
Background
Apache Pinot is a blazingly fast OLAP system that has become popular in the open source community. It provides a convenient way to “pull” data from various sources like streaming systems (Kafka, Kinesis, PubSub), batch systems (S3, GCS, HDFS) and also integrates well with frameworks such as Flink and Spark.
Startree is excited to introduce a brand new WriteAPI feature in Pinot to further simplify the Pinot data ingestion. Users can now “push” data into a Pinot cluster by simply issuing an HTTP POST request to an endpoint.
WriteAPI: A Push Based Data Ingestion Interface
Currently, Pinot real time table adopts a pull model to fetch data and generate segments for it. The real time table reads from a streaming source like Kafka/PubSub. These techniques work very well and they are the preferred methods for doing analytics at scale. However, in some scenarios, users might prefer a simpler way of pushing data into Pinot.
For example with the Pinot real time table, the user needs to go through the process of creating a Streaming Producer (for writing data into a stream) before seeing the data in the Pinot table. This may seem a simple task for experienced programmers, but there are many cases where we would love the capability to do a simple curl command to POST data into a Pinot table or run the standard SQL INSERT command to generate data.
With the brand new WriteAPI feature, below is one simple example of producing into a Pinot table “airline_stats” from the Pinot QuickStart example:
<span class="">curl -XPOST https://demo.startree.cloud/v1/write/airline_stats -H "Content-Type: application/json" -d '{
</span> "tableName": "airline_stats",
"data": [
{
"ActualElapsedTime": 20304,
"AirTime": 21904,
"AirlineID": "1000-1059",
"ArrDelayMinutes": 10
},
{
"ActualElapsedTime": 20104,
"AirTime": 20134,
"AirlineID": "1020-2032",
"ArrDelayMinutes": 8
}
]
}'Code language: HTML, XML (xml)This is a powerful abstraction and unlocks several great features:
- The Streaming Producer concept is abstracted away. This not only frees the users from the tedious work of dealing with Streaming Producers but also provides the isolation needed for an Admin to modify Pinot real time tables in cases like data center migration.
