
Note: With the release of Apache Pinot 1.0 on Sept. 19th, 2023, the multi-stage query engine is functionally complete, and now offer users a wider range of possible ways to gain insights from their data. Read the updated blog here .
Apache Pinot™ is a blazingly fast OLAP system. One of the many reasons why Apache Pinot is so fast is its highly-optimized query execution engine. However, this query execution engine follows a single-stage scatter-gather model, which poses some limitations in supporting complex multi-stage queries, such as distributed joins and window operations. As the popularity of Apache Pinot grew over the past few years, there have been a growing number of requests from the community to handle these complex queries in Pinot.
Today, we are excited to introduce a new feature preview for Apache Pinot – the multi-stage query execution engine! This new query engine enables Pinot to support distributed joins, windowing, and other multi-stage operators in real time.
Current Query Execution Model
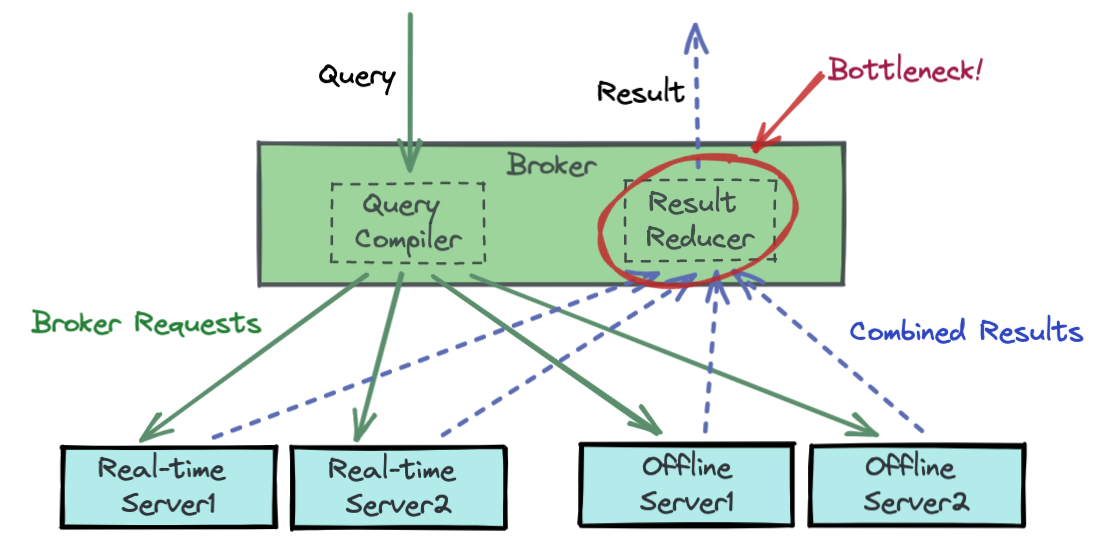
Apache Pinot has a distributed architecture that consists of the following components:
- Servers to host columnar data and execute queries on it
- Controllers to coordinate cluster operations
- Brokers for query execution
You can learn more about the architecture and components in the documentation.
When the Pinot broker receives a query, it gets distributed directly to Pinot servers that host the segment data. Each such server then executes the query locally. Finally, the broker merges the results from all servers. For typical analytical queries such as high-selectivity filters and low-cardinality aggregations, this is a very efficient process. However, for queries that require data shuffling, such as join operations, a lot of the computation needs to be performed on the Pinot broker, effectively making it the bottleneck.
