
You would expect to join a fact table with several dimension tables in a typical OLAP database to enrich/decorate the result with more descriptive dimension fields. Ultimately, those fields can be further utilized to perform aggregations and filtering on the final result.
The lookup-based join support has been added to Apache Pinot from version 0.7.1 so that you can perform joins between fact and dimension tables. Lookup support for Pinot has been a long-awaited feature, and it has made OLAP joins convenient, scalable, and performant.
This article discusses how lookup joins work in Apache Pinot by taking you through a working example. We will create a real-time fact table and an offline dimension table and then join them using the lookup UDF function.
Lookup UDF Joins in Pinot
Pinot has been designed with querying single tables in mind. If you recall its architecture, a Pinot table is broken down into small chunks called segments. Pinot uses smart strategies to place segments across multiple servers in a cluster for durability and increased query performance. Queries are finally executed at the server level.
If you consider segments from two tables, they may or may not be located in a single server. Thus, joining segments at the server level would be challenging as it might need to access segments in remote servers. To overcome that, join support has been added to Pinot via Presto, enabling you to join Pinot tables which can be significant in size.
Today, we are discussing not the large-scale joins that require Presto but joins based on lookup tables that are small in size. For example, to enrich the final result with the customer name, you can join an orders table with a customers table, which can be used as a lookup table.
Joining a fact table with a small lookup table is made possible by the lookup UDF function of Pinot. Lookup UDF is used to get additional dimensional data via the primary key from a dimension table, allowing a decoration join functionality.
Qualifying a Pinot table as a lookup/dimension table
To qualify as a lookup table, a Pinot table must be:
- Defined as an offline table.
- Marked as a dimension table.
- Having a primary key column. It can be a composite key as well.
- Smaller in size, preferably less than 200 MB.
The following is an example of a lookup table definition along with its schema.

Once you mark a table as a lookup table, it will be replicated across all the servers of a Pinot cluster, enabling high-performant local joins by leveraging data locality. Hence, making them small in size would be a critical factor.
Use case
To understand how lookup joins work, let’s take a simple example.
Assume we have a fact table of orders and a dimension table of customers with the following schemas.

The goal is to answer the following questions.
- Find all the orders placed by Gold customers.
- Find the total number of orders by customer’s tier.
- Find the top five countries by sales.
The orders table alone can’t answer the questions above. Hence, we need to do a lookup join with the customers table to enrich the result with additional dimensions such as tier and country.
That requires us to define customers as a dimension table and join with orders table using the customer_id field.
Solution architecture
The solution is based on two Pinot tables.
Orders table – This table captures every fact about sales orders and qualifies as a fact table. We can implement this as a real-time table as new orders constantly arrive. Data ingestion takes place from a Kafka topic called the orders .
Customers table – This captures customer dimensions and has a primary key of customer_id. We can model this as a dimension table of OFFLINE type. Since customer information is not frequently updated as orders, a daily batch job can be used to populate this table.

Before we begin
You can find the completed example from the following GitHub repository.
https://github.com/startreedata/pinot-recipes
You need to have Docker Compose installed on your local machine to get it working. Check out the repository, navigate to the lookup-joins directory, and run the following commands on a terminal to start the project.
git clone https://github.com/startreedata/pinot-recipes
cd lookup-joins
docker-compose up
Once the project is up and running, it will launch a Pinot cluster consisting of the following containers.
- Zookeeper
- Pinot Controller
- Pinot Broker
- Pinot Server
- Kafka
Running the sample
Step 1: Create the orders Kafka topic
The Docker project brings up a Kafka container.
Execute the following command from the project’s root directory to create a new topic called orders to represent the incoming stream of orders.
<span class="">docker exec -it kafka /opt/kafka/bin/kafka-topics.sh
</span>--create --bootstrap-server kafka:9092 --topic ordersCode language: HTML, XML (xml)Step 2: Define the orders table and ingest some orders
Let’s first define a schema and table for the orders table.
You can find the schema definition in the orders_schema.json file and table definition in the orders_table.json file. They are both located in the /config directory. In terms of configurations, they look similar to any other real-time table. Hence, I’m not going to explain them here.
Go ahead and execute the following command from the project’s root directory.
<span class="">docker exec -it pinot-controller /opt/pinot/bin/pinot-admin.sh AddTable
</span>-tableConfigFile /config/orders_table.json
-schemaFile /config/orders_schema.json -execCode language: JavaScript (javascript)The above command connects to the container that runs the Pinot controller and executes the pinot-admin.sh to create the schema and a table for orders.
Step 3: Define the customers table and ingest some customer records
Now that we have our orders fact table. Let’s create the customers dimension table next.
You can also find the schema and table definitions inside the /config directory.
You’ll notice that the customer id field has been marked as a primary key in the _customers_schema.json file.
