Introducing StarTree Serverless: Your Own Real-Time Analytics Environment

Written by Neha Pawar, Chinmay Soman
Introduction
StarTree Cloud is a platform designed for building sophisticated real-time analytical applications and dashboards, powered by Apache Pinot. During our initial launch, users could request a dedicated StarTree Cloud environment that could be provisioned in the StarTree account (SaaS offering) or in the customer’s account (BYOC – Bring Your Own Cloud offering). Both these options required initial capacity planning, infrastructure provisioning, and deployment of software.
To allow users to get up and running quickly, we’re very excited to announce a new offering called StarTree Serverless. StarTree Serverless is primarily targeted for use by developers new to Apache Pinot who want to get started quickly without any upfront commitment. With Serverless, users simply register for a StarTree Cloud account and can instantly start ingesting datasets and building applications.
StarTree Serverless is now powering our new Free Tier trial experience, which was announced at our recent RTA Summit. Registered users get a free forever StarTree workspace without having to worry about a 30-day expiry. In this blog, we’ll walk through key features of StarTree Serverless, its architecture, and how to get started.
Serverless features
Some of the highlights of the StarTree Serverless offering include instant provisioning, collaborative environment, no-code/low-code data ingestion, and our reimagined StarTree Query Console. Learn more about these features below:
Instant provisioning
When we initially launched our 30-day free trial experience, new registrations triggered the provisioning of a dedicated StarTree environment that took 15-plus minutes. In addition to being slow, this is also cost-prohibitive since these trial environments cannot be shared and are mostly underutilized. You can see that workflow in the following diagram:

In Serverless, new registrations are instantly assigned a virtual StarTree workspace and belong to an existing StarTree Environment, as shown below:
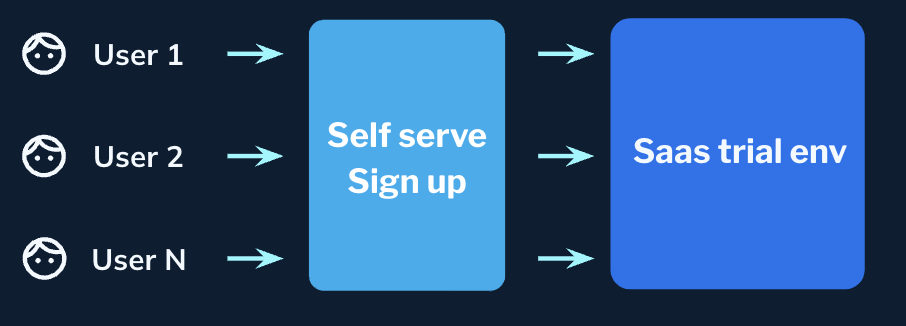
These virtual workspaces are isolated from each other (see below for details) and end up making efficient use of the shared underlying resources. In addition, this leads to a great user experience since you go from signup to a ready workspace in seconds.

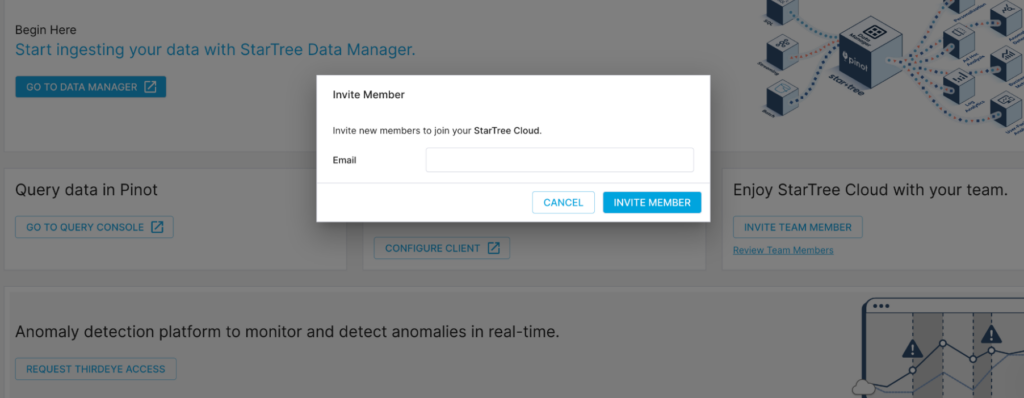
Collaboration with teammates
The trial experience powered by Serverless is designed to be highly collaborative. Once you’ve registered and been assigned to a workspace, you can invite your teammates to the same workspace (which also happens instantly). Thereafter, these users have full access to the datasets created within the shared workspace, thus increasing productivity.
