
Apache Pinot® is purpose-built to support low latency queries at very high throughput, enabling real-time user-facing analytics. It can ingest data from streaming sources like Apache Kafka® and Amazon Kinesis in real-time to make fresh data available for queries instantly. It can also ingest data from batch sources like S3, ADLS, and GCS to load Pinot with a huge amount of data quickly and keep it in sync with the data sources. Having both past and present data all managed within Pinot allows one to query the whole world in real time.
As in the figure below, the real-time ingestion is accomplished with the Pinot REALTIME table, which keeps pulling data from streaming sources like Kafka. But the batch ingestion can be done in various ways. There are command-line tools to help prepare Pinot segments but they are not automatic and scalable. One can also run a Spark or MapReduce job to preprocess the batch data with transformations, sorting, or partitioning; and then generate segments and push them to Pinot. Although scalable, many users find it non-trivial to run a Spark or Hadoop cluster to ingest data into Pinot, particularly if they have to set up such data infra from scratch. In addition, it’s critical to have the job scheduling, monitoring, and failure handling all in place to enable automatic and reliable batch ingestion for Pinot.
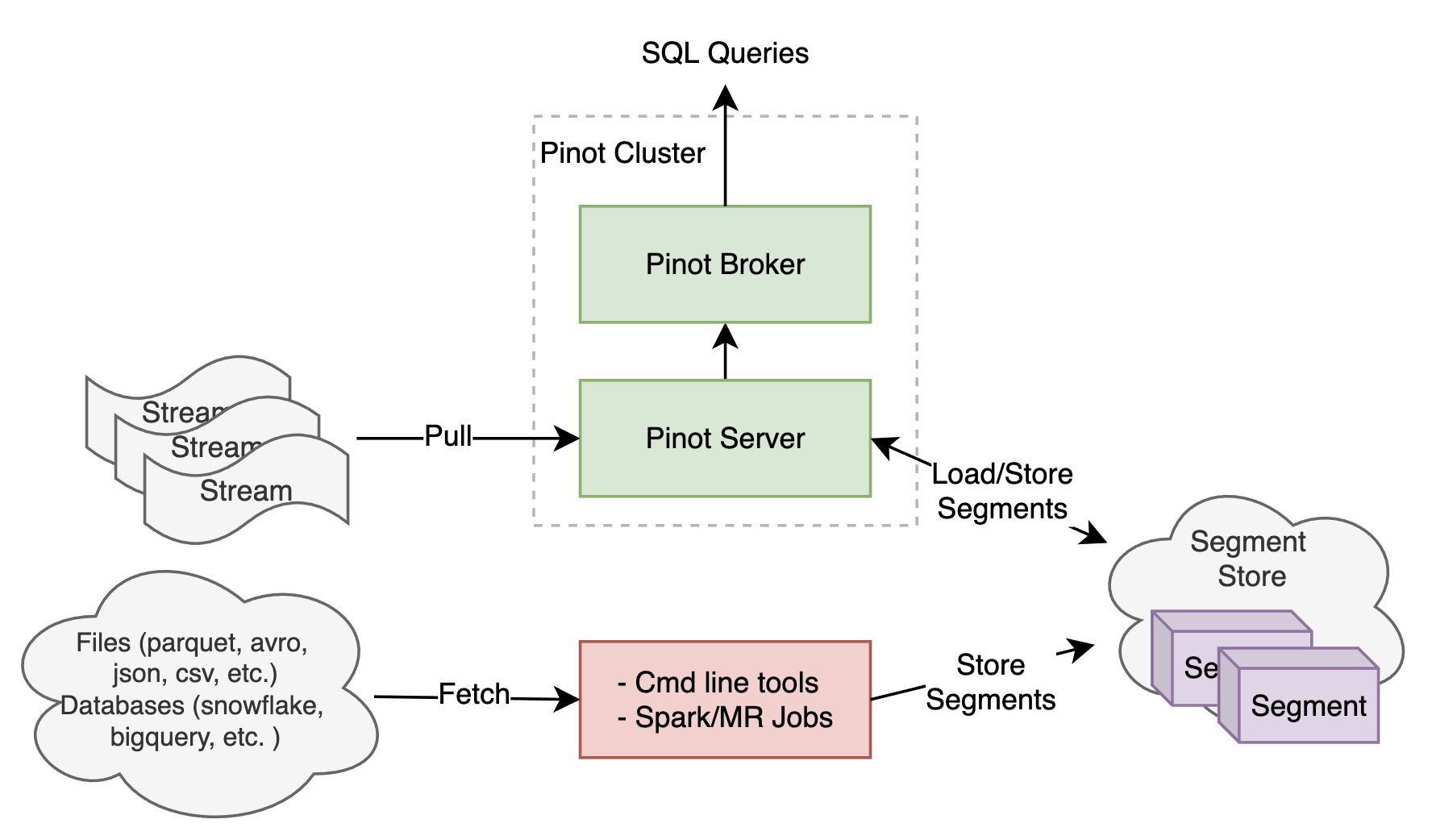
Fig. The current methods to ingest data into Pinot
StarTree’s Automated, Self Serve Batch Ingestion
StarTree provides a cloud-native, fully managed real-time analytics platform using Apache Pinot. To make it really easy for our customers to enjoy the speed of Pinot, we provide an automated way to do the batch ingestion in StarTree cloud without the need for any external data processing systems. We have built an automatic data ingestion framework with Pinot Minion. It can ingest data files from S3, ADLS, and GCS, and also tables in BigQuery or Snowflake. In addition, job scheduling, monitoring, and failure handling are all supported out of the box to make it easy to use.
