
One of the most critical aspects of real-time analytics is the ability to derive timely and accurate insights from data in motion. Companies of all sizes are constantly generating data – whether that be new events (insert) such as clickstream, logs, and metrics, or updates to existing events (upsert) such as customer/employee profile changes. The ability to ingest these upsert events in a real-time analytics database is essential for generating the right insights. Real-time upserts ensure the query results are accurate and reflect the latest changes happening to your business.
For example, Uber’s financial intelligence and AdTech insights depend on accurate metrics generated from constantly updating events (like driver and rider location). Similarly, various risk and fraud detection use cases depend on the ability to derive instant and accurate insights from customer data managed by an Online Transaction Processing (OLTP) system (like MySQL, Cassandra, or MongoDB) that is constantly getting updated.
Apache Pinot was the first open-source Online Analytical Processing (OLAP) platform to support real-time upserts for all such use cases, unlocking a new way of doing things that was not possible using legacy systems. In this blog, we will take a brief look at how upserts are implemented in Pinot, along with its advanced feature set. In addition, we will also look at how StarTree improved on this amazing feature to make it more scalable and reliable in our fully-managed service.
What are real-time upserts?
An UPSERT operation combines the functionality of an UPDATE with an INSERT, all in one single operation. If a record already exists, it performs the record update. If it doesn’t yet exist, it performs an insertion of the data. This makes it very efficient when you cannot be sure a record already exists in the database. It minimizes the complexity of reading-before-writing to check on prior existence and avoids contentions when a single record may be repeatedly updated by many operations.