Multi-stage Execution model
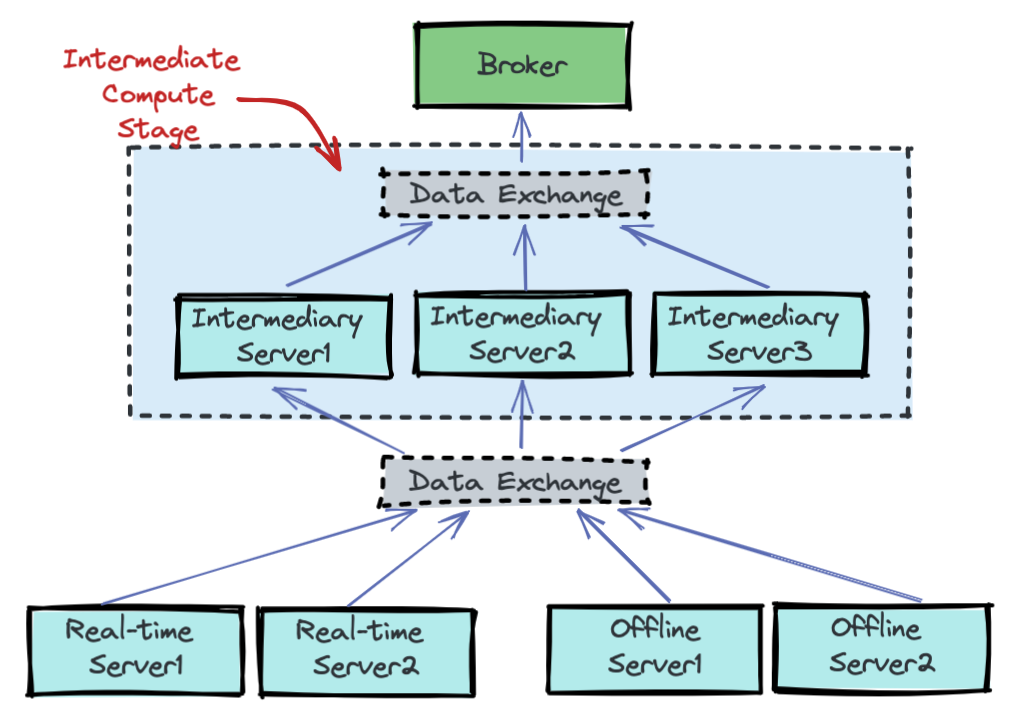
The new multi-stage execution model is designed to address the bottleneck mentioned above.
As part of the multi-stage execution model, we introduced a new intermediate compute stage in Pinot to handle the additional processing requirements and offload the computation from the brokers. The intermediate compute stage consists of a set of processing servers and a data exchange mechanism.
- Processing Servers: The role of processing servers in the intermediate compute stage can be assigned to any Pinot component, however, in the initial version we are leveraging the Pinot servers for this. There could be multiple servers processing data in the intermediate stage. Each server in the intermediate stage executes the same processing logic, but against different sets of data.
