Real-Time Data Integration of Confluent Cloud with StarTree Cloud
Written By
Vibhuti Bhushan
Published
September 26, 2023
Reading Time
Users of Apache Pinot and Apache Kafka have gotten their wish answered! StarTree now offers a seamless, no-code integration between Confluent Cloud and StarTree Cloud. With the new Confluent Cloud connector in StarTree Data Manager, the process of integrating topics and data streams into real-time user-facing analytics applications has become far easier than ever before.
Open source Apache Pinot has long supported ingestion directly from Apache Kafka — practically since its inception — and we’ve talked many times before about integratingthe twoopen sourcetechnologies. However, many users have asked for — demanded, really — fully managed cloud-based solutions for both Apache Kafka and Apache Pinot. Their organizations want to run lean, focus on developing their applications and data models, and not be burdened with the backend administration of cloud services. Now, with support for ingesting data directly from Confluent Cloud, developing and managing real-time analytical applications based on data streaming is easier than ever before.
StarTree Data Manager: No-code self-serve data pipeline tool for ingesting data into StarTree Cloud
Apache Pinot supports data ingestion from a wide variety of sources such as streaming (eg: Kafka, Pulsar, RedPanda, Kinesis), batch (eg: S3, GCS, HDFS, Databricks Delta Lake) as well as SQL sources(eg. Snowflake, BigQuery, etc.). Users can create a new Pinot table and configure the corresponding ingestion mechanism in a declarative manner using the Pinot Table Config.