Pinot Minion
The Minion task framework is a native component of Apache Pinot. It has been built to offload computationally intensive tasks away from the other Pinot components. This helps in conserving resources for serving low latency queries and real-time stream ingestion. It can be added to an existing Pinot cluster to execute tasks as provided by the Pinot controller and dynamically scaled up and down as needed.
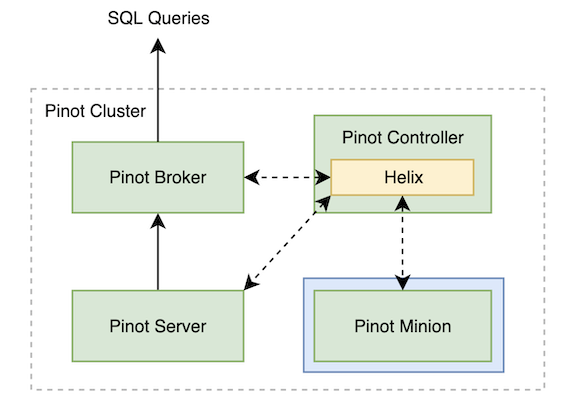
Fig. Pinot Minion is native to a Pinot cluster
This Minion task framework is built around the Apache Helix® task framework to schedule and monitor the Minion tasks in a reliable and scalable way. As depicted in the diagram below, this framework consists of a task generator and many task executors. As the name suggests, the task generator is responsible for breaking up a given task into multiple smaller subtasks, which can run on many minion workers in parallel. Each subtask is wrapped in a task executor to run to its end in a single thread. The task generator can be triggered with the HTTP endpoints on the Pinot controller or scheduled to run by setting a cron expression in the table config. The workers then start to run the subtasks once they receive the task configs generated by the task generator. The execution states of those subtasks can be tracked by the Helix task framework reliably for the task generator to inspect.