- Data Exchange Service: The data exchange service coordinates the transfer of the different sets of data to and from the processing servers.
With the new multi-stage query execution model, we also introduced a new query plan optimizer to produce the optimal process logic on each stage and to minimize data shuffling overhead. We will dive into the details in the “Implementation Challenges” section.
Join Query Example
With a multi-stage query engine, Pinot first needs to break down the single scatter-gather query plan into multiple query sub-plans that run across different sets of servers. We call these sub-plans “stage plans” and thus each execution is called a “stage.”
Let’s use a distributed JOIN query example to illustrate the breakdown of a query into stages. Consider the following join query where you want to join a real-time orderStatus table with an offline customer table:
<span class="">SELECT
</span> os.uid, -- user ID
os.rName, -- restaurant Name
c.ltv -- life-time value
FROM
orderStatus AS os
INNER JOIN customer AS c
ON os.uid = c.uid
WHERE
os.ic < 10 -- item count
AND c.lto > 5 –- life-time order countCode language: SQL (Structured Query Language) (sql)Once the query is received by the multi-stage query engine broker, it will be broken down into three stages, each with its sub-plan SQL as follows:
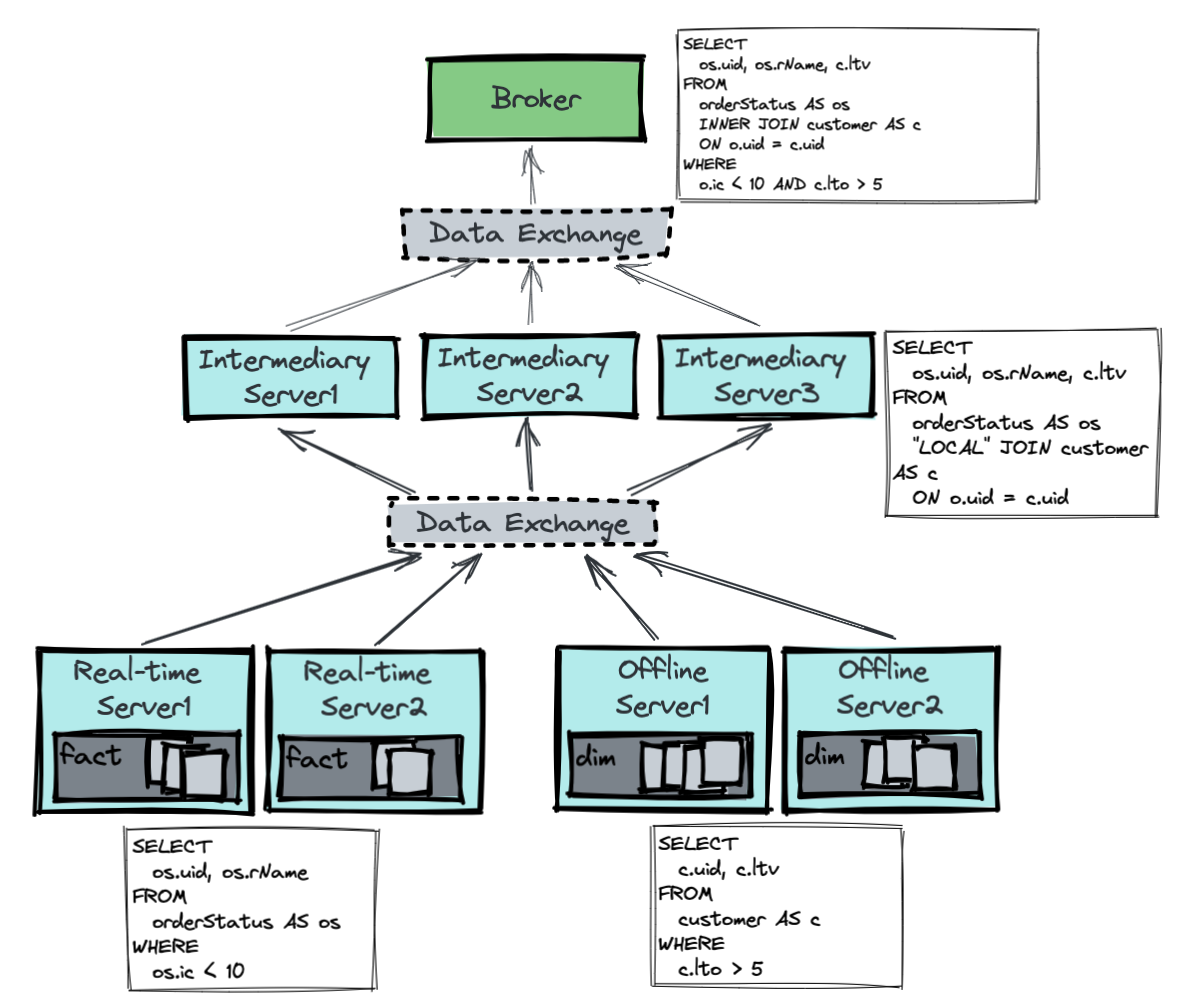
Stage 1
In the first stage,
- the real-time servers execute the filter query on the real-time orderStatus table:
