
At our stealth startup, we process billions of events from millions of users. These events are generated by a collection of customer-facing and internal business use cases. Customer-facing use cases provide real-time analytics dashboards, giving customers insights into how their business is doing, which would aid in better marketing opportunities. Internally, we rely on real-time insights about critical metrics and alerts indicating issues with our facilities and infrastructure, enabling customers to take quick action.
Delivering these use cases puts additional scalability and reliability constraints on our data infrastructure. We started with a micro-batch architecture where we processed real-time events every few minutes. That was sufficient when the data volume and latency requirements were low, but as our business grew, so did the data volume, and we quickly outgrew our initial design.
Therefore, we sought an efficient and scalable real-time analytics platform and evaluated Apache Pinot, Apache Druid, and Clickhouse. Pinot was chosen as the winner because it was most compatible with our infrastructure and the development ecosystem, primarily based on Java.
This article takes a deep dive into three key areas where Apache Pinot excelled and helped us scale our analytics infrastructure for the long term.
- Data ingestion: Ability to ingest structured data from Confluent while maintaining data freshness for up to seconds.
- Query improvements: Ability to perform expensive aggregation and filtering queries with low latency. Also, the queries should be federated to include results from diverse data sources.
- Backup and recovery: we needed backups to ensure data availability in a disaster.
Architectural overview
Our real-time analytics infrastructure primarily consists of Apache Pinot and Trino. We used Trino along with Pinot to achieve several goals, including query federation. Also, we configured Trino to write data to Pinot, which we discuss at the end of the article.
The rest of the architecture includes Confluent Schema Registry and Google Cloud Storage (GCS), which helped us ingest Avro encoded data and implement backups, respectively.
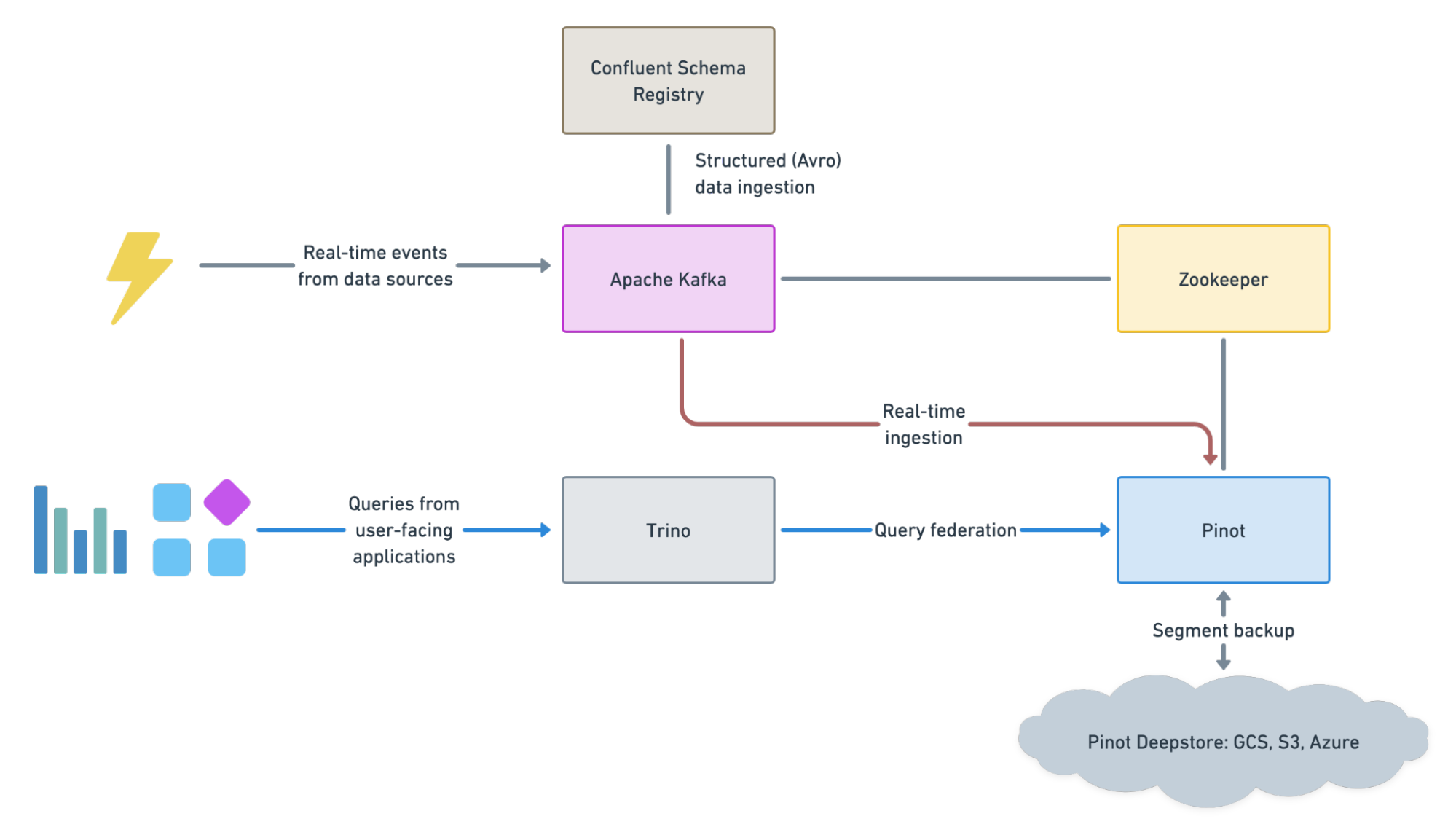
Figure 01 – A high-level view of the analytics infrastructure.
Data ingestion
