
Introduction
The last few years have seen the rise of Apache Pinot™ – 1an open-source, distributed OLAP store which is powering latency-sensitive analytical applications across a broad range of industry segments. Initially adopted by LinkedIn and Uber, Pinot is now relied upon by the heavyweights of Fin-Tech (Stripe, WePay, RazorPay), Logistics (Walmart, 7-11, Target, Doordash), Communication (Cisco, Slack), and other industry segments. Its ability to support extremely high throughput analytical queries within milliseconds for both mutable and immutable data is what makes it a perfect fit for a wide range of applications as discussed in the previous blog: ‘How To Pick A Real-Time OLAP Platform’
At StarTree, our goal is to build a cloud-native platform around Apache Pinot to make it easily accessible and secure for companies of all sizes. In this blog, we will look at one particular aspect of Pinot which was drastically improved within StarTree Cloud: Data Ingestion.
Apache Pinot Current Data Ingestion Experience
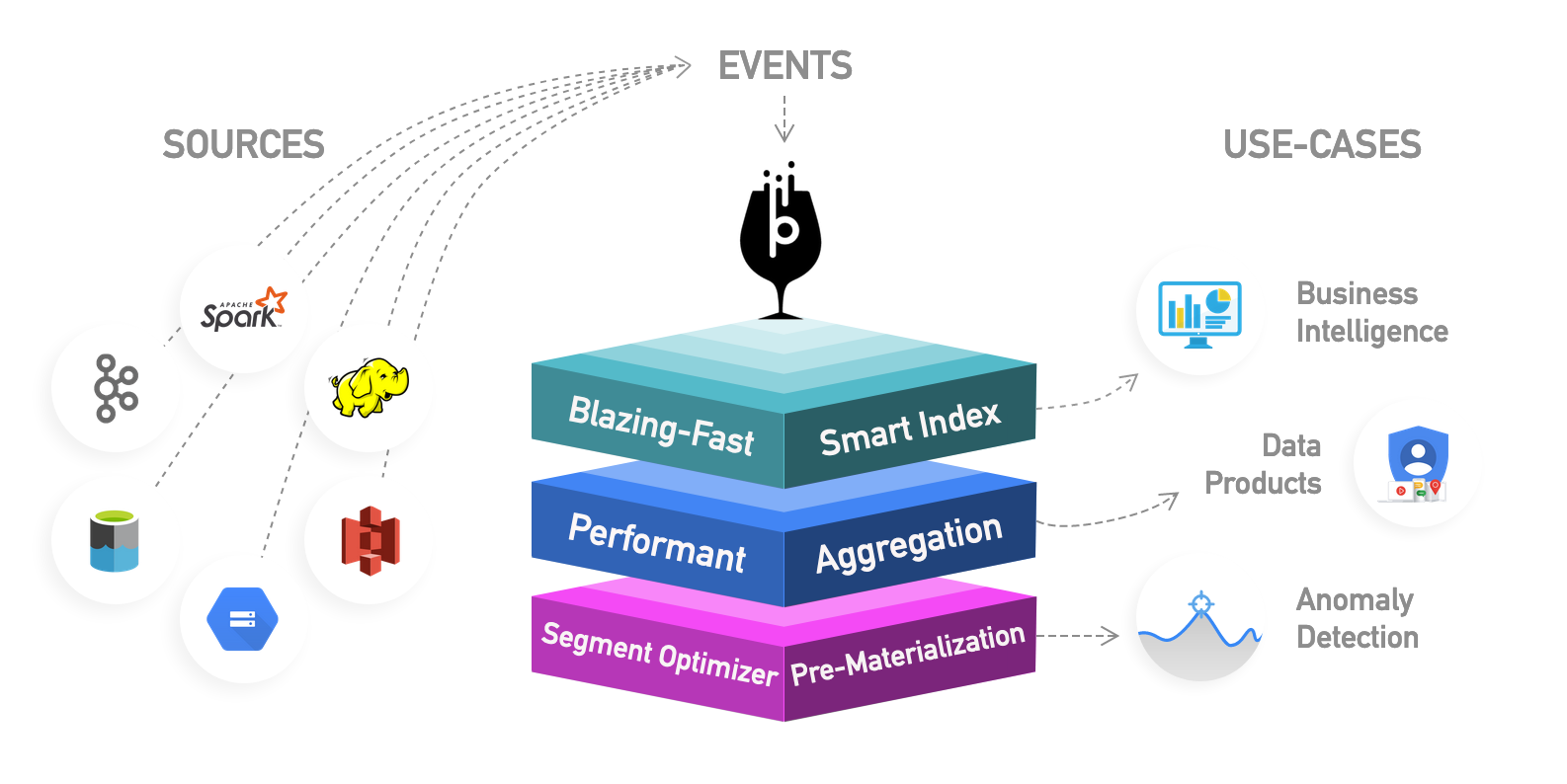
Apache Pinot supports data ingestion from a wide variety of sources such as streaming (eg: Kafka, Pulsar, RedPanda, Kinesis), batch (eg: S3, GCS, HDFS) as well as SQL sources. Users can create a new Pinot table and configure the corresponding ingestion mechanism in a declarative manner using the Pinot Table Config. For example, here’s a sample Pinot config and schema for ingesting from a Kafka topic:

Fig: Sample Real-Time Pinot Table config

Fig: Sample Pinot schema
Although flexible, this has a certain set of challenges today:
- Learning curve: Users need to understand the table config syntax which can get very tedious for new users. Not only do users need to understand different attributes of ingestion config, but they also need to know about additional settings such as data partitioning, column indexes, retention, quotas, and so on.
- Lack of tooling: At the moment there’s no convenient tool to construct and validate the Pinot table config and schema on the fly.
- Data Modeling complexity: There are many scenarios where users need to pre-process the input data (eg: flatten) or add derived columns or filter out a certain set of rows. In addition to being complex, there is no way to validate the data model until after the table is already created.
- Manual overhead: When dealing with 100s of dimensions, creating a schema manually can get quite tedious.
Introducing StarTree Data Manager
StarTree Data Manager is a no-code, self-service tool that helps users of all caliber to quickly get started with Pinot. It provides a convenient wizard to walk users through the different table creation steps including advanced settings. It also makes it very easy to iterate on the data model before creating anything within the Pinot cluster. With Data Manager, StarTree users can go from registration to first query within a matter of minutes. The rest of the blog will go through the different features of Data Manager.