However, using the above mechanism to ingest data into Pinot requires extensive knowledge of Apache Pinot, is complex especially when it comes to data modeling and doesn’t provide a feedback loop. This results in a repetitive error-prone process which raises the bar to ingest data for folks who are not experts in Apache Pinot.
StarTree Data Manager is a no-code, self-service tool that helps even a first-time user quickly get started with Pinot. It provides a convenient workflow-based wizard to walk users through the different table creation steps, including advanced settings. Data Manager also makes it very easy to iterate on the data model before creating anything within the Pinot cluster. With Data Manager, StarTree users can go from registration to first query within a matter of minutes.
How to ingest data from Confluent Cloud using StarTree Data Manager
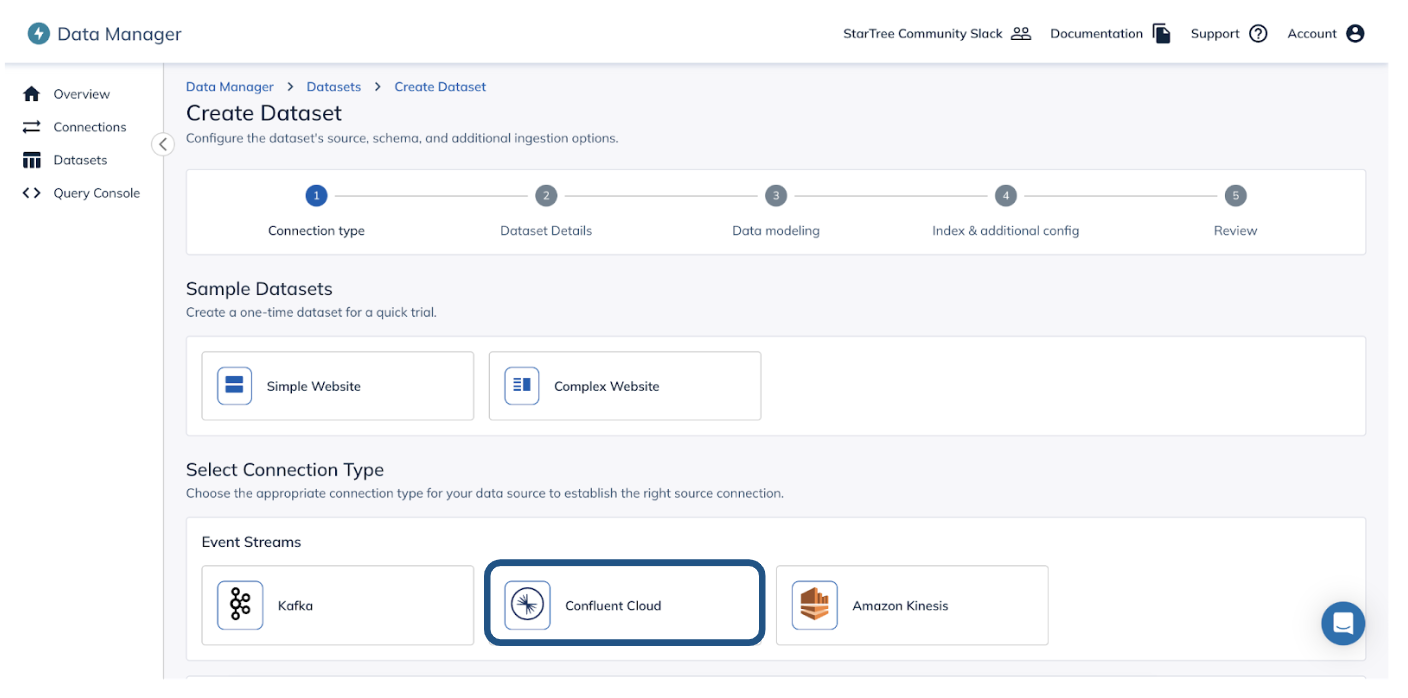
Users can create a table using StarTree Data Manager in 4 simple steps:
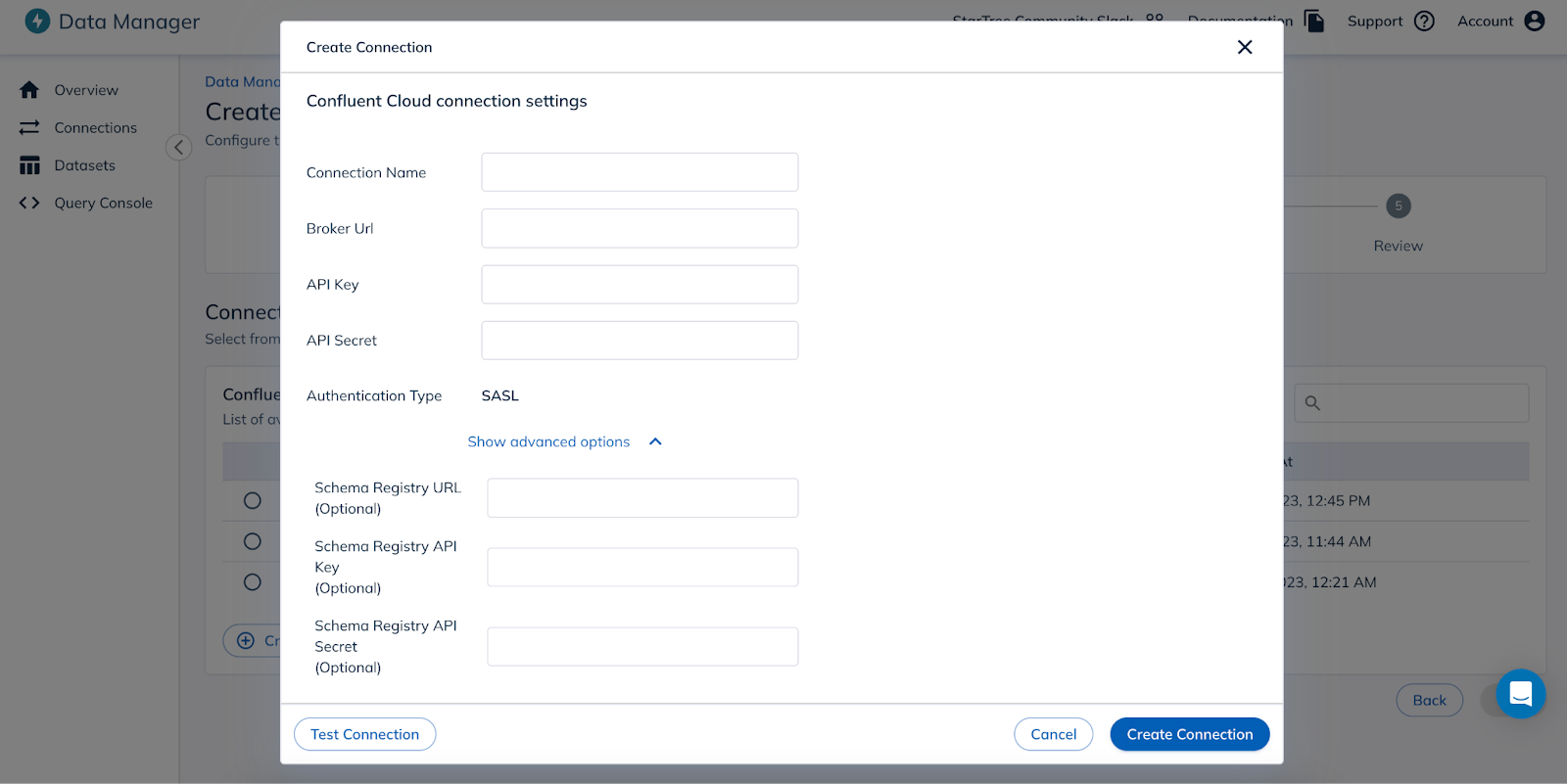
Connect to Confluent Cloud: StarTree Data Manager supports a variety of data sources and categorizes them in different source types. Confluent Cloud can be found under the Event Streams category.Users can either select an existing connection or create a new connection with Confluent Cloud. To create a new connection, users need to have the broker URL and API key and secret to connect to Confluent Cloud. If the user wants to use a schema registry, they need to provide relevant information for that here as well. It can be ignored, if the schema registry is not used.