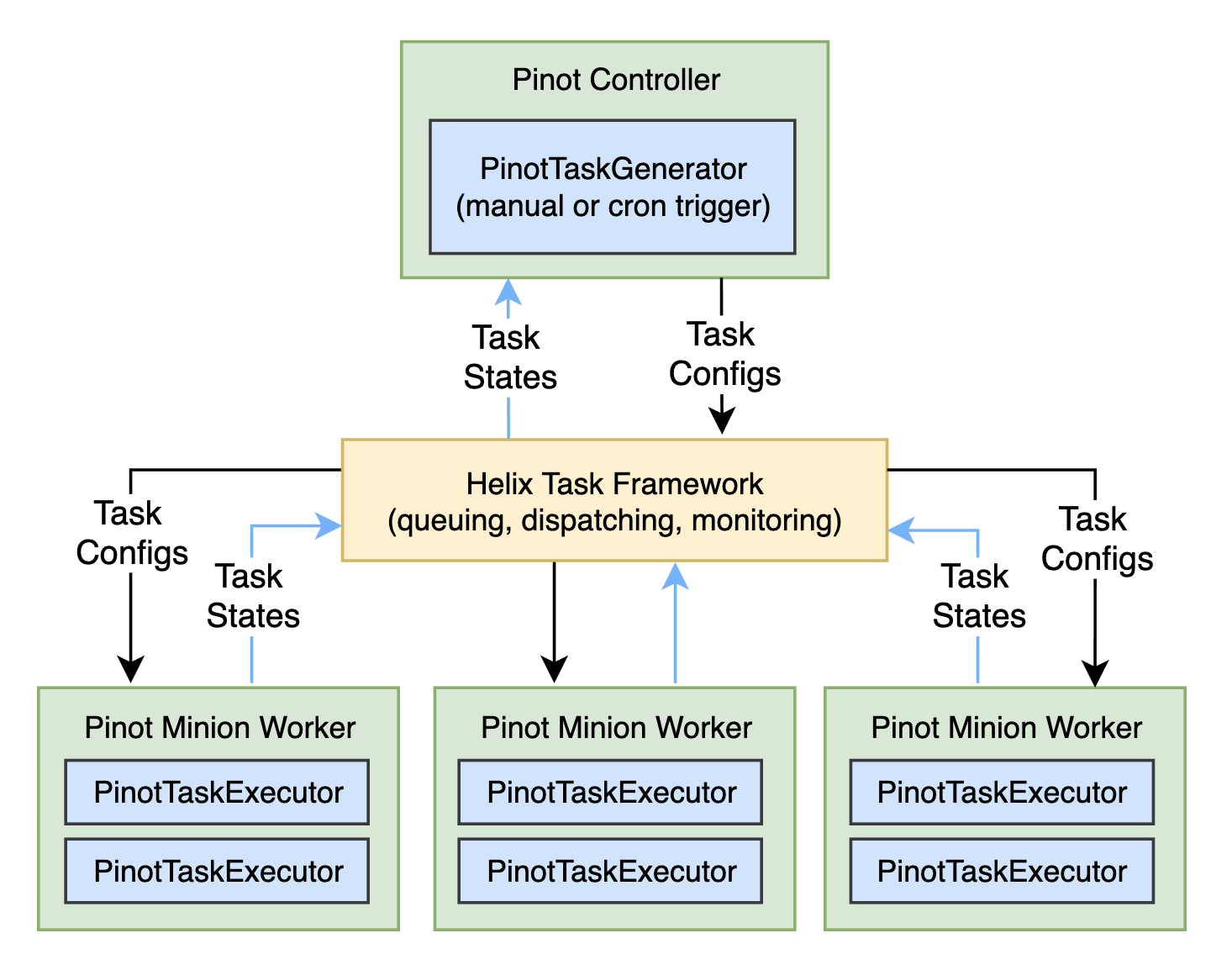
Fig. Overview of the Pinot Minion task framework
This framework can be customized via two main interfaces: PinotTaskGenerator and PinotTaskExecutor. For anyone interested in creating new tasks, you can implement the PinotTaskGenerator interface with your own policy for breaking up a task into smaller subtasks, e.g. to detect and retry failed ones when generating the next batch of subtasks. Similarly, you can implement the PinotTaskExecutor interface for the actual data processing. For example, to convert files into segments, you may need to download the input files, preprocess them according to the table config, generate the segments, and upload them to the segment store.
Many types of Minion tasks have been built for Pinot, as summarized in the figure below. For example, the MergeRollupTask is used to merge segments to larger ones and pre-aggregates data as configured for better query performance; and the PurgeTask for GDPR purposes. In the following sections, we’d like to share how we have leveraged Pinot Minion to ingest batch data reliably in StarTree cloud.
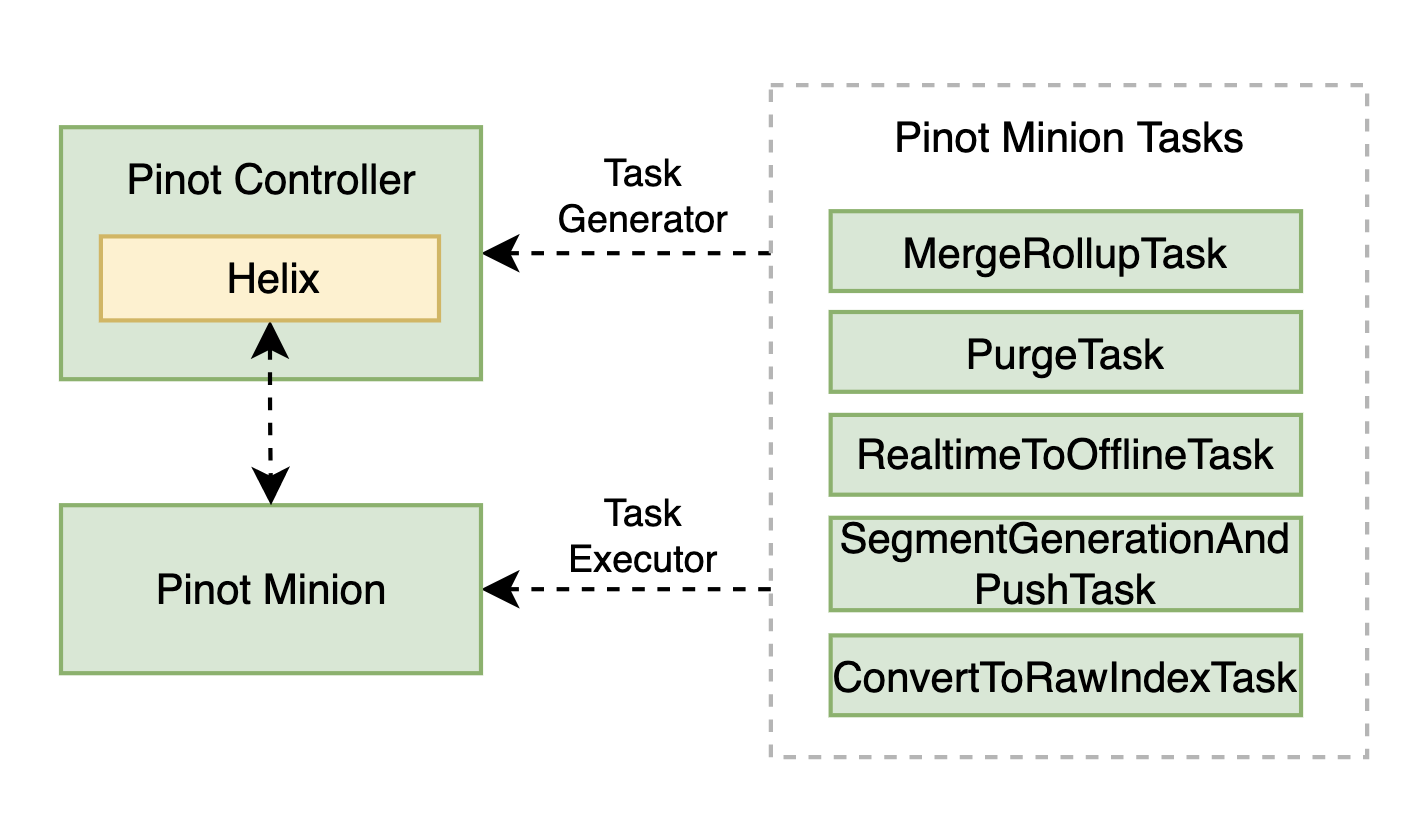
Fig. Pinot Minion tasks for various use cases