- Provides immediate schema validation feedback for the data payload posted. The user can know immediately whether the data is correctly formatted or not. This short feedback will save lots of development time for the user
WriteAPI Design: Workflow and Architecture
Under the hood, we introduced a few new REST endpoints so the Administrators can set up the WriteAPI easily, and the users can also POST into the Pinot table with a simple JSON payload, without any knowledge of how the data arrives into Pinot.
Below is a diagram of the typical workflow of how WriteAPI works for each table.
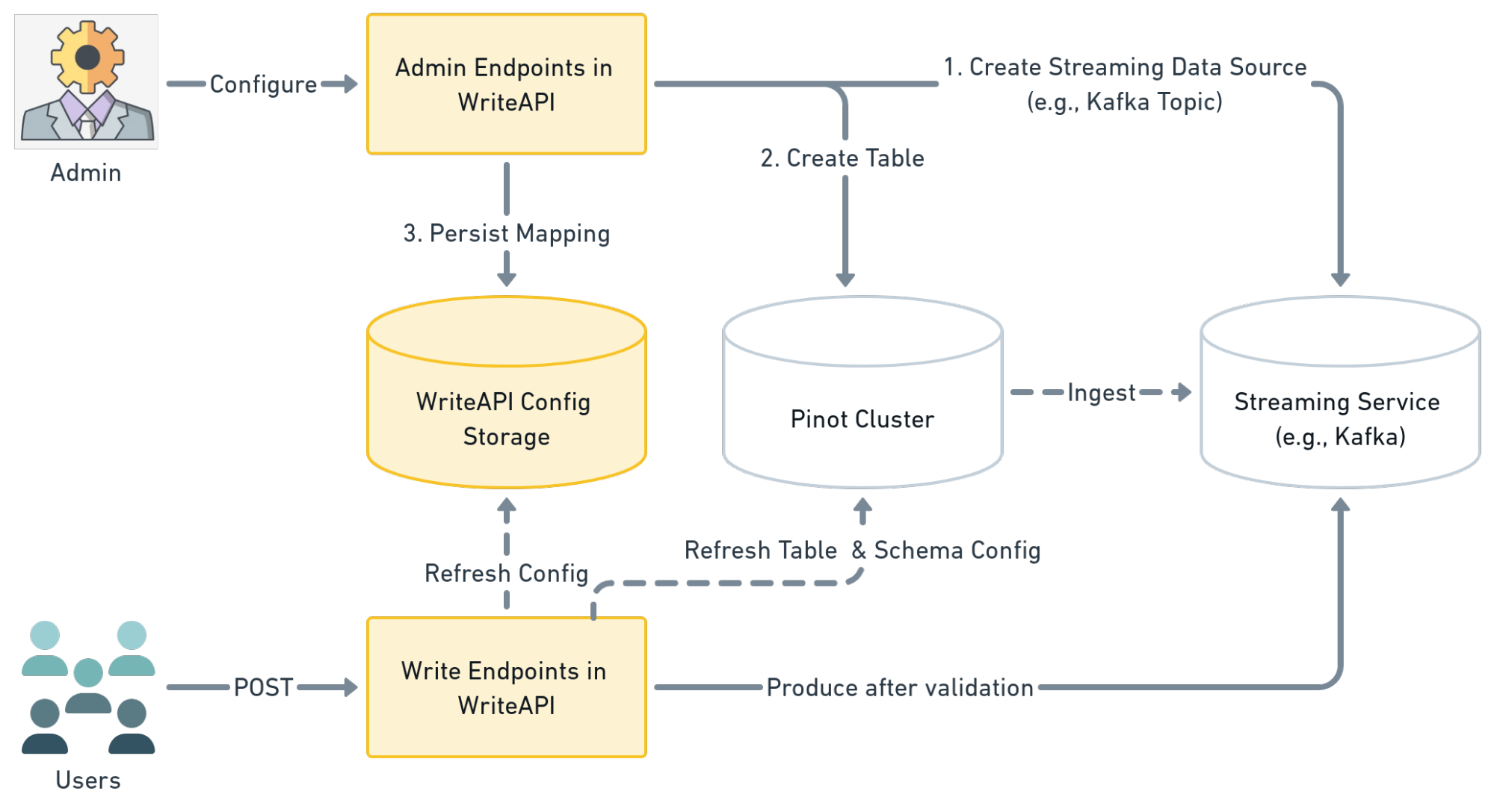
As shown in the above diagram, before a table can be written by the user, the Admin needs to configure each Pinot table first. The configuration task is done inside a WriteAPI Admin endpoint; it performs administrative tasks like creating Kafka topic, Pinot real time table, and finally writes the configuration into a storage for other WriteAPI endpoints. Such admin calls can be easily templated and automated in a production environment.
Later the user can do a plain simple HTTP POST into the WriteAPI endpoint to write data. The WriteAPI endpoint will keep a local cache of all necessary configurations, perform validation on the data, and then write the data into Streaming Service.
It is worth pointing out that currently WriteAPI still relies on Kafka Producer to deliver data into Pinot real time tables. With the abstraction of WriteAPI, it is possible to switch to any streaming data source. In the future, we will implement this natively in Pinot which removes any dependency on external systems.
Regarding architecture of WriteAPI, in a nutshell WriteAPI is a microservice that can be deployed standalone, or can be hosted as a plugin inside Pinot Broker or Pinot Controller. Below is the diagram of the relationship between components of WriteAPI and Pinot:
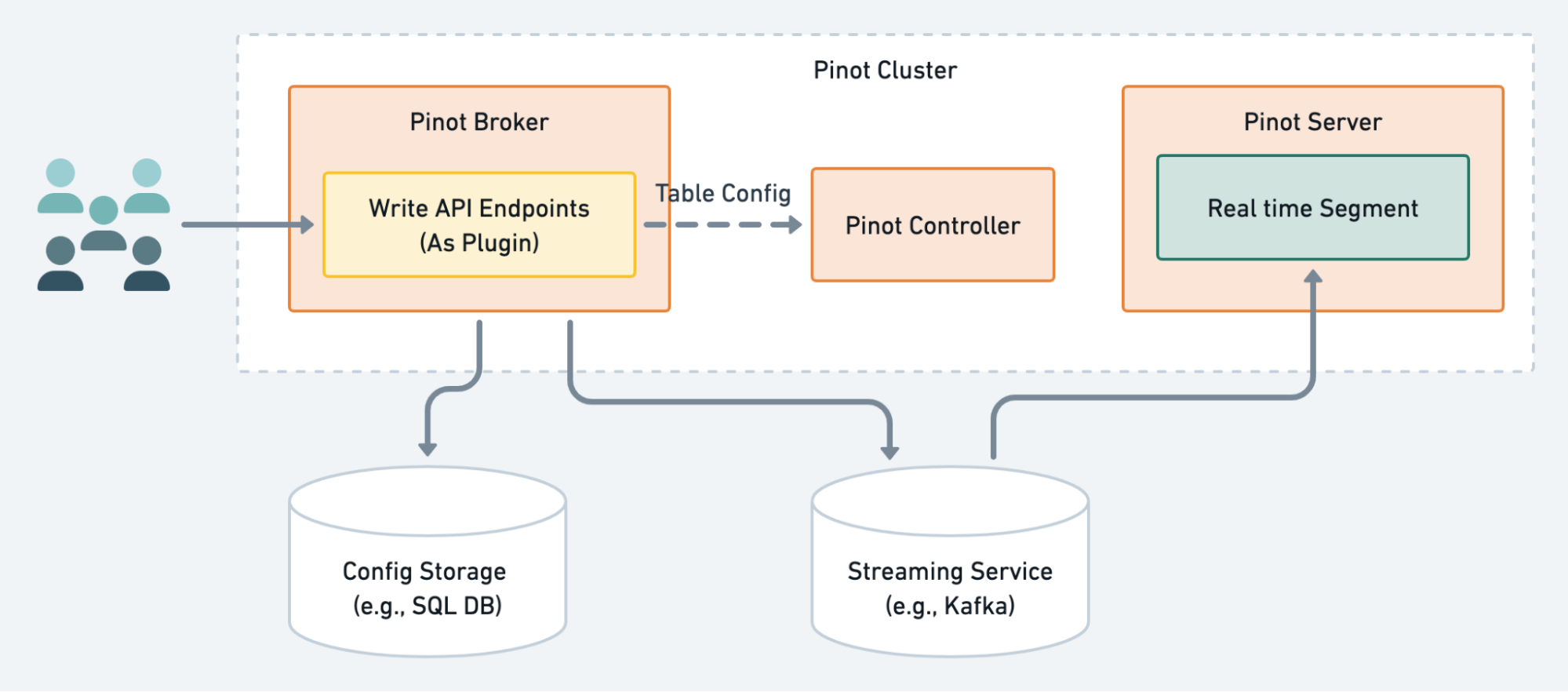
Internally, WriteAPI follows layered extensible design principles. Endpoints depend on configurable modules, while WriteAPI can be configured and extended to rely on different storage or streaming services freely.
Challenges
This section covers the different challenges we had to overcome for implementing WriteAPI.
Data Validation in Endpoint