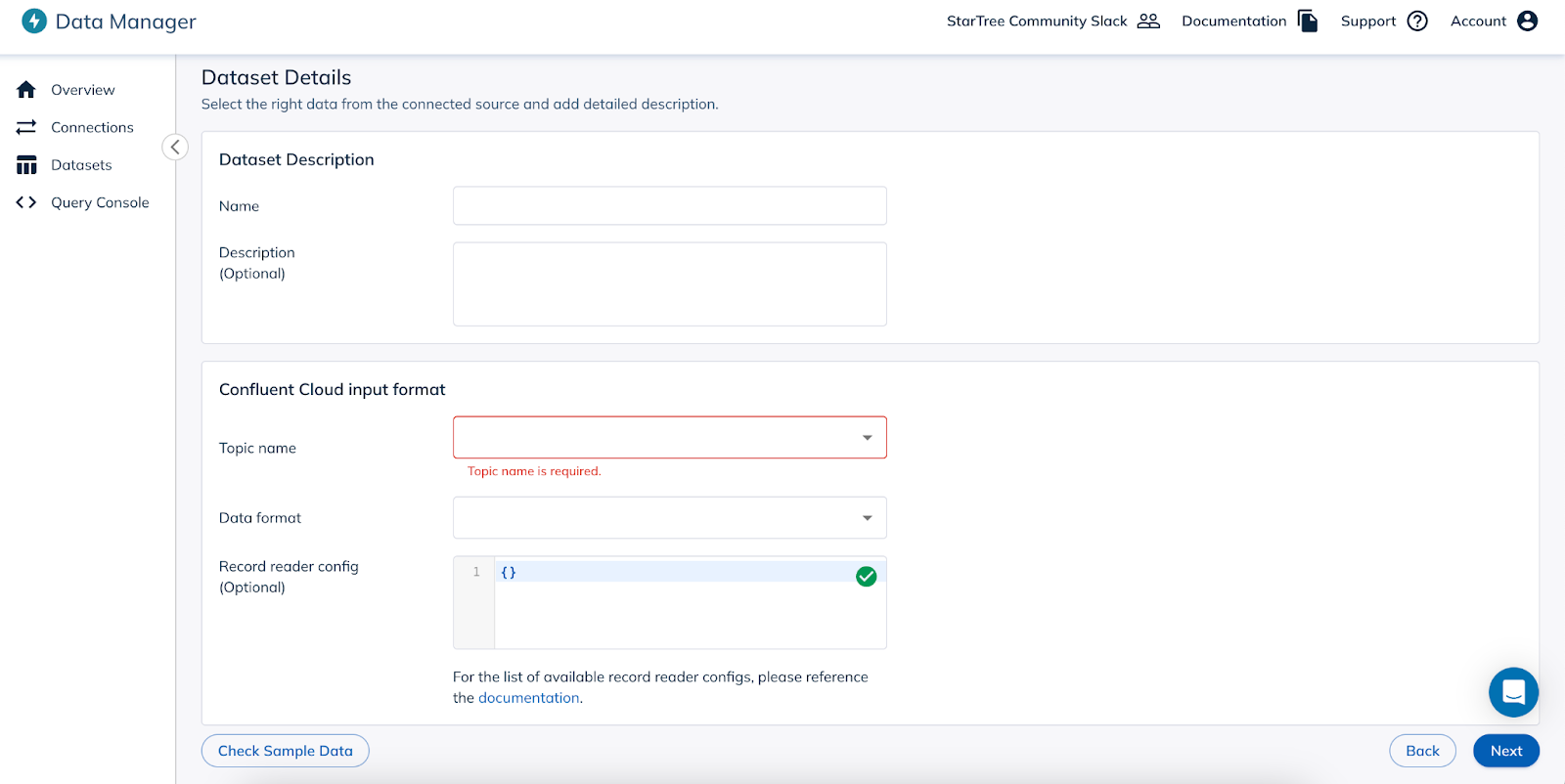
Topic Selection: Now that StarTree can connect with Confluent Cloud, users need to select the topic they want to integrate with and the data format. Before going to the next step, Data Manager will check the connection and pull in some sample data to make sure the connection is working properly.