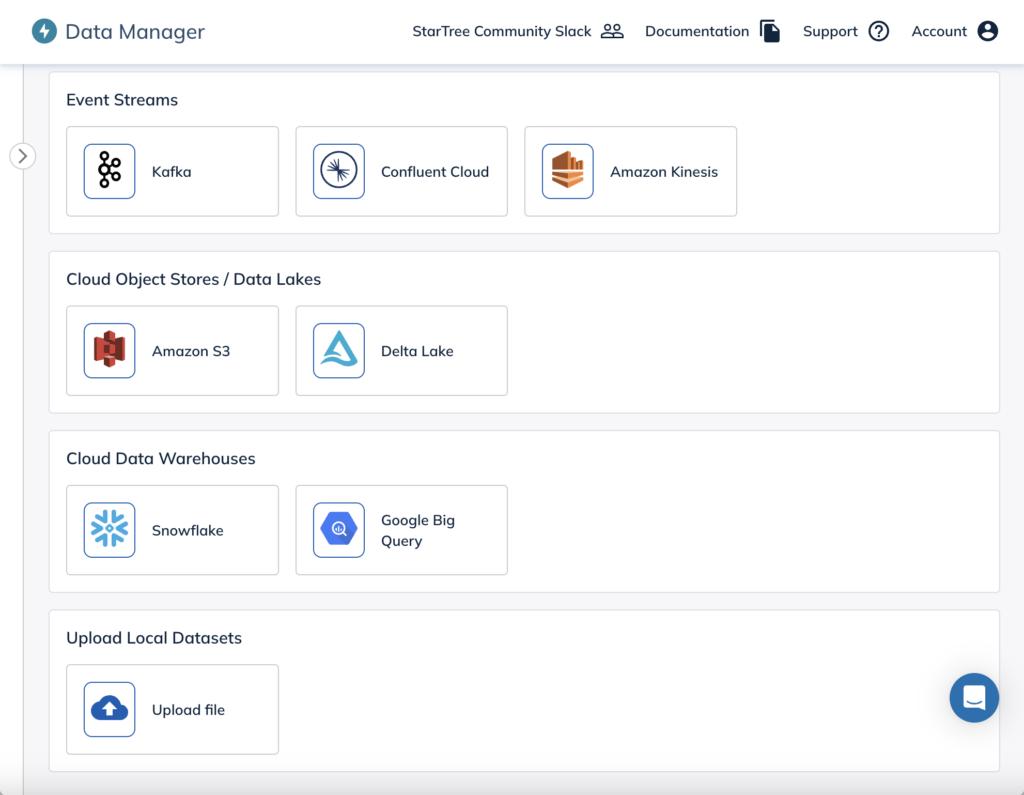
No-code/low-code ingestion with Data Manager
Serverless users get access to the same StarTree Data Manager available in production environments. This is a great tool to help you get started quickly. It allows you to connect and ingest data intuitively from various sources like Kafka, S3, Snowflake, and Delta Lake. It also has powerful data modeling capabilities including:
- Automated schema inference
- Adding derived columns on the fly
- Rich transformation support
- Rich preview of Apache Pinot dataset
New Query Console
We’re also announcing a brand new StarTree Query Console for interactive analysis of the datasets created via Data Manager. This has all the functionality of the open source Query Console included with Apache Pinot.
