
When ChatGPT 3.0 exploded onto the scene, it felt like the future had finally arrived. AI could talk, reason, and respond in seconds. We were promised jetpacks. But for those of us working with enterprise data—whether as builders or business users—the jetpack never showed up.
Trying to layer an LLM on top of a traditional data lakehouse has been a bust. Why? Because the very things that make tools like ChatGPT feel magical—speed, interactivity, and contextual awareness—are exactly where today’s enterprise data platforms fall short.
- First, legacy systems like Snowflake and Databricks simply can’t support real-time, ad-hoc querying with sub-second latency. A conversation with your data shouldn’t require a loading bar.
- Second, they weren’t built for external data products. Giving your customers or your AI agents access to live data at massive concurrency? Not a chance. These platforms were architected for internal analysts—not for swarms of autonomous agents acting in parallel.
- Third, vector databases had their moment by promising the ability to augment foundation model knowledge with enterprise information, but most operate in batch mode, lagging hours or days behind the data they’re supposed to represent. This ultimately limited the kinds of enterprise use cases they could address.
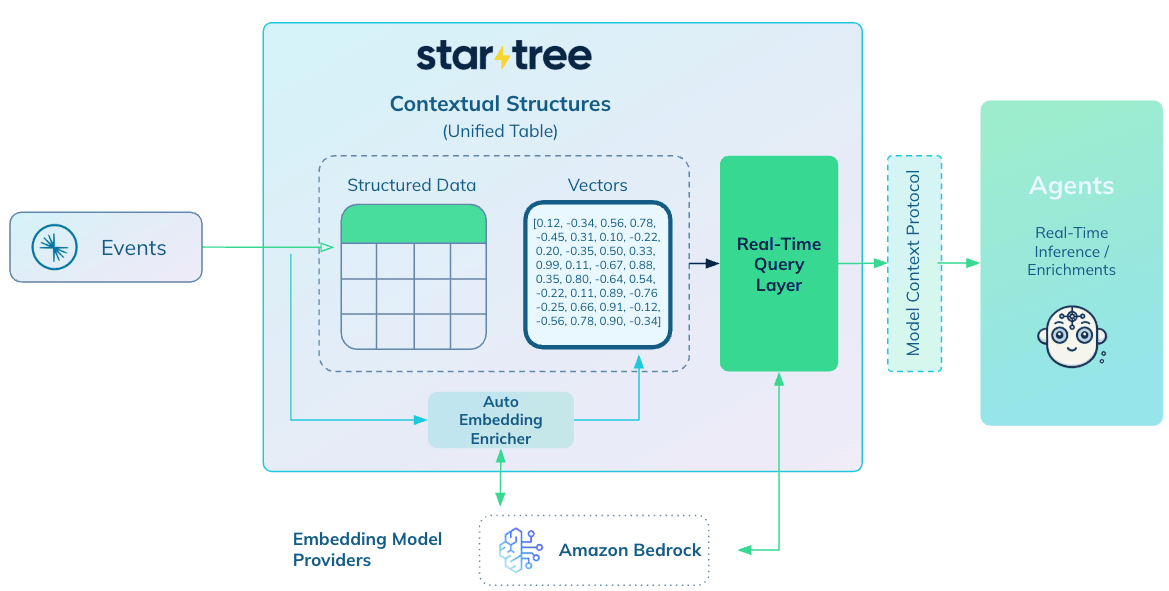
That’s why StarTree is launching Model Context Protocol (MCP) support and native vector auto embedding—two major features designed to unlock the promise of real-time AI for the enterprise. Built on Apache Pinot™, StarTree already powers some of the world’s most demanding analytics workloads. With these capabilities we’re making conversational querying, real-time RAG, and agentic AI not just possible—but production-ready.
It’s the real-time data infrastructure AI has been waiting for. And yes, this one actually comes with a jetpack.
Catching Up with Apache Pinot
If it’s been a while since you looked at Apache Pinot, here’s a quick refresher on why it’s become the real-time OLAP engine of choice for modern enterprises.
Pinot was purpose-built to handle fresh data at massive scale. It can ingest, index, and make data available for querying within about a second of it being created at the source—whether that’s a clickstream event, transaction, or system log.
Once ingested, Pinot delivers blazing-fast queries—measured in milliseconds, even when scanning across petabytes of data. And unlike legacy warehouses that struggle under user load, Pinot handles hundreds of thousands of queries per second, making it ideal for powering customer-facing apps, dashboards, AI agents, and other real-time systems that need always-on performance.
This isn’t theoretical. 30% of the Fortune 1000 now use Apache Pinot to power real-time analytics and AI applications. That includes Apple, Stripe, LinkedIn, Uber, Citi, Goldman Sachs, Etsy, 7-Eleven, Nubank, Walmart, Slack, Robinhood, Hyundai, JP Morgan, Cisco, and many more.
They rely on Pinot because it solves a real problem—how to deliver fast, fresh, and frequent access to live data at scale.
StarTree, the managed cloud service powered by Apache Pinot, builds on this foundation to bring even more performance, flexibility, and ease of use—especially for AI use cases. And with the addition of MCP support and native vector auto embedding, Pinot’s core superpowers now extend into the next generation of AI-powered workflows.