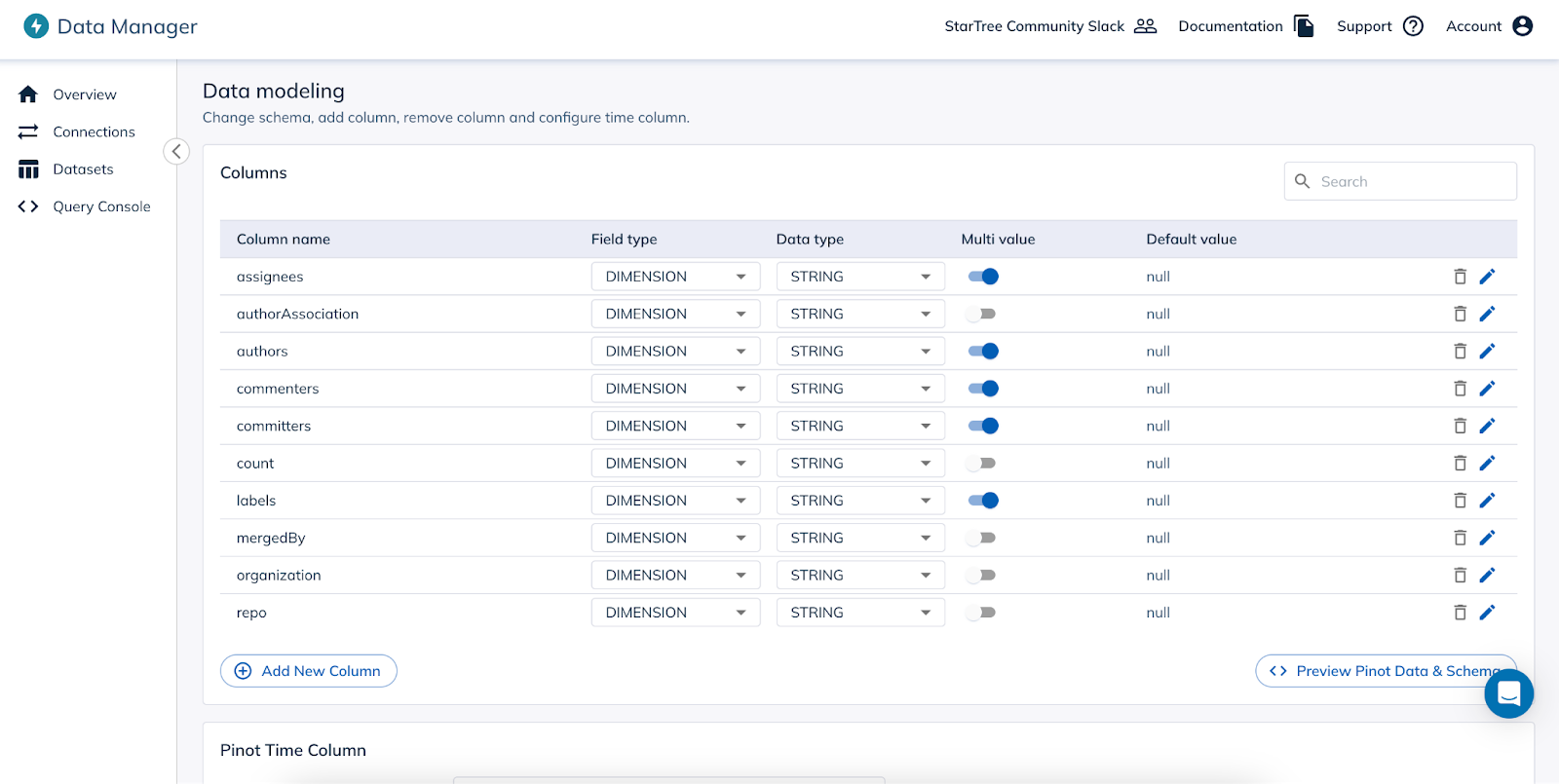
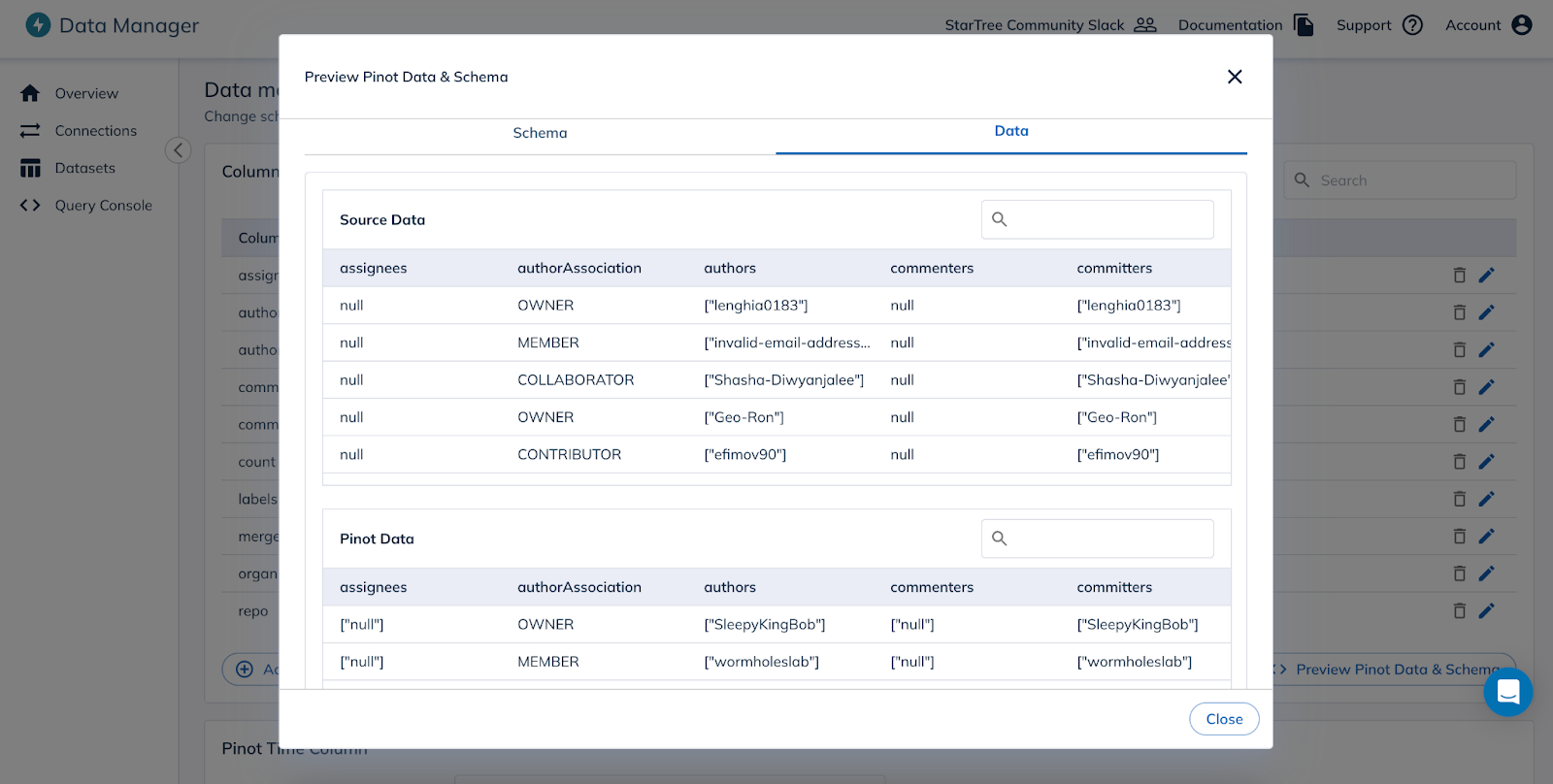
Data Modeling: This is one of the most challenging aspects of any data ingestion process. StarTree Data Manager provides an interactive interface to model data as needed for their user-facing applications. Data Manager infers the schema based on the source dataset and format. Users are also able to perform additional operations to create the data model they need for their application, such as removing columns, changing the inferred properties of a column and adding a derived column.With each change in the data model, users are also able to visualize the changes and compare it with the source. This instant feedback greatly simplifies the data onboarding process and reduces the chance of misconfiguration.
