
Apache Pinot was purpose-built for real-time ingestion and to provide millisecond latencies for OLAP queries from day 1. Pinot achieves data freshness of near real-time because the consumers, which ingest the data from real-time sources, run directly on the Pinot servers responsible for serving the data. The Pinot servers ensure that the data is queryable as soon as it is ingested without any additional overhead.
However, real-time support is only half of the story. With its smartly designed, decoupled architecture, Apache Pinot also supports ingesting data from batch data sources such as object store data lakes (like Amazon S3 and Delta Lake) or data warehouses (such as Snowflake and BigQuery) through its minion component.
In this blog, I will highlight two things:
- How batch ingestion from data lakes work under the hood in StarTree, a managed Apache Pinot platform.
- How StarTree’s Minion Autoscaling helps customers save costs on their cloud infrastructure spend. I will use data lake–based ingestion as an example to highlight this, but it is applicable to all minion-based tasks including other batch ingestion flows (Snowflake, BigQuery, and such).
Batch ingestion in Apache Pinot
When it comes to ingesting batch data in open source Apache Pinot, there are many options. For example, data engineers can use an external application such as Apache Spark to generate Pinot segments and upload/push them to the Pinot cluster using the Controller API.
StarTree Cloud, powered by Apache Pinot, has some unique built-in options for automated and scalable ingestion. Since our foundation we have invested heavily in building features that are geared towards ease of use and operational excellence.
The blog touches on the following differentiating features of StarTree Cloud (a fully managed Apache Pinot platform):
- Data Manager – Provides ease of use for onboarding datasets from various data sources (real-time or batch).
- Minion FileIngestionTask – Simplifies your tech stack by bringing batch ingestion in-house in Apache Pinot and eliminating that external dependency on having to write external jobs (in Apache Spark or Java).
- Minion Autoscaling – Leverages cloud elasticity to help optimize cloud spend.
- Grafana Dashboards – For observability in Apache Pinot.
StarTree Data Manager is one such feature; it provides a click-through wizard through which the user can point to an ingestion source of their choice (batch or real-time), do schema modeling, configure indexes and boom! — onboard your dataset in a matter of minutes.
Another such feature is StarTree’s Minion FileIngestionTask, which brings batch ingestion in-house in Apache Pinot by leveraging the minion framework.
How minion-based batch ingestion works in StarTree Cloud
A minion in Apache Pinot is a stateless component. It is designed to perform administrative operations. Some examples include repartitioning data post-ingestion, merging smaller segments into larger ones for optimal query performance, and so on.
StarTree’s Minion FileIngestionTask is designed to ingest data from batch data sources such as cloud object stores (S3, GCS, Azure Blob Store) into Apache Pinot.
A FileIngestionTask generates a number of sub-tasks, which can run independent of each other — either sequentially or in parallel depending on the availability of minion worker resources.

FileIngestionTask has a few tunable configurations that can be used to maximize resource utilization and improve ingestion speed. StarTree Data Manager abstracts these complexities from users; it automatically generates configurations that are optimized for ingestion as well as for querying.
Let’s look at these configurations and understand what they mean:
1. Task max data size
This knob is used to tune the degree of task parallelism.
This is configured to derive the optimal throughput from a single minion, which then can be horizontally scaled/applied across many minions for parallelism. In other words, this defines the maximum amount of input data (uncompressed) a single minion sub-task can process.
Default value = 1G
The task planner creates a number of subtasks based on this configuration.
Total # of subtasks = Total input data size DIVIDED BY task max data size.
Example:
- Let’s say we have 100G of total input data to be ingested.
- Task max data size = 1G (Default)
- # of sub-tasks = 100G / 1G = 100
2. Desired segment size
Desired size for each segment: Default 500MB.
The input data from external sources have their own compression factors (eg: snappy Parquet). The system automatically figures out the optimal number of documents from the input source that needs to fit into the segment based on the desiredSegmentSize provided by the user.
Apache Pinot stores the data in chunks of segments that can be operated on (queried, built indexes on, reloaded, etc.) independently. Each Pinot segment stores the data in a Pinot-specific columnar format, which is optimal for OLAP query patterns.