Also, “real-time” means upserts are available immediately — within milliseconds of ingestion. Otherwise, users can query stale data that doesn’t reflect the current state of affairs.
Real-time upserts are extremely useful when real-time data may have a high likelihood of rapid updates, such as fluctuating prices of a commodity, inventory levels for products, or tracking locations for where all your orders may be throughout their delivery routes.
Historically, real-time OLAP systems (including Pinot) were not designed to handle upserts, and there’s an architectural reason for this. Most of these databases followed an append-only paradigm with the use of immutable data structures, which enabled ease of scalability, better performance, reduced system complexity, and ease of recovery. Allowing data to be updated in real time increases complexity in all such aspects. When we designed upserts in Apache Pinot, our grounding principle was to minimize the impact on the scalability, performance, and complexity of data ingestion and query.
How upserts work in Apache Pinot
Here’s a quick view of how real-time data is ingested in Apache Pinot:
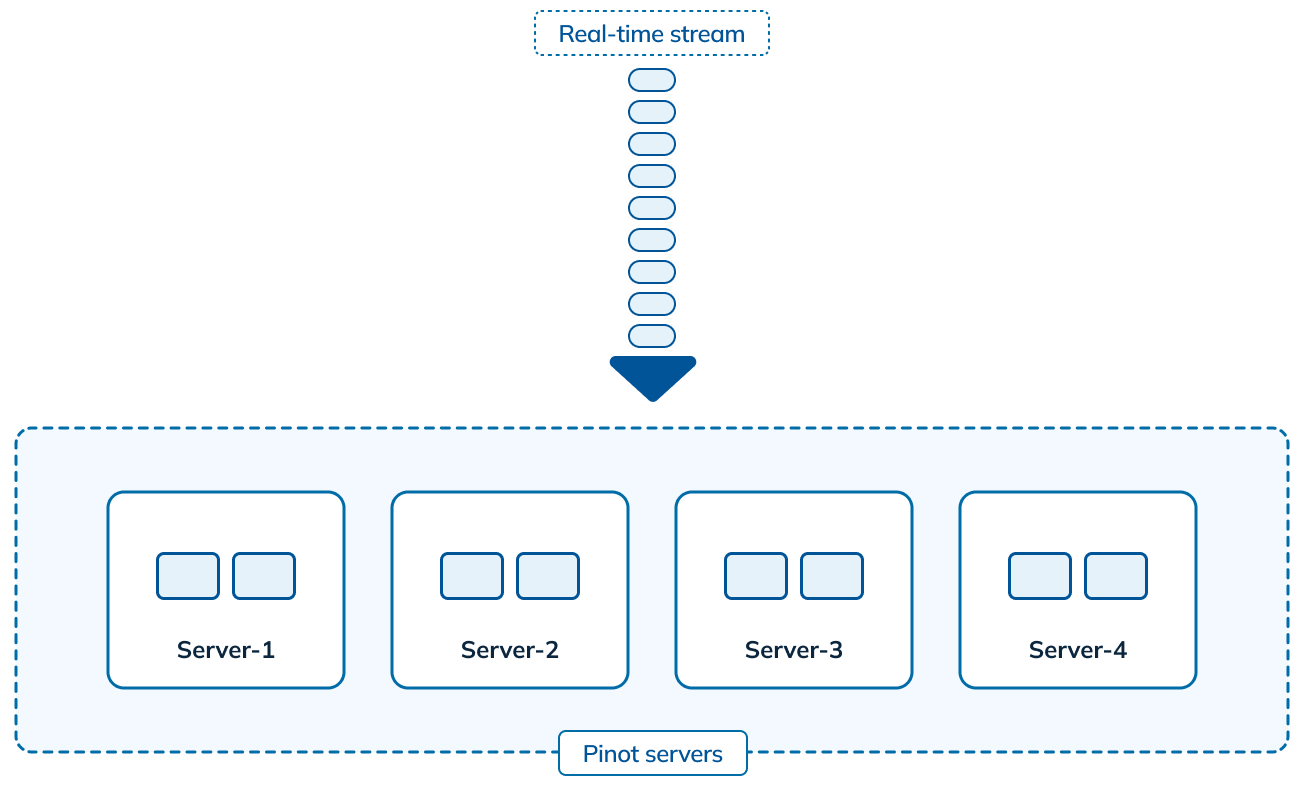
Figure 1: Real-time ingestion in Apache Pinot
Messages from an incoming real-time stream (like an Apache Kafka topic) are consumed across different Apache Pinot servers and converted into a columnar format called a segment. Such messages can be queried by Pinot clients as soon as they’re ingested by the servers (within seconds). In order to handle upserts, we made two key assumptions with respect to the incoming real-time stream.
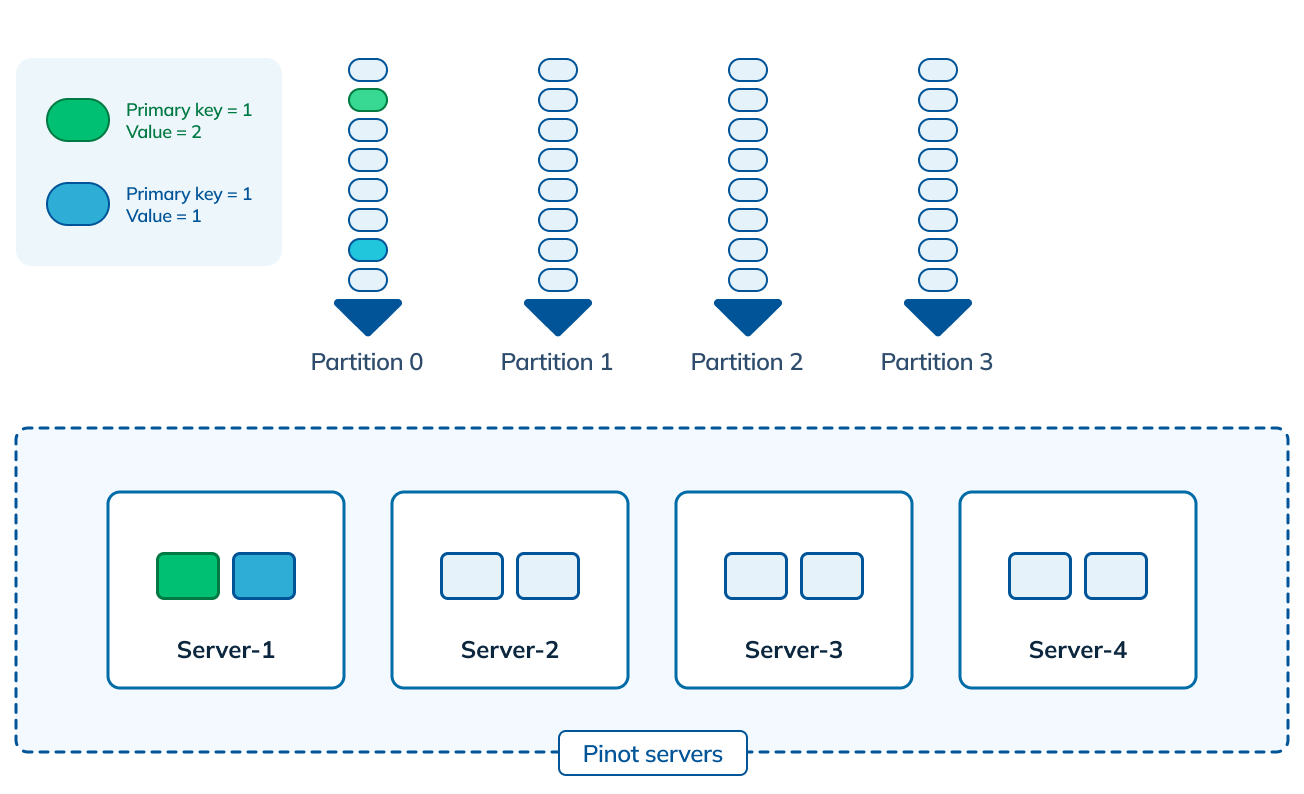
Figure 2: Real-time upserts in Apache Pinot using partitioned input stream
The incoming stream a) has to support the concept of a partition/shard and b) data is assumed to be partitioned by the primary key in the incoming stream. This means for a given primary key K1, all messages corresponding to K1 are co-located in the same incoming partition. This also allows all such messages to be co-located on the same Pinot server.