<span class="">{
</span> "schemaName": "customers",
"primaryKeyColumns": [
"customer_id"
],
"dimensionFieldSpecs": [
{
"dataType": "INT",
"name": "customer_id"
},
{
"dataType": "STRING",
"name": "name"
},
{
"dataType": "STRING",
"name": "tier"
},
{
"dataType": "STRING",
"name": "country"
},
{
"dataType": "STRING",
"name": "dob"
}
]
}Code language: HTML, XML (xml)Also, you will notice the following unique configurations in the customers_table.json file.
<span class="">{
</span> "tableName": "customers",
"tableType": "OFFLINE",
"isDimTable": true,
"segmentsConfig": {
"segmentPushType": "REFRESH",
"replication": "1"
},
"tenants": {
},
"tableIndexConfig": {
"loadMode": "MMAP"
},
"metadata": {
"customConfigs": {
}
},
"quota": {
"storage": "200M"
}
}Code language: HTML, XML (xml)The isDimTable directive instructs Pinot to mark this table as a dimension table. Pinot will then replicate a copy of this table on all the servers.
Execute the following command to create the schema and table definition for customers.
<span class="">docker exec -it pinot-controller /opt/pinot/bin/pinot-admin.sh AddTable
</span>-tableConfigFile /config/customers_table.json
-schemaFile /config/customers_schema.json -execCode language: JavaScript (javascript)At this point, you should be able to see two tables, orders, and customers have been created inside Pinot Query Console.
Step 4: Ingest sample records
Now that we have the tables created inside Pinot. Before writing any join queries, let’s ingest some sample records into both tables.
Produce sample orders to Kafka
You can find two sample data files inside the /data directory. The orders.json file contains thousand of JSON formatted orders.
A sample would look like this:
<span class="">{
</span> "order_id":1,
"customer_id":40,
"order_status":"PROCESSING",
"amount":7075.2,
"ts":"1619116750"
}Code language: HTML, XML (xml)Execute the following command to publish those events into the orders topic we created earlier.
<span class="">docker exec -it kafka /opt/kafka/bin/kafka-console-producer.sh
</span>--bootstrap-server kafka:9092 --topic orders < /data/orders.jsonCode language: JavaScript (javascript)If you check the orders table after a few seconds, you will see it has been populated with data as follows.

Ingest the customers CSV file
In the same /data directory, you can find the customers.csv file containing several customer records.
Execute the following command to ingest them into the customers table.
<span class="">docker exec -it pinot-controller /opt/pinot/bin/pinot-admin.sh LaunchDataIngestionJob
</span>-jobSpecFile /config/customers_job-spec.ymlCode language: JavaScript (javascript)You can find the ingestion spec file inside the /config directory. The above command launches an ingestion job inside the Pinot controller. The /data directory has been mounted as a volume there to read the customers.csv file and write the generated segments back to the same folder.
Upon successful ingestion, you should see that the customers table will be populated with data.
Step 5: Write the lookup join queries
Now that we have got both tables created and populated with data. What remains is to write SQL queries that answer the questions stated above.
The signature of the lookup UDF function looks similar to this:
lookUp('dimTableName', 'dimColToLookUp', 'dimJoinKey1', factJoinKeyVal1, 'dimJoinKey2', factJoinKeyVal2 ... )Code language: JavaScript (javascript)Where:
- dimTableName Name of the dimension table to perform the lookup on.
- dimColToLookUp The column name of the dimension table to be retrieved to decorate our result.
- dimJoinKey The column name on which we want to perform the lookup, i.e., the join column name for the dimension table.
- factJoinKeyVal The value of the dimension table join column will retrieve the dimColToLookUp for the scope and invocation.
The return type of the UDF will be that of the dimColToLookUp column type. There can also be multiple primary keys and corresponding values.
Let’s walk through a couple of queries that answer the questions that we initially had.
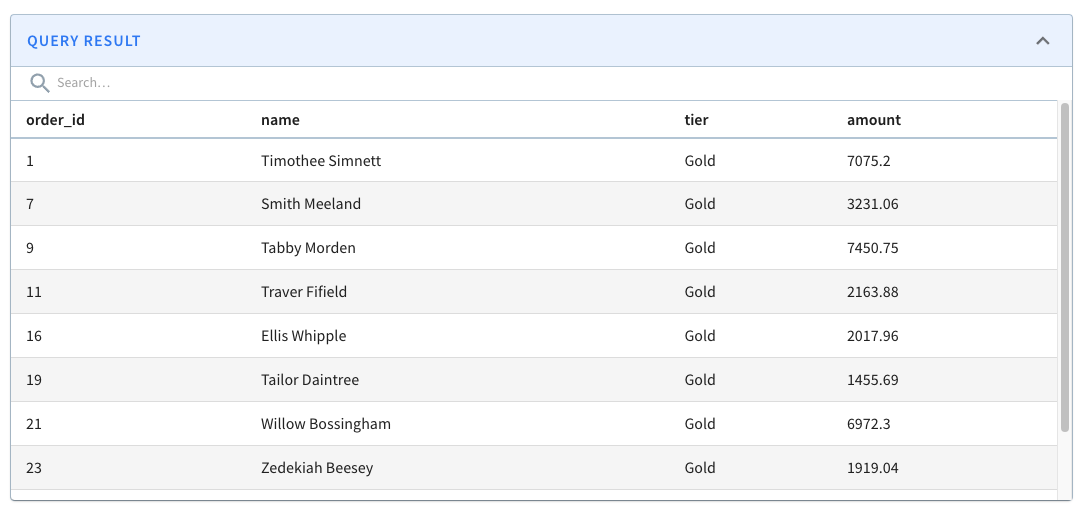
5.1 Find all the orders placed by Gold customers.
What are the orders placed by Gold customers?
