
This is the second blog post in the Getting Started with Apache Pinot series. In the first post , we learned about Pinot’s storage model, the components in a cluster, and then loaded a CSV file into an offline table, before querying the data.
In this post, we will learn about real time tables, which support the import and querying of data from streaming systems like Apache Kafka.
We’re going to write a Node.js script that queries an HTTP endpoint of Wikipedia events, put those events onto a Kafka topic, ingest the events into Pinot, and run a SQL query to explore the data. A diagram showing the data flow is shown below:
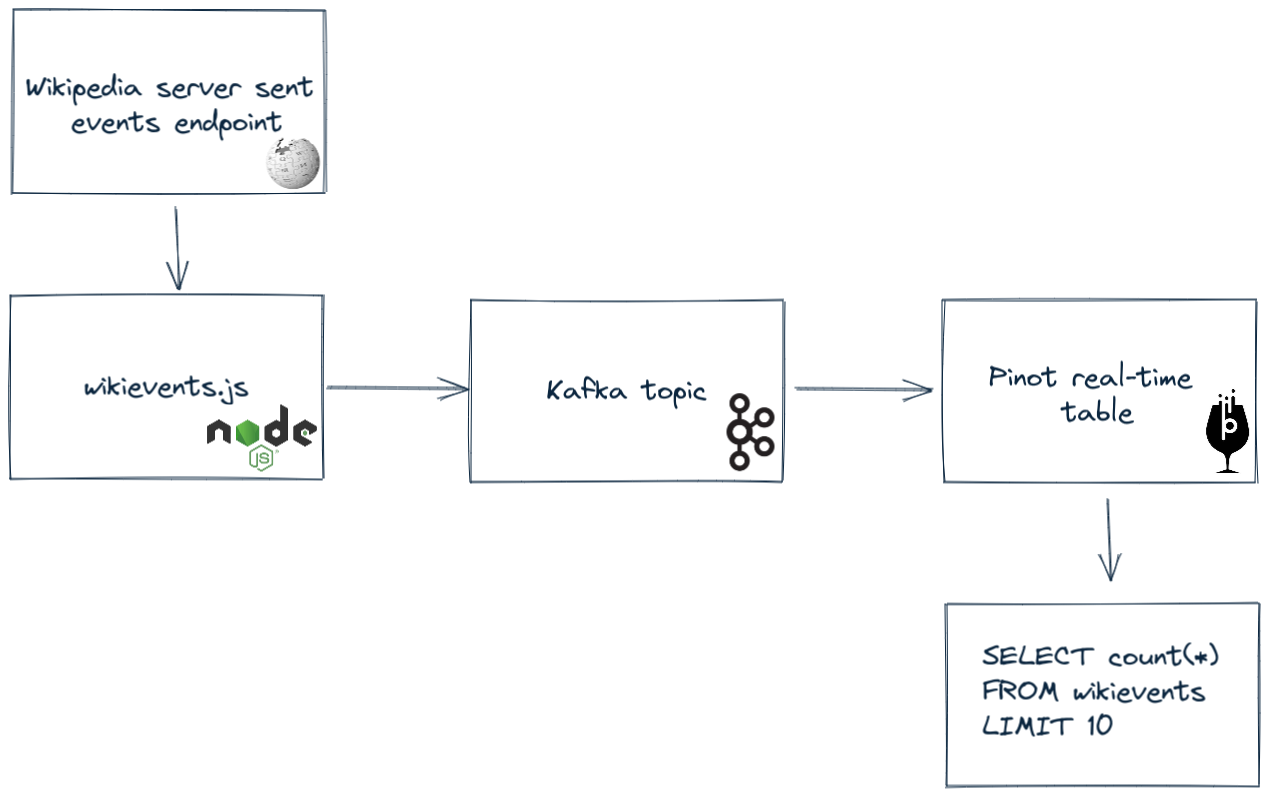
You can find all the code used in this post at github.com/mneedham/startree-realtime-tables.