Currently, in Pinot real time table, the data transformation and validation are done during real time ingestion. When the user writes into the streaming source (e.g., Kafka Topic), the user will only know the validation result when the Pinot real time table reads from it.
With WriteAPI, we have decided to implement/re-use the same transformation and validation logic inside the write endpoints. Although this introduces extra overhead in the endpoints, it provides the following benefits:
- At-least-once processing with 100% durability guarantee: If we return 200 (OK) to the user, the user can know for sure that data will show up.
- All-or-nothing ingestion for a batch of data rows: if there is one row broken, abandon the whole batch.
- Exactly-once delivery into Pinot table: this is an exciting mechanism that we will discuss in detail in our next blog.
Eventual Consistency Model
WriteAPI provides eventual consistency. Once the user receives ‘Status OK’ for a write request, data is guaranteed to be queryable via Pinot, albeit with a small delay.
This consistency model is not as strong as the “read-after-write” model, and it is due to the delivery mechanism by a streaming service. In the future, if we implement the direct write into Pinot segments, we can improve the consistency level of our model.
Try It Out !
WriteAPI is now available as part of StarTree Cloud (soon to be open sourced in Apache Pinot). Please get in touch with us if you like to take this for a spin!
Future Work
With the WriteAPI in place, there are many exciting things to come:
- Open source the WriteAPI modules so it will be available for the whole Pinot community.
- Design the INSERT INTO SQL statement feature so the users will be able to write into Pinot in SQL consoles like Presto cli.
- Design and implementation a native WriteAPI design without a streaming service in the middle.
We’d love to hear from you
Here are some ways to get in touch with us!
You can get in touch with StarTree by contacting us through our website. We encourage you to Book a Demo or contact us for a free trial.
New to Apache Pinot? Here are some great resources to help you get started. You can find our documentation here, join our community Slack channel, or engage with us on Twitter at StarTree and ApachePinot.