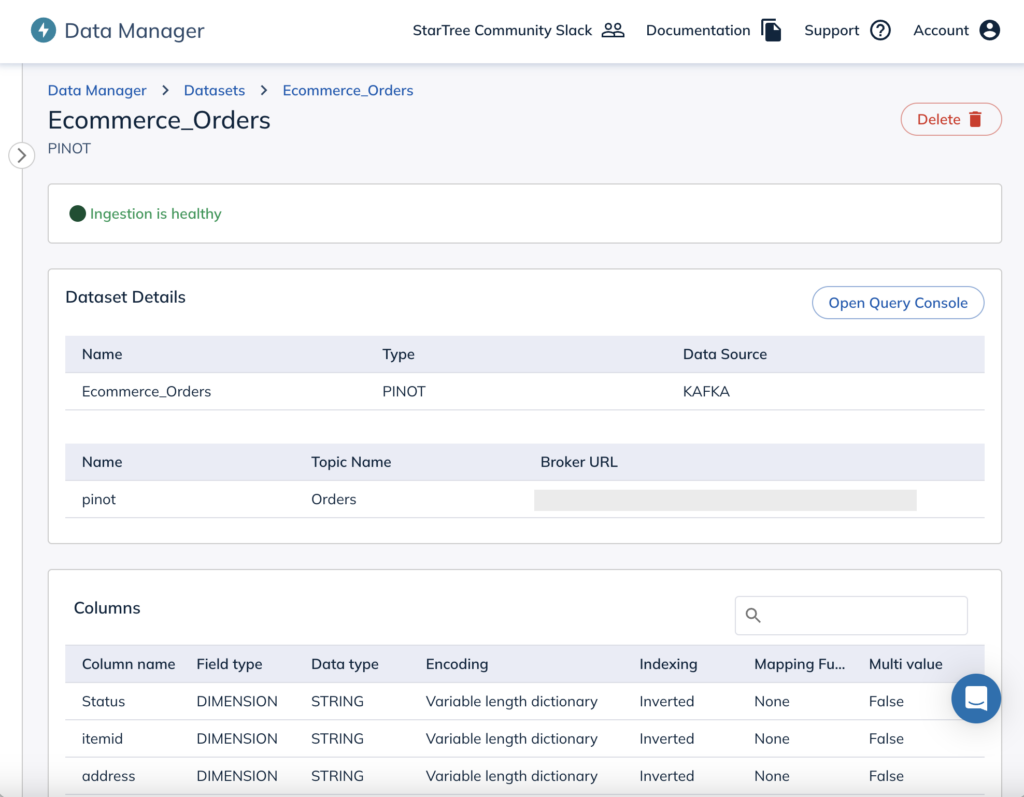
In addition, we’ve added a bunch of improvements such as:
- Cleaner, more intuitive UI
- Syntax highlighting
- Semantic query validation
- Performance analyzer (in private preview)
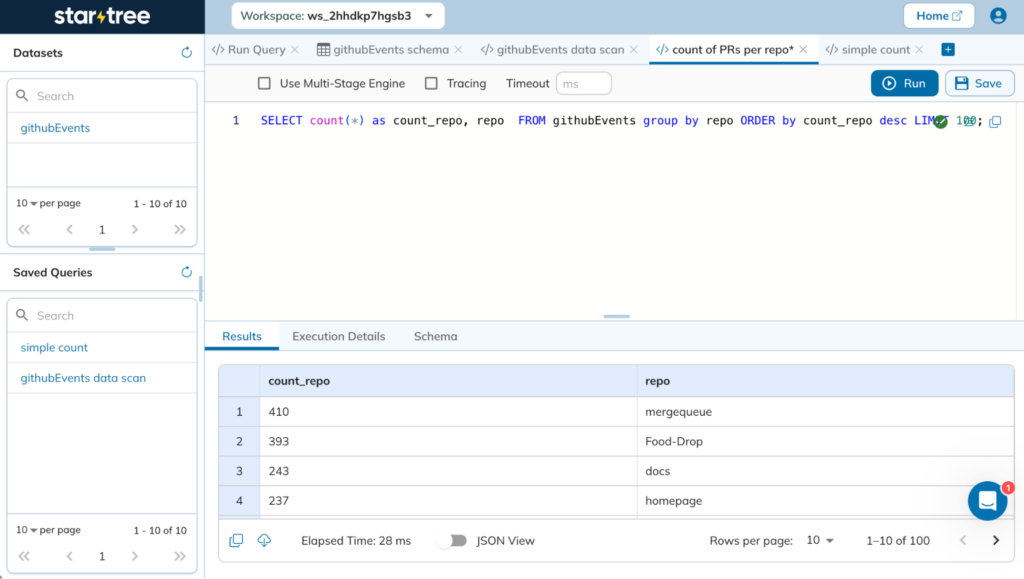
Architecture
At the heart of StarTree Serverless lies a new concept we’ve integrated into our logical model: StarTree Workspace. These workspaces share underlying physical resources, and provide a logical unit of isolation to the users.