Figure 3: High-level architecture of upserts in Apache Pinot
In turn, each Pinot Server maintains a map of the primary key to the location of the latest version of the record for that key. When an existing record is upserted by a new one, the server uses this map to
- Mark the old record as obsolete using a per-segment bitmap
- Insert the new record, and
- Update the map.
All obsolete records are then filtered out during query execution.
Benefits of Pinot’s upsert approach
The benefits of this design include:
- Low ingestion overhead : The only additional work required is updating the map, which is very quick and efficient.
- Minimal query overhead : Per-segment bitmaps are used to filter out obsolete records, which is very fast. We’ve observed no significant change in query performance in the presence of upserts.
- Ability to view change history : If desired, we can view all the previous versions of a given primary key using the `skipUpsert=true` query flag.
In short, most of the work of merging upserts is done during ingestion (write) time, and very little during query (read) time.
One caveat of this approach is that the number of partitions must be carefully provisioned to handle organic growth, as it is difficult to change the number of partitions in the input stream after the fact. This is typically not an issue with systems like Apache Kafka.
To try out upserts for yourself, please look at this recipe.
Advanced upsert features
This section elaborates on some of the common operations routinely performed on real-time Pinot tables with the Upsert feature enabled.
Deletes
Pinot now also supports the ability to soft delete a primary key, starting with release 1.0. This requires the input stream to contain a special boolean column to indicate that the corresponding primary key should be deleted. During ingestion Pinot looks at this column, and if set to true, it will effectively mark all records corresponding to the specified primary key as obsolete and thus filter them out during query time. To know more about this feature, please read the wiki and check out the video.
Partial upserts
In certain situations, the incoming stream only contains partial information or a subset of the columns in the schema for a given primary key. For example, when consuming a Change Data Capture (CDC) stream from an upstream OLTP database, oftentimes we see only those columns that got updated in the corresponding transaction (eg: address / salary of an employee). In other cases, we may wish to stitch together various column values generated at different times in the same Pinot table (and schema). Pinot’s partial upserts capability allows you to handle such cases with ease.
With partial upserts, you can fine-tune the strategy for specific columns as desired. For example, we may wish to add new values to the existing one for column A, keep the max value for column B, and ignore any new values for column C. This can be achieved with the following configuration:
{ "upsertConfig": { "mode": "PARTIAL", "defaultPartialUpsertStrategy": "OVERWRITE", "partialUpsertStrategies":{ "columnA": "INCREMENT", "columnB": "MAX", "columnC": "IGNORE" } }, "tableIndexConfig": { "nullHandlingEnabled": true } }Code language: JSON / JSON with Comments (json)Copy
In this example, the default strategy is OVERWRITE, which is applied to all other columns. For more information on partial upserts, please read the wiki. You can also try it out yourself using this recipe (and check out the video ).
Compaction
As discussed above, the design of upserts in Pinot retains the append-only paradigm. This means over time the Pinot table might have a lot of obsolete records, depending on the percentage of upserts done in the input stream. More upserts equates to more obsolete records. Although these records are filtered out in the queries, they continue to occupy disk space and add to the overall infrastructure cost.
To address this, the 1.0 release of Apache Pinot added segment compaction support using a new minion task aptly called ‘UpsertCompactionTask’. This task will periodically replace completed Pinot segments with newer compacted segments that only contain valid records (i.e. not upserted by newer records). This can be configured in the table config as shown below:
"task": { "taskTypeConfigsMap": { "UpsertCompactionTask": { "schedule": "0 */5 * ? * *", "bufferTimePeriod": "7d", "invalidRecordsThresholdPercent": "30", "invalidRecordsThresholdCount": "100000" } } }Code language: JavaScript (javascript)Copy
To learn more about this feature, please find the details in the 1.0 blog.