SELECT os.uid, os.rName FROM orderStatus AS os WHERE os.ic < 10Code language: CSS (css)- the offline servers execute the filter query offline customer table:
SELECT c.uid c.ltv FROM customer AS c WHERE c.lto > 5Code language: CSS (css)The data exchange service is responsible for doing a data shuffle, such that all data with the same unique customer ID will get funneled into the same processing server for the next stage.
Let’s visualize the process in the image below. For simplicity, let’s assume there are only three unique customers (1, 2, 3) on the partition uid column in both tables and each uid is assigned to one of the three intermediate servers.
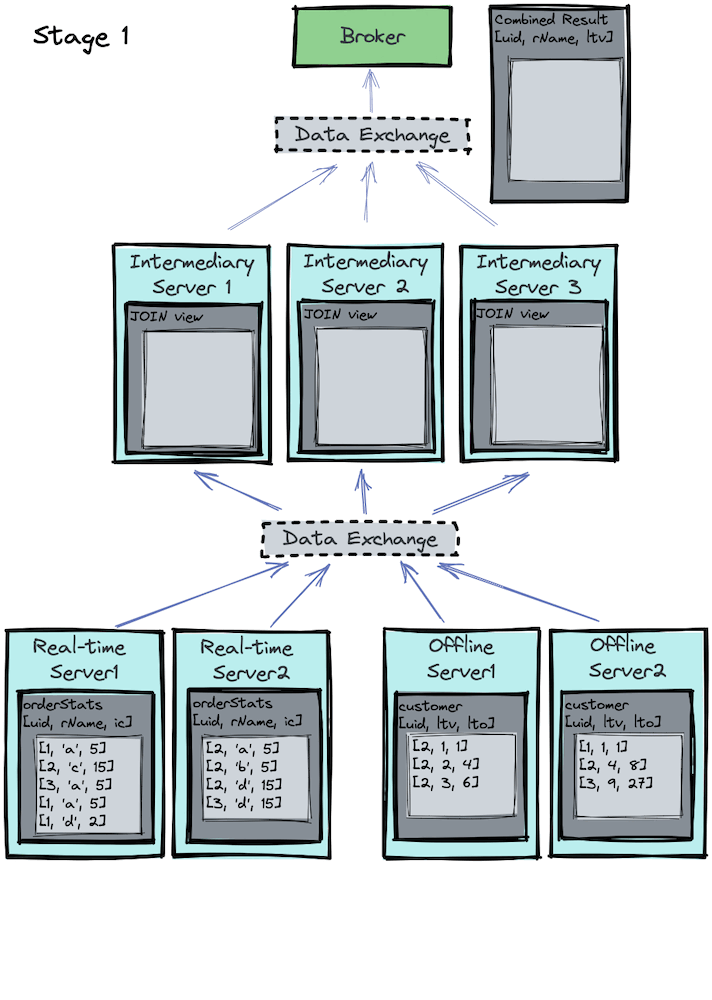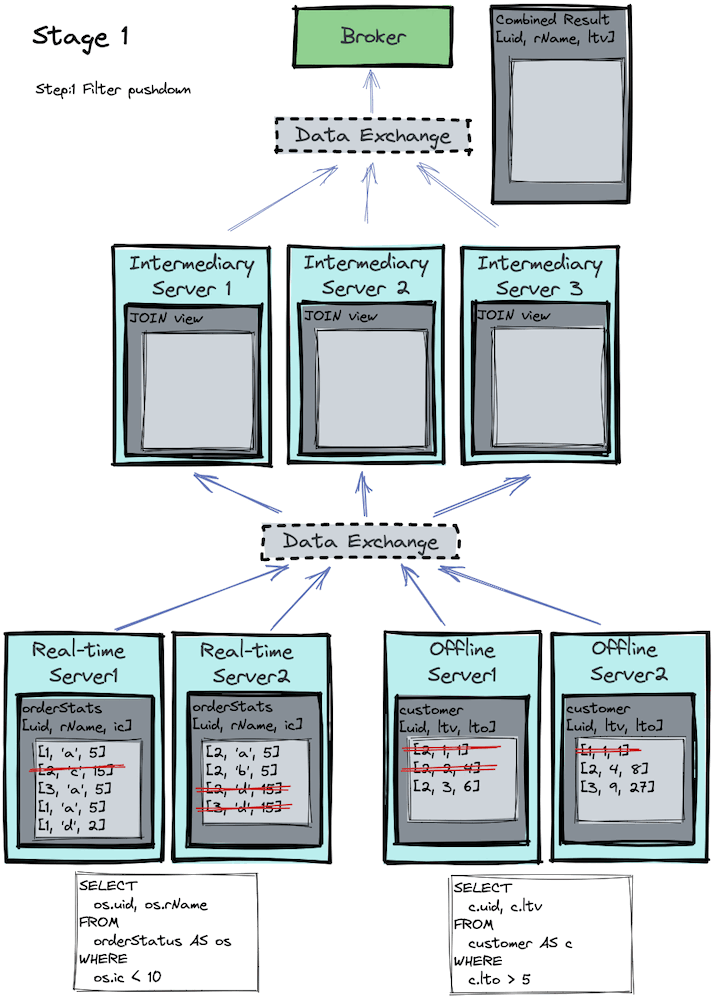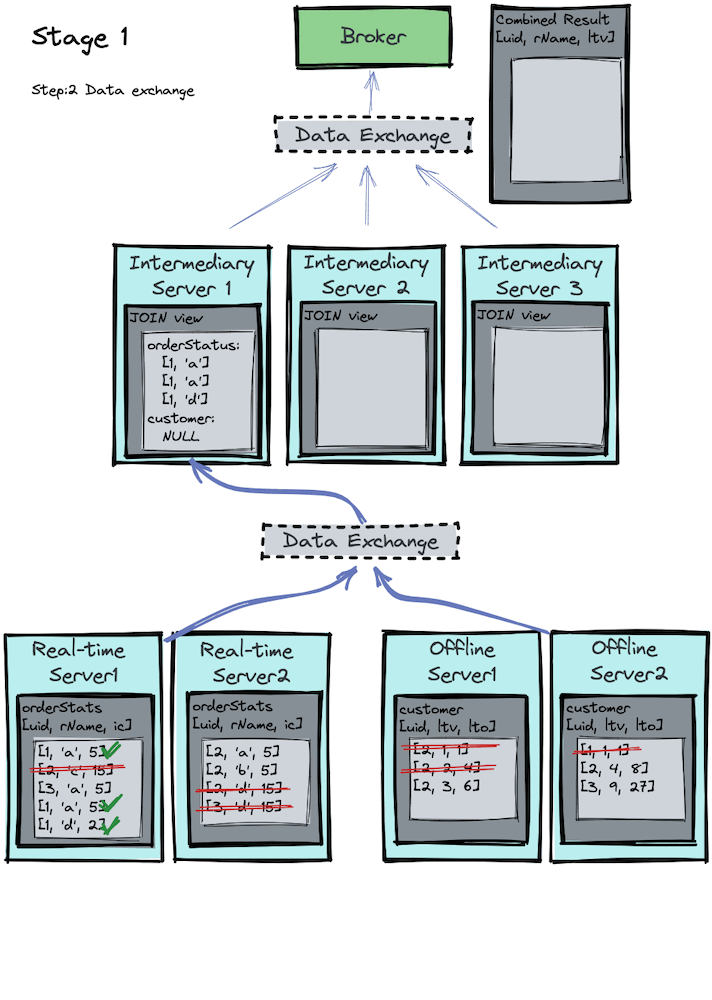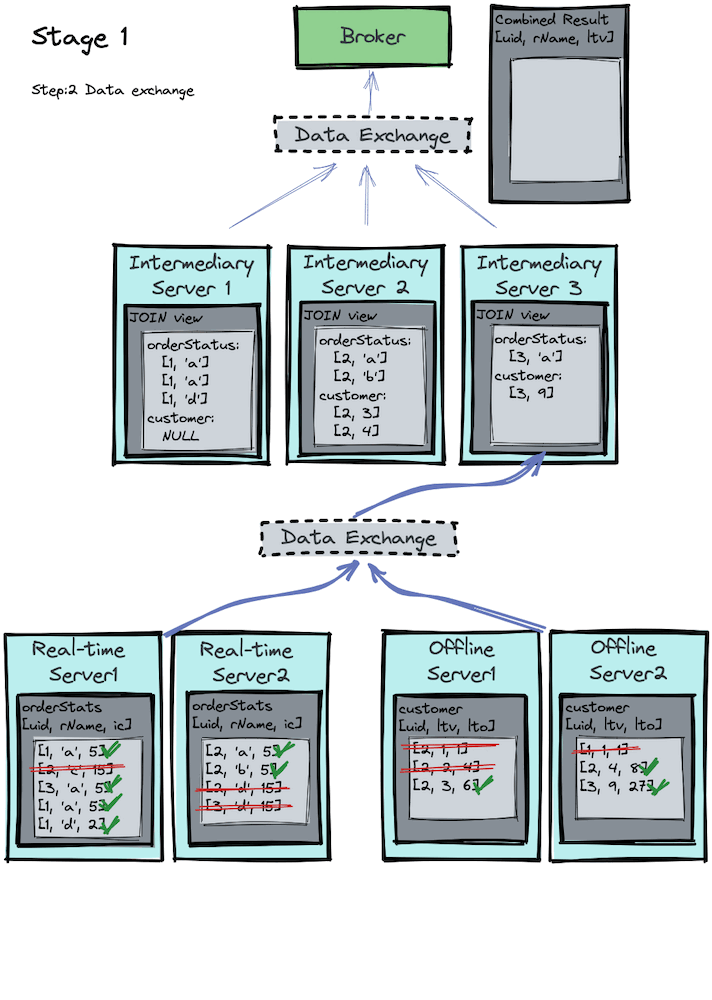