As part of StarTree Serverless, we’ve elevated the workspace to a first-class citizen within StarTree Cloud, ensuring it functions seamlessly across all apps and services within the data plane:
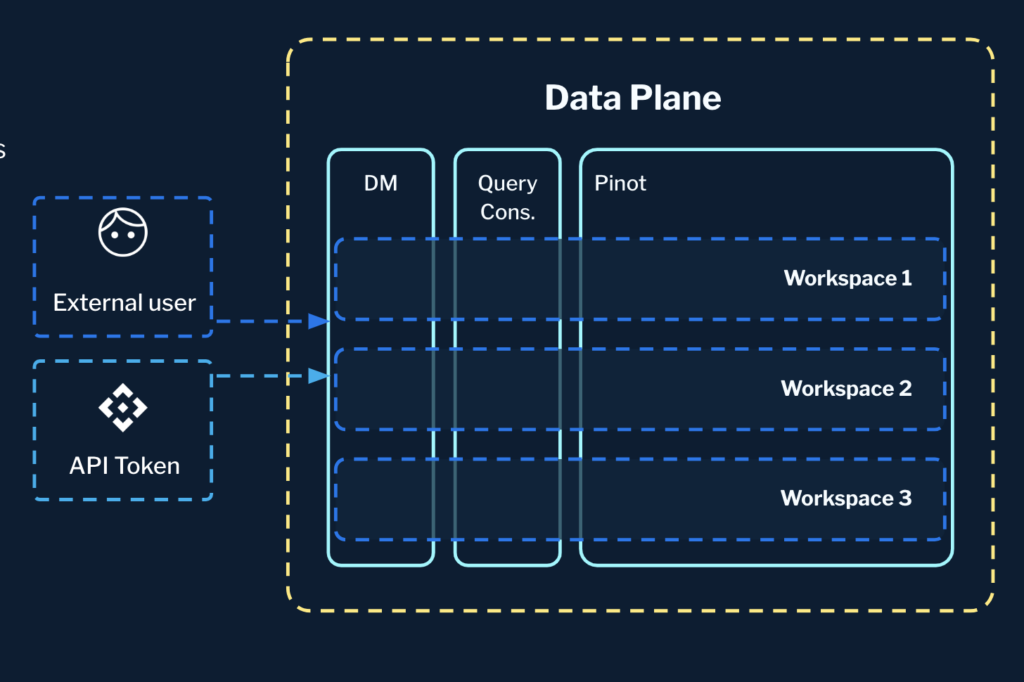
- Signup and invitations: In StarTree Serverless, new registrations are instantly assigned a virtual StarTree workspace within an existing StarTree Environment. Users can only invite other teammates to their own workspace.
- Data Manager: In Data Manager, you can easily view all of the workspaces you have access to and create/delete tables (but only within the scope of your workspace).
- Query Console (QC): When it comes to querying data, the Query Console ensures that you can only view and interact with data within your own workspace.
- Tokens: Our service tokens are designed to be workspace-aware. When you generate a token for programmatic access, it’s tied to your specific workspace, ensuring that it can only be used within that context.
- Pinot cluster level: Tables created within a workspace have their context stored in the table details, preventing conflicts like duplicate table names. This also enables the setup of common attributes such as quotas and Role-Based Access Control (RBAC) policies at the workspace level.
The workspace concept is flexible and not tied to physical isolation, which is achieved using tenants. However, it can be paired with tenants for stricter isolation guarantees. Additionally, the workspace concept applies not only to Serverless but also to our other offerings like Bring Your Own Cluster (BYOC) and Dedicated SaaS.
RBAC integration
Behind the scenes, our Role-Based Access Control (RBAC) system orchestrates everything.
Just to quickly recap on RBAC, the two main concepts to understand here are Subjects and Roles. Subjects are the people and programs interacting with your data, including users, user groups, and service accounts for programmatic access; whereas Roles define what actions are allowed or denied based on policies that specify resources, actions, and effects.
In StarTree Serverless, the Subjects are users who sign up, or service tokens generated by the users. These Subjects can assume the Role of workspace admin or workspace reader, which controls the level of access they get within their workspace. When users sign up or create tokens, this mapping is automatically created, thus contextualizing interactions with apps and entities like datasets, alerts, and connections, as these entities inherit access control from the workspace level.