Configurable comparison column
By default, Pinot uses the primary time column to resolve upserts. In other words, during ingestion, the record with the largest timestamp “wins” and others are marked as obsolete. While this works for a lot of cases, sometimes you may want to choose a different time column for doing this comparison (and yes, Pinot supports multiple time columns in the same schema). This can be achieved by specifying the following in the table config:
{ "upsertConfig": { … "comparisonColumn": "anotherTimeColumn" } }Code language: JavaScript (javascript)Copy
For more information, please read the wiki.
Bootstrap and backfill
Just like any other Pinot table, users need to be able to bootstrap and backfill data into an upsert-enabled table. One way is to simply stream this data back into the Kafka topic and let Pinot ingest it. Although simple, this approach is inefficient and time-consuming.
A better way is to use a batch data pipeline for uploading segments directly to Pinot. This can be done via frameworks like Apache Flink (specifically Flink Pinot Connector ) or an equivalent Apache Spark job. Regardless of which framework you choose, the effect is still the same – we can upload segments directly to an upsert-enabled real-time Pinot table. This can either be used for bootstrapping data for a new table or backfilling a date range in an existing table. Yupeng Fu (Principle Engineer, Uber) talks about this in detail in his RTA talk: Backfill Upsert Table Via Flink/Apache Pinot Connector.
Upserts in StarTree Cloud