“Data Manager helped us auto-discover the schema and has a simple web flow which cut our onboarding time for a new table from more than an hour to under 10 minutes” – Rahul Jain, Engineering @ Cisco
StarTree Data Manager Features
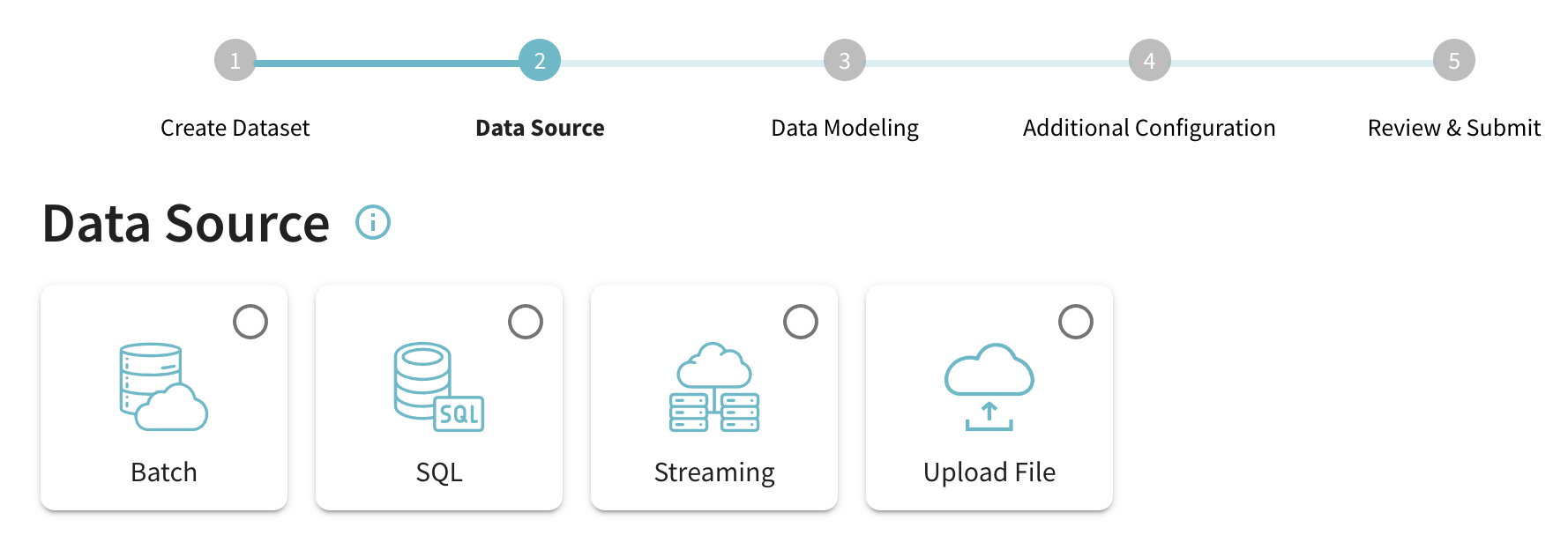
Data Sources
Fig: Data Source Selection step
Currently, Data Manager supports the following categories of data sources
- Streaming: Ingest events from real-time streaming sources such as Apache Kafka and Amazon Kinesis
- Batch: Fetch batch/offline data from sources such as Amazon S3, Google GCS and so on.
- SQL: Fetch batch data from SQL sources such as MySQL, PostGres, Snowflake, Google BigQuery.
- File upload: Upload a file to StarTree cloud which is then ingested into a Pinot table
For each such source, users enter connection information (eg: Kafka broker URL) as well as other things such as authentication and schema registry which are instantly validated. Users can either create a new data source or choose from one of the existing sources created earlier.
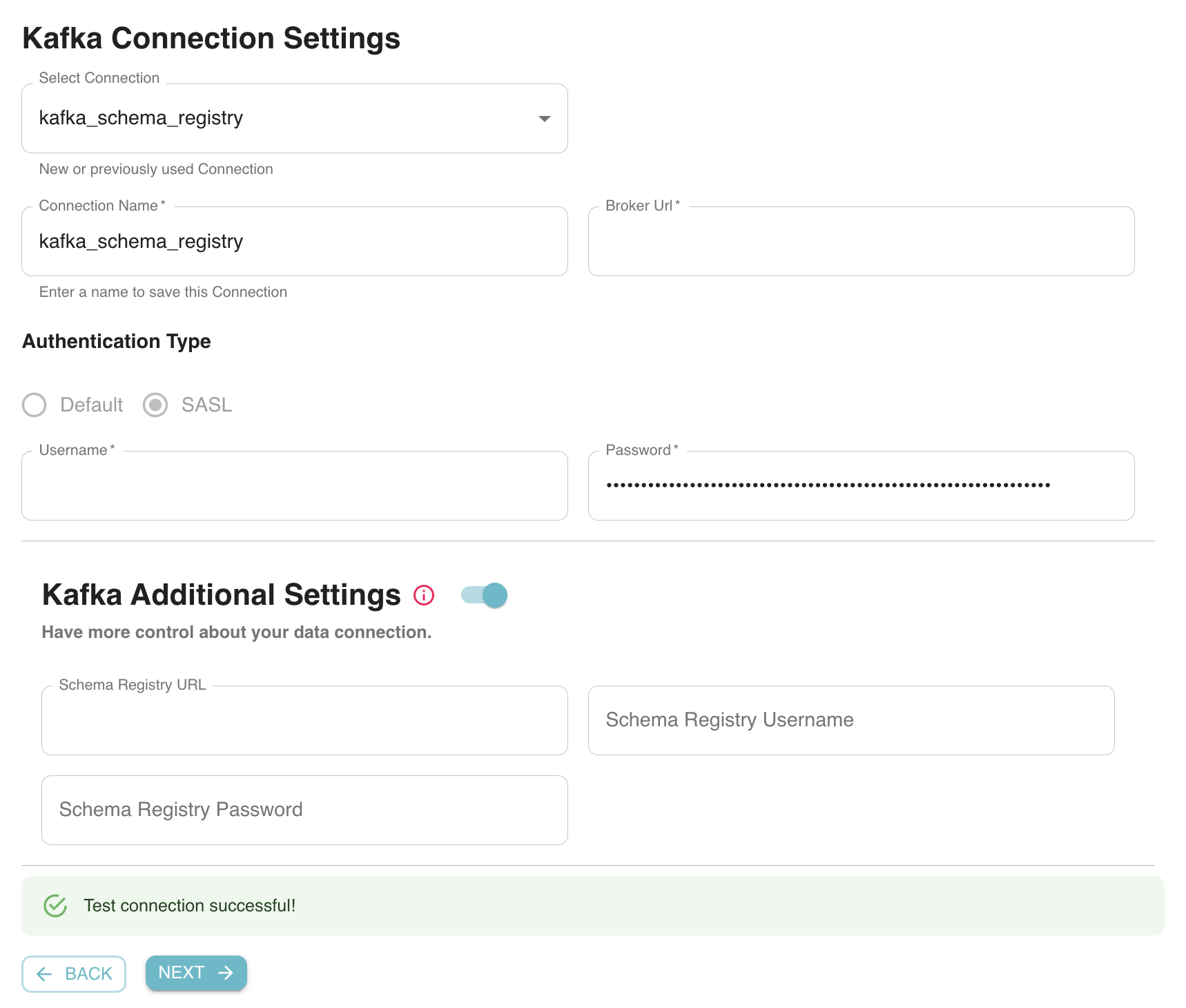
Fig: Configuring Apache Kafka as the data source for a new Pinot Dataset
In addition, Data Manager also allows new users to create a Pinot table with a sample dataset included in StarTree cloud. This is the fastest way to get started with Pinot without having to worry about data modeling or any advanced settings.
Data Modeling
This is one of the most complex steps in the Pinot table creation process. Users need to come up with a Pinot schema based on the source schema. The different steps involved are as follows:
1. Dataset and format selection
Once a data source is created, users can select the specific dataset that needs to be ingested into Pinot. This could be a Kafka topic or a directory within an S3 bucket. In addition, users also need to specify the source data format. At the moment, Data Manager includes support for Avro, Json, CSV, and Parquet formats.