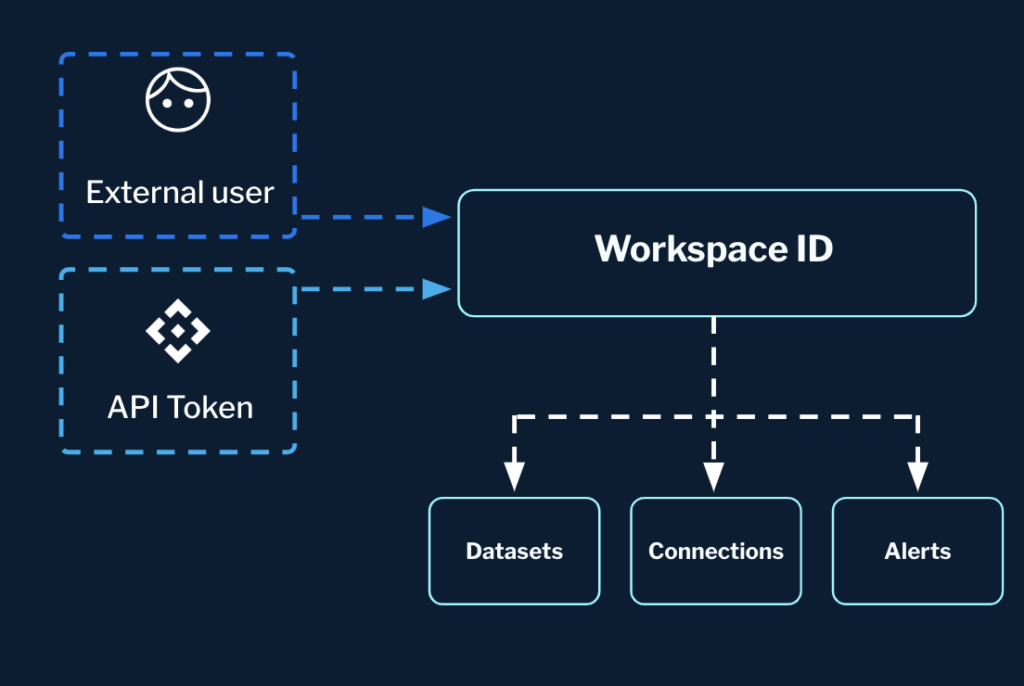
Database concept in Apache Pinot
We introduced the concept of “database” in Apache Pinot to integrate workspaces. Unlike the physical tenant concept (a tag associated with physical nodes), the database is a logical concept equivalent to workspaces or namespaces.
With databases, all tables in Pinot have a logical name (e.g. myTable_OFFLINE) and a fully qualified name (myDatabase.myTable_OFFLINE). This is transparent to users, who can continue using their logical table names while the system handles the fully qualified names behind the scenes.
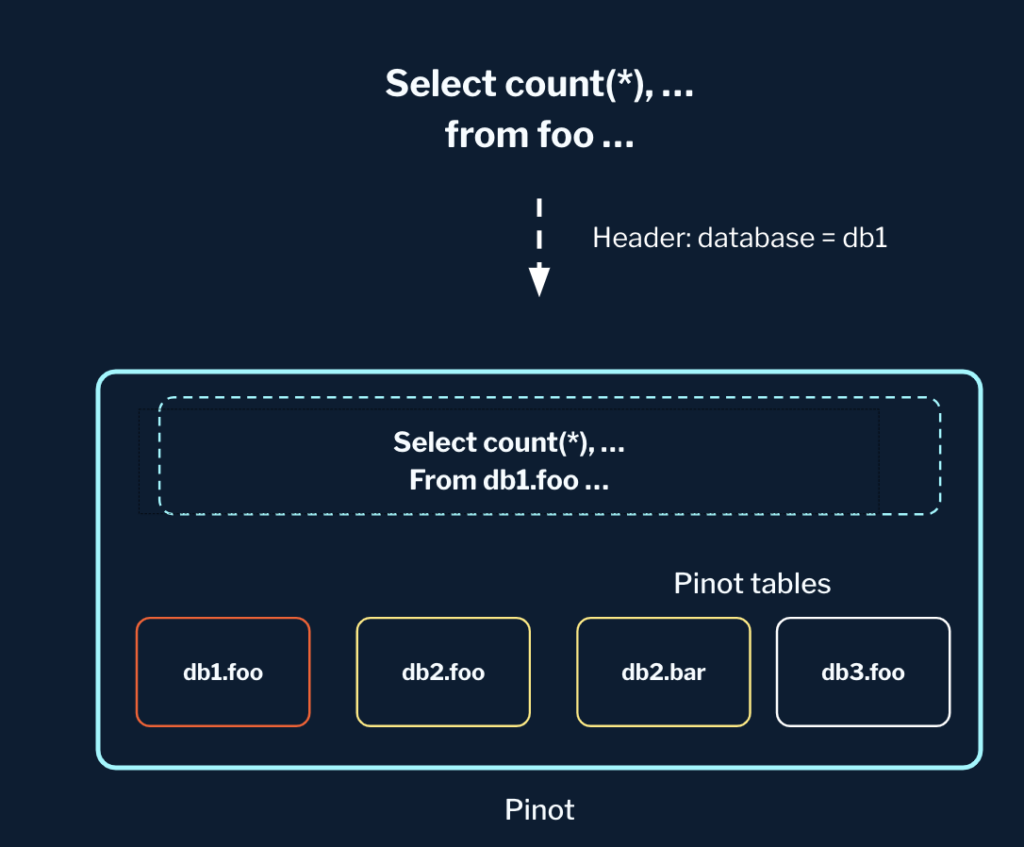
In StarTree Serverless, we made a 1:1 mapping between workspaces and databases, applying workspace-level policies to tables via their association with the database.