Streaming Wiki events
Wikipedia provides an HTTP endpoint that returns events, in the server-sent events format , representing all the changes being made to their pages. An example of one such event is shown below:
event: message
id: [{"topic":"eqiad.mediawiki.recentchange","partition":0,"timestamp":1635935095001},{"topic":"codfw.mediawiki.recentchange","partition":0,"offset":-1}]
data: {"$schema":"/mediawiki/recentchange/1.0.0","meta":{"uri":"https://pl.wikipedia.org/wiki/Kategoria:Infoboksy_%E2%80%93_brakuj%C4%85ce_parametry_%E2%80%93_Jednostka_administracyjna_infobox","request_id":"45eb5803-f73b-410c-a640-c76c5d86d91f","id":"5a7ee8b2-fead-4d54-b6fc-4bb433a08e51","dt":"2021-11-03T10:24:55Z","domain":"pl.wikipedia.org","stream":"mediawiki.recentchange","topic":"eqiad.mediawiki.recentchange","partition":0,"offset":3410637559},"id":119002871,"type":"categorize","namespace":14,"title":"Kategoria:Infoboksy – brakujące parametry – Jednostka administracyjna infobox","comment":"usunięto [[:Sukhaura]] z kategorii","timestamp":1635935095,"user":"MalarzBOT","bot":true,"server_url":"https://pl.wikipedia.org","server_name":"pl.wikipedia.org","server_script_path":"/w","wiki":"plwiki","parsedcomment":"usunięto <a href="/wiki/Sukhaura"" title=""Sukhaura"">Sukhaura</a> z kategorii""}Code language: PHP (php)We’re only interested in the stuff under the data key. Let’s write a Node.js application that registers an event listener against the Wikipedia endpoint, extract those events, and write them to a Kafka topic.
Our application uses the following libraries:
npm install eventsource kafkajsThe interesting parts of the app are shown below:
<span class="">wikievents.js
</span>var EventSource = require("eventsource");
const { Kafka } = require("kafkajs");
var url = "https://stream.wikimedia.org/v2/stream/recentchange";
const kafka = new Kafka({
clientId: "wikievents",
brokers: ["localhost:9092"],
});
const producer = kafka.producer();
async function start() {
await producer.connect();
startEvents();
}
function startEvents() {
var eventSource = new EventSource(url);
eventSource.onmessage = async function (event) {
const data = JSON.parse(event.data);
await producer.send({
topic: "wikipedia-events",
messages: [
{
key: data.meta.id,
value: event.data,
},
],
});
};
}
start();Code language: HTML, XML (xml)You can see the full script at github.com/mneedham/startree-realtime-tables/blob/main/wikievents.js.
Before we can run this we need to start up a Kafka server, so let’s do that next.
Starting Pinot and Kafka
The Dockerfile below extends the one from the Getting Started with Apache Pinot blog post to install Kafka, Node.js, and the libraries used by our Node.js application.