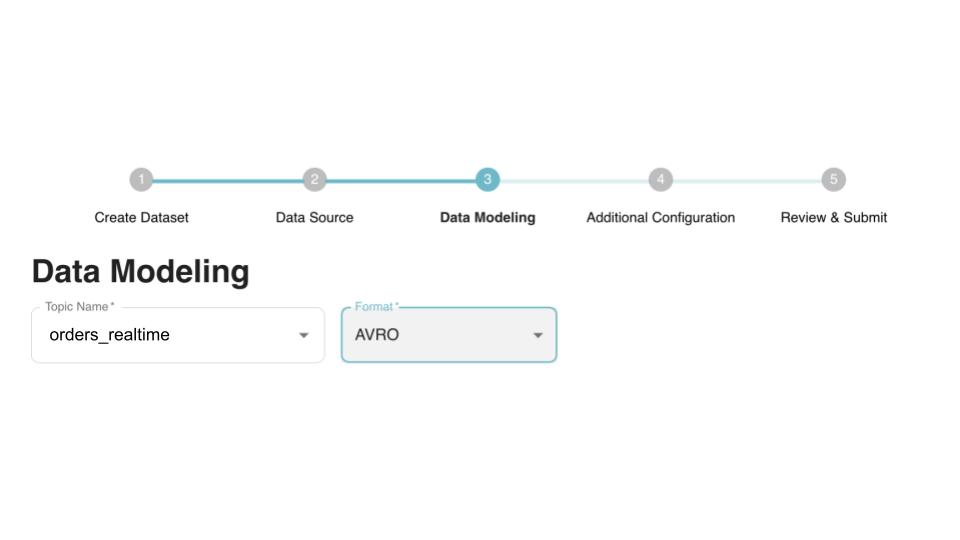
Fig: Real-Time table ingestion: Select source dataset and format
2. Schema inference
Next, Data Manager infers the Pinot schema based on the source dataset and format. In the case of JSON source data, it fetches some sample messages from the source and tries to infer a Pinot schema based on the payload structure. In the case of Avro, it fetches the source schema (either from the Schema registry or Parquet file) which is then converted into a Pinot schema.
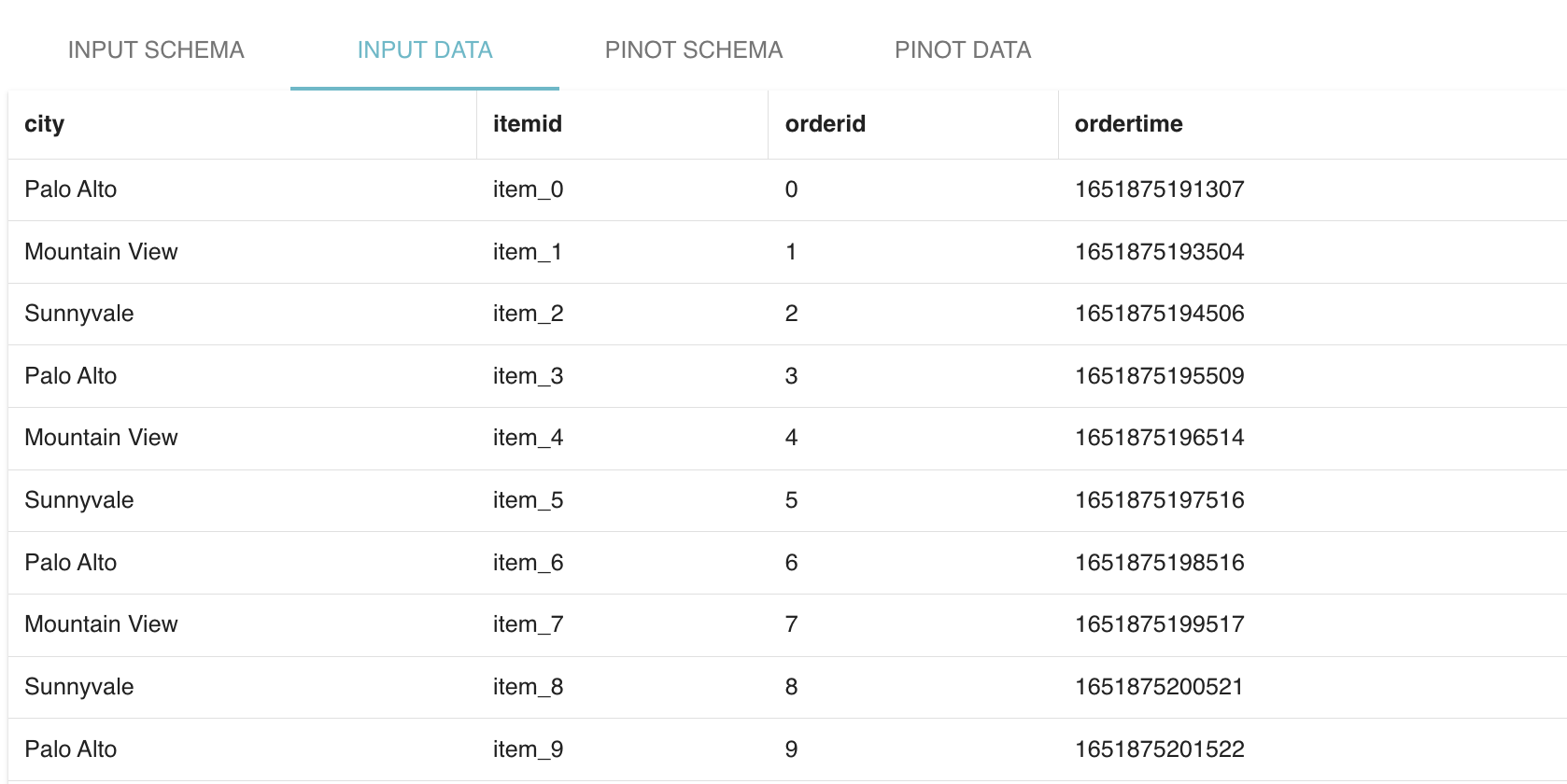
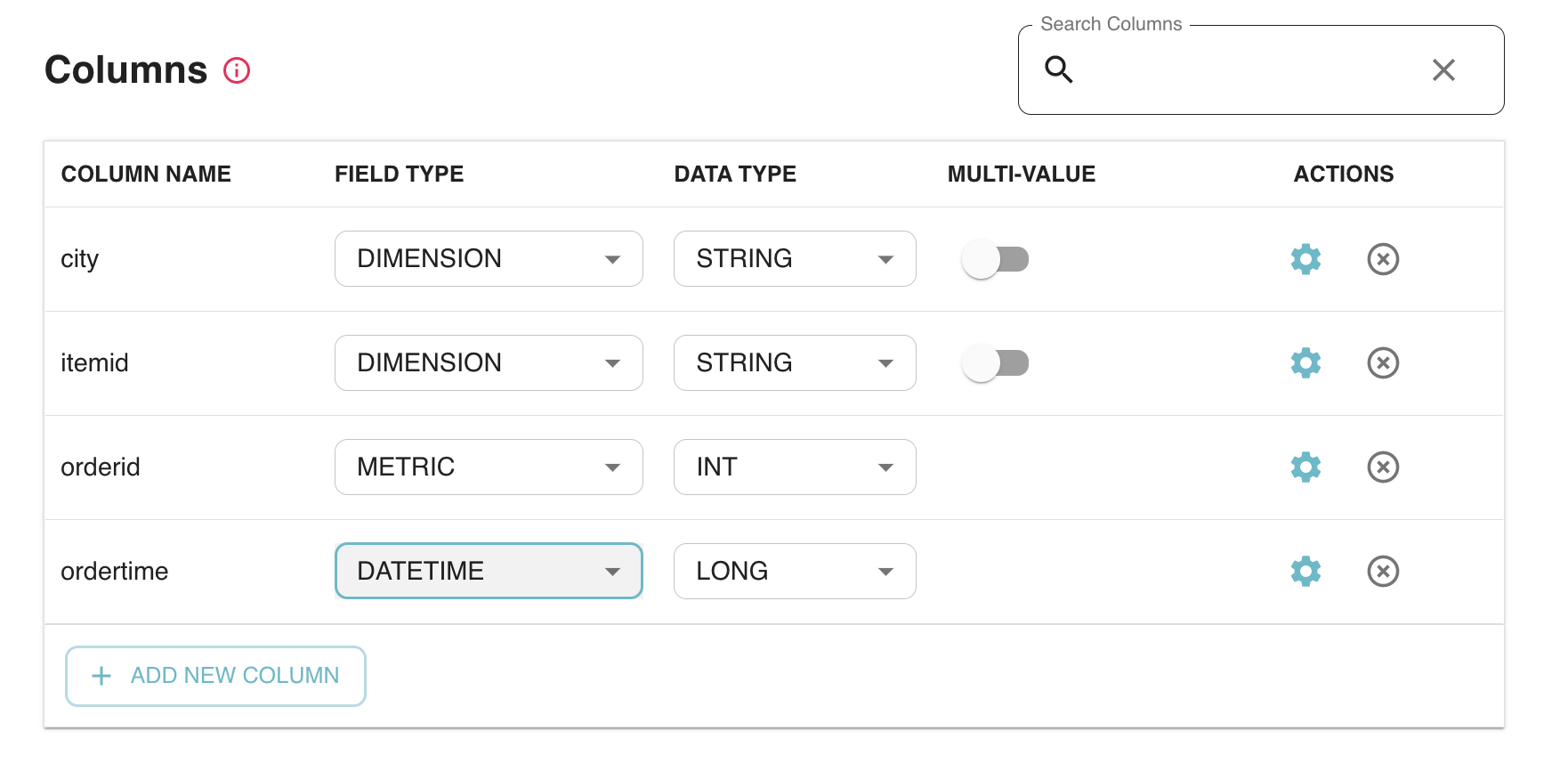
Fig: Raw input data and the corresponding auto-Inferred Pinot schema
“Data Manager makes ingesting data into Apache Pinot really easy. Automatic schema detection and instant configuration validation is saving us a lot of time” – Leon Graveland, Senior Data Engineer, Just Eat Takeaway.