The number of segments defines the degree of parallelism at table level.
However, having too many small segments (size in KBs) can be counterproductive.
With the default configuration, each sub-task breaks down the ingested data into chunks of segments of 500MB each.
"FileIngestionTask": {
"input.fs.className": "org.apache.pinot.plugin.filesystem.S3PinotFS",
"schedule": "0 */5 * ? * * *",
"input.fs.prop.region": "<AWS_REGION>",
"inputDirURI": "<S3_PATH>",
"desiredSegmentSize": "500m",
"taskMaxDataSize": "1G",
"tableMaxNumTasks": "-1",
"input.fs.prop.iamRoleBasedAccessEnabled": "true",
"inputFormat": "PARQUET",
"input.fs.prop.roleArn": "<ROLE_ARN>",
"includeFileNamePattern": "glob:**/*.parquet"
}
Code language: JavaScript (javascript)3. Schedule
Additionally and optionally, you can also configure a cron schedule to trigger the minion task at a periodic schedule of your choice. At every periodic run, the controller checks if the new data has arrived at the input source (specified by inputDirURI). If new files have arrived, then the controller generates a plan and submits a FileIngestionTask. If there are no new files, then the controller treats it as a “no op”.
4. Max concurrent tasks per worker
This defines the degree of parallelism at the worker level. In other words, this config determines how many sub-tasks can run concurrently on a given minion worker.
Default configuration = 1
This configuration is set at the cluster level using cluster/configs Controller Admin API.
In StarTree Cloud, each minion worker comes with 2 vCPUs, 8 GB memory, and 100GB of Persistent Storage Volume (EBS).
When onboarding a new use case, it is a good practice to start your first iteration with max worker concurrency of 1. If resource utilization (CPU, memory, and disk storage) is under 50%, then bump up the config to 2 and 3 and so forth in the following iterations until the utilization reaches 80-90% mark. The idea is to pack as many tasks as possible on a single minion worker maintaining a healthy peak resource utilization (80 to 90%).
Let’s put things into perspective with an example
Let’s walk through an example of the Minion FileIngestionTask in action. Let’s say each subtask takes 6 minutes to finish.
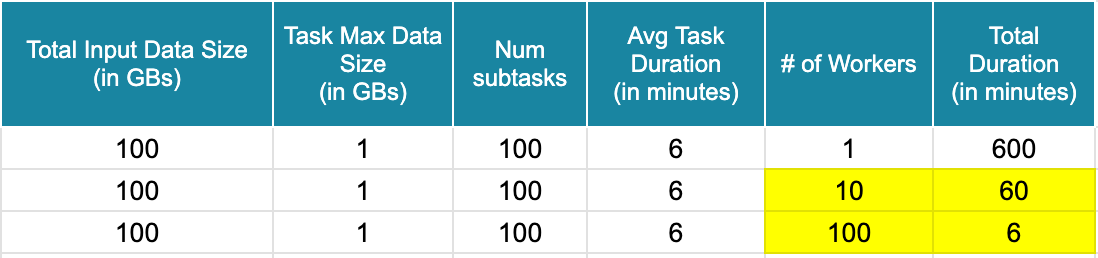
Projections:
- With 1 minion worker, 100 sub-tasks will run sequentially one after the other and the FileIngestionTask will finish in 100 * 6 = 600 minutes.
- With 10 minion workers, 100 sub-tasks will run in batches of 10 one after the other and the FileIngestionTask will finish in 10 * 6 = 60 minutes.
- With 100 minion workers, all 100 sub-tasks will run in parallel, and the FileIngestionTask will finish in 6 minutes.
Depending on the available minion capacity, the FileIngestionTask in this example can finish in as fast as 6 minutes or as slow as 10 hours. Effectively, total wall clock time remains the same; but the ingestion SLA improves linearly as we add more capacity.
Given the periodic nature of batch ingestion, having 100 minion workers up and running 24/7 is not very cost effective and it’s not possible to pre-plan the capacity upfront. This is where StarTree Cloud’s Minion Autoscaling feature brings in a lot of value for the customers.
