
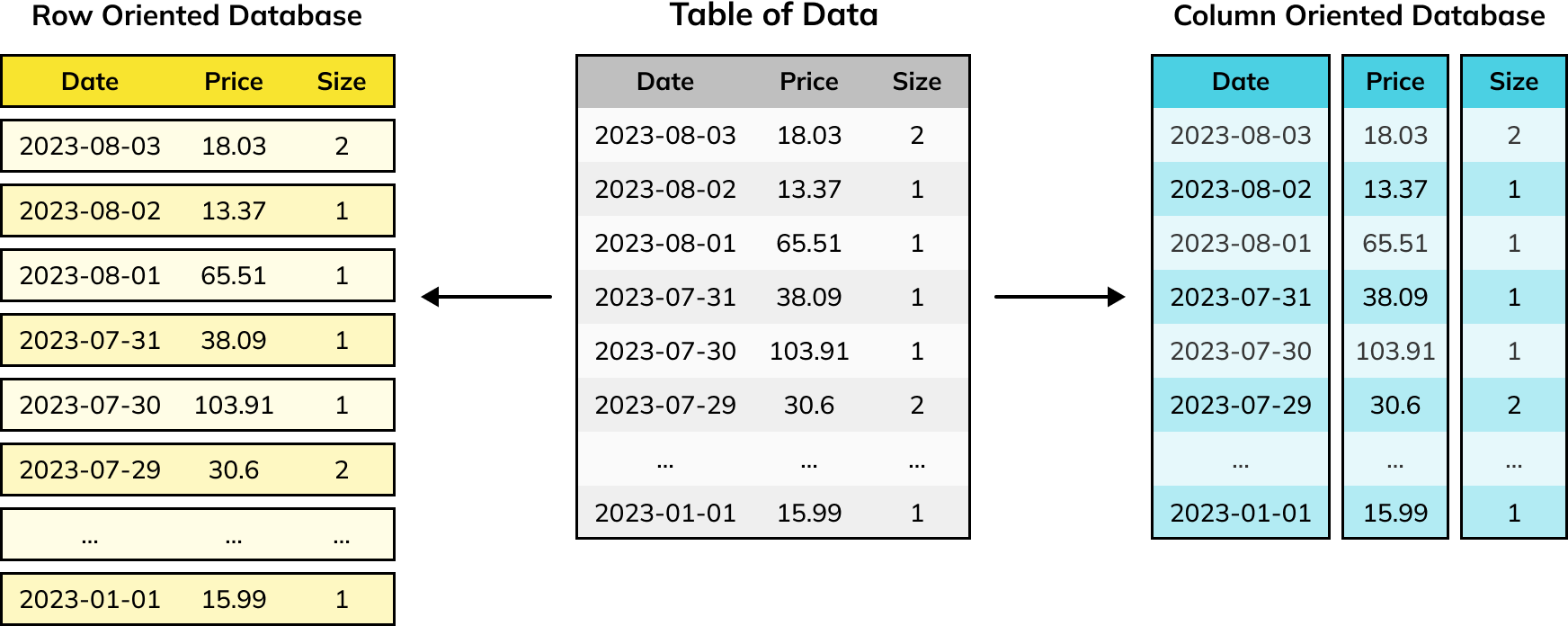
In 1972, E.F. Codd published a paper that started the relational database management systems (RDBMS) revolution. This encouraged us to think of data as tables made of rows, with each row made up of the same set of columns. The typical implementation of an RDBMS stored the data in rows on disk.
In 2005, Michael Stonebaker et al. published another paper that catalyzed the C-Store, or columnar database, revolution. The paper introduced the idea of a columnar database, which organizes storage by columns, not by rows.
Row-Oriented vs. Column Databases
This blog post aims to contrast row-based with columnar databases, including their architectures, performance, data retrieval efficiency, and suitable applications. Most importantly, we’ll explore why Apache Pinot™ is columnar and how it can deliver real-time analytics at scale.
Row-Based Databases
Row-based databases, also known as row-oriented databases, are the traditional database model prevalent in most relational database management systems (RDBMS). In this structure, data is organized and stored in rows, with each row representing a complete record or entity. The row-based approach aligns closely with the concept of a table in a relational database, where each row corresponds to a tuple.