<span class="">FROM openjdk:11
</span>
WORKDIR /app
ENV PINOT_VERSION=0.8.0
RUN wget https://downloads.apache.org/pinot/apache-pinot-$PINOT_VERSION/apache-pinot-$PINOT_VERSION-bin.tar.gz
RUN tar -zxvf apache-pinot-$PINOT_VERSION-bin.tar.gz
RUN mv apache-pinot-$PINOT_VERSION-bin pinot
RUN curl -fsSL https://deb.nodesource.com/setup_14.x | bash -
RUN apt install nodejs
RUN npm install eventsource kafkajs
RUN mkdir -p /app/realtime/events
COPY wikievents.js /app/realtime
COPY pinot /app/realtime/pinot
RUN wget https://mirrors.ocf.berkeley.edu/apache/kafka/2.8.1/kafka_2.13-2.8.1.tgz
RUN tar -xvf kafka_2.13-2.8.1.tgz
RUN mv kafka_2.13-2.8.1 kafka
COPY kafka/server.properties /app/kafka/config/
EXPOSE 9000Code language: HTML, XML (xml)We can build a Docker image based on this Dockerfile by running the following command:
docker build . -t gs-pinotAnd launch a Docker container by running the following command:
docker run -p 9000:9000 -it gs-pinot /bin/bashWe’ll now be at the command prompt inside our Docker container, where we need to run commands to launch the Pinot components:
First up we’ll launch Zookeeper:
./pinot/bin/pinot-admin.sh StartZookeeper &Once that’s started, we can launch the other components. We’ll need to wait until we see a component is ready before we run the next command:
<span class="">./pinot/bin/pinot-admin.sh StartController &
</span>./pinot/bin/pinot-admin.sh StartBroker &
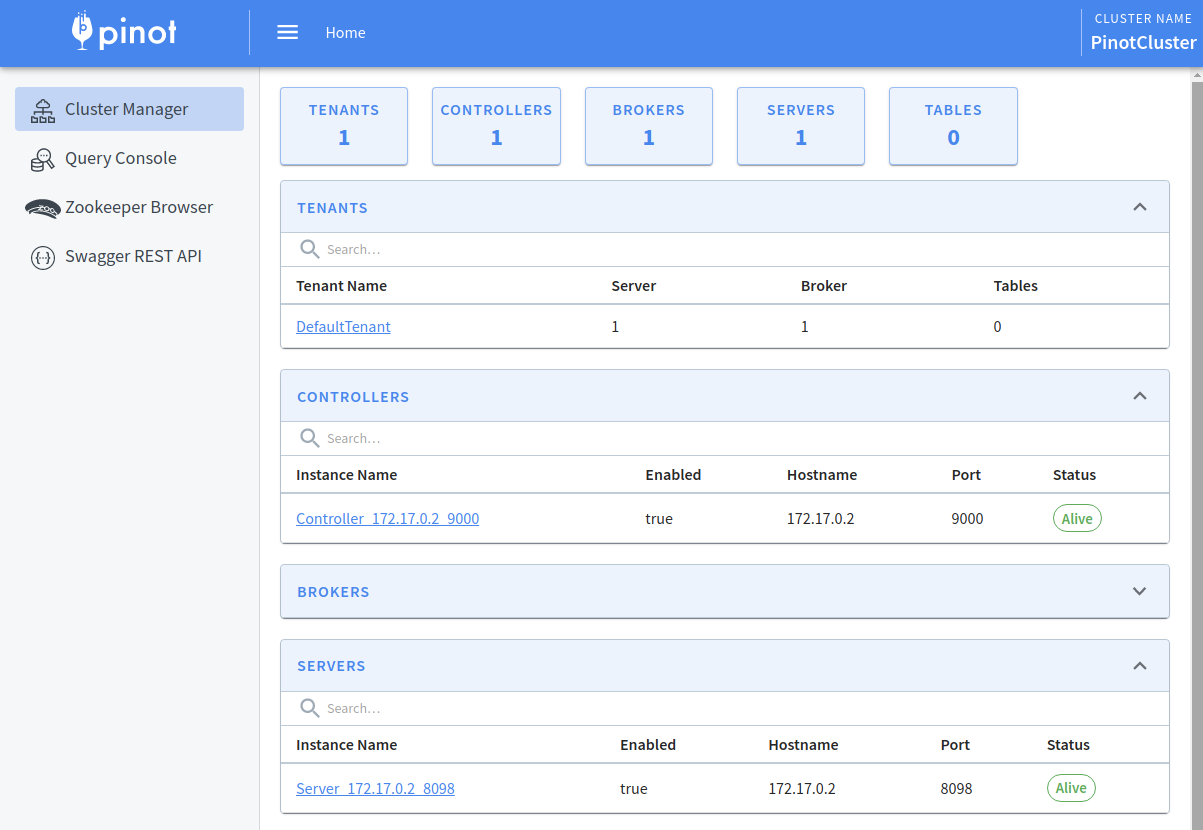
./pinot/bin/pinot-admin.sh StartServer &Code language: JavaScript (javascript)Once we’ve run all these commands we can navigate to http://localhost:9000 to make sure that everything has launched. We should see the following:
To launch Kafka, run the following:
./kafka/bin/kafka-server-start.sh ./kafka/config/server.properties &If we navigate to http://localhost:9000/#/zookeeper we’ll see the following:
We should see a separate entry for kafka. Now we’re ready to import Wiki events into Kafka which we can do by running the Node.js script that we saw earlier:
node realtime/wikievents.jsWe’ll see the following output:
Connecting to EventStreams at https://stream.wikimedia.org/v2/stream/recentchange — Opened connection.
As long as we don’t see any connection errors, everything should be working fine. Each Wiki event is also being written to the file system under /app/realtime/events (for testing/debugging purposes), and we can check how many events have been processed by stopping the node process and running the following command:
ls -alh realtime/events/* | grep json | wc -lIf we see a result of more than 0, the next step is to get those events into Apache Pinot.