StarTree Minion Autoscaling in action
Minion Autoscaling helps optimize infrastructure cost by ensuring that no minion workers are running during the idle times.
The Minion Autoscaler operates within a pre-configured autoscaling boundary of minimum and maximum number of workers. It provisions a desired number of minion workers to ensure that sub-tasks are processed in parallel and ingestion SLAs are met.
- Scenario #1: If the total number of sub-tasks generated by FileIngestionTask (say x) is less than the max autoscaling boundary (say y), the autoscaler will provision only that many (x) workers. In this scenario, all subtasks will run in parallel.
- Scenario #2: If the total number of sub-tasks generated by FileIngestionTask (say x) are greater than the max autoscaling boundary (say y), the autoscaler will provision max (y) workers. In this scenario, the subtasks will run in batches of y.
Let’s take a look at a real customer example that illustrates StarTree’s Minion Autoscaling feature in action.
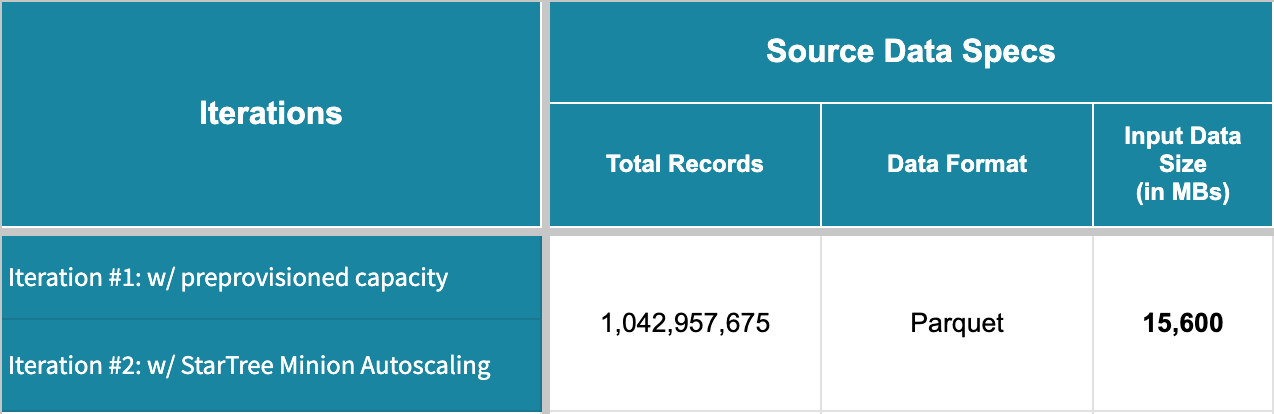
The dataset has ~1B records across a number of parquet files with a total data size of 15.6G.
The FileIngestionTask config is as follows:
"FileIngestionTask": {
…
"desiredSegmentSize": "500m",
"taskMaxDataSize": "400m",
…
}
Code language: JavaScript (javascript)With task max data size of 400m, the FileIngestionTask ended up generating 39 sub-tasks.

In iteration #1, we had pre-provisioned capacity. With that, all 39 sub-tasks ran in parallel with minimal waiting time on the tasks queue.
- Average sub-task duration = 7.58 minutes
- Max sub-task duration (slowest running sub-task) = 8.62 minutes
- Total task duration = 8.62 minutes
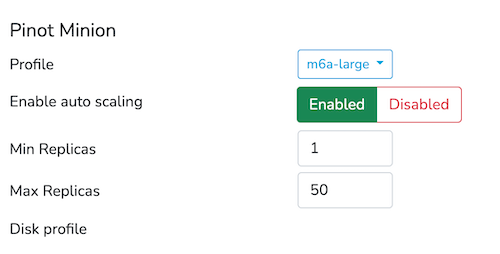
In iteration #2, we leveraged StarTree’s Minion Autoscaling with Min, Max boundaries of 1 and 50 respectively.
- Average sub-task duration = 7.58 minutes
- Max sub-task duration (slowest running sub-task) = 8.62 minutes
- Total task duration = 15.27 minutes
- Note the delay of ~5 minutes in total task duration. This is due to the fact that we did NOT have any pre-provisioned capacity.
