
Speed of Apache Pinot at the Cost of Local Disk Cloud Storage
Introduction
In today’s era of real-time analytics, the ability to crunch large quantities of data very quickly has become critical for modern businesses. User personalization, business metrics, fraud detection, and other mission-critical use cases need a system that can process 100s to 1000s of complex queries per second on such large datasets in real-time. In the last few years, Apache Pinot has stood out as a differentiator in the OLAP landscape to deliver such performance at scale across some of the biggest companies in the world including LinkedIn, Uber, Stripe, Walmart, and many more. StarTree provides a cloud-native, fully managed platform using Apache Pinot for companies of all sizes.
But how much data can Pinot process? And how much does it cost to serve queries on such large datasets? As it turns out, our clusters can process petabytes of data in a cost-efficient manner while still maintaining SLAs for the critical datasets. This is achieved using a new Tiered Storage solution that we’re making available in StarTree Cloud for limited customers. Read on to know more about this new feature and what motivated us to build it.
All Data is Not Equal
With the rise of event-driven architectures, enormous amounts of data are being collected by companies of all domains and sizes. Quite often, businesses find it necessary to retain several months or even years of data. But, all data is not equal. The fresh and recent data is often more valuable than the historical data, and typically queried more frequently. Naturally, users are willing to pay more for fresh data insights and expect better latency SLAs. Since the historical data is queried less frequently and is of relatively lesser value, users want to optimize for cost at the expense of slightly higher latencies.
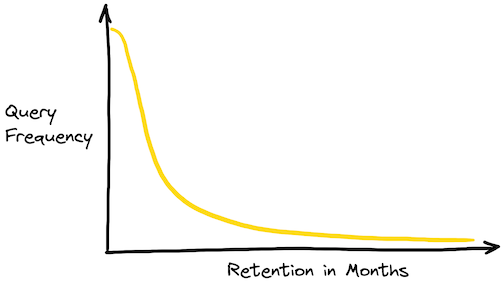
Fig 1. A typical distribution of queries and the time range they span
A Tale of Two Architectures
