
Apache Pinot has been purpose-built to run analytics queries with low latency and high throughput. Its architecture allows for easy scalability. As data volume grows, we can add more servers to the cluster and rebalance the workload, keeping queries running fast. However, hardware costs increase almost linearly as the cluster scales out.
The cost of storage
For real-time analytics, the value of data diminishes quickly as time passes, so many Pinot users use short data retention to control storage costs. Older data may be stored in other systems optimized for offline analytics, which tend to have a compute-storage decoupled architecture. This trade-off between storage cost and higher query latency is made. Additionally, running multiple systems adds more complexity to development and operation.
Multi Volume storage – Making storage costs manageable
To keep the simplicity of running one system for various analytics use cases, the multi volume feature was added to Pinot. Users can now keep large amounts of data in Pinot in different storage tiers based on access patterns to keep storage costs manageable.
The multi volume storage feature used to be tightly coupled to table tenants. Users had to use a separate tenant, backed by a specific server pool, for a new storage tier.
For example, a tenant with servers equipped with SSDs would be configured to store the most recent data for very fast data access, while another tenant of servers with HDDs would store older data for a lower cost. This works well when users have access to heterogeneous hardware and comes with the benefit of strong performance isolation among queries accessing different data sets.
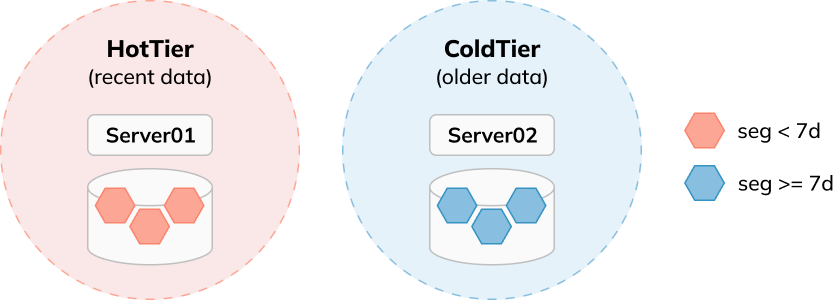
Unfortunately, it’s not flexible enough for cases where users want to add more cheaper disks to existing servers to store older data at a lower cost or where users have servers already equipped with both fast and slow disks.
It also means that if users want to add more storage or a different grade of storage, they also need to add extra compute that they don’t need.
To build on the previous example, if we had three servers with SSDs and wanted to add 3 HDDs, we’d be forced to add three new servers to the tenant pool. This is more expensive than just adding the extra HDDs and means we likely have some wasted compute.
Imagine that a server costs $100, a TB of SSD storage costs $100, and a TB of HDD storage costs $50. Based on the example above, assuming 1 TB of storage per server, we’d have the following costs:
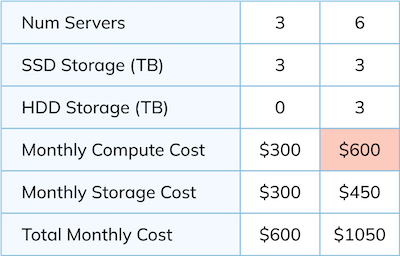
We end up paying an extra $300 for the servers, which enables the $150 of extra HDD storage. This is wasteful, and surely we can do better!
An improved multi volume storage
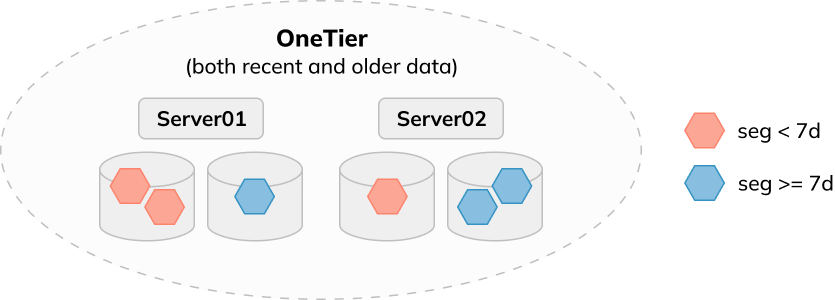
To make Pinot handle those use cases in a cost-effective manner, in version 0.11, we extended the multi volume storage feature to allow servers to use multiple data directories, which can be backed by different disks (e.g., HDD, SSD, or different types of EBS volumes) to store data.
A Worked Example
Now for an example that shows how all this works.