A deeper look at Minion Autoscaling
Let’s take a closer look at how it all unfolded in this example.
Every StarTree Cloud deployment comes with Grafana dashboards for all Pinot components. The Grafana dashboard below shows the CPU utilization on Pinot minions. Each line in the graph belongs to an individual minion worker.
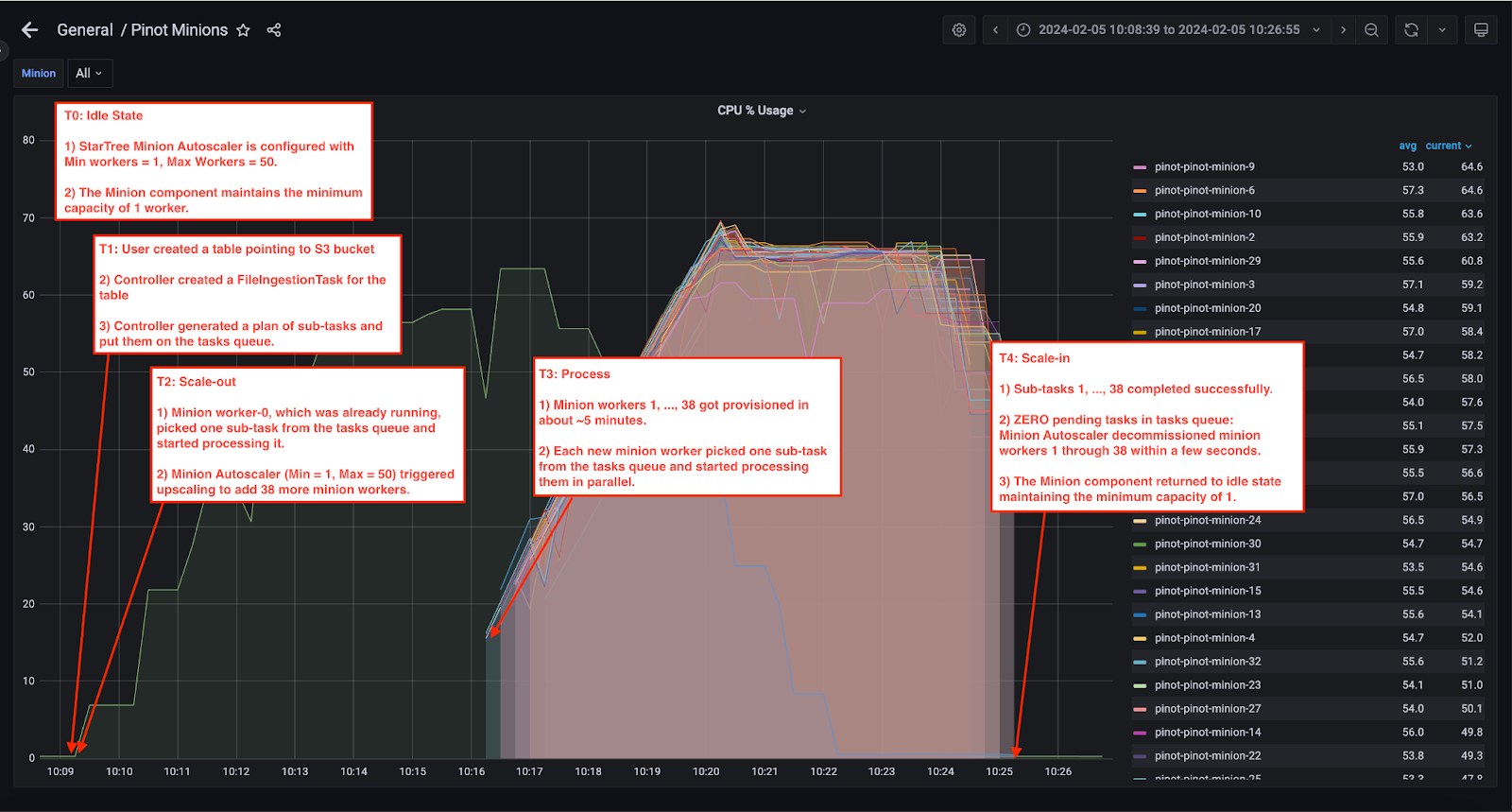
T0: Ingestion job arrives
Minion Autoscaling is enabled in StarTree Cloud and configured with the following configuration:
- Minimum workers = 1
- Maximum workers = 50
T1: User creates a Pinot Table pointing to an S3 bucket
- Controller created a FileIngestionTask for the table
- Controller generated a plan of sub-tasks and put them on the tasks queue.