3. Customizations
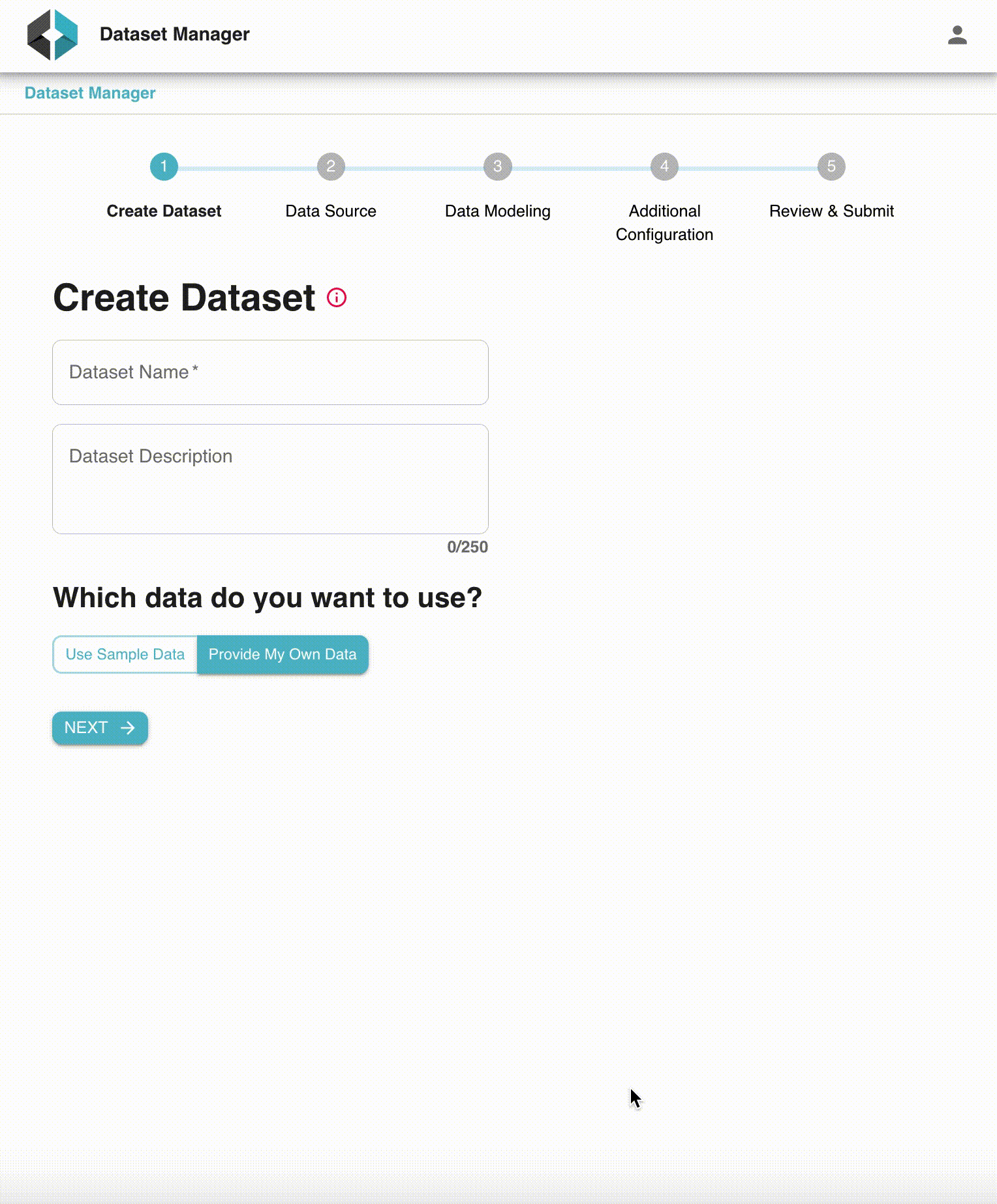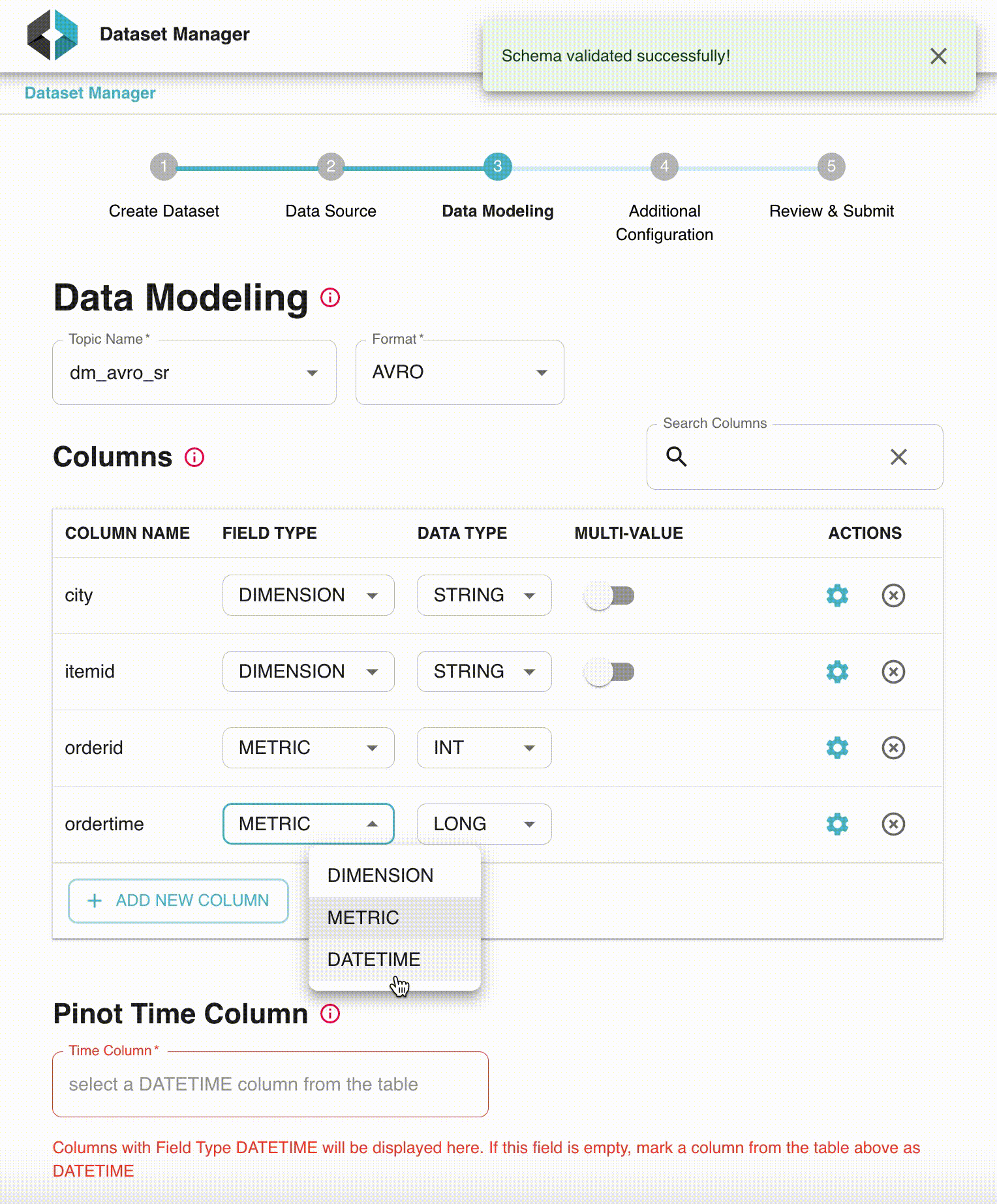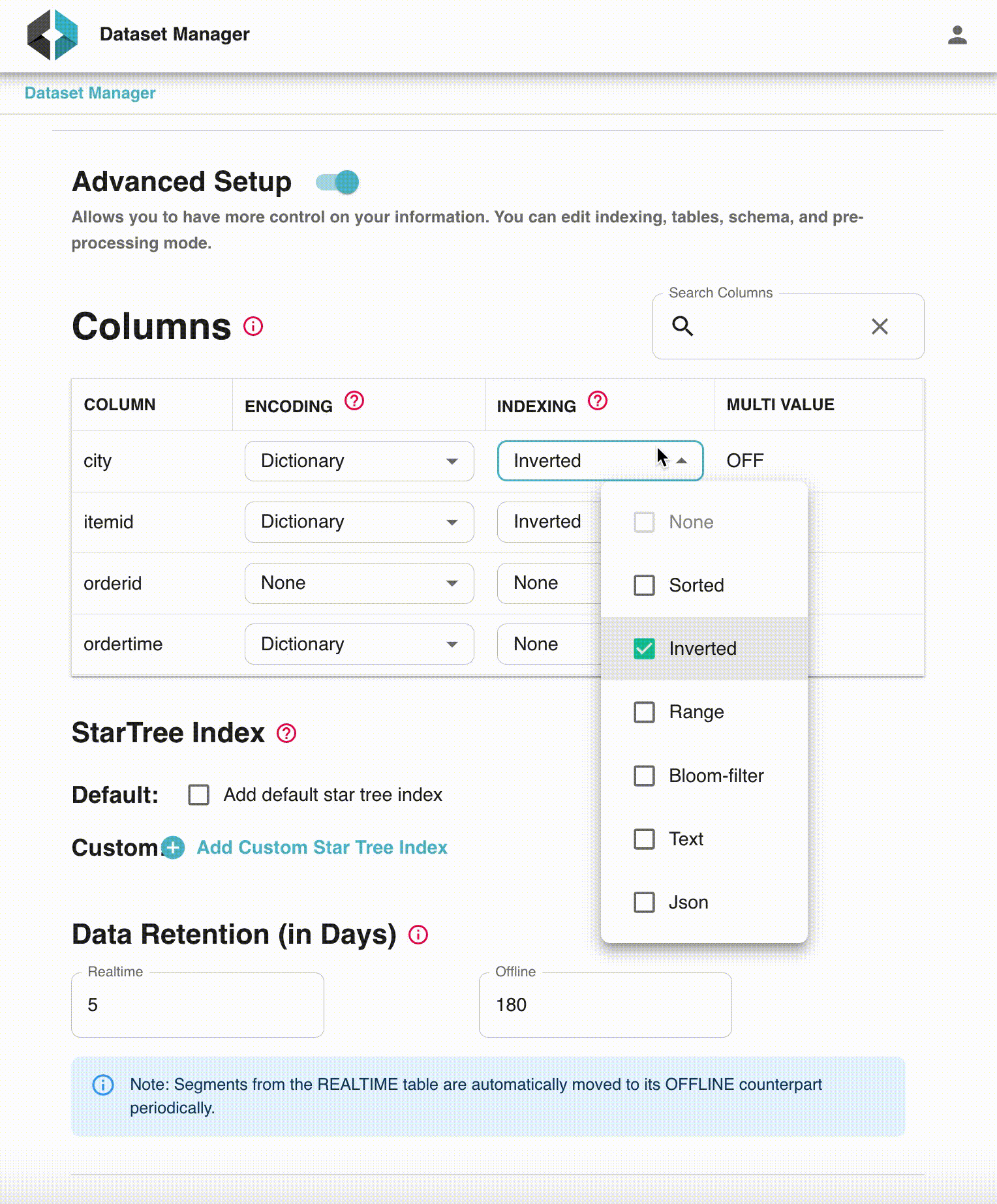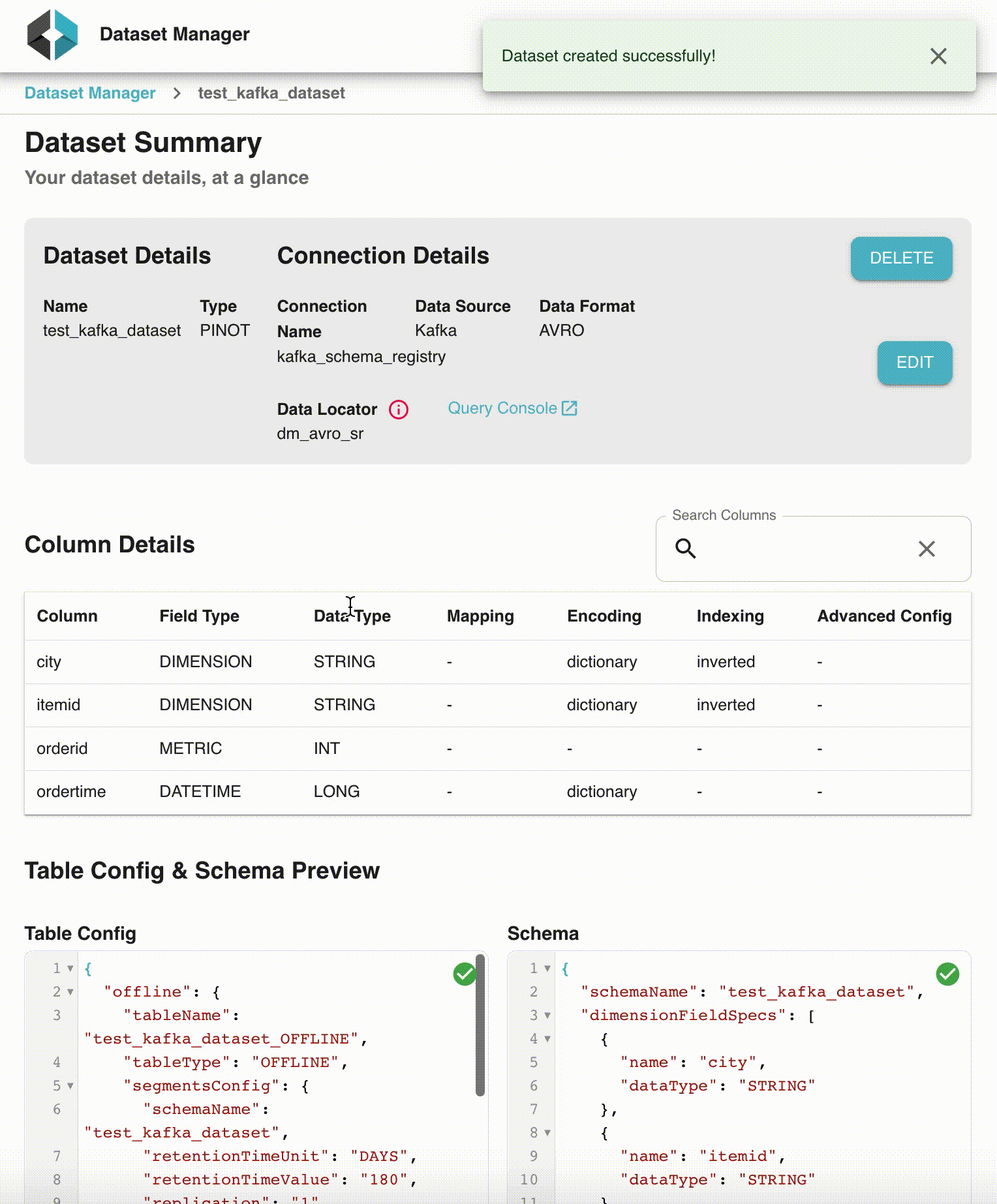
In this step, users can further customize the inferred Pinot schema. This includes:
- Drop certain unwanted columns
- Specify a column as being metric/dimension or date-time column
- Change inferred type of a column.