StarTree’s Data Ingestion with Minion
In StarTree cloud, we have automated multiple data ingestion tasks with Pinot Minion. They allow users to ingest data from many kinds of batch sources, like files in data lakes built on object stores such as S3, GCS, or ADLS; tables in data warehouses like BigQuery or Snowflake; or segments from other Pinot tables. We have also added tasks that can optimize segments continuously based on the query patterns. These tasks share many common design ideas. In this blog, we will focus on the FileIngestionTask. The other tasks will be discussed in detail in future blogs.
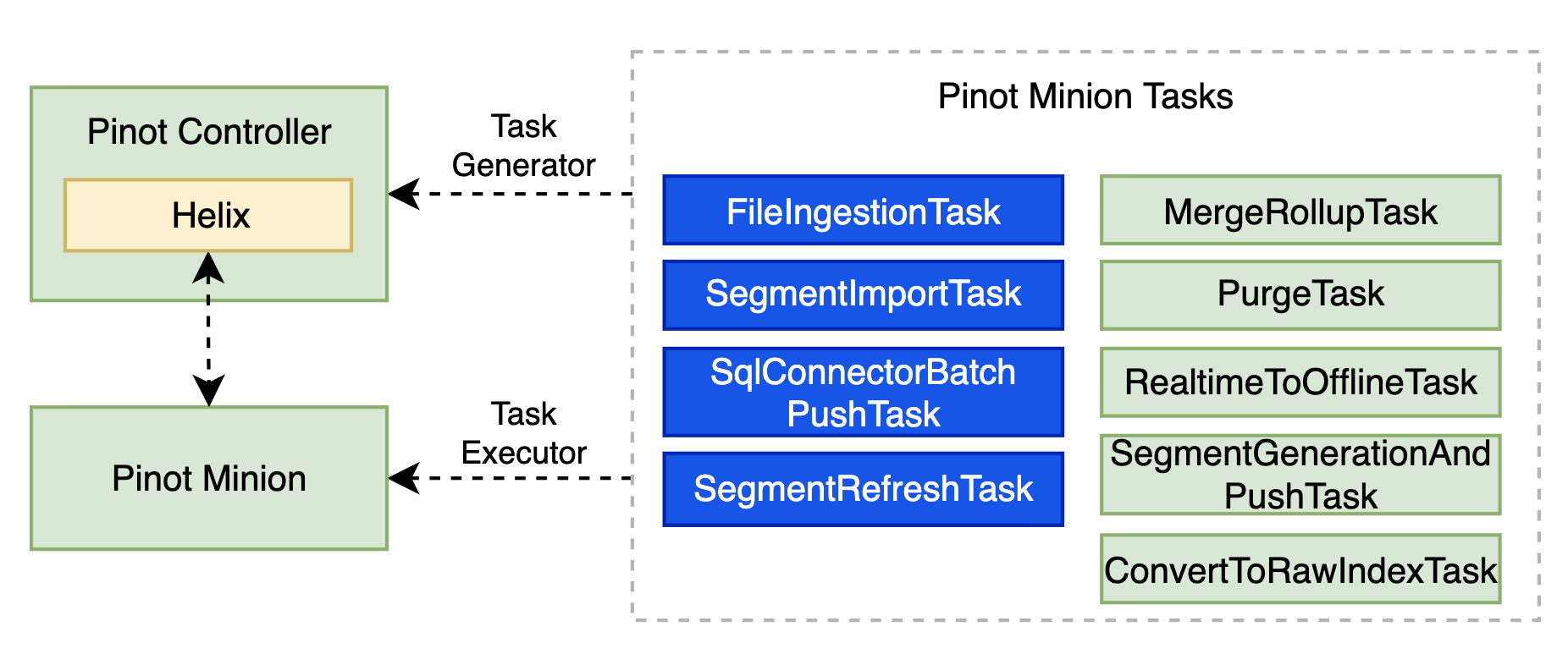
Fig. Additional Pinot Minion tasks available in StarTree cloud
We have built a new minion task called FileIngestionTask as in the figure below, for automatic and reliable batch data ingestion in StarTree cloud. In general, the task fetches input data files from the source, converts them into Pinot segments, and then imports the segments into the Pinot cluster. But in particular for flexibility and correctness:
- Segment Processor Framework a library from Apache Pinot has been reused for flexible data preparation;
- Checkpoint Framework is added into the task for the exactly-once guarantee in the presence of failures.