Isolation and scalability
As mentioned earlier, the logical isolation of the workspace is not coupled with the physical isolation of the tenant. As a result of this flexibility, we are able to operate in several different modes.
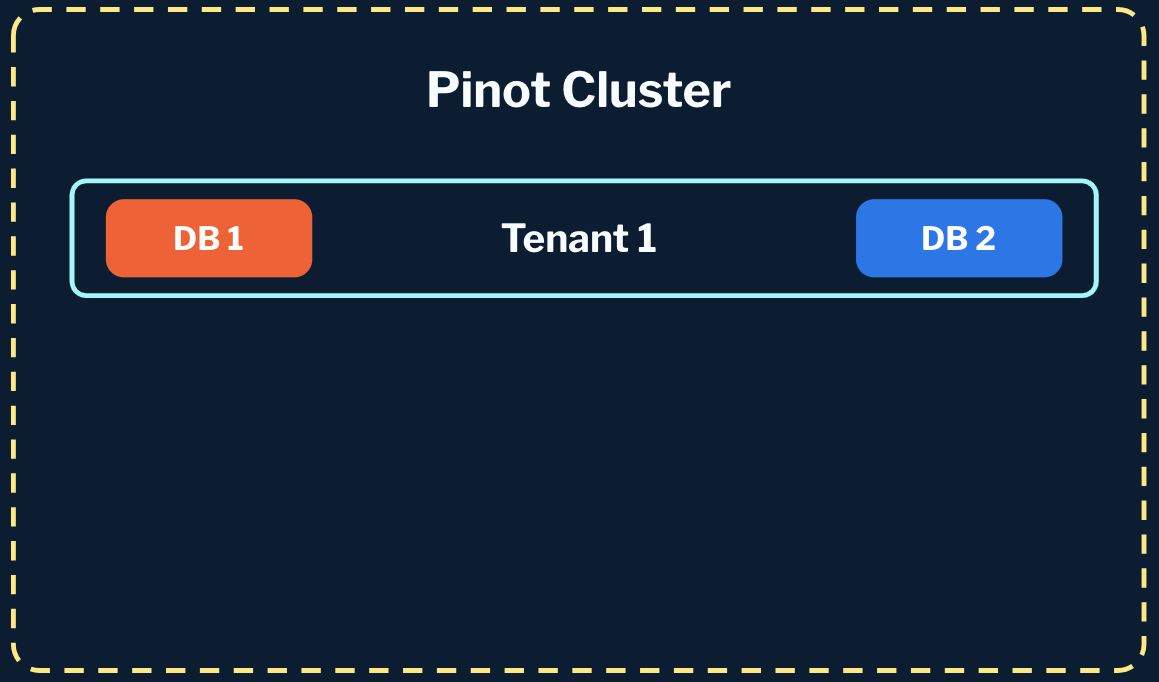
- 1:N tenant to workspaces: We can support one large physical tenant that is shared by multiple workspaces for the most cost-effective utilization and best performance.