Introducing Model Context Protocol (MCP) Support
MCP is a new open standard that acts like a smart interface between your enterprise data and your AI agents. It allows AI models to dynamically query live structured data as part of their reasoning process—no more hard-coded logic, no more brittle, ad hoc integrations.
With StarTree’s support for MCP, AI agents and copilots can seamlessly pull in real-time signals—like delivery times, customer feedback, or telemetry logs—at query time. This enables next-generation applications where agents don’t just react—they reason, act, and adapt in real time.
Native Vector Auto Embedding
Apache Pinot added support for handling vectors in 2024, extending the same performance characteristics that made Pinot valuable—allowing organizations to ingest vector indexes as they’re created, index them on the fly, and reconcile updates in real time. This powers true real-time RAG (Retrieval-Augmented Generation)—enabling AI models to reason over live data instead of stale snapshots.
Now, with the introduction of native vector auto embedding, StarTree is making that power easier to harness. The new feature enables enterprises to generate, ingest, and index vector embeddings in a fully integrated workflow, eliminating the need for complex, stitched-together pipelines.
It’s not just about speed anymore—it’s about speed and simplicity, making it easier than ever to unlock the full potential of real-time RAG for use cases in finance, observability, cybersecurity, and beyond.
Conversational Querying: From Conversation Interruptus to Fluid Interactions
Natural language interfaces only work if the responses are fast and fresh. No one wants to ask a question and then sit through an awkward 90-second pause while a traditional data warehouse tries to churn out an answer. That kind of lag breaks the flow and defeats the purpose of conversational AI.
Powered by StarTree’s integration with Amazon Bedrock and support for real-time data, enterprises can now build fluid, multi-turn conversations with live data as the backend. StarTree delivers sub-second performance even at massive scale—making it possible for someone like a rideshare driver to ask follow-up questions like:
- “How much money have I made today?”
- “What about this month?”
- “Where and when am I making the most money?”
From ride-hailing to e-commerce and logistics, this unlocks conversational analytics that actually keep up with the pace of business.
Agentic AI: From Customer-Facing to Agent-Facing Applications
Agentic AI isn’t just about speed—it’s about scale. In a world where every autonomous agent needs live access to data, concurrency becomes the critical bottleneck.
Apache Pinot, the engine behind StarTree, was originally built to serve analytics at scale for companies like Uber, LinkedIn, and Stripe—supporting millions of customer-facing queries per second. But agentic AI changes the scale equation entirely.
Soon, enterprises won’t just have thousands of customers interacting with data every second—they’ll have millions of agents, each making micro-decisions, querying data products, and adapting to live context in real time.
That’s a tsunami of concurrent demand. And legacy data warehouses weren’t built to handle it.
Designed for extreme concurrency, StarTree enables swarms of AI agents to access real-time insights—simultaneously, continuously, and without degradation. Whether it’s:
- A logistics agent checking inventory and ETAs to reroute deliveries
- A pricing agent adjusting discounts based on real-time demand
- A system health agent scaling cloud resources to prevent outages
All of them rely on live, structured data at scale—and StarTree is the only real-time database ready to meet that challenge. Agentic AI is coming fast. The only question is whether your data infrastructure can keep up.
Real-Time RAG: From Deterministic Queries to Probabilistic Reasoning at Speed
Vector embeddings enable pattern matching on steroids—unlocking semantic relationships and contextual similarities far beyond what traditional data management techniques reveal.
Traditional analytics platforms excel at deterministic queries—asking precise questions with clear answers:
- “How many 500 errors occurred in the last 5 minutes?”
- “Which server had the highest latency yesterday?”
But as systems grow more complex, those kinds of queries hit their limits. Enter Retrieval-Augmented Generation (RAG) with vector embeddings—enabling probabilistic reasoning that can surface deeper, pattern-based insights:
- “Is this latency spike similar to a past incident?”
- “What kinds of logs typically precede a memory leak in this cluster?”
This is where Real-Time RAG becomes essential. In domains like cybersecurity, observability, and financial markets, the value of insight decays by the second. Waiting hours—or even minutes—for batch-generated embeddings renders these use cases ineffective.
With StarTree, vector embeddings can be:
- Generated, ingested, and indexed in near real time
- Queried immediately alongside structured data
- Updated continuously with zero disruption
Real-Time RAG Observability Example
Before Vector RAG:
An SRE sees repeated log lines with error code 503. A deterministic query returns the frequency and server IDs—but fails to connect this pattern to a prior incident caused by a config drift.
After Vector RAG (with StarTree):
The same logs are instantly embedded and indexed. An LLM queries them semantically and returns:
“This pattern matches an outage from two weeks ago linked to a rolling restart misconfiguration.”
StarTree’s ability to handle high-velocity embedding ingestion and make it instantly queryable bridges the gap between structured analytics and semantic reasoning—giving AI the fresh context it needs to detect patterns, spot threats, and surface insights in real time.
When the stakes are high and timing is everything, batch-mode RAG won’t cut it.
Although Apache Pinot pre-dates the rise of LLMs, its architecture—built for data freshness, speed, scale, and concurrency—is a natural fit for modern AI workloads. With these new AI capabilities, we’re entering a new AI-Native Era, and Pinot is ready to power it.
Model Context Protocol (MCP) integration will be available in June, with native vector embedding support following in Fall 2025.
If you’re building real-time analytics infrastructure for GenAI, we’d love to hear about your use case—and show you how StarTree can help.