- In our case, we had a total of 15.6GB of data to be ingested. We had configured Max Data Size as 400 MB which ended up generating 15.6 GB / 400 MB = 39 minion sub-tasks.
- 39 sub-tasks were generated and put on the tasks queue.
T2: Scale-out
- Minion Worker-0, which was already running, picked one sub-task from the tasks queue and started processing it. The remaining 38 sub-tasks stayed on the task queue waiting to be picked.
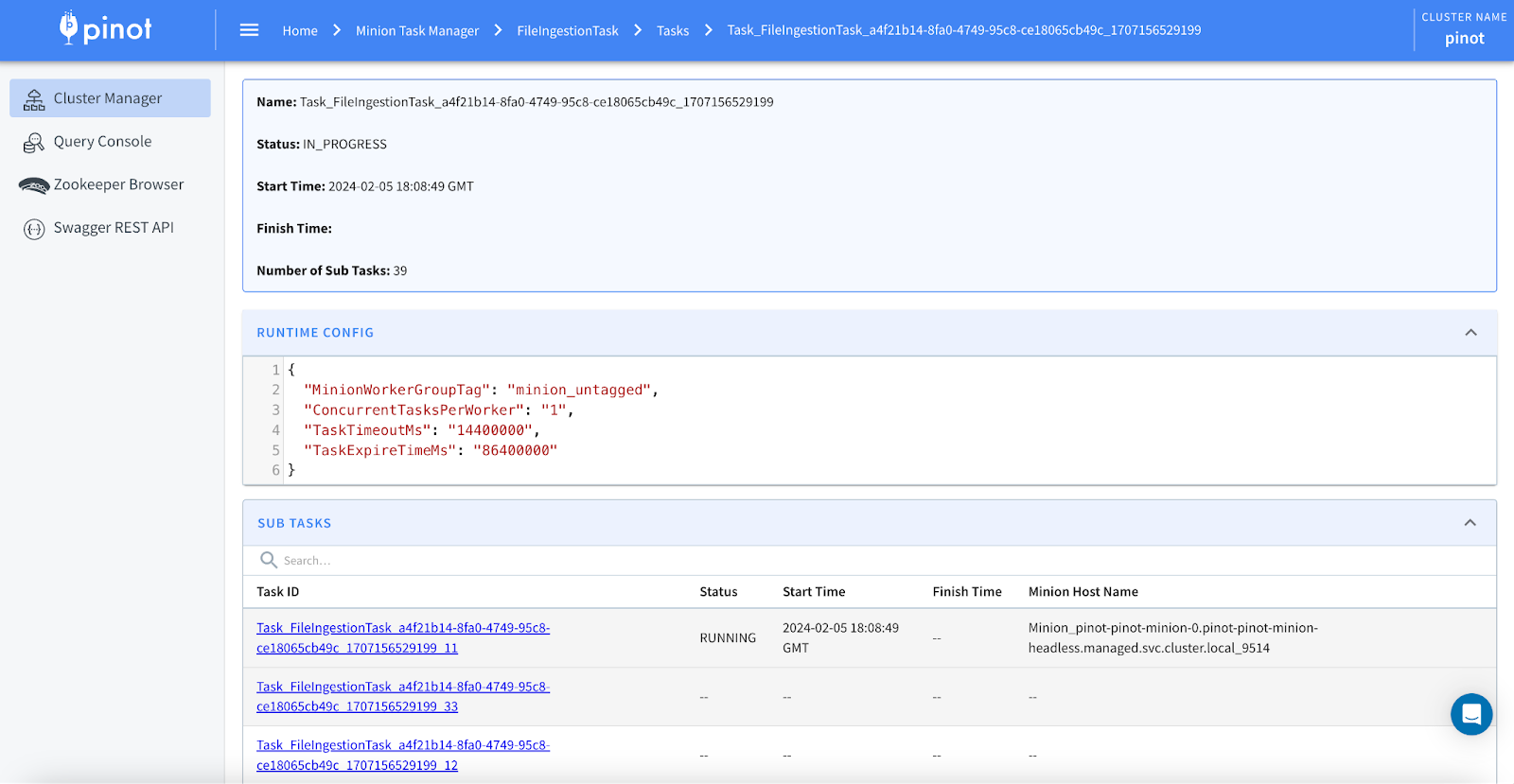
- Minion Autoscaler (Min = 1, Max = 50) triggered upscaling to add 38 more minion workers. The screenshot below shows the EKS adding minion-1 through minion-38 pods.