Apache Pinot is capable of ingesting data from a streaming data source like Kafka. The data is ready to be queried seconds after ingesting, delivering insights while the data is still fresh.
We could onboard datasets quickly via real-time ingestion, resulting in an immediate and significant payoff. Instead of hours or days, we could detect issues with our customers or anomalies within our infrastructure in seconds. Teams quickly started to onboard more datasets.
Real-Time ingestion with Confluent Schema Registry
One of the great features of Pinot is the pluggable architecture which facilitated our effort to implement real-time ingestion for Avro encoded messages from Kafka using the Confluent Schema Registry. The open-source community was very helpful. Within a short time, we contributed to this feature and reap the benefits of ingesting structured data.
Most of our topics use the Confluent Schema Registry, which stores the Avro schemas of messages, allowing for more compact messages as the schema is not part of the message. That resulted in the rapid adoption of Pinot for real-time use cases.
Query improvements
Pinot helped us achieve high-performance querying on large data sets while maintaining consistent SLAs. Also, integrating Pinot with Trino made it possible to federate queries to different data sources.
Query Federation with Trino Pinot Connector
While people enjoyed using Pinot directly and quickly reaped the benefits of real-time insights, we needed to integrate the real-time data with the rest of our stack. Analytics needed to join data from disparate sources and combine it with real-time data from Pinot.
We used Trino, which allowed us to access data stored in Hive, Postgres, and Pinot from a unified place. Within a short time, we implemented the connector, which allowed us to access data from Pinot, and analytics was able to join in with our existing data assets.
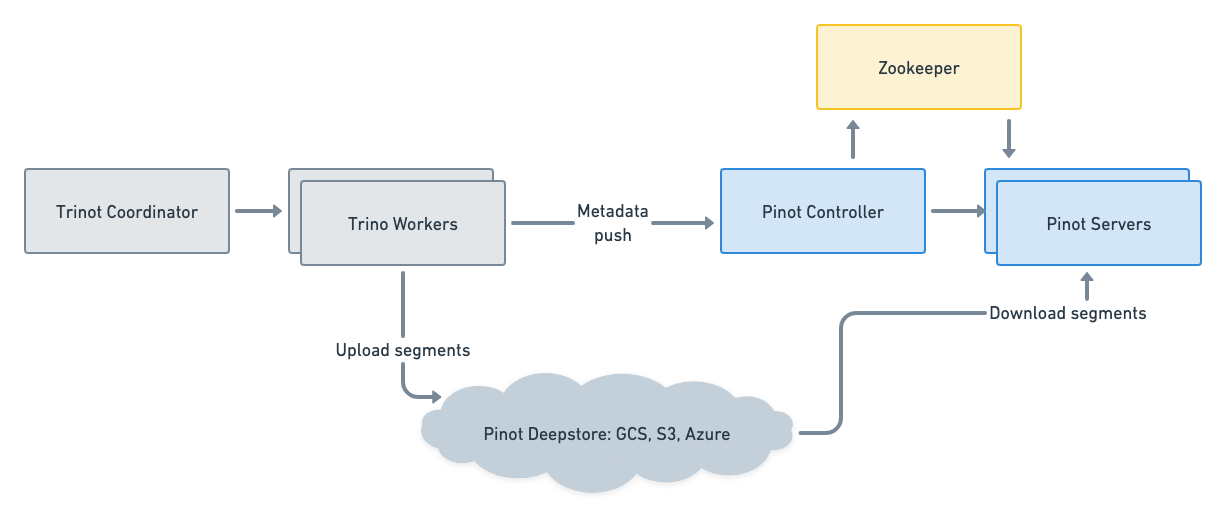
Figure 02 – Query federation with Trino and reliable storage with Deepstore
Passthrough Queries: Allow Direct Querying of Pinot from Trino
Pinot offers useful UDFs that our analytics team benefited from but could not use directly in Trino. We came up with a solution that allows a query to select from a Pinot query as a table by including the broker request as an SQL identifier.