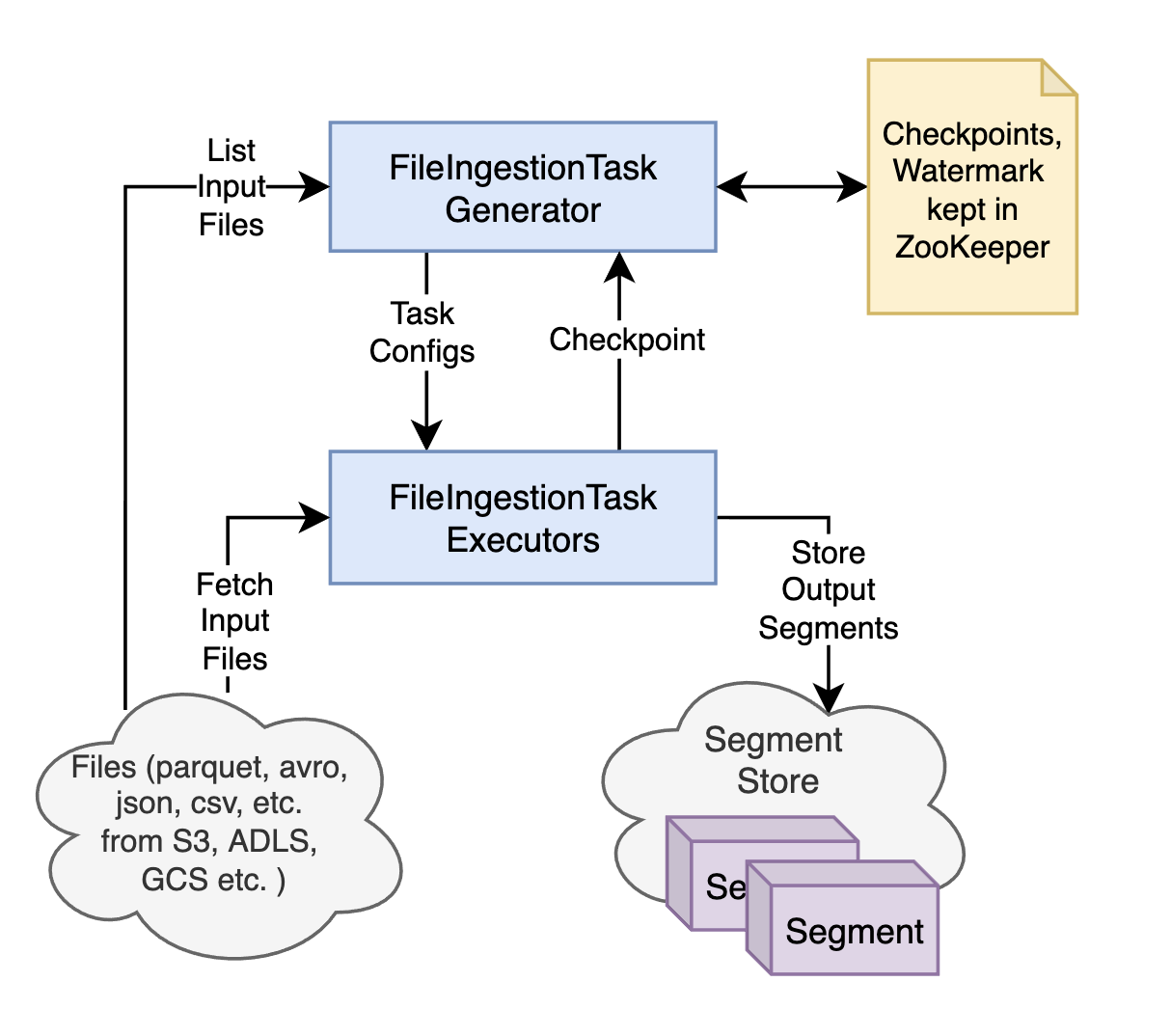
Fig. The general architecture of FileIngestionTask
Segment Processor framework
The Segment Processor framework is a library in Apache Pinot initially built for segment management tasks like RealtimeToOfflineSegmentsTask and MergeRollupTask. We have reused it in FileIngestionTask to preprocess the input files with sorting, partitioning, transforming, or rollup in order to generate segments that can serve the queries efficiently. It processes the data with map and reduce phases, where record level transformation, partitioning, and filtering happen at the map phase; sort, rollup, and dedup at reduce phase. The results from reduce phase are used to generate the segments.