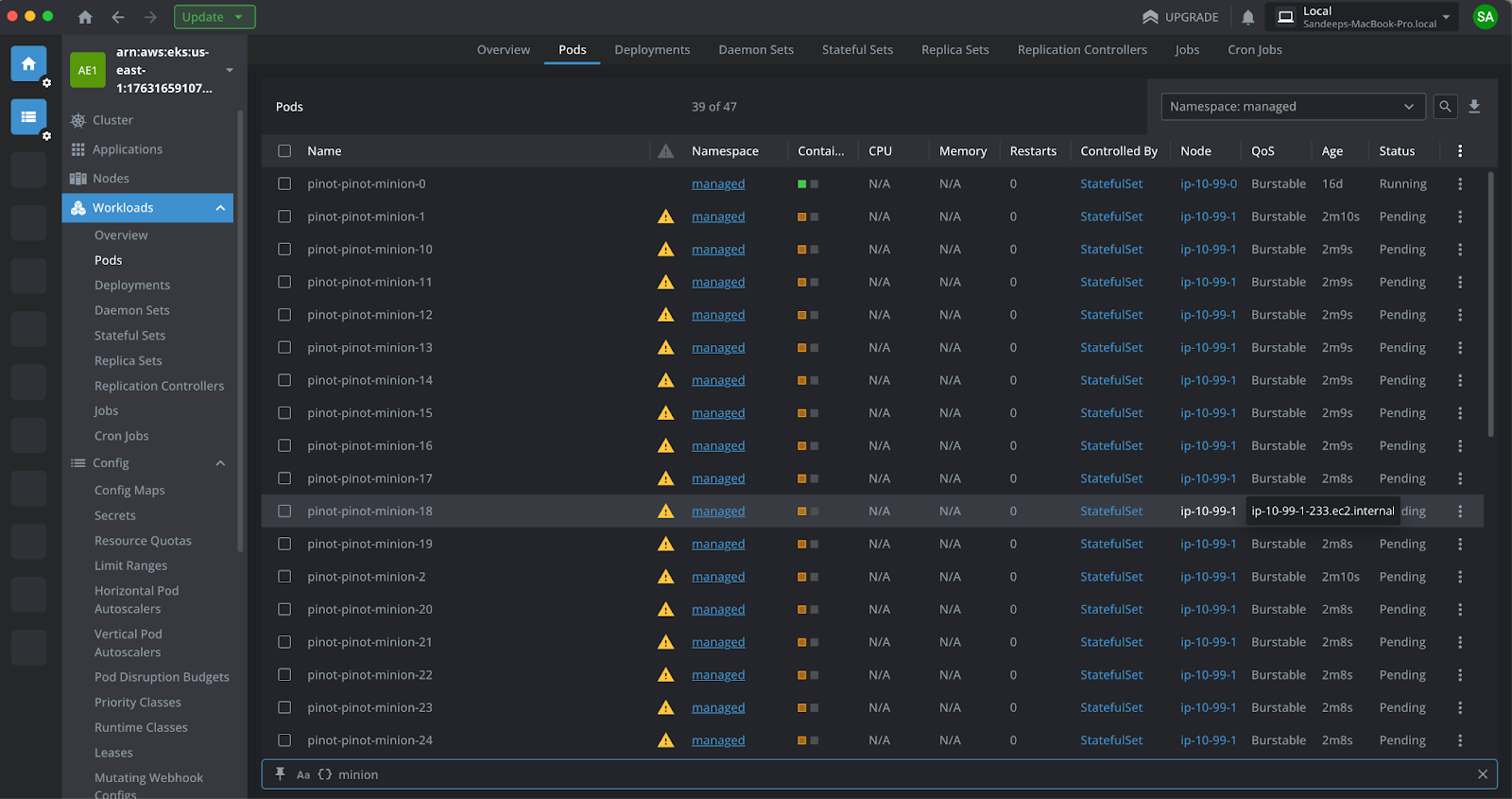
T3: Process
- 38 additional Minion Workers got provisioned in about ~5 minutes.
