
How does one deliver insights to hundreds of thousands of users in ways that are useful?
More and more companies are finding ways to provide value to their users by providing actionable insights based on their own data. The term for this that we have coined is “user-facing analytics” (also sometimes referred to as “customer-facing analytics”), and it is just one kind of real-time analytics that is becoming the norm for the most successful brands.
LinkedIn is one such brand; both individual users and companies can get insights from the platform’s data and thus get much more value from it. It is also a good example of one of the biggest technical challenges when it comes to providing analytics in real-time: Latency at scale.
An OLAP Platform at OLTP Speeds
Think, for a moment, about what real-time user-facing analytics on a platform like LinkedIn entails in terms of the functionality needed. There are roughly 200,000+ queries per second happening at any given time, from LinkedIn’s millions of users. These queries are all different, suiting the needs of different users with different goals. Those users have many other tasks on their plates and are not going to want to wait for their insights.
When we think of all the users being connected to LinkedIn and using apps, we might think that LinkedIn’s platform was acting like an OLTP (online transaction processing) database: There are a high number of concurrent users and a need for millisecond latency. In OLTP systems, data is optimized for specific applications and uses to achieve consistent, fast transactions.
But what is being done with the data in a user-facing application is much more like what we see in OLAP (online analytical processing). Large amounts of data need to be aggregated and mined, and the queries are often complex, varying with time and user need. Thus, data is optimized for “slicing and dicing” in many different ways.
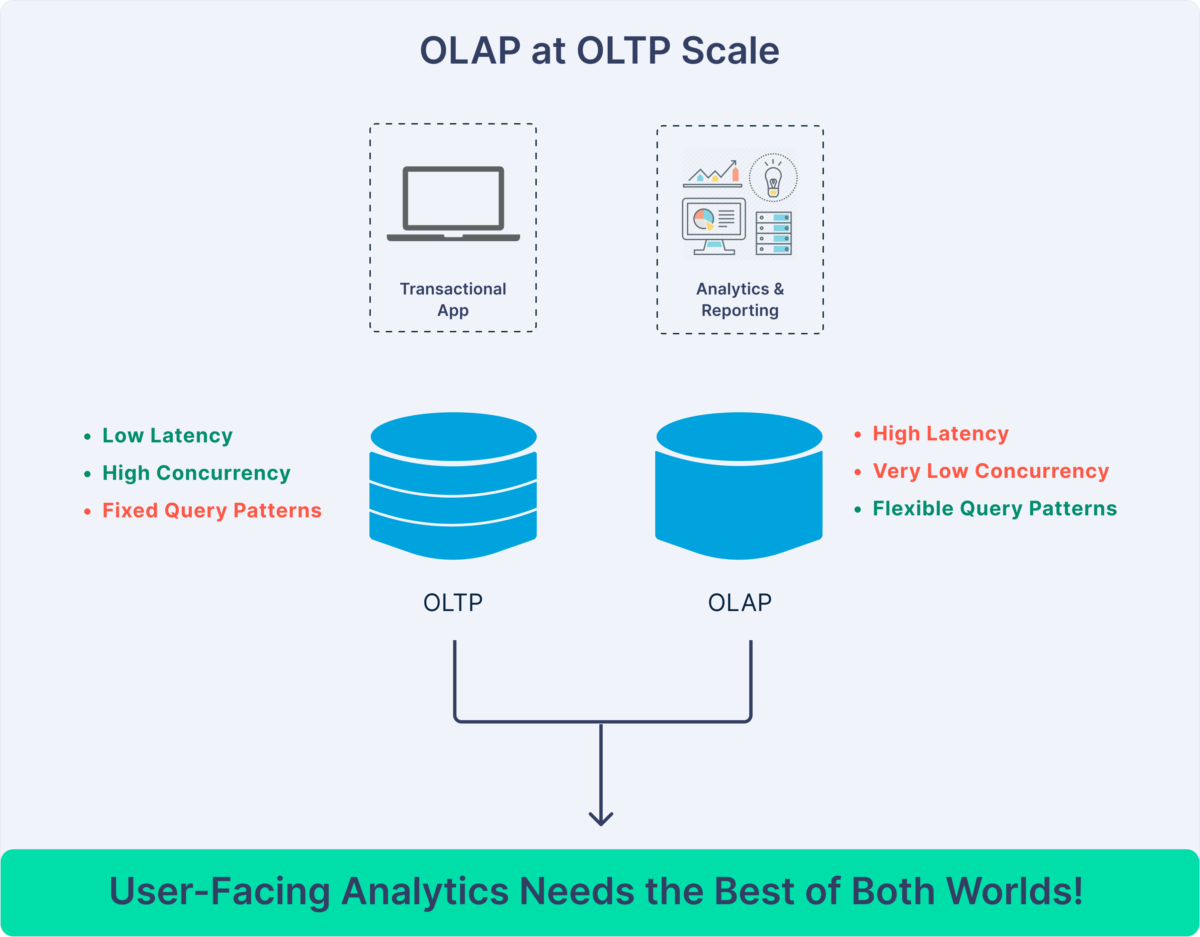
OLAP and OLTP are built differently, for different purposes…and yet elements of each are needed for the kinds of user-facing applications that LinkedIn is running. And as other organizations are realizing the power of real-time analytics, they too need a solution that has elements of both.
So here is the challenge for today’s databases, particularly those that are providing user-facing analytics at any kind of scale:
How does one achieve OLAP functionality at OLTP scale?
In other words, how does one retain the ability to slice and dice data in whatever ways are demanded by complex queries, while still serving millions of concurrent users at millisecond latency?
Maintaining Latency at High Throughput
Why has this only become a challenge recently? And why are current approaches not proving adequate to meet this challenge?
Let’s look at latency for queries first. For most traditional OLAP systems, latency does not become an issue because throughput is relatively low. This happens when looking at “inward-facing” analytics—that is, analytics that are being accessed by only a handful of analysts on an internal team. In such a scenario there are relatively few concurrent connections at any given instant, and the users are fairly tolerant of queries that take some time to run. Between these two factors (few connections and greater user patience), query latency is much less of a factor.
Now shift our example from a handful of users, querying via a dashboard or SQL editor at hundreds of qps (queries per second), to a situation with millions of potential users and hundreds of thousands of qps. This is where existing systems would begin to buckle, introducing latencies that are many seconds long (instead of milliseconds). The delay is noticeable and could lead users to abandon the tool. Getting those latency times back down with that number of concurrent users becomes prohibitively expensive with traditional technology. For example, in our story about Pinot at LinkedIn, we described how hundreds of nodes had to be added just to maintain SLAs at this kind of scale. In general, the number of nodes needed faces a combinatorial explosion as the number of concurrent users increases. That kind of increase just is not sustainable as a system scales.

What about traditional OLTP systems? True, these kinds of databases are built to handle a high volume of transactions concurrently. However, they can only handle simple queries and are not built with analytics in mind. Using them for analytics would necessitate creating a new model of the data every time a new unique query was made. Again, this would become cumbersome and expensive very quickly.
A Growing Challenge for Big Brands
Here, LinkedIn was used as just one well-known example of the challenge of getting real-time analytics at scale. The challenge, however, is general. As the number of users and the number of queries grows for an analytics application, latencies will grow, too. Keeping those in check becomes costly and, eventually, unsustainable. Any solution that rises to the challenge will need to have OLAP functionality at OLTP speed and scale.
In our next piece, we’ll take a look at how existing solutions (pre-aggregate, pre-cube, etc.) tried to tackle some part of this challenge, and how it was ultimately overcome with a flexible tool (Pinot).