Modern real-time analytics systems can generally be categorized into decoupled and tightly-coupled systems. In decoupled systems, the storage and compute resources are decoupled and can scale independently of each other. Such systems store data on cloud storage solutions, which leads to lower costs at the expense of query performance. In contrast, tightly-coupled systems can achieve much better query latency and throughput. But such systems tightly couple the data to the compute nodes. As the total data volume grows, more resources (compute + storage) need to be provisioned, whether or not the corresponding compute resources are utilized, resulting in a high cost to serve.
Based on the above graph, here’s what the cost and latency pattern looks like for the two architectures:
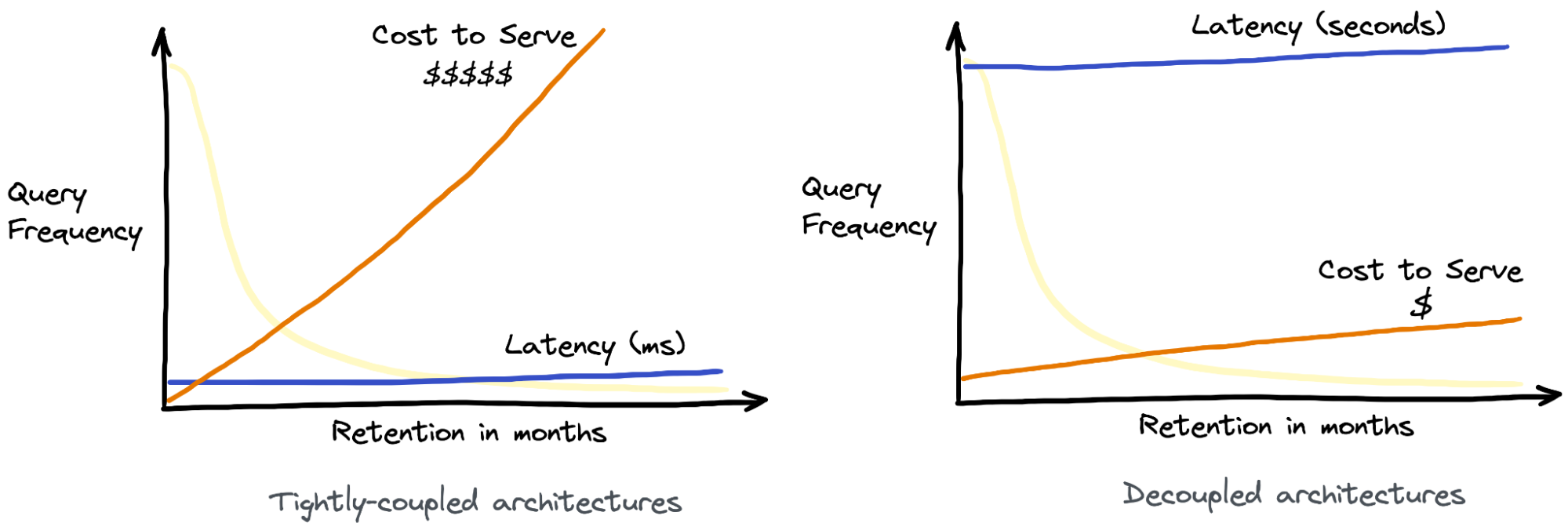
Fig 2. Cost vs latency tradeoff in real-time analytics systems with storage & compute tightly-coupled (L) vs decoupled (R)
Apache Pinot: Built for Speed
Apache Pinot – built for high throughput low latency use cases – was originally designed with a tightly-coupled architecture in mind. Here’s a brief architectural diagram of Apache Pinot:

Fig 3: Apache Pinot Architecture (Ref: What makes Apache Pinot fast – Chapter I)
A Pinot cluster consists of several data nodes known as ‘Pinot Server’ that can ingest data from various sources (streaming, batch, SQL) and store it locally as ‘Pinot Segments’ on attached storage volumes. A ‘Pinot Broker’ then performs distributed scatter-gather as part of the query processing. Each Pinot Server will locally execute the query, which is very fast since the data is locally accessible. Read more about different Pinot components on this wiki page.
Users loved the speed and many Pinot users came back for more (read more in What Makes Apache Pinot Fast – Chapter II). They wanted to keep the data in Pinot forever, but the tightly-coupled storage was not cost-effective. Ideally, users want to leverage the speed of the tightly-coupled architecture and the cost-effectiveness of the decoupled architecture.
Introducing Tiered Storage in Apache Pinot
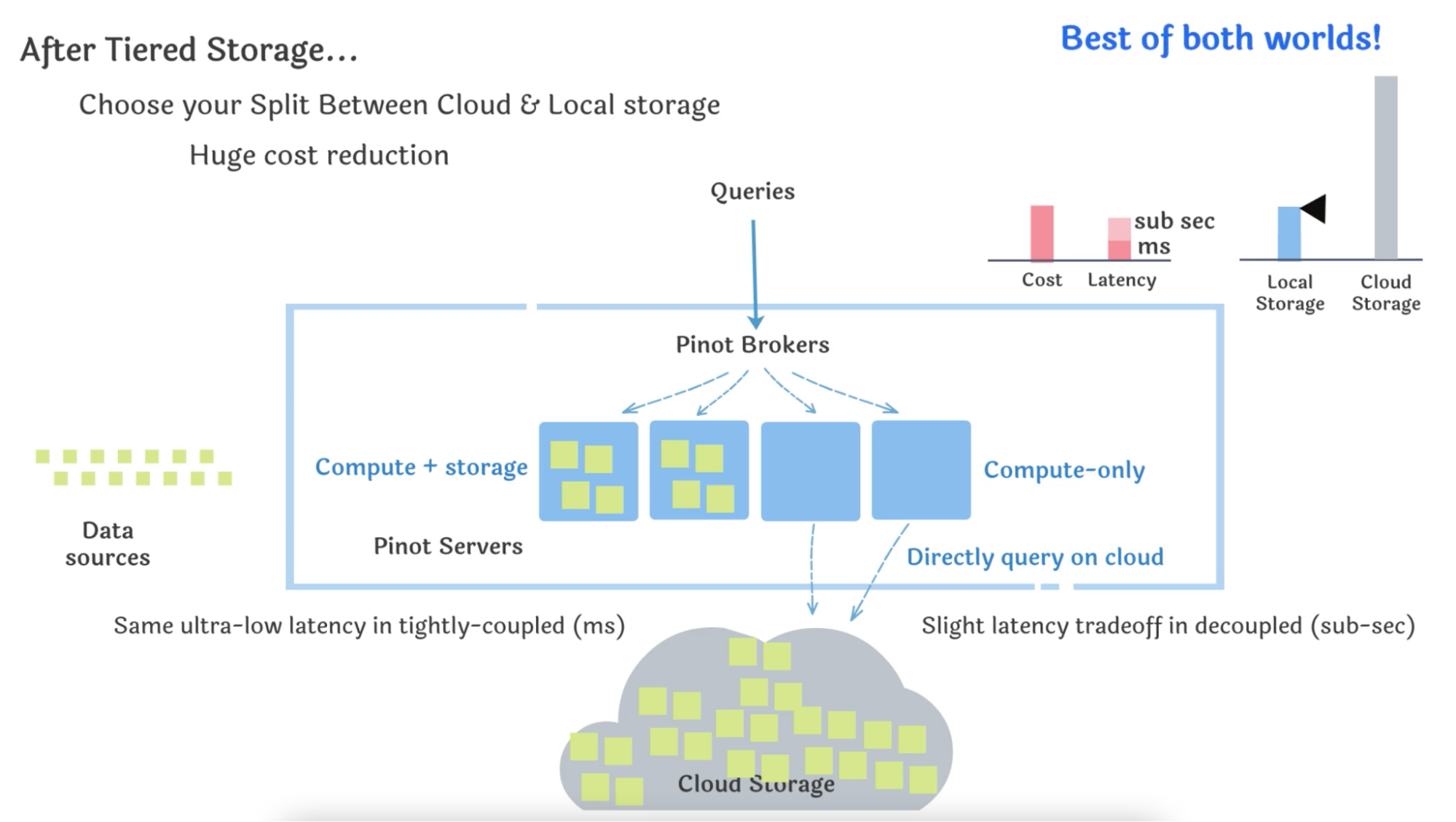