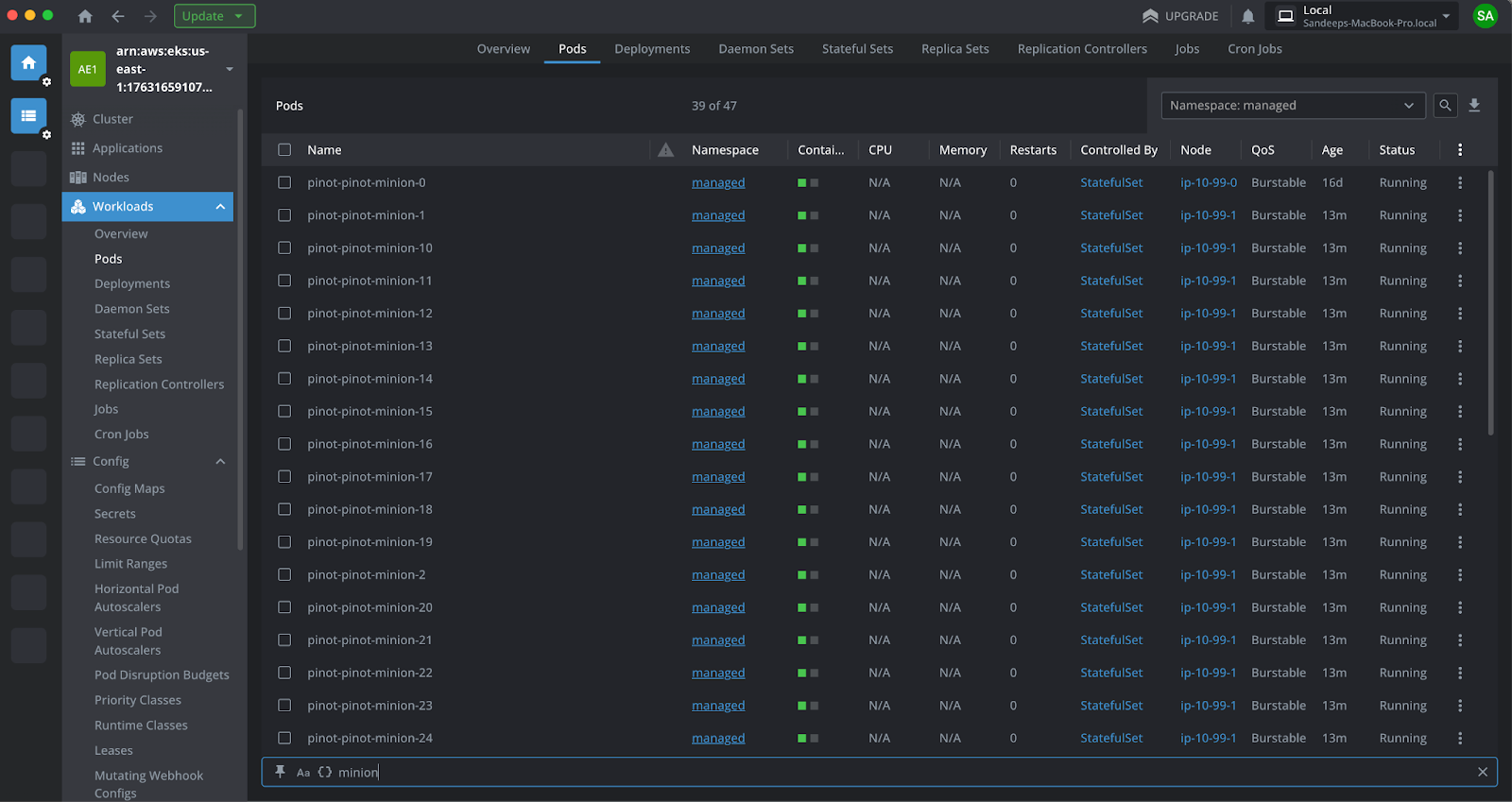
- Each new minion worker picked one sub-task from the tasks queue and started processing them. Pinot Cluster Manager UI shows the sub-tasks 1 through 38 moving to RUNNING state.