To answer this problem, we need to write a SQL query that performs a lookup join between orders and customers table, based on customer_id . The joined result can be further filtered down on the ‘tier’ field.
<span class="">SELECT
</span> orders.order_id,
lookup('customers','name','customer_id',customer_id) as name,
lookup('customers','tier','customer_id',customer_id) as tier,
orders.amount
FROM orders
WHERE tier='Gold'
LIMIT 10Code language: HTML, XML (xml)The query returns the following result:
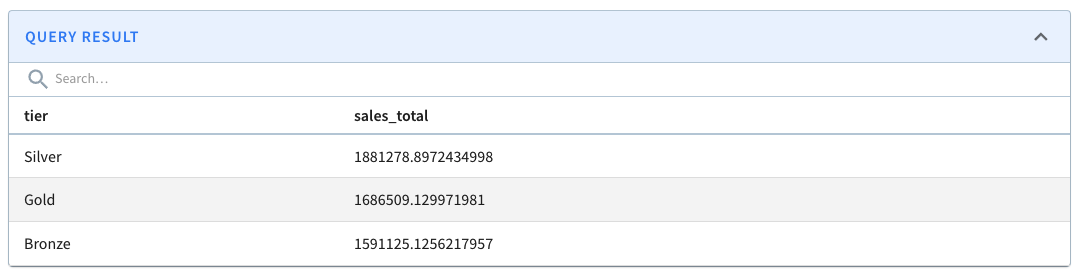
5.2 Find the total number of orders by customer’s tier.
Which customer tier has made the most sales?
The query looks similar to the above, but we need to aggregate the orders.amount by customers.tier .
<span class="">SELECT
</span> lookup('customers','tier','customer_id',customer_id) as tier,
SUM(orders.amount) as sales_total
FROM orders
GROUP BY tier
ORDER By sales_total DESCCode language: HTML, XML (xml)The above returns this:
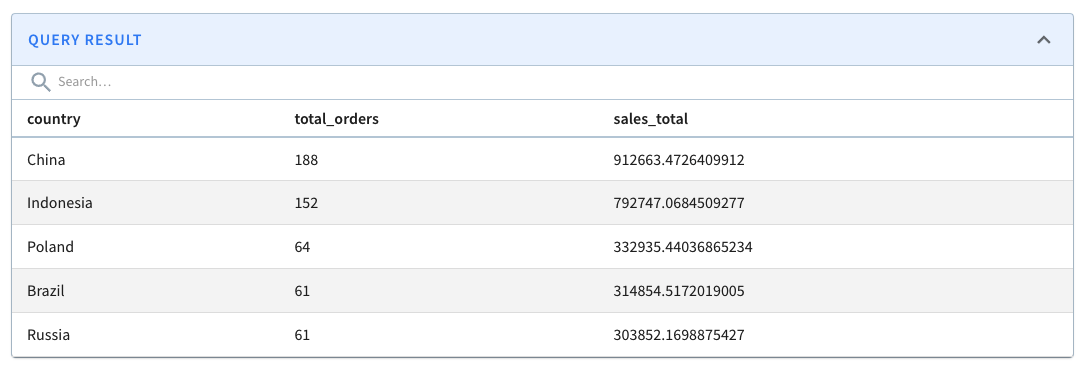
5.3 Find the top 5 countries by sales
Who are the top five countries that have contributed to the most sales?
The query will be the same as the above, but we will use the customers.country field to enrich the results further.
<span class="">SELECT
</span> lookup('customers','country','customer_id',customer_id) as country,
COUNT(*) as total_orders,
SUM(orders.amount) as sales_total
FROM orders
GROUP BY country
ORDER By sales_total DESC
LIMIT 5Code language: HTML, XML (xml)This returns:
Things to consider
When a table is marked as a dimension table, it will be replicated on all the hosts. Hence, the size of the dimension table has to be small. Pinot allows you to control the size of a dimension table to prevent oversized tables.
The maximum size quota for a dimension table in a cluster is controlled by controller.dimTable.maxSize controller property. Table creation will fail if the storage quota exceeds this maximum size.
Conclusion
The lookup UDF function in Pinot enables you to join a table with a small lookup table to enrich the final result of a query. These lookup tables must be modeled as dimension tables of type OFFLINE and possess a primary key.
Dimension tables are replicated across all servers of a Pinot cluster, taking advantage of data locality to perform fast and scalable lookups.
You can find more information about Lookup joins in the following video.