Create a Schema for the Events
The first thing that we need to do is create a schema for the Pinot table. The schema defines the table’s fields and their data types. The schema for Wikipedia is described below:
<span class="">{
</span> "schemaName": "wikipedia",
"dimensionFieldSpecs": [
{
"name": "id",
"dataType": "STRING"
},
{
"name": "wiki",
"dataType": "STRING"
},
{
"name": "user",
"dataType": "STRING"
},
{
"name": "title",
"dataType": "STRING"
},
{
"name": "comment",
"dataType": "STRING"
},
{
"name": "stream",
"dataType": "STRING"
},
{
"name": "domain",
"dataType": "STRING"
},
{
"name": "topic",
"dataType": "STRING"
},
{
"name": "type",
"dataType": "STRING"
},
{
"name": "metaJson",
"dataType": "STRING"
}
],
"dateTimeFieldSpecs": [
{
"name": "timestamp",
"dataType": "LONG",
"format": "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}
]
}Code language: HTML, XML (xml)This dataset only contains dimension and date time fields, we don’t have any metrics fields. This schema file is available in the Docker image at /app/realtime/pinot/realtime.schema.json and we can create the schema in Pinot by running the following:
<span class="">./pinot/bin/pinot-admin.sh AddSchema
</span>-schemaFile ./realtime/pinot/realtime.schema.json -execCode language: JavaScript (javascript)The output should contain something like the following:
<span class="">Executing command: AddSchema -controllerProtocol http -controllerHost 172.17.0.2 -controllerPort 9000 -schemaFile ./realtime/pinot/realtime.schema.json -user null -password [hidden] -exec
</span>Notifying metadata event for adding new schema wikipedia
Handled request from 172.17.0.2 POST http://172.17.0.2:9000/schemas, content-type multipart/form-data; boundary=xnReLR-9AfMZ93XxMdhPATXcWBjkPz91mTu9ff status code 200 OK
Sending request: http://172.17.0.2:9000/schemas to controller: efa8e57485ae, version: UnknownCode language: HTML, XML (xml)We can check that our schema has been created by navigating to http://localhost:9000/schemas/wikipedia. We should also be able to see it in the ZooKeeper Browser:
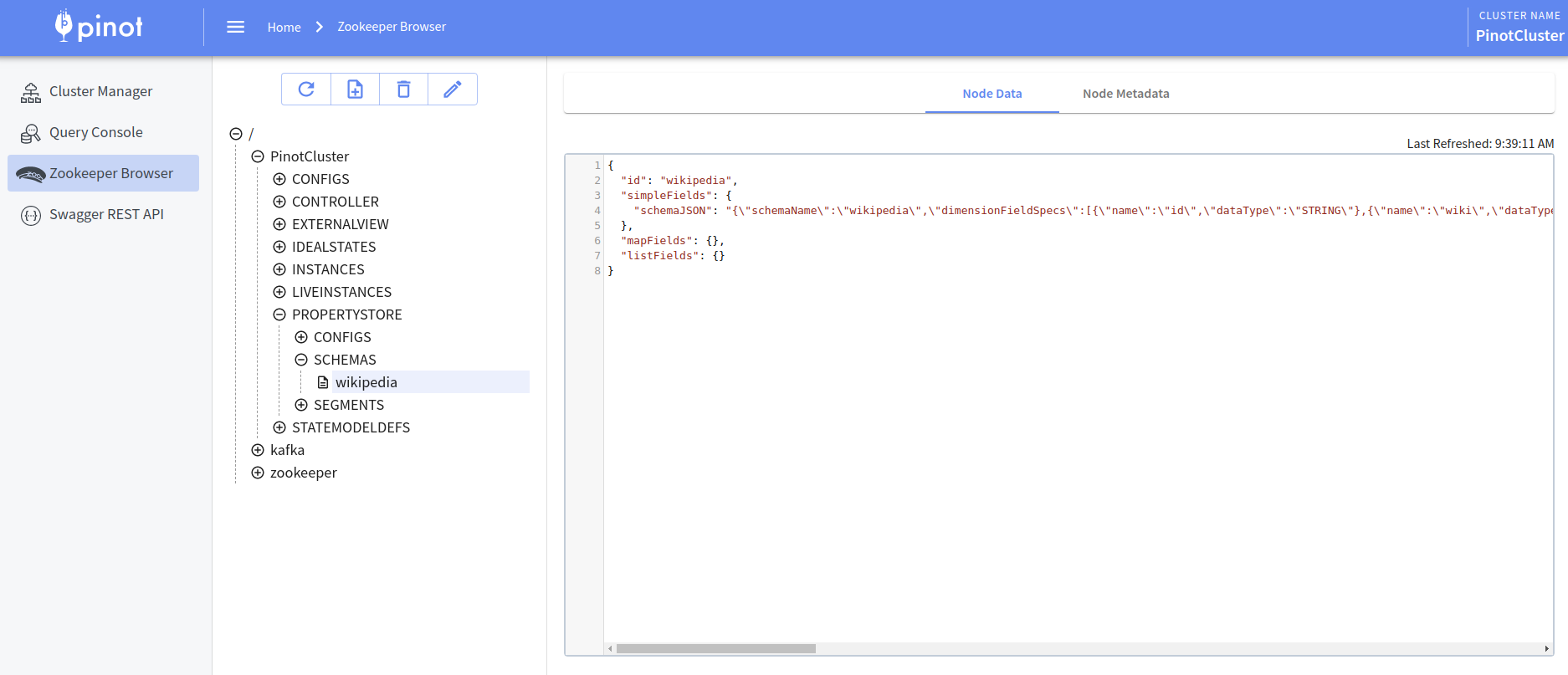