Setting up a Pinot cluster
We’re going to start a Pinot cluster that has a controller, broker, server, and minion. Our Docker Compose file is shown below:
version: "3" services: zookeeper: image: zookeeper:3.8.0 hostname: zookeeper container_name: zookeeper-multidir-blog ports: - "2181:2181" environment: ZOOKEEPER_CLIENT_PORT: 2181 ZOOKEEPER_TICK_TIME: 2000 networks: - multidir_blog pinot-controller: image: apachepinot/pinot:0.11.0-SNAPSHOT-a6f5e89-20230110-arm64 command: "StartController -zkAddress zookeeper-multidir-blog:2181 -configFileName /config/controller-conf.conf" container_name: "pinot-controller-multidir-blog" volumes: - ./config:/config - ./batch-data:/batch-data restart: unless-stopped ports: - "9000:9000" networks: - multidir_blog pinot-broker: image: apachepinot/pinot:0.11.0-SNAPSHOT-a6f5e89-20230110-arm64 command: "StartBroker -zkAddress zookeeper-multidir-blog:2181" container_name: "pinot-broker-multidir-blog" volumes: - ./config:/config restart: unless-stopped ports: - "8099:8099" networks: - multidir_blog pinot-server: image: apachepinot/pinot:0.11.0-SNAPSHOT-a6f5e89-20230110-arm64 command: "StartServer -zkAddress zookeeper-multidir-blog:2181 -configFileName /config/server-conf.conf" container_name: "pinot-server-multidir-blog" volumes: - ./storage:/storage/ - ./config:/config restart: unless-stopped networks: - multidir_blog pinot-minion: image: apachepinot/pinot:0.11.0-SNAPSHOT-a6f5e89-20230110-arm64 container_name: "pinot-minion-multidir-blog" command: "StartMinion -zkAddress zookeeper-multidir-blog:2181" restart: unless-stopped volumes: - ./batch-data:/batch-data depends_on: - pinot-broker networks: - multidir_blog networks: multidir_blog: name: multidir_blogCode language: JavaScript (javascript)The controller and server are both using configuration files.
Controller configuration
Let’s have a look at the contents of those files, starting with the controller:
config/controller-conf.conf controller.segment.relocator.frequencyPeriod=60s controller.segmentRelocator.initialDelayInSeconds=10 controller.segmentRelocator.enableLocalTierMigration=true controller.data.dir=/deep-store controller.access.protocols.http.port=9000 controller.zk.str=zookeeper-multidir-blog:2181 controller.helix.cluster.name=PinotCluster controller.host=pinot-controller-multidir-blog controller.port=9000Code language: JavaScript (javascript)The main sections of interest for us are the first three parameters. These control the frequency of the segment locator job, as well as make it possible to move segments around on the same server, which is one of the changes made in the latest release.
Server configuration
The other configuration isn’t interesting for the purposes of this blog post, so let’s ignore that and move on to the server config:
config/server-conf.conf pinot.server.instance.dataDir=/storage/server/default pinot.server.instance.segment.directory.loader=tierBased pinot.server.instance.tierConfigs.tierNames=hotTier,coldTier pinot.server.instance.tierConfigs.hotTier.dataDir=/storage/server/hot pinot.server.instance.tierConfigs.coldTier.dataDir=/storage/server/coldCode language: JavaScript (javascript)The first line sets the default directory for segments when they are first created. We then enable tier-based storage, define the names of the tiers, and where segments that fall into each tier should be stored.
Note that while we’re using different folders on the same disk in this example, an actual production setup would be using different mounted disks and folders from those separate disks.
We can start up our cluster by running docker-compose up.
Setting up table with multi directory
Once that’s running, it’s time to create a table and schema. The schema is shown below:
{ "schemaName": "events", "dimensionFieldSpecs": [ {"name": "eventId", "dataType": "STRING"}, {"name": "userId", "dataType": "STRING"}, {"name": "name", "dataType": "STRING"}, {"name": "city", "dataType": "STRING"}, {"name": "region", "dataType": "STRING"}, {"name": "action", "dataType": "STRING"} ], "dateTimeFieldSpecs": [ { "name": "ts", "dataType": "TIMESTAMP", "format": "1:MILLISECONDS:EPOCH", "granularity": "1:MILLISECONDS" } ] }Code language: JSON / JSON with Comments (json)And the table config below:
{ "tableName": "events", "tableType": "OFFLINE", "segmentsConfig": { "timeColumnName": "ts", "schemaName": "events", "replication": "1", "replicasPerPartition": "1" }, "tableIndexConfig": {"loadMode": "MMAP"}, "ingestionConfig": { "transformConfigs": [ { "columnName": "ts", "transformFunction": "FromDateTime(eventTime, 'YYYY-MM-dd''T''HH:mm:ss.SSSSSS')" } ] }, "tierConfigs": [ { "name": "hotTier", "segmentSelectorType": "time", "segmentAge": "0d", "storageType": "pinot_server", "serverTag": "DefaultTenant_OFFLINE" }, { "name": "coldTier", "segmentSelectorType": "time", "segmentAge": "3d", "storageType": "pinot_server", "serverTag": "DefaultTenant_OFFLINE" } ], "tenants": {}, "metadata": {} }Code language: JSON / JSON with Comments (json)In this config we’ve defined two storage tiers:
- coldTier , which will store segments that contain data from 3 days ago or further back. (” segmentAge “: ” 3d “)
- hotTier , which will store segments that contain data within the last 3 days. (” segmentAge “: ” 0d “)
Storage tiers are defined within the same server pool.