We are excited to announce Tiered Storage for Apache Pinot which combines the best of both worlds! Users can now choose a portion of the data from their Pinot datasets to reside locally as tightly-coupled, and the rest will reside on cloud storage. For instance, users can configure their Pinot table to host the first 7 days of data in local storage. Behind the scenes, all other data (i.e. Pinot segments with age > 7 days) are automatically migrated by Pinot to cloud storage. This threshold (7 days) is dynamic and can be changed at any point in time and Pinot will automatically reflect the changes. Users can then query the entire table, across local and remote data, like any other Pinot dataset.
To support tiered storage, we built an abstraction for the file system making Pinot agnostic to where the segment is located. As a result, Pinot can query the segment whether it is on local or cloud storage. Note that this is not implemented as lazy-loading – Pinot servers directly query data on the cloud and are never downloading the entire segments locally. In the first version, we have added the implementation for Amazon S3. The architecture is pluggable, setting us up to easily build future extensions to Azure Blob Store and GCP.
A lot of techniques have been used to minimize processing time such as smart pre-fetching of required indexes and column data during query processing. Additional optimizations include in-memory + persistent cache on the compute nodes with intelligent memory management. We will go through all these techniques in-depth in our follow-up blogs.
Benchmarking Tiered Storage
To demonstrate the power and value of this feature, let’s walk through the results of a small test we conducted.
We set up a Pinot cluster and uploaded ~500G of data. We used the publicly available Github Events data.
To begin with, the cluster was configured to tightly couple the storage and compute. In other words, all data must reside locally in the Pinot cluster ( roughly $150/month). We then ran some queries to establish the baseline (see column Tightly coupled).