Create a Real-time Table
Next, we’ll create a table based on that schema. The config for this table contains:
-
A reference to the schema defined that we just created.
-
Stream config that describes the Kafka server address and topic name.
-
Transform config that describes how to extract data from the JSON meta field.
The config is shown below:
<span class="">{
</span> "tableName": "wikievents_REALTIME",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"schemaName": "wikipedia",
"replication": "1",
"replicasPerPartition": "1"
},
"tenants": {
"broker": "DefaultTenant",
"server": "DefaultTenant",
"tagOverrideConfig": {}
},
"tableIndexConfig": {
"invertedIndexColumns": [],
"rangeIndexColumns": [],
"autoGeneratedInvertedIndex": false,
"createInvertedIndexDuringSegmentGeneration": false,
"sortedColumn": [],
"bloomFilterColumns": [],
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.topic.name": "wikipedia-events",
"stream.kafka.broker.list": "localhost:9092",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"realtime.segment.flush.threshold.rows": "0",
"realtime.segment.flush.threshold.time": "24h",
"realtime.segment.flush.segment.size": "100M"
},
"noDictionaryColumns": [],
"onHeapDictionaryColumns": [],
"varLengthDictionaryColumns": [],
"enableDefaultStarTree": false,
"enableDynamicStarTreeCreation": false,
"aggregateMetrics": false,
"nullHandlingEnabled": false
},
"metadata": {},
"quota": {},
"routing": {},
"query": {},
"ingestionConfig": {
"transformConfigs": [
{
"columnName": "metaJson",
"transformFunction": "JSONFORMAT(meta)"
},
{
"columnName": "id",
"transformFunction": "JSONPATH(metaJson, '$.id')"
},
{
"columnName": "stream",
"transformFunction": "JSONPATH(metaJson, '$.stream')"
},
{
"columnName": "domain",
"transformFunction": "JSONPATH(metaJson, '$.domain')"
},
{
"columnName": "topic",
"transformFunction": "JSONPATH(metaJson, '$.topic')"
}
]
},
"isDimTable": false
}Code language: HTML, XML (xml)Notice that under ingestionConfig.transformConfigs we’re applying some JSON functions to treat the data under the meta key as JSON and to extract the id, stream, domain, and topic keys.
