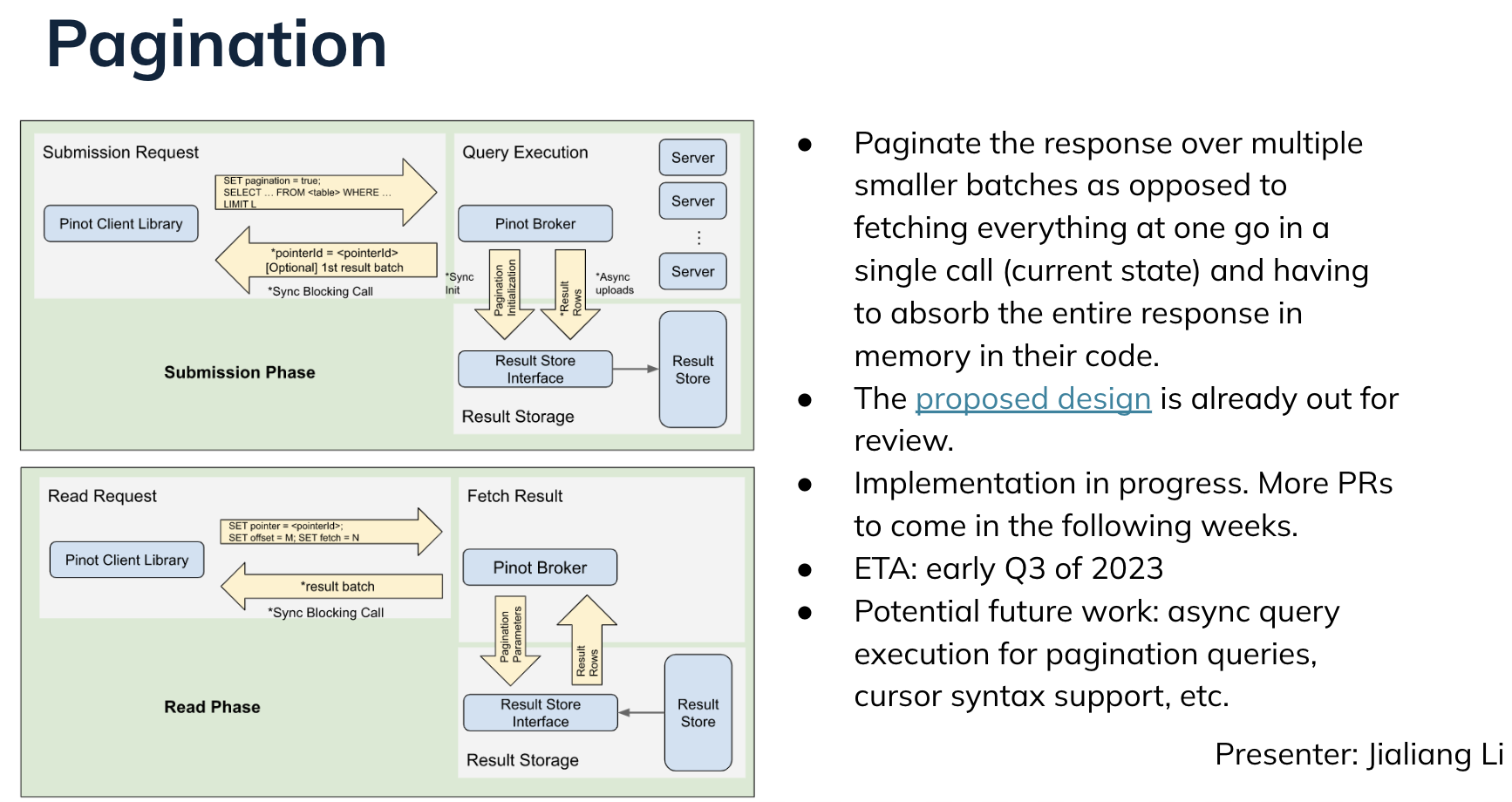
Pagination
Jialiang Li told us all about pagination (proposed design here ; #5246). The current, suboptimal approach for pagination does not work for many use cases. This year, the community aims to paginate over multiple smaller batches rather than fetching everything in one go and needing to keep a lot of data in memory (see proposed design doc and #5246). Potential future work includes the ability to execute asynchronous queries and support for cursors.