Stage 2
Now that proper data shuffling has been done in stage 1, an inner join can be performed locally on each processing server for stage 2. Let’s visualize the process in the image below:
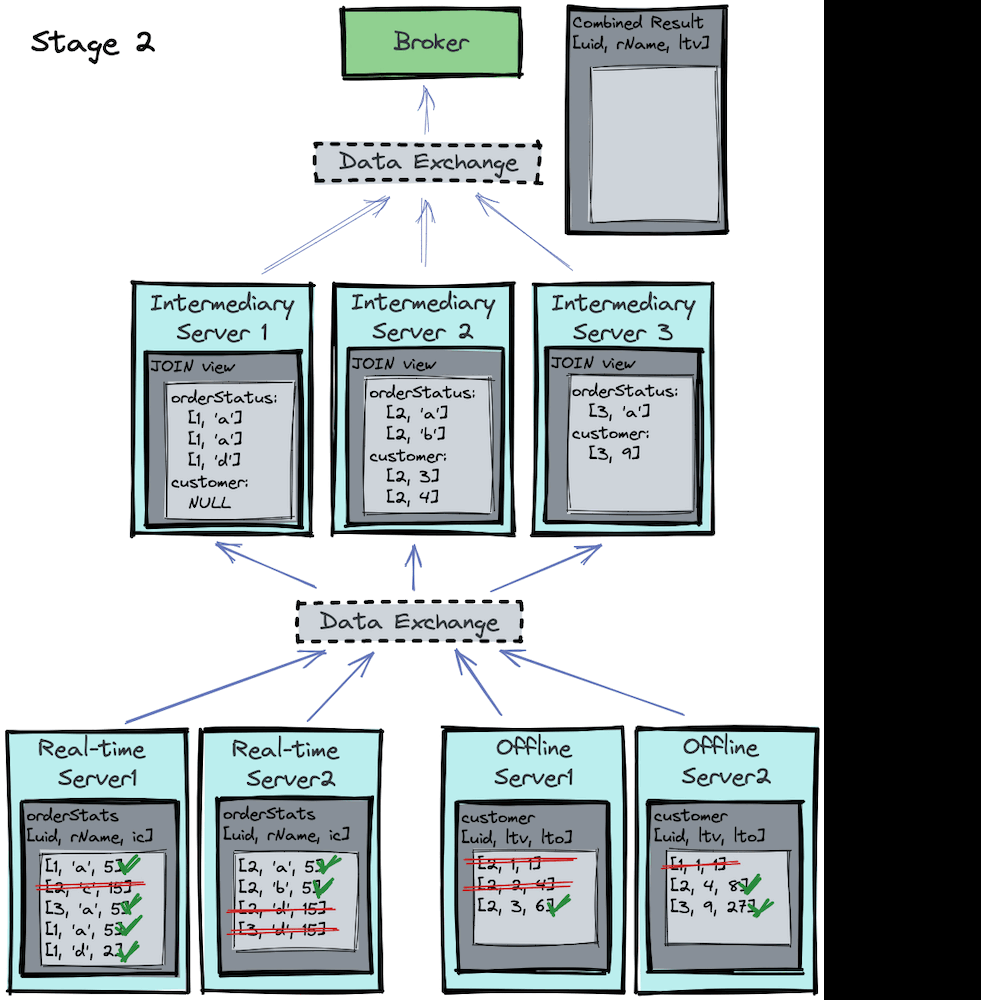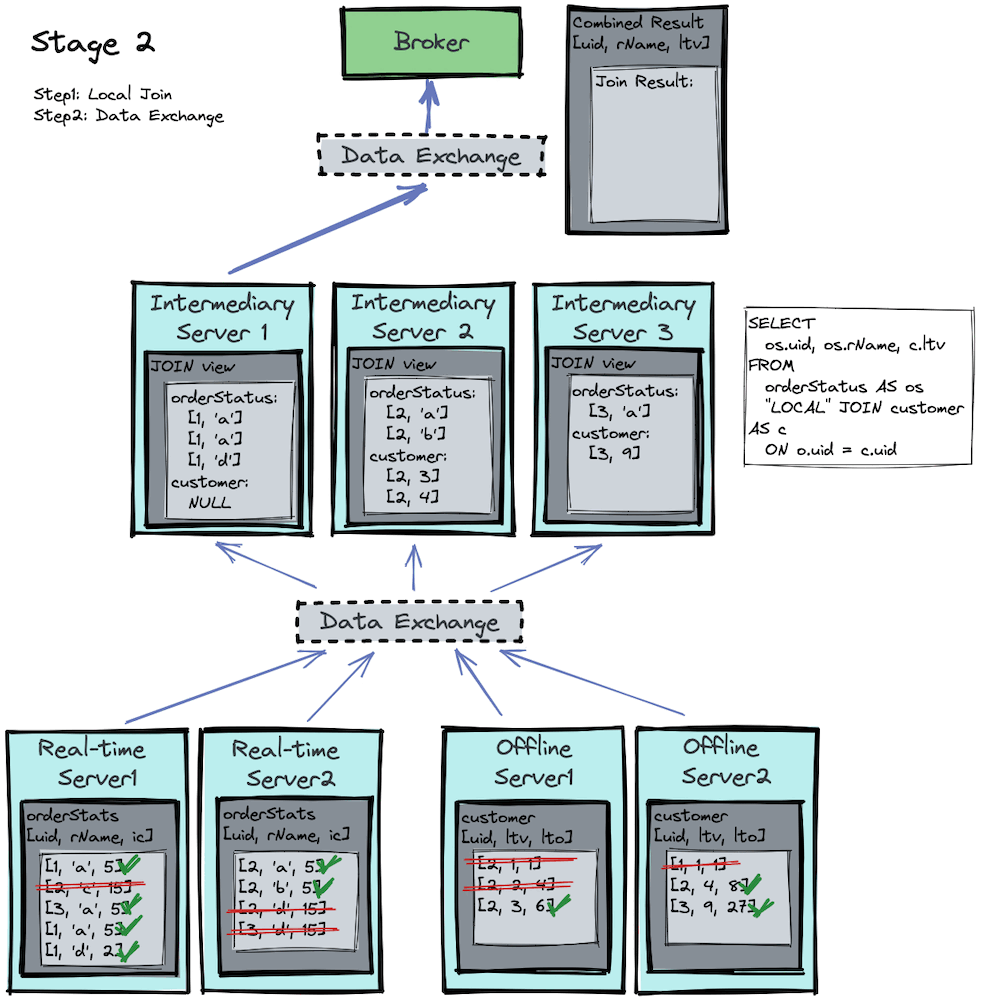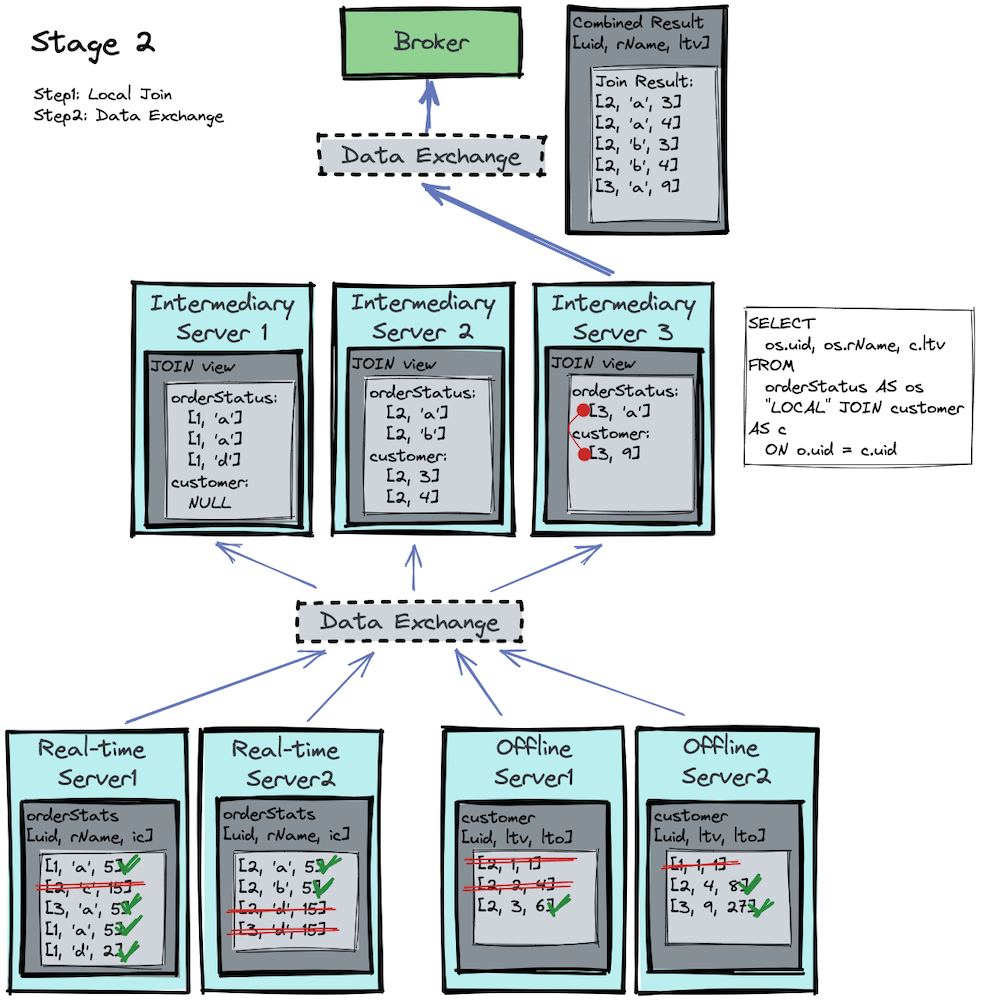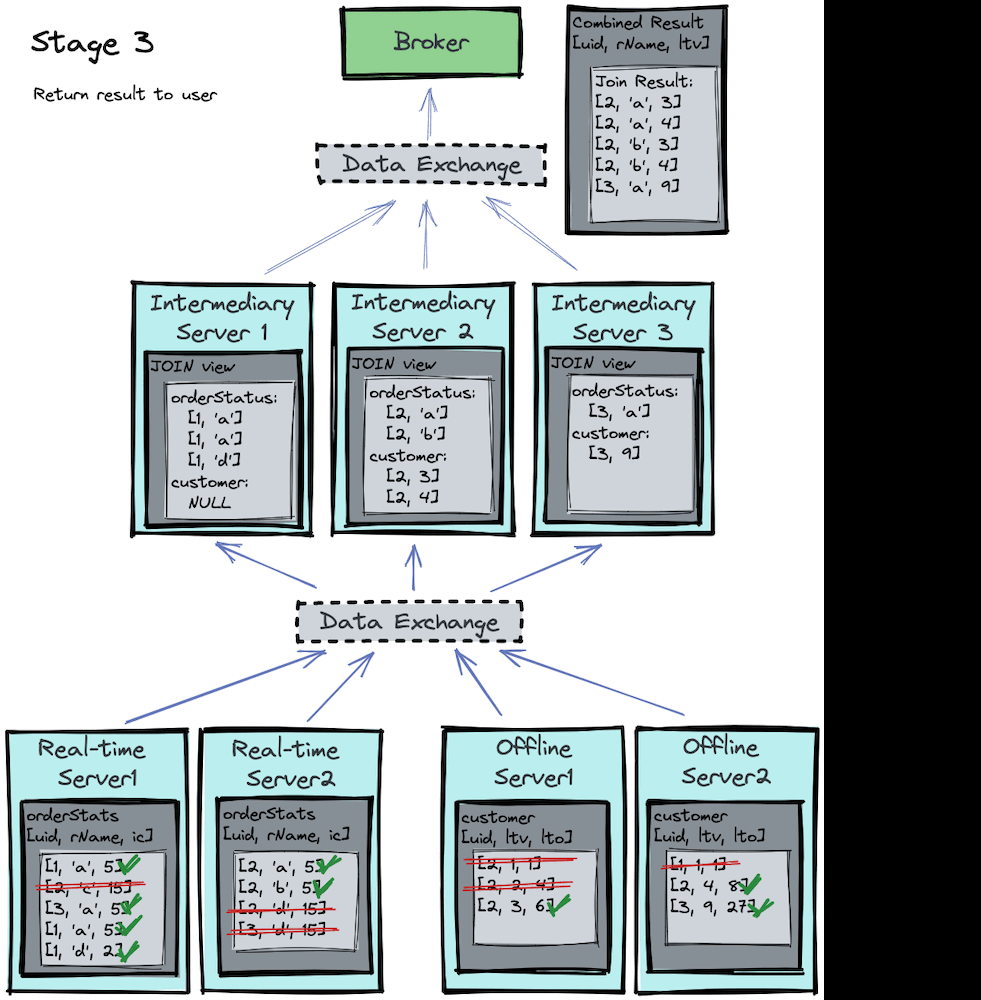
If you focus on the intermediary servers, you’ll notice that each intermediary server
- performs a local join, and
- runs the same join algorithm, but on different
uids.
Stage 3
Finally, in the third stage, after the join algorithm completes, the results are sent back to the broker and then served to the end-users. This stage is identical to the current Pinot broker behavior.