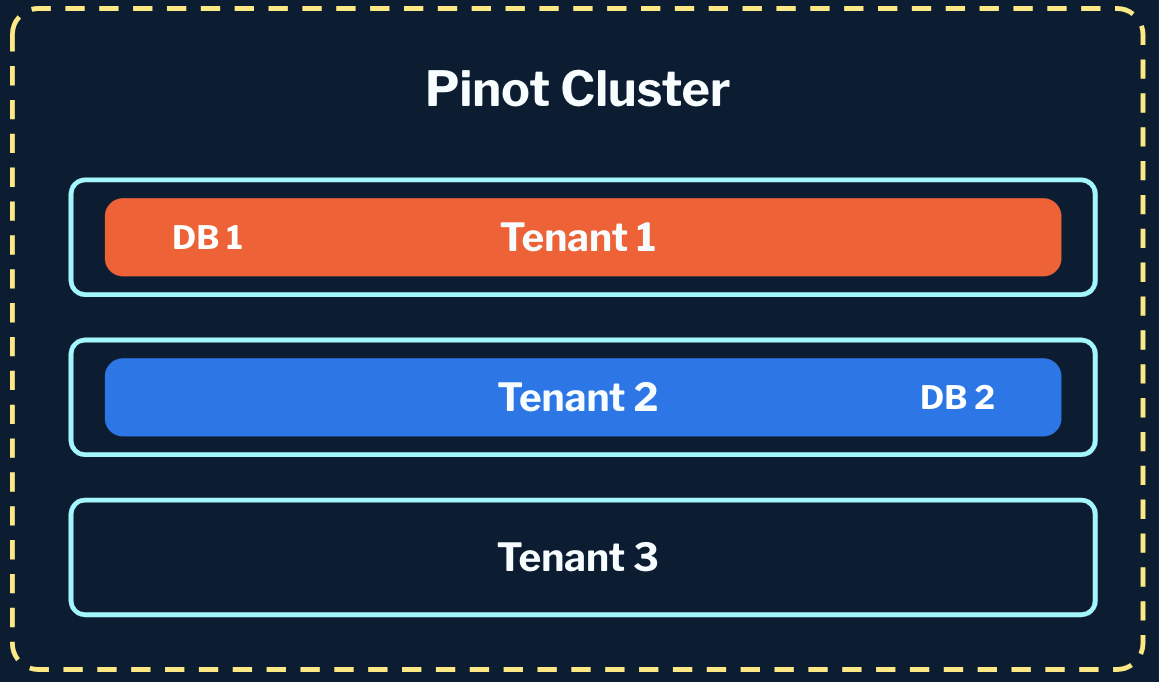
- 1:1 tenant to workspace: We can also do a 1:1 workspace-to-tenant mapping, providing both physical and logical isolation in one shot if desired.
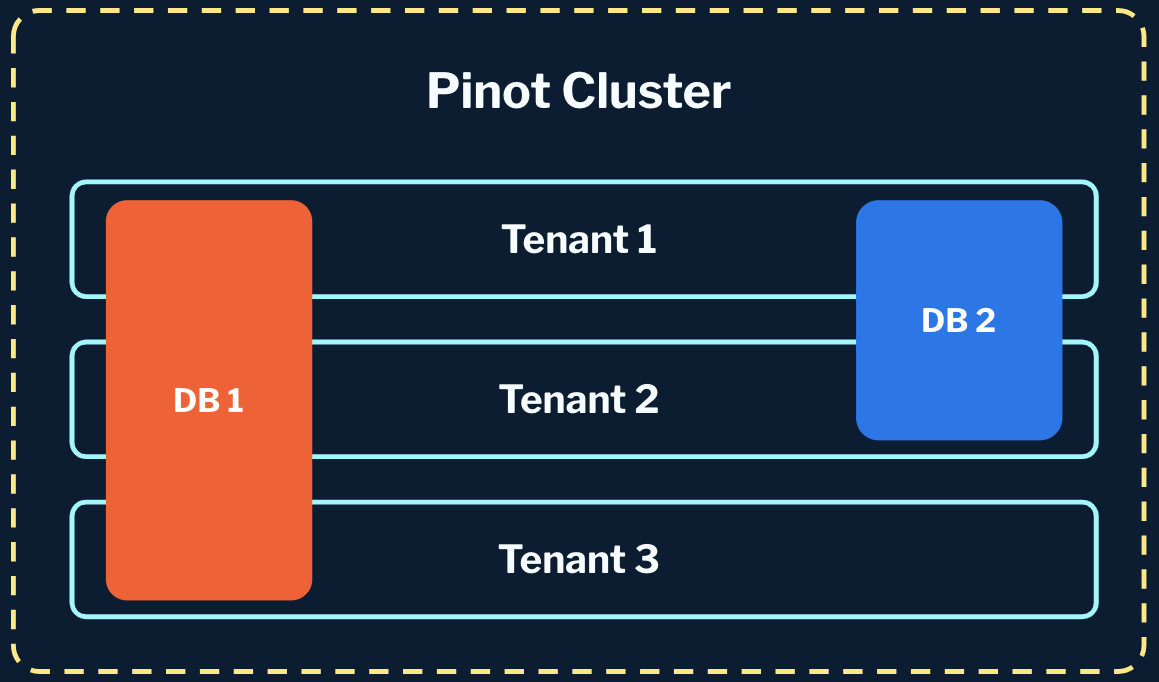
- N:N tenant to workspace: Workspaces can also span multiple tenants, if physical separation within the same data set or for tables within the workspace is needed.