Pluggability
Gonzalo Ortiz described the plans for the index service provider interface (SPI) for Pinot (see PEP and #10183) will allow you to include new index times at runtime. This will make it easier for the community to plug in their own novel or proprietary indexing strategies without having to modify the Pinot code.

Ingestion
Pinot’s Spark connector recently added support for Spark 3 (PR #10394), but there’s more work to do. Caner Balci described the plans to add support for Pinot query options (PR #10443), like maxExecutionThreads, enableNullHandling, skipUpsert, and more.
After that comes logging and monitoring improvements, support for aggregation pushdown, and experimentation with write support using Spark 3’s BatchWrite interface.
Sajjad Moradi presented the work to address the issue of when Pinot stops ingesting data from data streaming platforms while segments are committed. This can take a significant amount of time, leading to consumption pauses that impact latency-sensitive use cases (#10147).
Wanting to delete data from an OLAP database might seem unusual because these data stores are usually append-only. But Navina Ramesh described the work that will make it possible to delete records from upsert tables (see design doc and #10452). This functionality is necessary for supporting streams from change data capture tools like Debezium, which handles DELETE events. It will only constitute a soft delete rather than actually getting rid of the record.
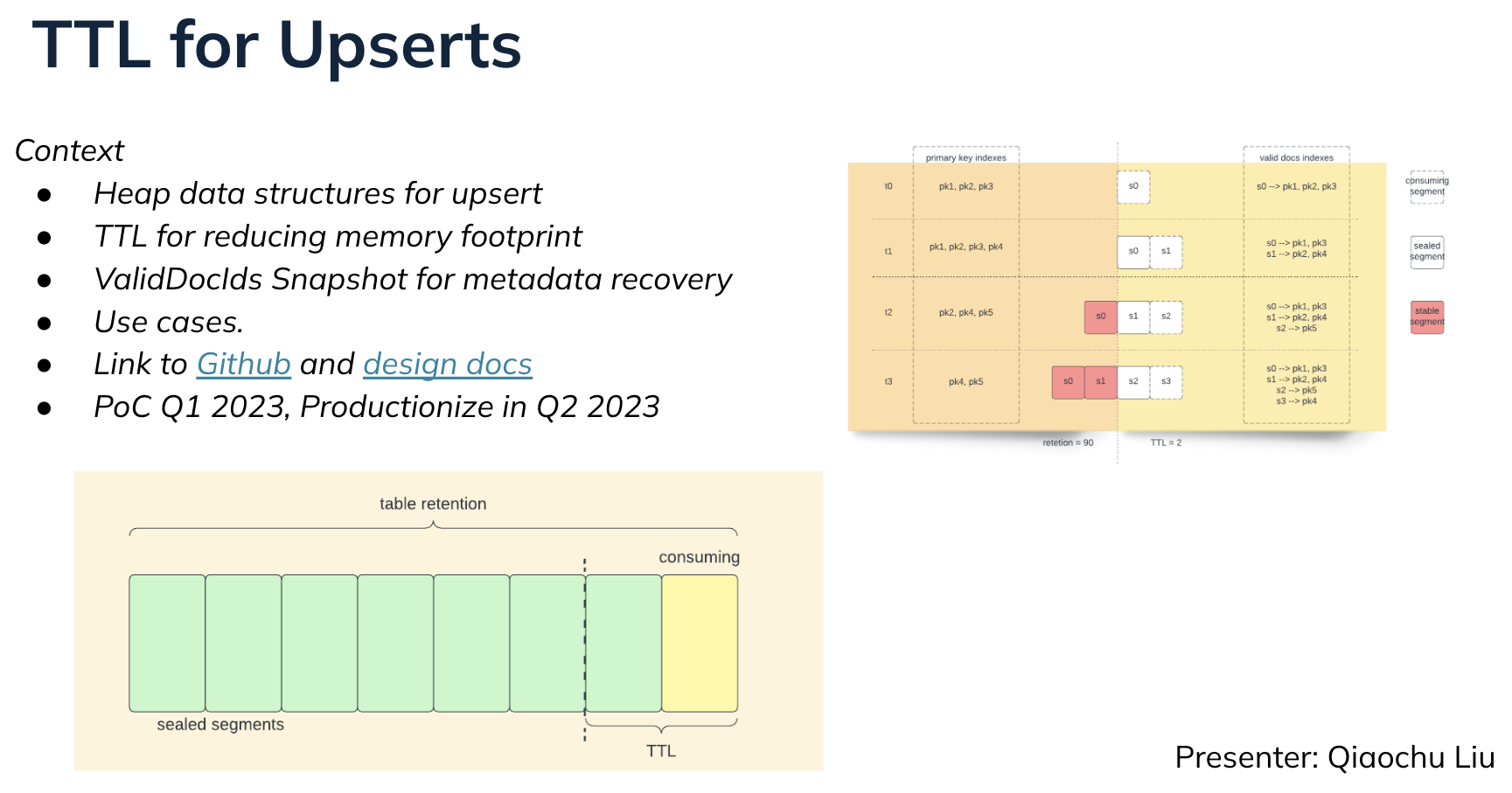
Qiaochu Liu observed that the upsert metadata (which contains the mapping from primary keys to record locations) takes a lot of heap memory. This problem especially impacts high-cardinality primary keys where the heap usage keeps growing in size and becomes the bottleneck of memory resources on the server, though for some use cases, the primary key contains a life cycle and will deactivate after the time window completes. A time to live (TTL) feature (see design doc and #9529) will allow for the removal of inactive primary keys, saving heap space.