T4: Scale-in
- All subtasks completed successfully.
- Noticing that there were ZERO pending tasks in the tasks queue, Minion Autoscaler decommissioned 38 minion workers within a few seconds.
- The minion component returned to idle state maintaining the minimum capacity of 1 minion worker.
Impact of Minion Autoscaling on TCO
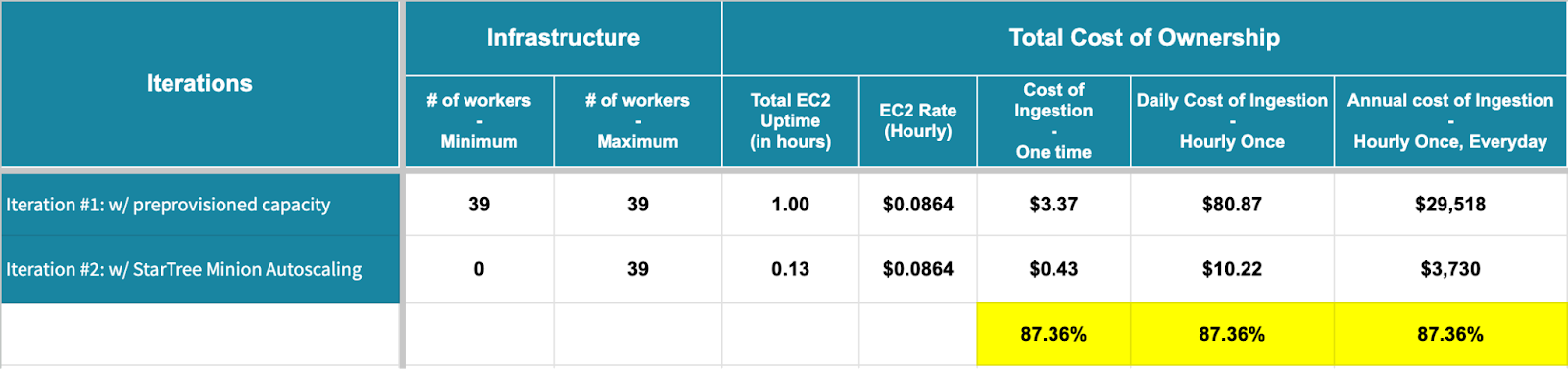
- Assuming the ingestion job runs hourly once, 365 days a week, that’s an 87.36% reduction in TCO from $29,518 to $3,730!
- All this, with a minor performance penalty which is generally flat (~5 minutes).
Key takeaways
StarTree’s Minion File Ingestion Task offers:
- Stack simplification: Brings batch ingestion in-house in your Apache Pinot architecture.
- Optimized Ingestion Speed: Provides knobs to maximize resource utilization and increase parallelism – allowing you to optimize the ingestion speed by maximizing resources.
StarTree’s Minion Autoscaling helps customers with:
- Maximizing Batch Ingestion Speed
- Optimizing TCO by eliminating unnecessary infra costs during idle times.
Learn more about how batch ingestion for Apache Pinot works in StarTree Cloud.
Want to see batch ingestion and Minion Autoscaling in action? Book a demo with our experts to learn more. You can also quickly get started with fully managed Apache Pinot using a trial of StarTree Cloud.