Ingesting old and new data
Next, let’s ingest some data into our table. We’re going to ingest two files:
- events-old.json, which contains data from a week ago
- events-new.json , which contains data from today.
The following command displays one row of the source JSON files:
$ head -n1 batch-data/*.json ==> batch-data/events-new.json <== {"eventTime": "2023-01-18T12:23:14.073732", "eventId": "ff552ac9-b3db-45ef-a87a-f09b5086a639", "userId": "94598fb6-3572-4d35-ac49-d7697a73d7cf", "name": "Mrs. Olivia Roberts", "city": "Kansas City", "region": "Missouri", "action": "Join"} ==> batch-data/events-old.json <== {"eventTime":"2023-01-09T16:18:39.710269","eventId":"31dacbd5-f630-44e5-a2d1-94b37b1dfa3c","userId":"465981cf-9871-4b69-b424-1be18f655990","name":"Erica Jones","city":"Singapore","region":"Singapore","action":"Join"}Code language: HTML, XML (xml)Each line contains a JSON record representing a join or leave event of a person attending a webinar or live stream. We can ingest that data by using the INSERT INTO clause:
SET taskName = 'events-task655'; SET input.fs.className = 'org.apache.pinot.spi.filesystem.LocalPinotFS'; SET includeFileNamePattern='glob:**/*.json'; INSERT INTO events FROM FILE 'file:///batch-data/';Code language: JavaScript (javascript)Segment location
Once that’s run, we can check where those segments have been stored:
$ tree storage storage └── server ├── cold │ └── events_OFFLINE ├── default │ └── events_OFFLINE │ ├── events_OFFLINE_cbbf2df1-cfd3-42e3-9dfc-7c2a3d07d5f9_0 │ │ └── v3 │ │ ├── columns.psf │ │ ├── creation.meta │ │ ├── index_map │ │ └── metadata.properties │ ├── events_OFFLINE_cbbf2df1-cfd3-42e3-9dfc-7c2a3d07d5f9_1 │ │ └── v3 │ │ ├── columns.psf │ │ ├── creation.meta │ │ ├── index_map │ │ └── metadata.properties │ └── tmp └── hotCode language: JavaScript (javascript)Both segments are under /storage/server/default at the moment, and at this point, it probably makes sense to explain the process of how segments find their way into multi volume storage with help from a diagram:
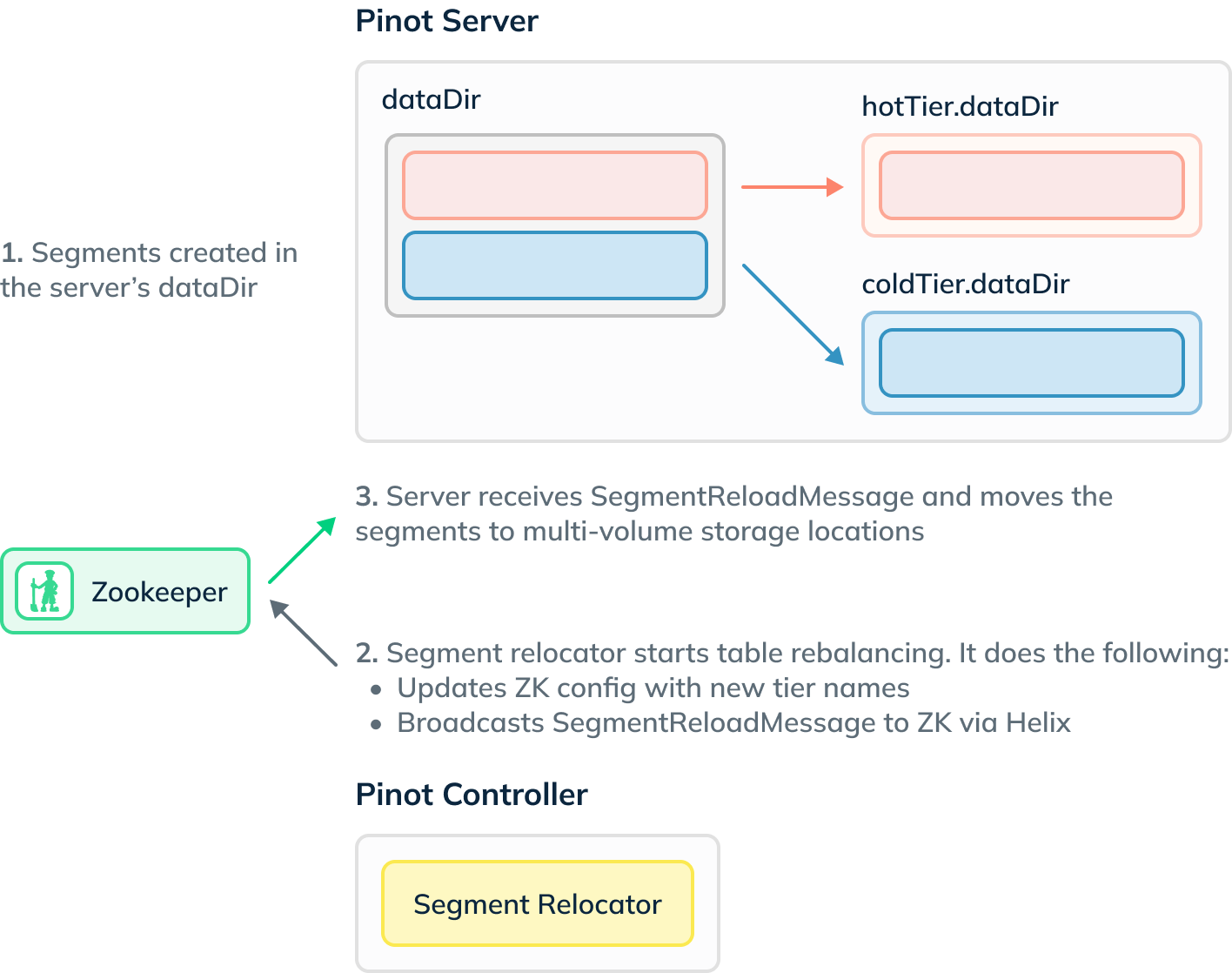
Segments are initially created in the default dataDir, in our case /storage/server/default . Every 60 seconds, the segment relocator job runs on the controller and checks whether any segments meet the criteria to be moved into multi volume storage.
If they do, then the controller sends a SegmentReloadMessage, which gets picked up by the server. The server then moves segments to the appropriate place.