For example, the below query is pushed directly to the Pinot broker and allows users to leverage Pinot transform and aggregate functions.
SELECT company, distinct_users
FROM pinot.default."SELECT company, distinctcounthll(user) FROM table GROUP BY company"Code language: PHP (php)That introduced some challenges as SQL identifiers must be in lower case, but broker requests may contain uppercase constants. The most common request was to leverage date-time functions so we added the ability to parse a broker request and automatically case time units. Some examples were users that wanted to use DateTimeConvert or DateTrunc. This was solved using passthrough queries but due to lower casing, the time unit parameters were unrecognized. The connector now fully supports time unit parameters and automatically upper cases them. To illustrate, here is an example:
SELECT company, converted_timestamp
FROM pinot.default."SELECT company, datetimeconvert(created_at_timestamp, '1:MILLISECONDS:EPOCH', '1:DAYS:EPOCH', '1:DAYS') FROM table GROUP BY company"Code language: PHP (php)In the above query, the 1:MILLISECONDS:EPOCH, 1:DAYS:EPOCH and 1:DAYS parameters are initially lower cased in trino since the query is treated as a sql relation, i.e. a table. The connector will recognize these parameters and convert them back to their original upper case values.
The latest version of the connector directly uses Pinot FunctionRegistry to convert the passthrough query to a broker request correctly. That also enables using Pinot functions natively via a Trino query.
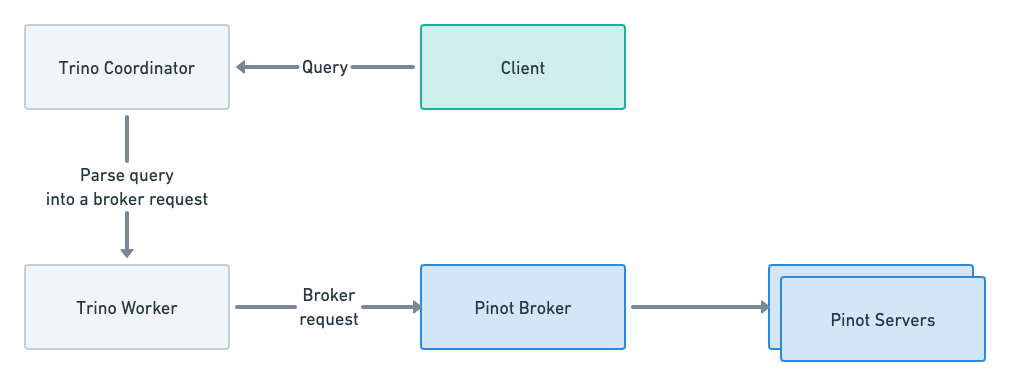
Figure 03 – Querying Pinot through Trino
Aggregation, filter, and limit pushdown
Trino added the ability for connectors to push filters and aggregations directly into the underlying data source. That allowed us to drastically reduce query latency from minutes to seconds, as we can now leverage the Star-Tree indexes in Pinot to perform the aggregations. Now users can do a “select COUNT(*)” and other aggregations, which would be directly pushed into Pinot without doing a passthrough query. The syntax is much easier to use and allows transparent pushdown to Pinot.