Performance Enhancements
Yao Liu described the challenges of high latency and low-resource utilization for large-scale groups. This year, the community hopes to reduce contention and enhance parallelism, thereby making better use of memory and CPU usage. These improvements will lead to more efficient resource allocation and overall performance enhancements (#10498).
Performance enhancements further apply to distinct(count). At LinkedIn, a lot of interest surrounds distinct(count), but they’ve encountered some problems when using this functionality. The distinct(count) clause generates an in-memory set, which increases the risk of out-of-memory errors and puts pressure on the garbage collector. Then add into the mix the difficulties of handling high cardinality and utilizing the disk for spilling.
Jia Guo described the plan to build an off-heap hash table (#10500) will strive to solve this problem. The community could expand the approach to support spilling over to disk and could apply to group-by queries as well, leading to improved performance and resource management (#10499).
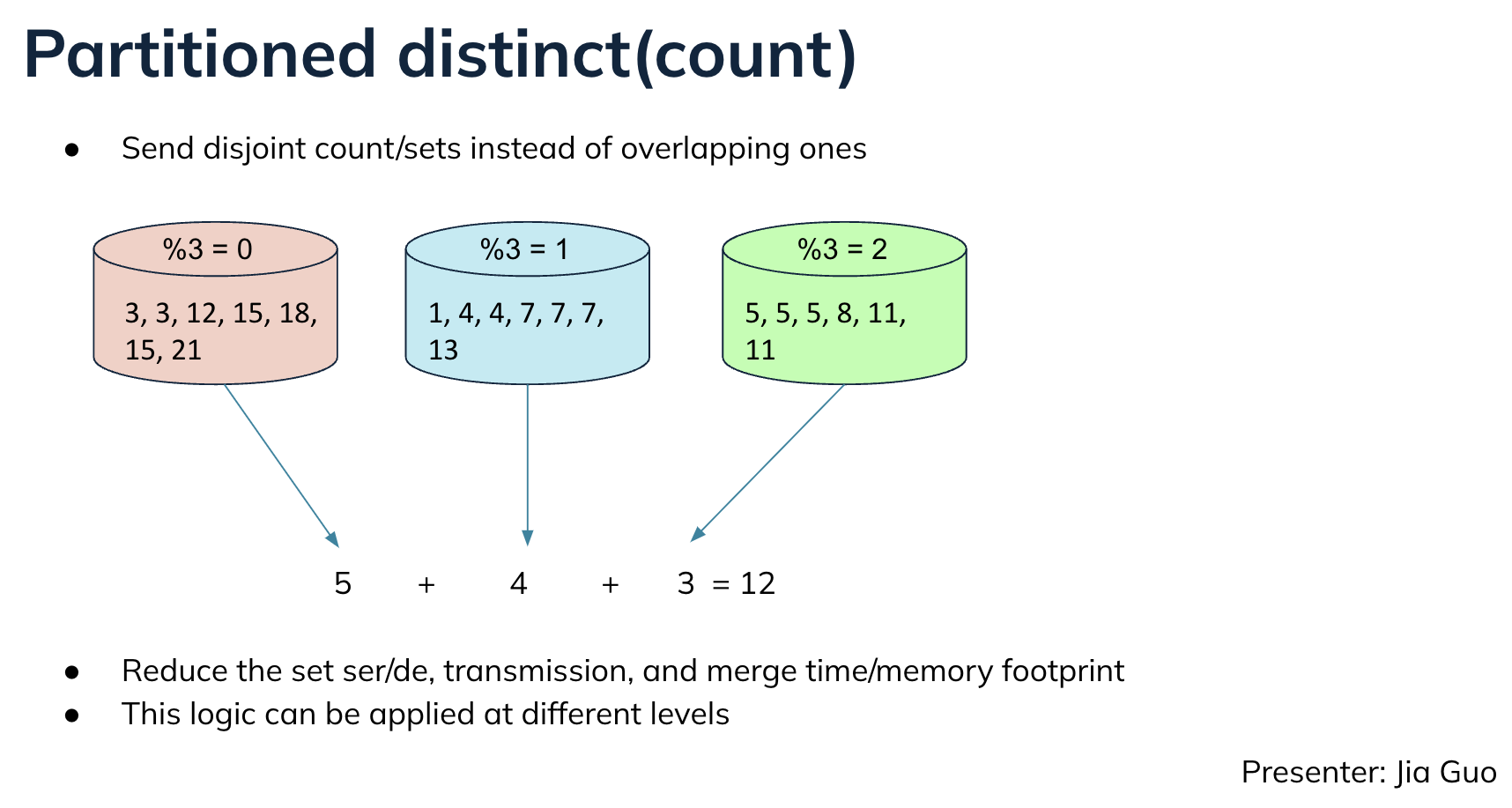
Another optimization that Jia presented is to the option to send disjoint count/sets from the server instead of overlapping, which will reduce the work of the broker when executing distinct queries.
Jia also presented the EXPR_MIN and EXPR_MAX functions (#6707) to find the min/max values in one column grouped by another column—proving much more efficient than writing a CTE join query.
Servers process queries in Pinot via a first-in, first-out fashion. This means that some queries can hog resources, leading to starvation. Vivek Iyer presented the plan to build a smart scheduling strategy that takes into account query priority, cost, and available resources. The feature will also include CPU/memory limits for queries and make it possible to control parallelization and reject queries when a server is overloaded.