- Derived column: users can add a new column to the Pinot schema by transforming any of the existing columns. Here’s an example of how to add a new column called ‘date’ by converting an existing column – ‘ordertime’ using a date time conversion function.

Fig: Adding a Derived column on the fly in Data Manager
- Primary key for upserts: In the case of real-time data sources like Kafka, users can select an optional primary key in order to enable upserts. Once enabled, new incoming records with a given primary key will upsert any old records with the same primary key.
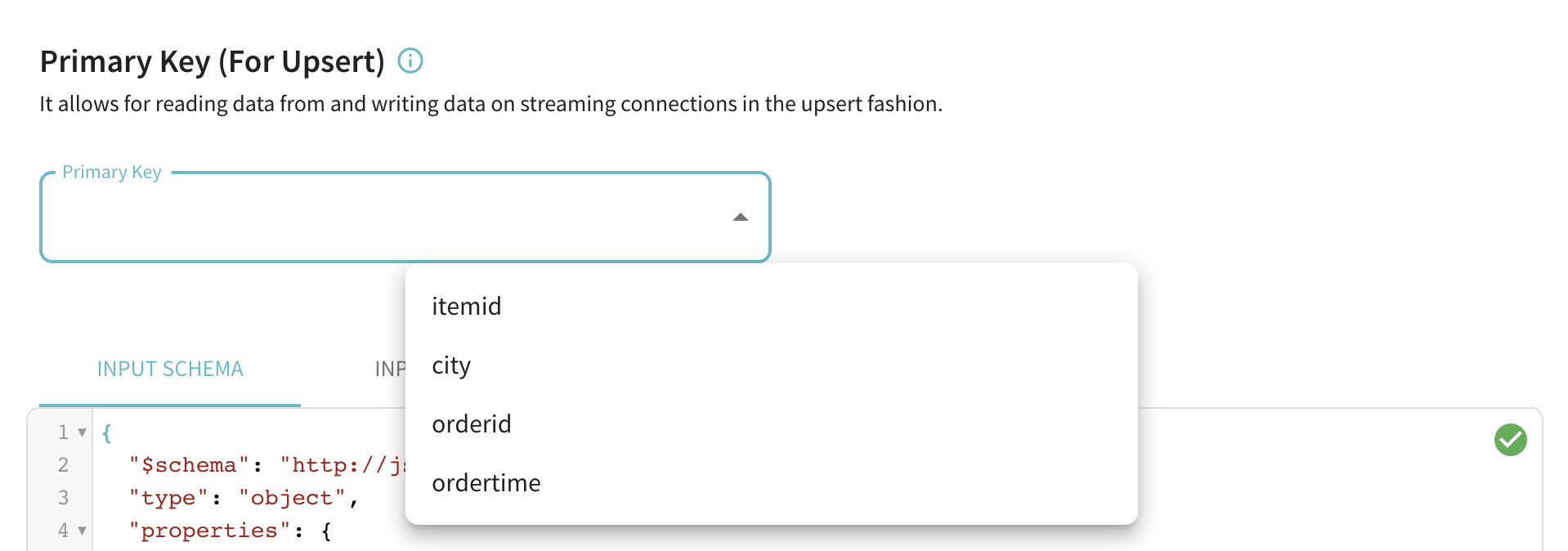
Fig: Select Primary key column for enabling upserts in real-time datasets
4. Data Preview
Data Manager shows a preview of the Pinot data generated from the source dataset which enables users to get a feel of how the final table will look like. This includes any derived columns added by the users which are dynamically updated on the fly based on the corresponding source column values.
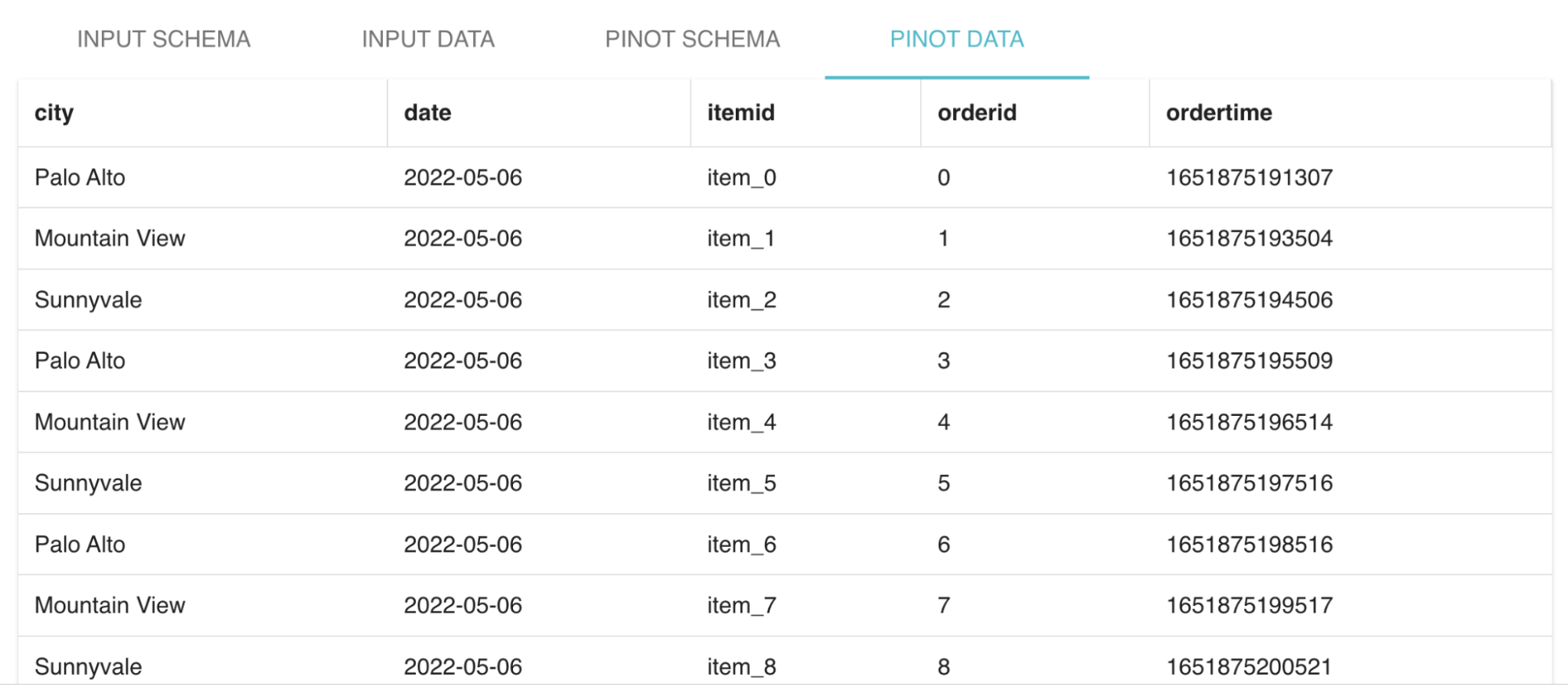
Fig: Preview of the resulting Pinot table data
Advanced settings
This section is meant for advanced Pinot users and is completely optional for most of the common use cases. Here are the different advanced settings that users can play around with:
Index Tuning
Data Manager automatically generates certain indexes based on the Pinot schema and data characteristics which are done transparently to the user. However, sophisticated users may choose to tune certain column indexes or add new indexes such as StarTree (which enables users to generate highly optimized materialized views). This is all done using a convenient click-through UI which makes it very easy to use.