It’s not uncommon to find many small data files in the input folder. Previously, we had to use Spark to coalesce the small files to output larger intermediate files before generating the final segments. But as part of the data preparation done by the FileIngestionTask, small files can be merged and large files can be split into segments of proper sizes automatically now.
Checkpoint framework
In case of Minion task failures, it is important to ensure data consistency. So we have added a checkpoint mechanism for FileIngestionTask to achieve exactly-once ingestion. When a subtask starts, it submits a checkpoint entry and marks it as IN_PROGRESS. The entry contains the list of input files and output segment names for that subtask. When the subtask is done generating and uploading the segments, it marks the entry as COMPLETED. The checkpoints are submitted to the task generator, which persists them in Zookeeper and checks them to generate the next batch of subtasks.
Every time the task generator runs, it processes the checkpoints kept in Zookeeper and the task execution states tracked by the framework, to identify the ingested files and failed ones. It can then retry the failed input files and dispatch the remaining files in the next round of tasks. To limit the number of checkpoints kept in Zookeeper, we have also introduced a watermark mechanism to clean up COMPLETED checkpoints regularly. There are a few knobs to control the watermark mechanism to allow new files or late data to be added to the input folder and get ingested safely.
Usability
Data from the input files can be appended to a Pinot table as new segments or used to refresh the table by replacing the old segments. New input files may be added to the input folders continuously during ingestion. To support these general behaviors, we implement two modes to help customize the FileIngestionTask:
- Scan : to continuously ingest new files into the table as new segments. The data is ingested exactly once. New files added during ingestion can be picked up automatically. In this mode, segments are always named uniquely to get appended to the table.
- Sync : after files are ingested for the first time, any future updates made by users can be detected automatically to regenerate the segments. This mode can append segments for new files or replace segments for updates made on the ingested files.
With FileIngestionTask, we don’t need other data processing systems to prepare the input files, and the job scheduling, tasks monitoring, and failure handling are all supported out of the box. We’re already seeing this being super valuable in our customer environments. A Pinot cluster is all they need to start batch data ingestion in StarTree cloud. This saved hours if not days of effort for our customers to get data ready in Pinot and try out its real-time analytics features. The minion workers can be scaled in and out easily. Such elasticity enables us to balance the performance and cost as needed. Sometimes we increased the number of minion workers to 30+ to ingest the data quickly and decreased it to zero after the ingestion was all done in StarTree cloud.

Fig. Automated batch ingestion with the FileIngestionTask
Try it out!
StarTree cloud provides a self-serve ingestion tool called Data Manager which simplifies getting data into Pinot on behalf of the users. Here’s how you can leverage Data Manager for batch ingestion:
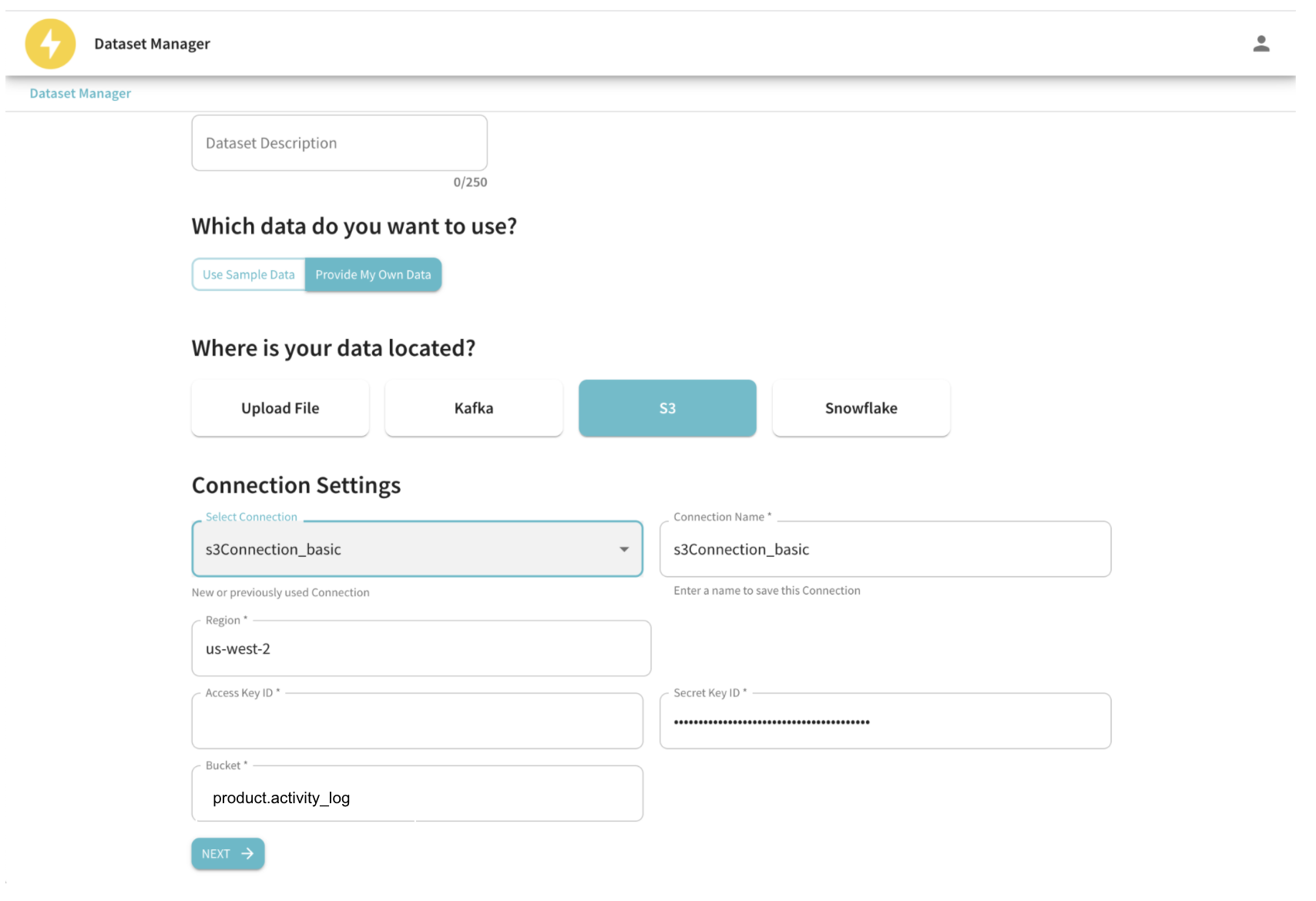