To protect the shared cluster from misuse and overloading, we’ve enabled various guardrails and checks:
- QPS quota: Queries are throttled if the quota is exceeded.
- Ingestion rate: Ingestion is throttled if the events per second goes higher.
- Storage quota: Batch data pushes are rejected if storage quota is exceeded.
- Expensive query killing: Monitors and kills resource-intensive queries to maintain performance.
From an operational standpoint, we continuously monitor cluster capacity and CPU/memory utilization, allowing us to increase capacity and rebalance data across new nodes.
Tiered storage
On StarTree Serverless, we have the capability of cloud-based tiered storage. This allows us to move data from local disk/SSD storage to cloud object stores while maintaining seamless query access through the same table. This helps us ensure that StarTree Serverless remains efficient, scalable, and user-friendly as it grows.
Today, the data movement is based on data age, to allow recent data to be on local disks, while migrating older data to the cloud object store. In the future iterations, we will adopt migration policies that consider age as well as size of the data, so that we gracefully handle tables that grow too big in size.
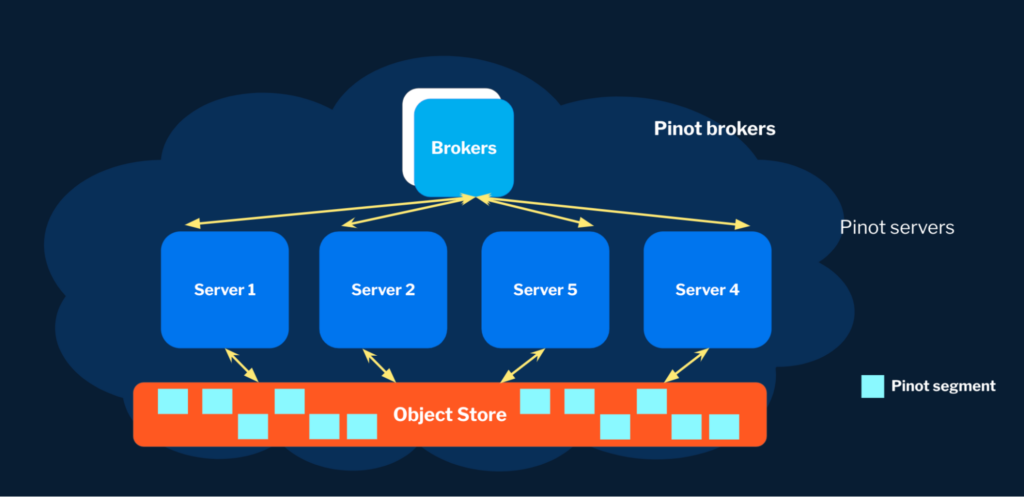
To ensure low latencies, even with remote tiered data, we’ve optimized several aspects, such as the ability to keep metadata and indexes local, or reducing the granularity of data reads. We also do smart prefetching and pipelining between fetches and execution to parallelize and optimize data retrieval.
What’s next
If you’re interested in learning more about StarTree Serverless, we urge you to try it yourself by signing up for our Free Tier. As we continue to improve the Serverless offering, here’s what you can expect in the near future:
Pay as you go
The current Serverless offering is intended for trial purposes only. In the near future, users can run production workloads on Serverless and pay only for the resources needed for their specific workspace. This is very useful for new users who are starting small and don’t need a dedicated environment yet. In addition, we will be providing a cost estimator that can give you an upfront price estimate based on various factors like data size, QPS, number of documents scanned, and so on.
StarTree Workspace in production
We will also be making the virtual StarTree Workspace a first-class citizen in all of our offerings including production environments (SaaS and BYOC). Many of our customers use StarTree as a platform for supporting various internal groups within their organization. StarTree Workspace is a great abstraction for isolating such groups either logically or physically.
In the meantime, you can take StarTree Serverless for a spin — get started immediately in your own fully-managed serverless environment with StarTree Cloud Free Tier.