We then put the same data on a decoupled system. That brought down the local storage utilization from 500G to 0 and added marginal cost for storing the same data on cloud storage (roughly $10/month). But now the same queries have much higher latencies (see column Decoupled)
At this point, we decided to configure tiered storage for the Pinot cluster. This migrated all Pinot segments to the cloud storage. Similar to the Decoupled case, this brought down the local storage utilization from 500G to 0 and added marginal cost for storing the same data on cloud storage (roughly $10/month). The latency did go up compared to the tightly-coupled case. However, it is a much smaller tradeoff compared to the decoupled case, for the same cost savings. Also, note that this reflects the worst-case scenario from a performance perspective, where 100% of the data is served from cloud storage.

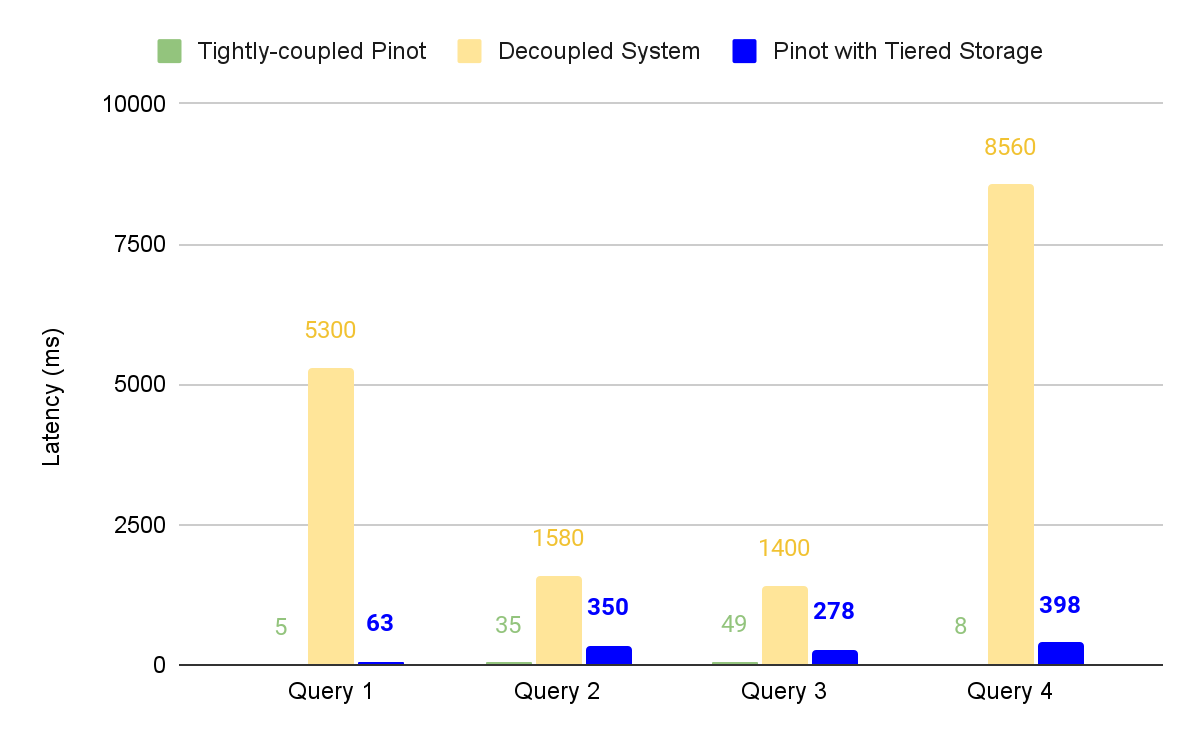
Best of Both Worlds
Now imagine, if our use case needed 10 times the retention. In tightly-coupled storage and compute, we would need to increase our storage infra cost by 10x ($1500/month). But with tiered storage, the cost of storage remains low ($10/month) whether we need to query a few days ago, months ago, or even years ago, in exchange for slightly elevated latencies. And we’re able to achieve this with just a single system!