We can determine the new location by calling the HTTP API, as shown below:
curl -X GET "http://localhost:9000/segments/events/tiers?type=OFFLINE" -H "accept: application/json" 2>/dev/null | jqCode language: JavaScript (javascript)This returns the following result:
{ "tableName": "events_OFFLINE", "segmentTiers": { "events_OFFLINE_cbbf2df1-cfd3-42e3-9dfc-7c2a3d07d5f9_0": { "targetTier": "hotTier", "Server_172.23.0.3_8098": "hotTier" }, "events_OFFLINE_cbbf2df1-cfd3-42e3-9dfc-7c2a3d07d5f9_1": { "targetTier": "coldTier", "Server_172.23.0.3_8098": "coldTier" } } }Code language: JSON / JSON with Comments (json)The response shows that one segment is in the coldTier and one in the hotTier . We can list the contents of that directory to confirm for ourselves:
$ tree storage storage └── server ├── cold │ └── events_OFFLINE │ └── events_OFFLINE_cbbf2df1-cfd3-42e3-9dfc-7c2a3d07d5f9_1 │ └── v3 │ ├── columns.psf │ ├── creation.meta │ ├── index_map │ └── metadata.properties ├── default │ └── events_OFFLINE │ ├── events_OFFLINE_cbbf2df1-cfd3-42e3-9dfc-7c2a3d07d5f9_0.tier │ ├── events_OFFLINE_cbbf2df1-cfd3-42e3-9dfc-7c2a3d07d5f9_1.tier │ └── tmp └── hot └── events_OFFLINE └── events_OFFLINE_cbbf2df1-cfd3-42e3-9dfc-7c2a3d07d5f9_0 └── v3 ├── columns.psf ├── creation.meta ├── index_map └── metadata.properties 12 directories, 10 filesCode language: JavaScript (javascript)Looks good! The multi volume storage feature has done its job.
StarTree Tiered Storage
This new extension on tiered storage makes it possible to scale storage independent of compute to some extent, but they aren’t completely decoupled because the storage is still local to each server.
The storage may be shared across servers if we mount DFS to all servers via POSIX, but the OS is not aware of the access patterns to those remote data during segment loading or query execution times, making performance likely unacceptable.
At StarTree, we are building a new tiered storage extension backed by cloud storage to truly decouple storage and compute resources and make both segment management and query executions efficient.
Summary
We’d love for you to give multi volume storage or StarTree tiered storage a try to see if they can better help control the storage costs of your Pinot estate.
Let us know how you get on and if you have any questions about this feature, feel free to join us on Slack, where we’ll be happy to help you out.