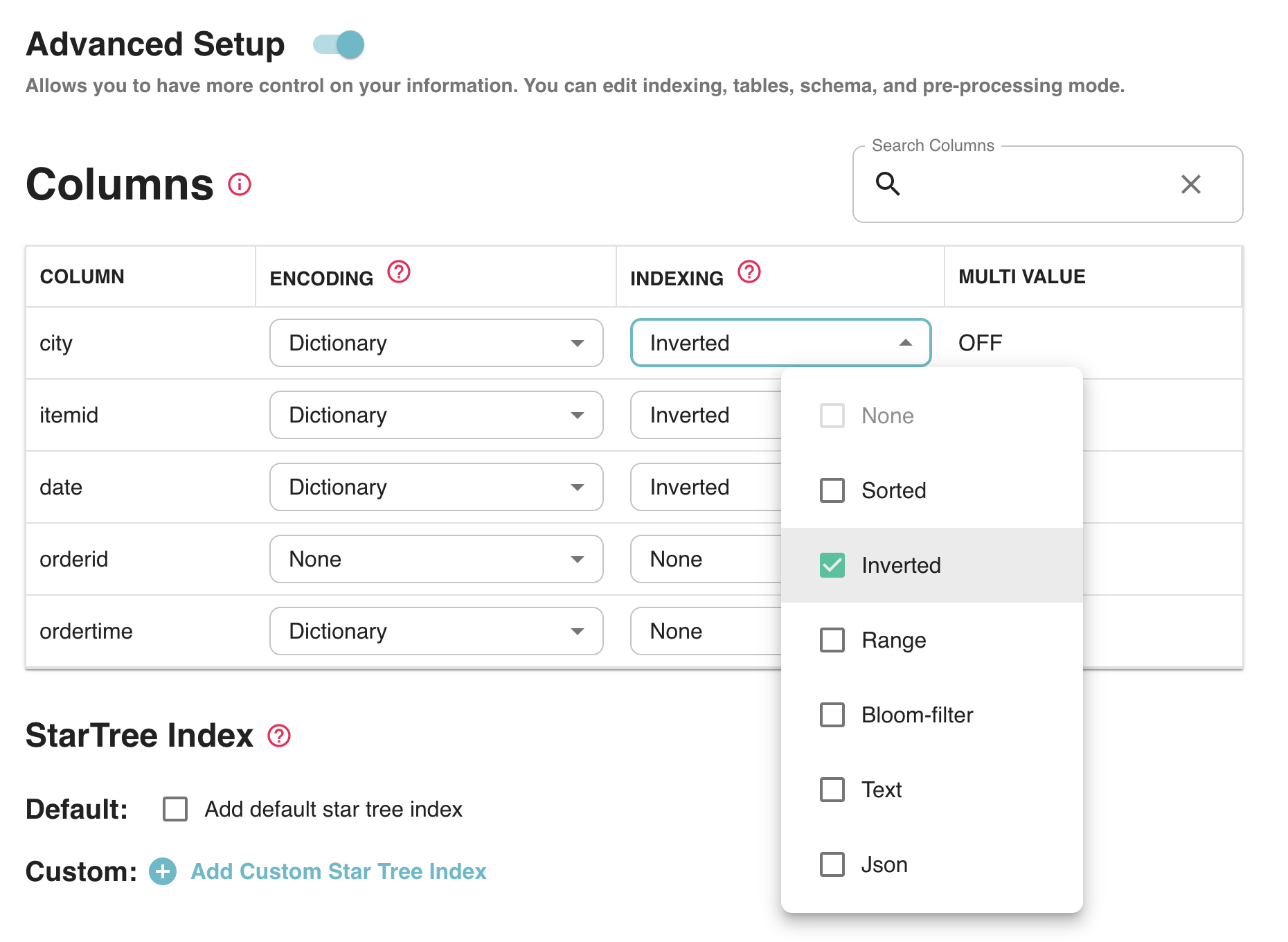
Fig: Index tuning for advanced users
You can also add a custom StarTree index very easily as shown below for accelerating aggregation SUM queries on delivery_fee for predicates on the dimensions listed below.