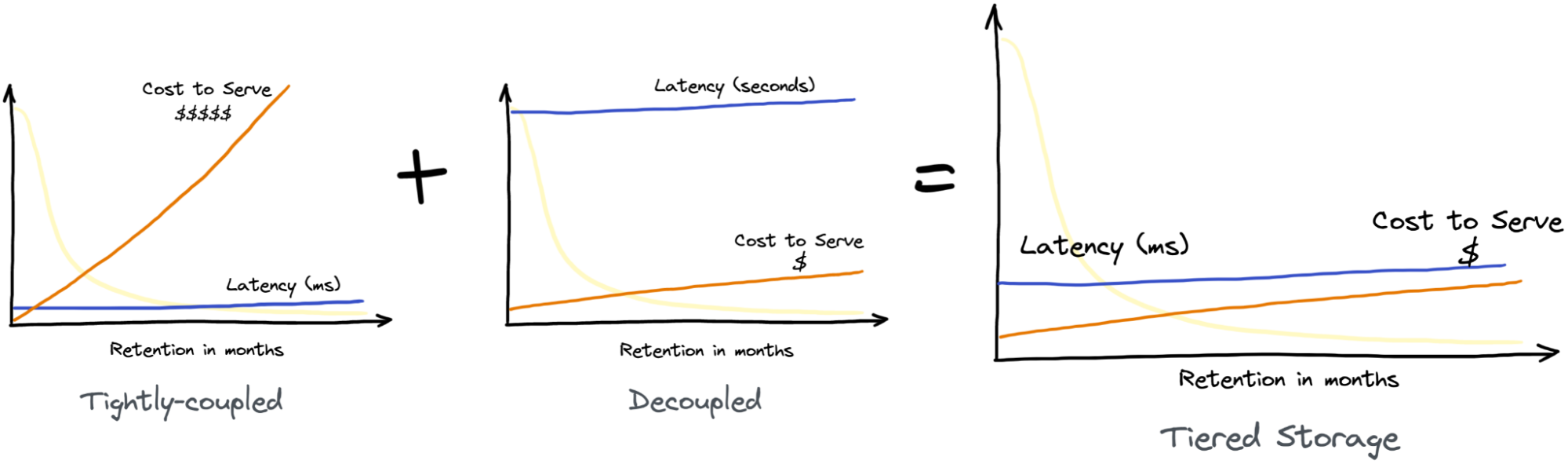
Fig 4: The best of both worlds in Apache Pinot with Tiered Storage
What’s Next?
As of today, StarTree cloud users can try out Tiered Storage for AWS deployments. It allows you to create datasets with a combination of local and remote storage. Users have full control over what data goes where using a dynamic age threshold. Tiered Storage thus unlocks the following:
- Infinite Retention: You can now throw massive amounts of data at Pinot and be able to query over the entire spectrum in a seamless manner. This is a game-changer since now you don’t need to rely on different systems for processing real-time and historical data.
- Reduced Cost to Serve: Pinot can now easily manage large amounts of data in a cost-effective manner. With Tiered storage, we can ensure a minimal infrastructure footprint required for query processing without worrying about the total data volume. Tiered Storage opens the door for using cheaper spot instances for compute, since nodes are now stateless.
- Compelling Query performance: As we saw in the benchmarks above, you still get the same lightning-fast query performance for fresh data residing in local storage and slightly elevated but ballpark query performance for remote data.
But we’re just getting started! In the next few releases, we will be rolling out a lot of advanced techniques such as
- Always local indices: Choose which Pinot indexes must always be cached locally.
- Cache optimizations: New and improved caching techniques
- Support for various cloud storage systems
- And much more …
Stay Tuned!
We’d Love to Hear from You
Here are some ways to get in touch with us!
You can get in touch with StarTree by contacting us through our website. We encourage you to Book a Demo or contact us for a free trial.
New to Apache Pinot? Here are some great resources to help you get started. You can find our documentation here, join our community Slack channel, or engage with us on Twitter at StarTree and ApachePinot.