Fig: Enter your S3 data source connection details
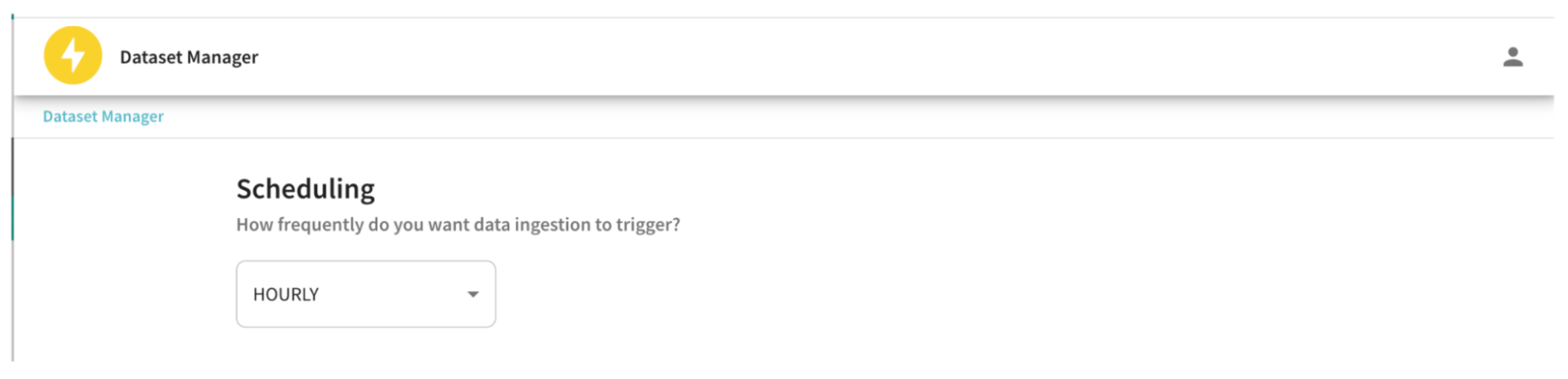
Fig: Select the cadence with which to run the minion job
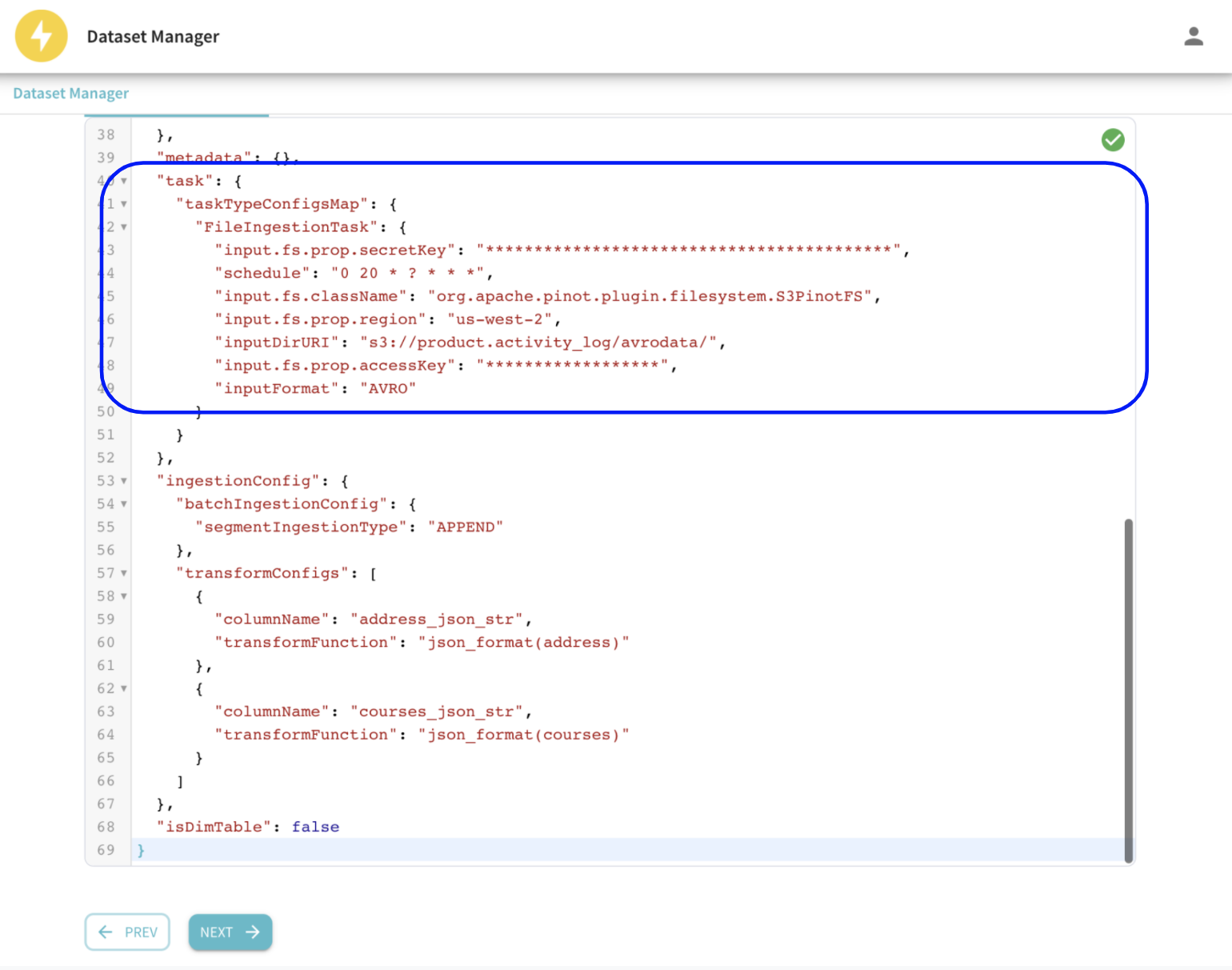
Fig: Review and submit the generated table config with the FileIngestionTask configured.
In the background, Data Manager translates the user intent into a Table config with the FileIngestionTask configured to run at a configurable cadence. This is available in StarTree cloud today – please try it out for yourself!
Future work
There are two general categories of future work to keep improving the batch data ingestion for StarTree cloud: adding new minion tasks and enhancing the existing ones for more features and better usability, and meanwhile improving the task framework to make it more cloud-native for efficiency.
For new features, we are looking at how to support flexible data backfilling; and adding coordination between ingestion tasks and segment management tasks so that newly ingested segments can be optimized continuously based on the changing query patterns.
For the task framework, we are adding more observability and knobs to make it easy to operate; and will explore ways to run the task framework economically given the dynamic workload and the elastic pool of cloud resources.
We’d love to hear from you
Please get in touch with us if you like to take this for a spin!
You can get in touch with StarTree by contacting us through our website. We encourage you to Book a Demo or contact us for a free trial.
New to Apache Pinot? Here are some great resources to help you get started. You can find our documentation here, join our community Slack channel, or engage with us on Twitter at StarTree and Apache Pinot.