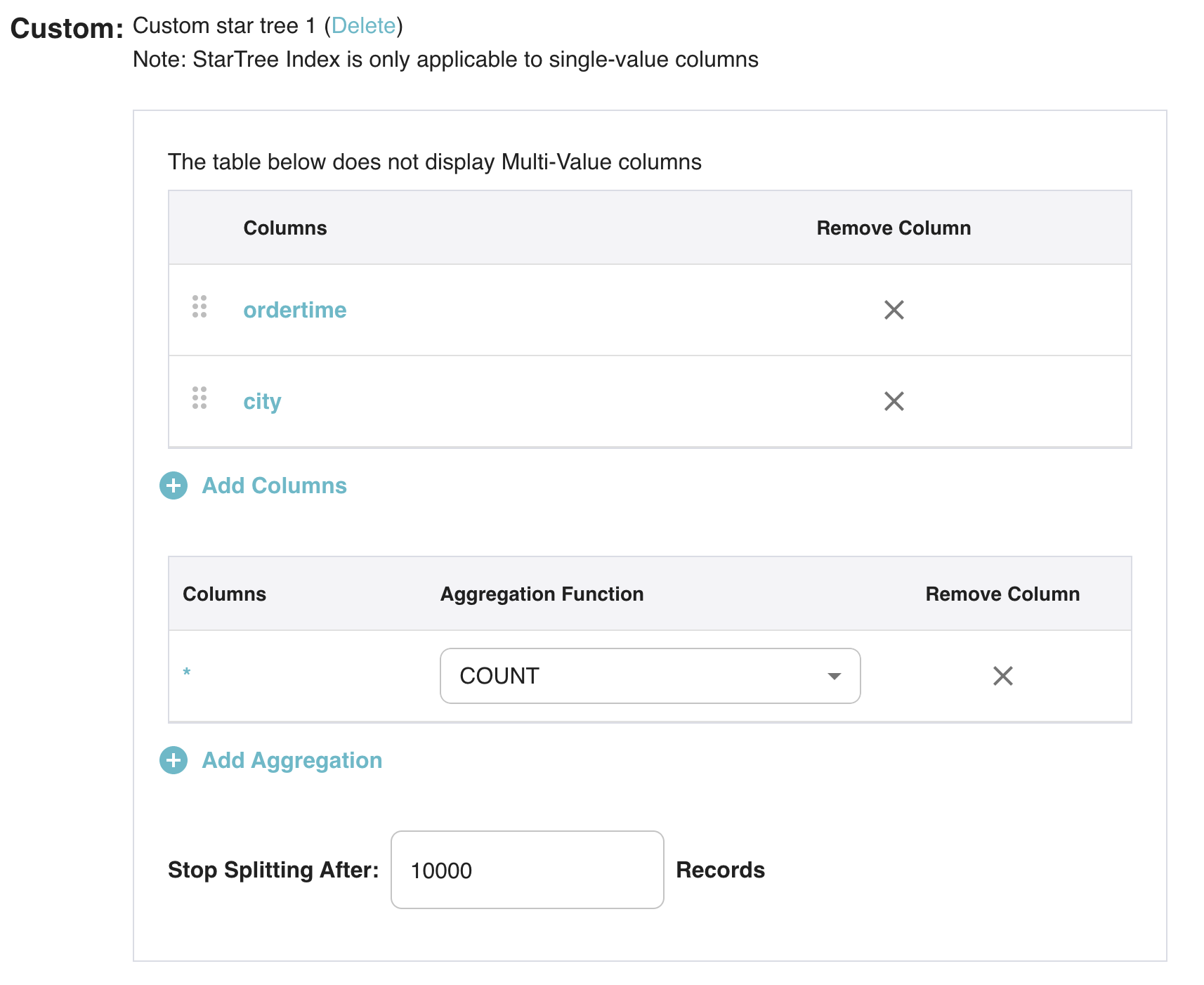
Fig: Adding custom StarTree index via Data Manager
Retention
By default, Data Manager uses retention of 180 days which is applied to all generated tables (historical data for real-time tables is automatically moved to offline tables). Users can choose to customize this value in order to influence the storage footprint of the resulting Pinot table.
Table Config and Schema
Advanced users can directly edit the Pinot table config and schema. This enables users to continue to use new Pinot features that are currently not supported in the UI flow. For any changes made by the user, Data Manager will automatically validate the resulting table config and schema (both syntactic and semantic checks).
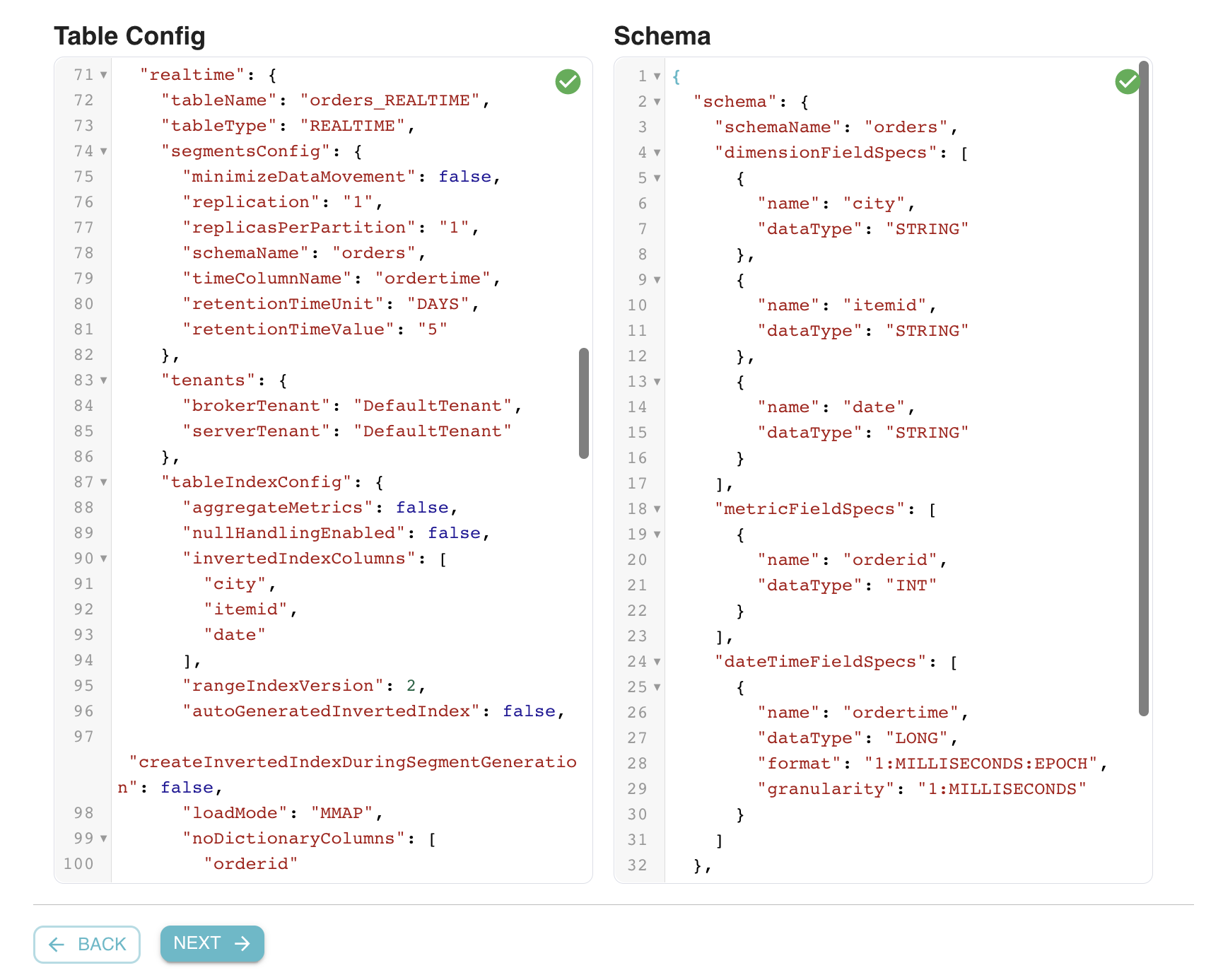
Fig: Edit Table Config and Schema for advanced users
Try it out!
Data Manager is available within StarTree Cloud. If you want to sign up for a free trial and start playing around with Data Manager yourself, please visit https://get.startree.ai/startree-cloud.
“Data Manager makes onboarding new datasets to pinot a breeze by automating schema inference and index creation.” – Santhi Kollipara, Engineering Manager, Pluto TV As mentioned in this blog, Data Manager provides:
- Self Serve Wizard: for creating Pinot tables ingesting from a variety of sources
- Data Modeling: allowing users to iterate on the schema and preview the Pinot table
- Validation: All the customizations are instantly validated before creating Pinot table
- Advanced Mode: for sophisticated Pinot users.
We continue to improve this tool and we plan on adding the following things in the near future:
- Advanced feature customizations like Cloud tiered storage, data rollups, de-duplication
- More data sources: PubSub, MySQL, PostGres
- Better dataset visibility: show health and progress of offline ingestion jobs
We’d love to hear from you
Here are some ways to get in touch with us!
You can get in touch with StarTree by contacting us through our website. We encourage you to Book a Demo or contact us for a free trial.
New to Apache Pinot? Here are some great resources to help you get started. You can find our documentation here, join our community Slack channel, or engage with us on Twitter at StarTree and ApachePinot.