Ting Chen (Staff Software Engineer, Uber) shares plans to use Pinot for large-scale log search at Uber. His team has identified compression and fast search as key factors and will use the Compressed Log Processor tool to losslessly compress text logs and search those logs without decompression (#9819, PR #9942).

Operational Improvements
At the moment, Pinot supports Groovy scripts for user-defined functions (UDFs) but disables them by default due to security concerns.
This is not an ideal state of affairs, so Haitao Zhang described functionality that will only authorized users could register Groovy functions (#9365), and other users then could access those functions in transformation functions or queries, that would be pretty great. Fortunately, the community is working toward this end.
Additional Highlights
Other features to note include:
- System metadata tables
- Upgrade to Java 17
- Server-level ingestion throttling
- Compaction for upserts
- Tenant-level rebalancing of Pinot components
- Pinot K8s operator: So far, Pinot has provided Helm Charts support, which serves the majority of needs for Pinot deployment. The Pinot K8s operator will enable better scaling and heterogeneous hardware support, including local SSD support for better performance.
Summary
There’s a lot of work planned for 2023, and hopefully, some of your desired features are being worked on. Pinot is released on a quarterly basis, and you’ll see the features added across the year.
It’s going to be a fun year for the Pinot community, and we’d love for you to join in on the journey. If you have questions about the roadmap or would like to see other specific features added, we welcome you to share in the Apache Pinot Slack community. I hope to see you there!