One of the biggest limitations of the upserts functionality in Apache Pinot is the memory overhead needed to handle the primary key map stored on the JVM heap. Depending on the total memory available in the Pinot servers, this puts a limit on the total number of primary keys that can be managed in the real-time upsert tables. In StarTree Cloud, we’ve removed this limitation and improved the scalability of the upserts feature.
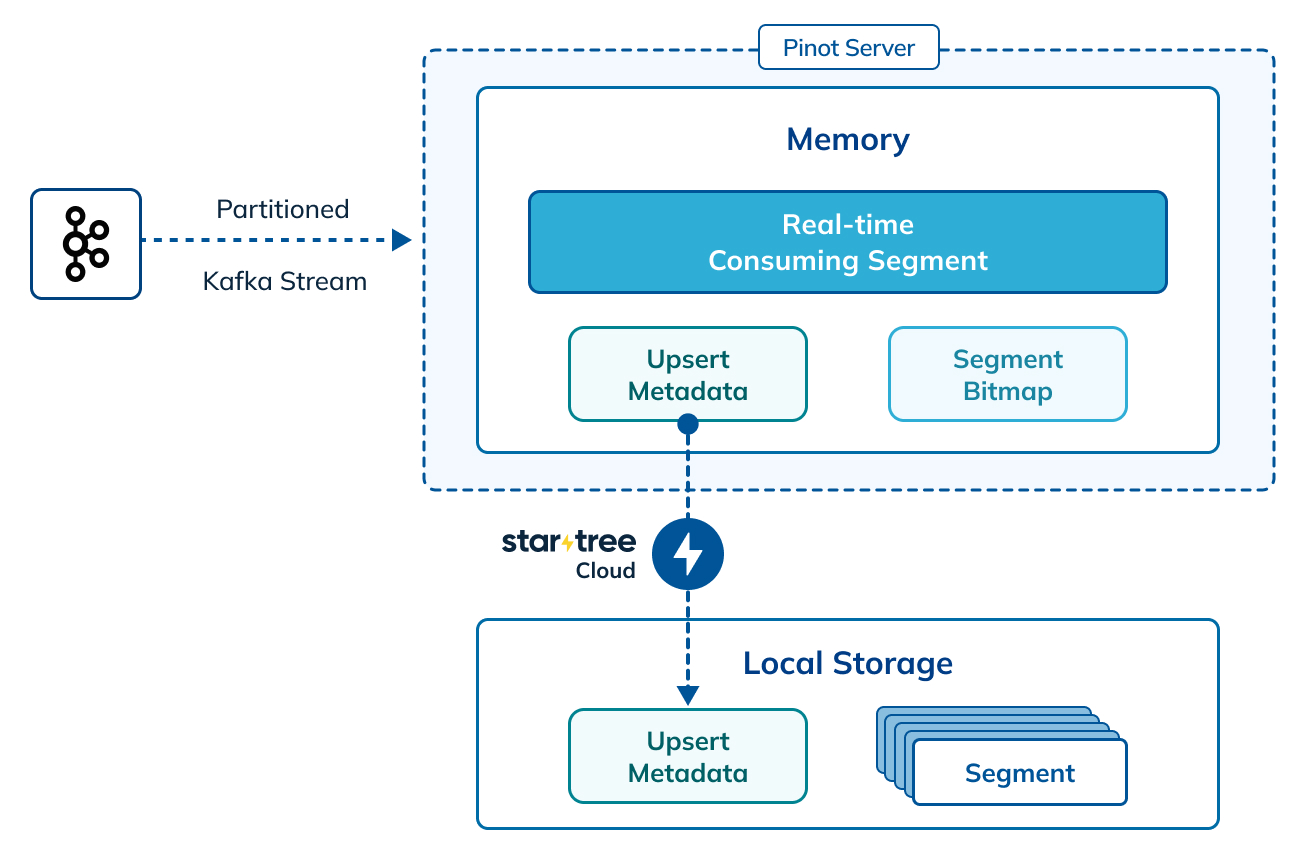
Figure 4: High-level architecture of upserts in Startree Cloud
As shown above, StarTree Cloud uses local storage to persist the upsert metadata and get around the memory limitations of open-source Pinot. StarTree Cloud workspaces can now handle billions of primary keys per server without sacrificing performance.
Summary
Real-time upserts are a must-have when building powerful analytical applications. Without this feature, users have to resort to complex ways of achieving the same result. With Pinot and StarTree, you can easily build instant insights on top of real-time mutable data coming from user behavior, database transactions, or business entity changes.
Curious how other OLAP databases handle upserts? Here’s a brief comparison of the upserts feature in Pinot, Druid, and ClickHouse:
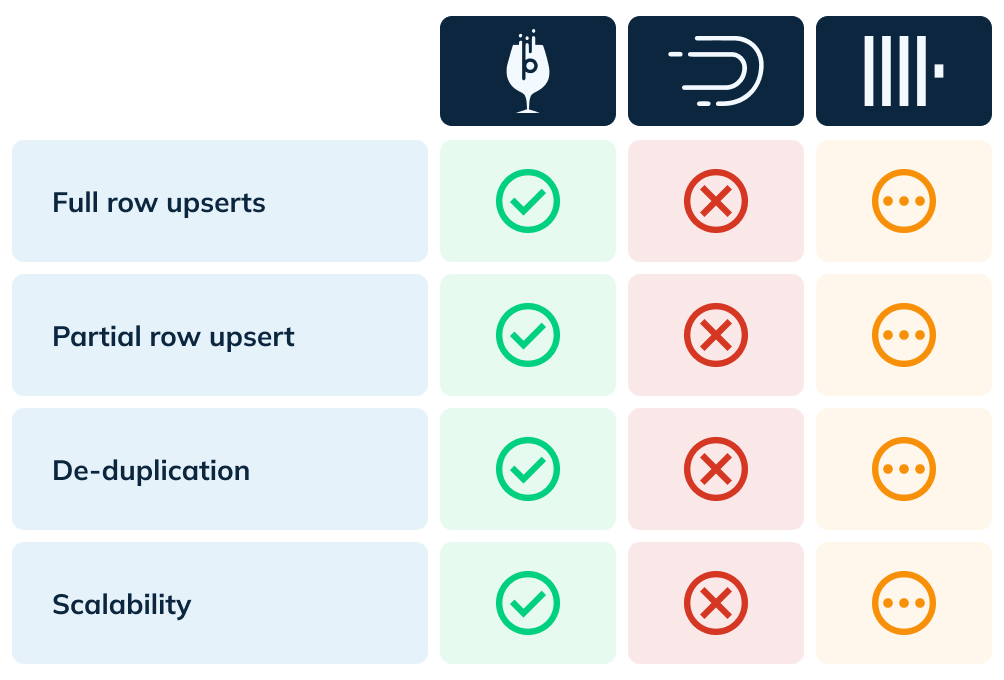
Figure 5: Comparison of upserts in Apache Pinot, Apache Druid, and ClickHouse
As shown, Apache Druid has no support for real-time upserts and ClickHouse has very limited support (done asynchronously and not in real-time). For more details on this comparison, please look at this blog.
Next Steps
Intrigued to try out upserts in StarTree Cloud? Sign up for a free trial of StarTree Cloud, the real-time analytics platform for user-facing applications.