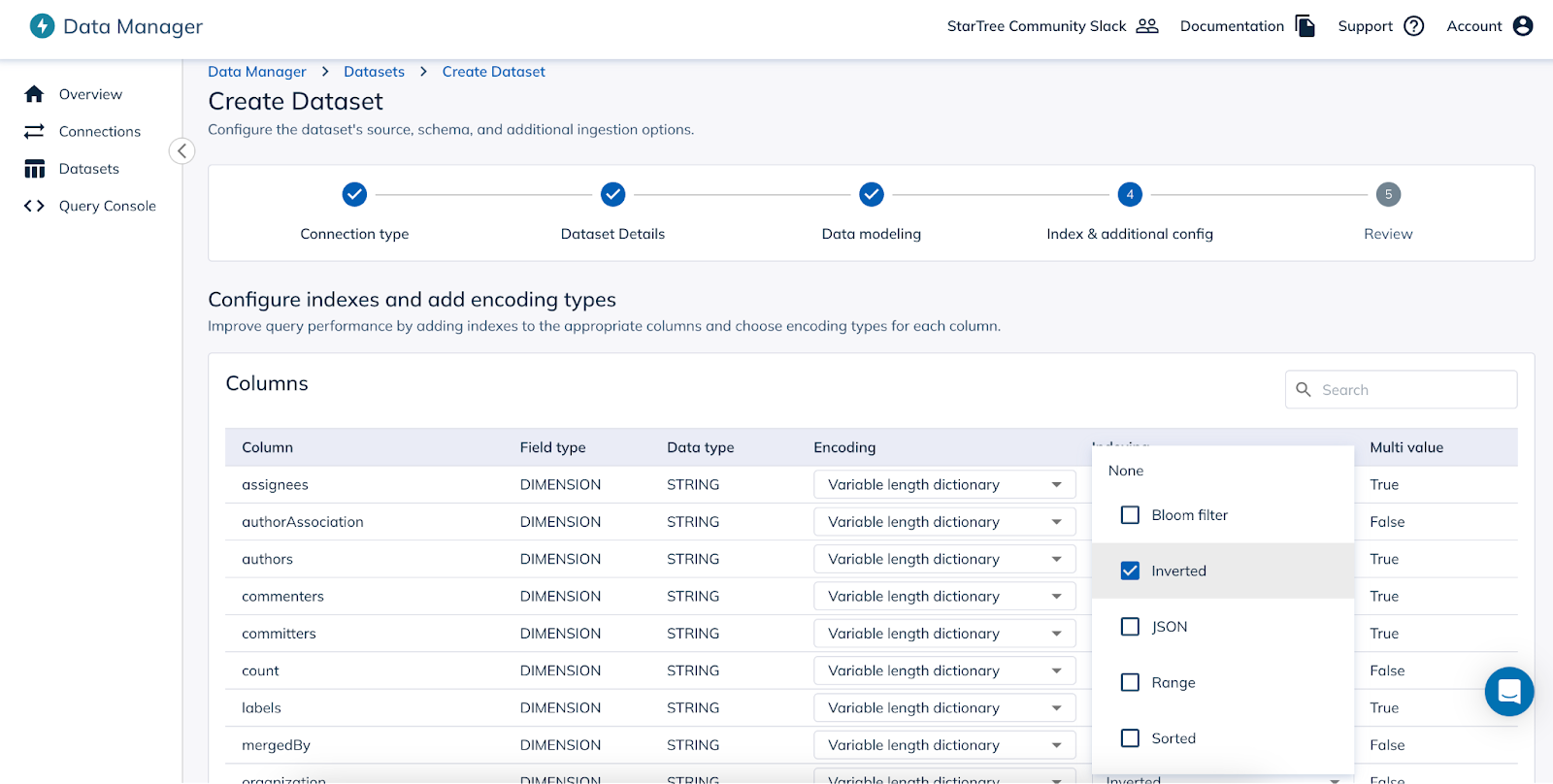
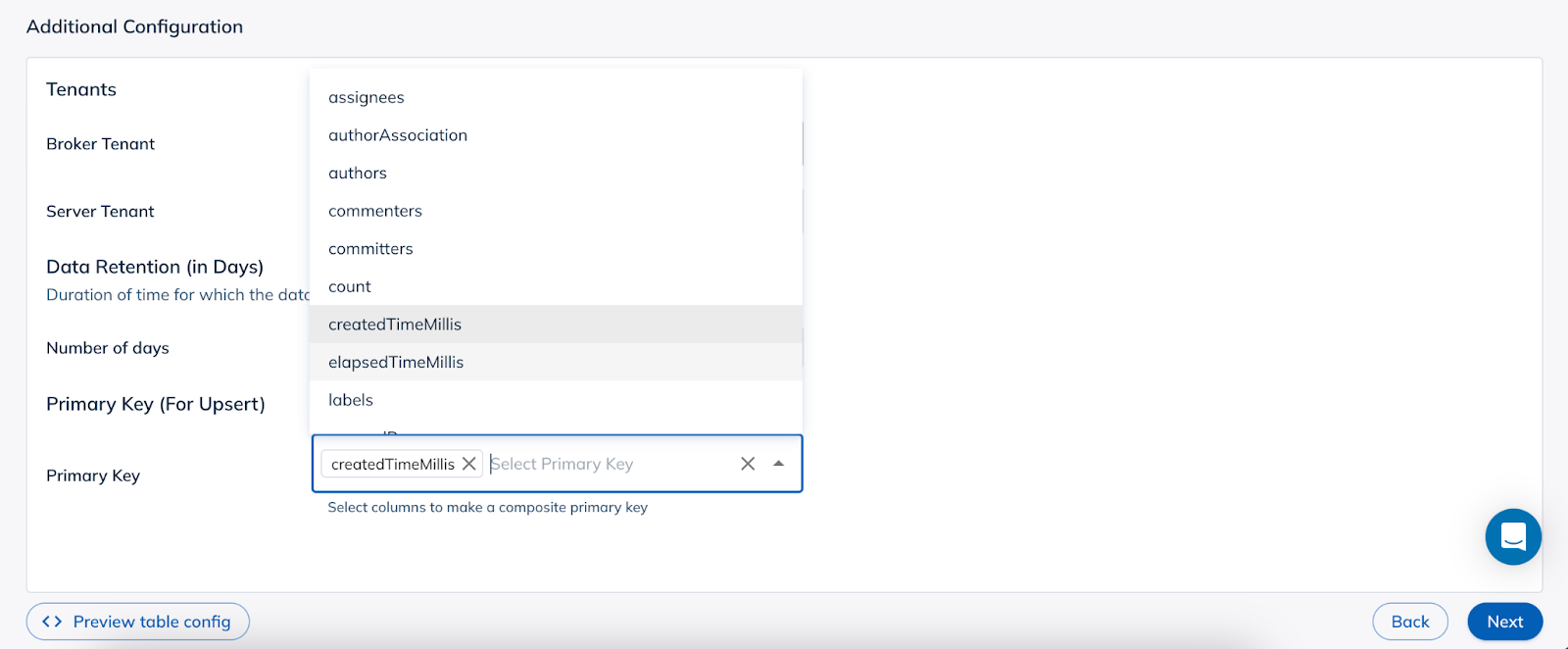
Advanced Configuration: In this section, users can create indexes including StarTree Index and also configure some advanced table properties like retention, enable upserts, etc.Similar to the data modeling section, all the operations here are no-code operations. Users are not required to write any code if they choose to. There is a JSON editor to configure these properties but that is something a user will not need to use to ingest data from Confluent Cloud.
In case users want to create a table with upsert, all they need to do is select a column or a set of columns as primary key to enable upsert.
StarTree Data Manager makes bringing data from Confluent Cloud extremely easy and allows users to start running queries with sub millisecond latencies in no time.
Try Data Manager on StarTree Cloud
Try Data Manager on StarTree Cloud. Request a trial to get access to Data Manager and experience the simplicity of Apache Pinot on StarTree Cloud. Or Book a demo if you have questions and would like a quick tour of how StarTree Cloud can work for you.
Contents
Share
RTInsights Research + Stratola Report
The Competitive Edge of Real-Time Data
Understand the transformative power of real-time data across industries, and uncover the technologies making real-time insights possible.