Example:
SELECT company, count(*)
FROM pinot.default.table
GROUP BY companyCode language: CSS (css)The above Trino query pushes down the aggregation into Pinot by issuing the following broker request:
SELECT company, count(*)
FROM table
GROUP BY companyThis performs the aggregation inside Pinot instead of sending all the data Trino and then doing the aggregation. The advantage is that the latency and amount of data sent to Trino are drastically reduced. Also, the Star-Tree and other indexes can be leveraged directly from Trino.
Filter pushdown allowed us to inject mixed case constants into the Pinot request, which was easier for users than wrapping uppercase constants in an “UPPER” function. The filter from the where clause of a Trino query would be directly passed as a broker request to Pinot, greatly reducing the amount of data needed to be transferred.
For example, the following Trino query will push the filter into the broker request to do the filtering inside Pinot. That greatly reduces the amount of data sent to Trino and leverages the Pinot indexes for the filtering.
SELECT company, address
FROM table
WHERE company IN ('foo', 'bar')Code language: JavaScript (javascript)Another example:
SELECT company, address
FROM pinot.default."SELECT company, address from table"
WHERE company IN ('foo', 'bar')Code language: PHP (php)The above Trino query will push the filter into the Pinot query and issue the following broker request:
SELECT company, address
FROM table
WHERE company IN ('foo', 'bar')Code language: JavaScript (javascript)Limit pushdown also drastically reduced the amount of data transferred from Pinot, as sometimes users may want to explore data. That also gave us more control over how much data was transferred from Pinot. We created some guardrails so a user does not inadvertently select a huge amount of data during the exploration phase.
For example, the following Trino query will push the limit into the broker request, which reduces the amount of data sent.
SELECT company, address
FROM table LIMIT 50Another example:
SELECT company, address
FROM pinot.default."SELECT company, address from table"
LIMIT 50Code language: PHP (php)Copy
The above Trino query will push the filter into the pinot query and issue the following broker request:
SELECT company, address
FROM table
LIMIT 50Backup and recovery with deepstore
As we grew more familiar with Pinot, we saw the need for the deepstore to have our data safely backed up to persistent object storage in the cloud. Again, we benefited from the pluggable architecture of Pinot as we needed to implement the PinotFS for Google Cloud Storage. PinotFS is the file system abstraction used by deepstore, connecting to object stores like GCS, S3, and Azure. And again, the knowledgeable and supportive community quickly welcomed our contributions, and we were up and running without fear of losing our data. We contributed the GcsPinotFS plugin, which allowed us to leverage the deepstore and benefit from having our data safely backed up.
Writing to Pinot from Trino
The Pinot Connector started as a way to select data, but we quickly realized that we could do much more, combining the power of Pinot with the power of Trino. We had many streaming datasets reconciled with sanitized data and required a way to combine them with real-time data.
Pinot HYBRID tables were a perfect fit for our use case. We needed Trino to have the ability to insert sanitized data from disparate datasets and transformations into the OFFLINE table while Pinot ingests the real-time data from Kafka. We implemented insert into Pinot using Pinot’s libraries for batch ingestion directly on the Trino workers. Refer to this pull request which we are actively working on merging into Trino.
That allowed us to scale horizontally, as selecting the data via JDBC creates a choke point. When we used an external job to select data from Trino, the data was gathered from the workers and sent via the coordinator, a single node. We wanted the Trino workers to upload new segments in parallel. Analytics teams could use the same SQL queries and tables used in batch jobs to insert data into Pinot and benefit from super-fast aggregations using Star-Tree indexes and the freshness of data ingested in real-time.
What to expect next?
We will be following up with a series of deep dives into the design, architecture, and uses of the features we added. Just to give a taste of what lies ahead:
- Query Pushdowns: the ability to push aggregate queries into Pinot, reducing the latency from tens of seconds to milliseconds
- Passthrough queries: the ability to leverage pinot queries directly as a virtual table, giving us access to Pinot UDFs and custom aggregations.
- gRPC Streaming: the ability to stream results with minimal impact to the Pinot servers
- Insert: Insert directly into Pinot via a SQL query, unleashing the onboarding of datasets by our analytics teams