Structure and Storage
Row-based databases store data in a row-major format, meaning that all of the bytes that represent the serialization of the row are stored contiguously in memory or on disk. This arrangement allows for efficient retrieval of complete records, making row-based databases suitable for transactional systems, whose access patterns usually prioritize a single record at a time. Transaction systems typically offer strong consistency and atomicity guarantees, which can be easier to implement with row-based storage. On the flip side, having to reassemble a row by accessing individual column values from different places would prove less efficient when that whole row is usually the object you want from the database.

How row-based database storage works
Performance Considerations
Row-based databases excel in scenarios that are more likely to read and write entire rows since their design serializes each row as a unit. However, they do not perform as well with large-scale analytical workloads that often involve aggregations of a single column value across many rows.
Column-Based Databases
Column-based (or “columnar”) databases present an alternative approach to storing and processing data. Instead of organizing information by rows, they break rows apart into their constituent columns and store large chunks of column values contiguously on disk or in memory. This makes it much more efficient to read a single column across many rows—a common analytical access pattern—because those columns are stored sequentially. It also helps columnar databases optimize compression since column values—particularly so-called “dimensional” columns—tend to exhibit high levels of data redundancy.

How column-based (or “columnar”) database storage functions
Performance Considerations
Column databases excel in scenarios that involve frequent aggregations . Because only the relevant columns are accessed during query execution, columnar databases can significantly reduce I/O overhead , leading to improved query performance. And because large scans of sequential column values can be read in fewer I/O operations, one very common (and often performance-limiting) kind of read access is more efficient. Column-oriented databases can also employ dictionary encoding, where duplicate data is not repeated. This provides compression and efficient reads. When it comes to handling transactional workloads that involve frequent updates or inserts, they may face challenges as any modifications must propagate across all corresponding columns in separate I/O operations.
Data Retrieval Efficiency
One of the significant differences between row-based and column-based databases lies in their data retrieval efficiency. This factor largely determines which database model suits each use case.
Row-Based Data Retrieval
Row-based databases excel in scenarios where complete records or entities need retrieval, updates, or inserts. This kind of database stores data together in a row, allowing for efficient access to an entire record, including quick retrieval and modification. On the other hand, accessing specific columns within a row may require scanning the entire row, which can lead to decreased performance when dealing with large datasets or complex queries.
Column-Based Data Retrieval
Column-based databases work well in scenarios that involve aggregations, filtering, and analyzing subsets of columns . Due to the columnar storage format, these databases can selectively access only the required columns, minimizing disk I/O and improving query response time. This makes column-oriented databases ideal for data warehousing, business intelligence, and analytical workloads .
Suitable Applications
The choice between column-based and row-based databases depends on the specific requirements and use cases of an application. Below are some common scenarios specifying where each type shines.
Row-Based Database Applications
- Transactional systems : Row-based databases make sense for applications that prioritize maintaining the integrity and consistency of complete records, such as banking systems, e-commerce platforms, and content management systems, and support frequent updates and inserts.
Column-Based Database Applications
- Analytical processing : These databases excel in scenarios that involve complex analytical queries, data warehousing, OLAP, and business intelligence applications. These databases provide superior performance when dealing with large datasets, aggregations, and filtering operations.
Apache Pinot Is a Columnar Database
Pinot is a real-time distributed OLAP datastore designed to answer OLAP queries with low latency. Building Pinot as a columnar store simply added up. Pinot leverages the power of distributed computing and data to overcome some of the write inefficiencies while leveraging all the goodness of columnar storage for reading, aggregating, filtering, and analyzing.
Conclusion
Both databases present distinct approaches to organizing and managing data, each with its strengths and weaknesses. Row-based databases thrive in transactional systems, where whole rows are more frequently accessed together, whereas column-oriented databases shine in analytical workloads, offering superior performance in aggregating, filtering, and querying subsets of data. Choosing the appropriate database model depends on the specific requirements of the application, balancing factors such as data retrieval efficiency, storage requirements, and processing capabilities.
By building a distributed database as a columnar store, Pinot has a strong foundation in real-time analytics optimized for low-latency query performance. To find out more about how Pinot achieves its amazing performance, join the community Slack channel and check out the quick start.
