The Story of Apache Pinot
A rapidly growing portion of the analytics landscape, real-time analytics depends on high speed data ingest and query response — at unprecedented scale. But just a few years ago, legacy ingest speeds and query response latencies on large datasets were nowhere close to what they needed to be to support real-time analytics. LinkedIn developed Apache Pinot to change all that.
Born from Fast-Growing Analytic Needs
In 2014, LinkedIn had 200M+ users generating ~1500 queries per second via user-facing applications. These real-time analytics derived from numerous streaming data sources and required large amounts of expensive infrastructure to support using established methods.
Among the services LinkedIn presented to customers was a simple query: “Who Viewed My Profile”. Initially able to present only aggregate views over fixed periods of time, the feature wasn’t very popular and generated only 10s of queries per second. But once LinkedIn expanded the query with detailed insights — i.e., views by company, geo, title, etc. — the growth and engagement of LinkedIn’s user base began to take off, and the organization realized they would need a fundamentally different approach to processing data — a new technology capable of handling unprecedented scale. That was the spark for Pinot.
Success is a Problem?
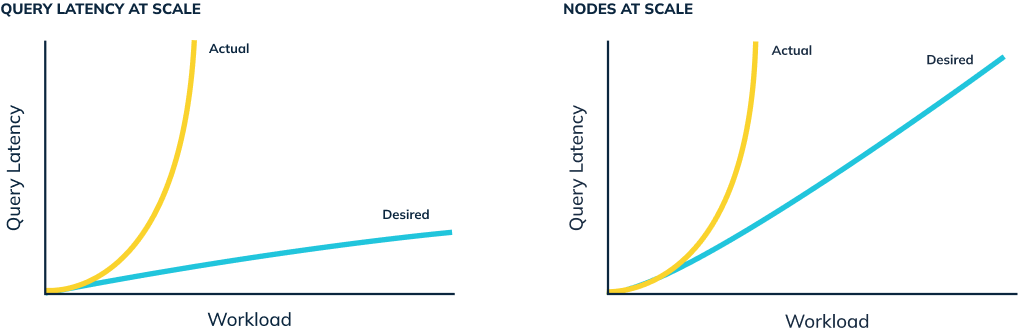
As engagement shot up, 10s of queries per second jumped to 1000s. To maintain the SLA for “Who Viewed My Profile”, the product team added hundreds of nodes to the cluster, and struggled constantly to manage it. Even so, query latency and resource consumption were trending the wrong way. It soon became obvious that LinkedIn’s existing analytics stack and cluster management system could not keep up with demand.
Rethinking All the Steps
To solve the bottlenecks, the Pinot team sought to evolve the existing search-based system for the needs of real-time analytics. In looking for a new solution, they had a key insight: instead of working to accelerate an existing, tightly-coupled query protocol, they would gain efficiency and save compute time by looking for stages in the query process that might be avoided altogether. The resulting leap forward was Pinot’s flexible, on-the-fly, per-query approach to assembling the query process itself.
Expanding with Radical Efficiency
Pinot’s success is reflected in its spectacular efficiency gains. Recall that in 2014, with north of 200M members, LinkedIn was struggling to handle the explosive growth of the “Who Viewed My Profile” product. Supporting that single query without Pinot eventually required a 1000 node system, with all its attendant costs and management overhead. By 2020, LinkedIn had grown to 700M+ members, with the “Who Viewed My Profile” product alone generating 5000 queries per second. But with Pinot, LinkedIn handles this query load with only 75 nodes — a 45x improvement in efficiency despite a massive increase in the user base.
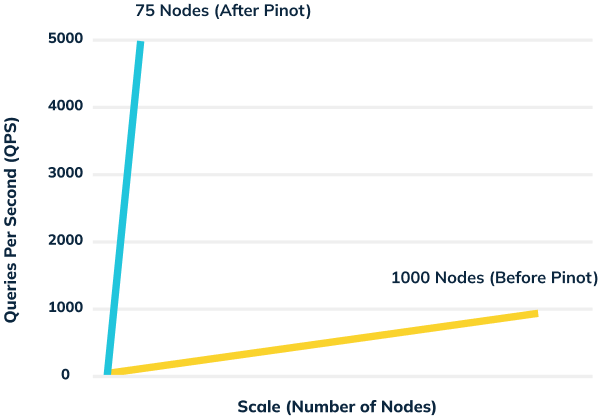
Despite breakneck growth for the “Who Viewed My Profile” product, query performance in 2020 featured:
- ~5ms average latency
- <100ms 95th percentile
- No inverted index or caching
- 45x better efficiency

LinkedIn Today: Pinot Everywhere You Look
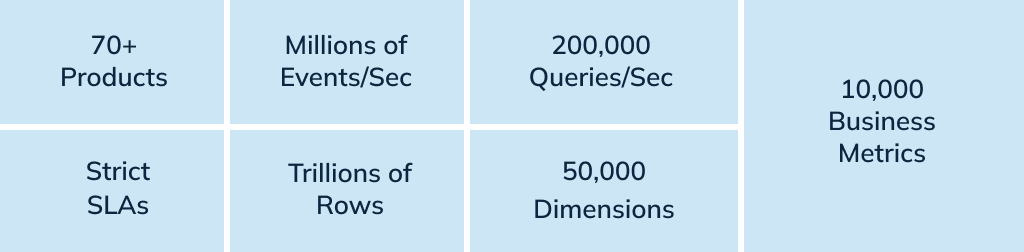
Today, LinkedIn leverages Pinot across the organization to support a total of 200K queries per second and 70+ products, many of which are user-facing and thus subject to strict SLAs around latency and throughput. In addition, Pinot serves as LinkedIn’s own repository for nearly 10,000 business metrics queryable across 50,000 dimensions.