We can apply this config to Pinot by running the following command:
<span class="">./pinot/bin/pinot-admin.sh AddTable
</span>-tableConfigFile ./realtime/pinot/realtime.tableconfig.json -execCode language: JavaScript (javascript)We should see the following output:
<span class="">Executing command: AddTable -tableConfigFile ./realtime/pinot/realtime.tableconfig.json -schemaFile null -controllerProtocol http -controllerHost 172.17.0.2 -controllerPort 9000 -user null -password [hidden] -exec
</span>PinotRealtimeSegmentManager.handleChildChange: /PinotCluster/PROPERTYSTORE/CONFIGS/TABLE
Processing change notification for path: /PinotCluster/PROPERTYSTORE/CONFIGS/TABLE
Received change notification for path: /PinotCluster/PROPERTYSTORE/CONFIGS/TABLE
PinotRealtimeSegmentManager.handleDataChange: /PinotCluster/PROPERTYSTORE/CONFIGS/TABLE
Processing change notification for path: /PinotCluster/PROPERTYSTORE/CONFIGS/TABLE
Received change notification for path: /PinotCluster/PROPERTYSTORE/CONFIGS/TABLE
PinotRealtimeSegmentManager.handleChildChange: /PinotCluster/PROPERTYSTORE/CONFIGS/TABLE
Processing change notification for path: /PinotCluster/PROPERTYSTORE/CONFIGS/TABLE
Received change notification for path: /PinotCluster/PROPERTYSTORE/CONFIGS/TABLE
Setting up new LLC table: wikievents_REALTIMECode language: JavaScript (javascript)Once the table is created, Pinot will start ingesting the events that we’ve already loaded into Kafka. We can see what data’s been imported by navigating to http://localhost:9000/#/query. We should see the following:
Query the Events in Real-time
If we click on the wikievents table it will run a query to return the first 10 records:
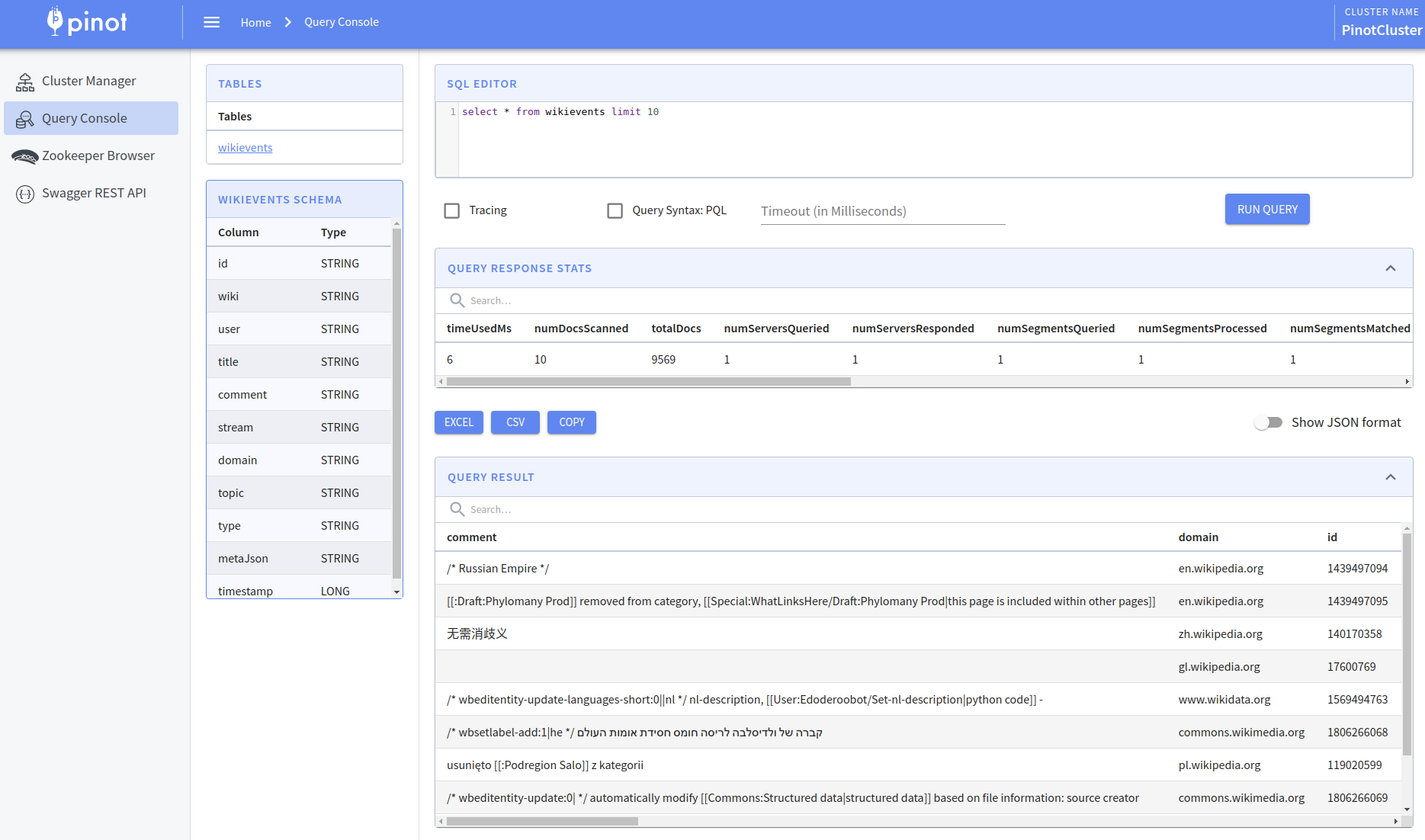
Let’s go back to the terminal and restart the Node.js app that imports Wikipedia events:
node realtime/wikievents.jsMore records are now being ingested, so if we click Run Query again we’ll see that the number of totalDocs has increased. We could also run a more interesting query to see who’s been editing all the pages:
<span class="">SELECT user, count(user)
</span>FROM wikievents
GROUP BY user
ORDER BY count(user) DESC
LIMIT 10;Code language: HTML, XML (xml)If we run this query, we’ll see the following output:
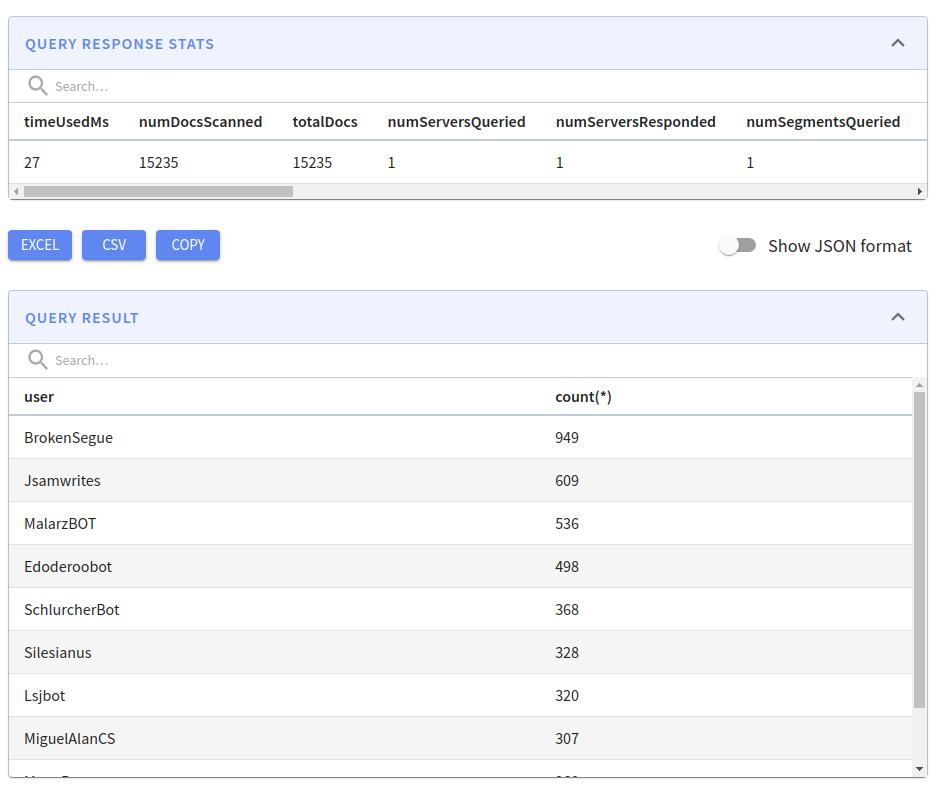
There are some seriously prolific users here and, perhaps unsurprisingly, many of them are bots.
Summary
In this post, we’ve learnt how to import streaming events from Wikipedia into Pinot via Kafka.
We wrote a Node.js app that processed Wikipedia events and put them onto a Kafka topic. We then created a schema and table config to take events from that topic and import them into Pinot. Pinot supports data ingestion from several streaming platforms and provides a Java based plugin mechanism to write a connector if your streaming source isn’t yet supported.
Finally, we ran SQL queries against the ingested data to see which users were making the most changes to Wikipedia pages.
That’s all for now, but stay tuned for future posts where we’ll cover indexing configurations and more.