Challenges of Multi-stage Execution
With the data exchange service and intermediary servers, we successfully unlocked multi-stage queries for Apache Pinot. However, with this, the end-user latency now includes not only the query execution time but also the data exchange time and query planner time. We were determined to ensure that the multi-stage queries also run with low latency and can be used in real-time, user-facing analytical applications.
Fast data exchange
As described above, one of our challenges was to ensure that our data exchange mechanism is very fast. To tackle this, we introduced a long-lasting GRPC channel between each pair of communicating servers, as the backbone of the data exchange service. The channels are managed by a “mailbox service” within the communicating servers. The mailbox service works very similarly to your local post office:
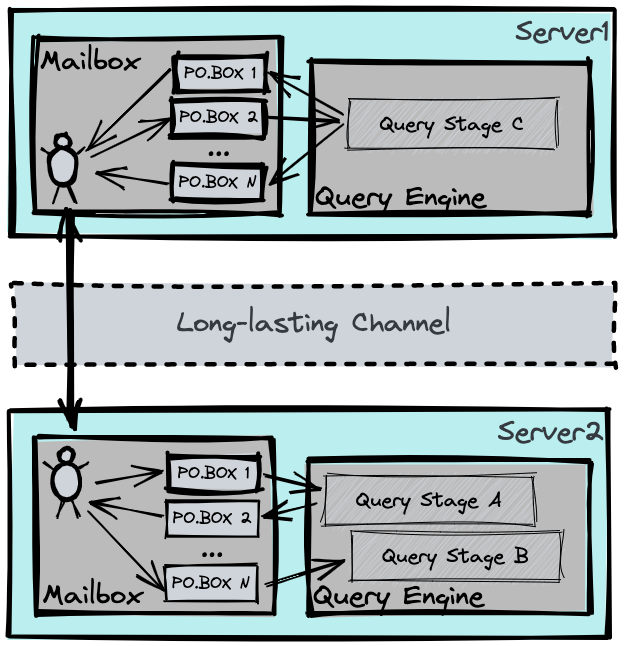
- At the source server, a “mailman” decodes the message from each “PO.BOX” then uses the long-lasting channel to send data, or “mails”, to the destination server;
- At the destination server, another “mailman” dispatches incoming mail to the corresponding “PO.BOX”.
For the multi-stage query engine, sending/receiving data is simply using a PO.BOX in the local post office, thus decoupling the data exchange layer and the query engine layer.
Planner optimization vs speed trade-off
Our next challenge was to ensure the query planner is also fast. When executing a multi-stage query planner, there’s the trade-off between faster-planning speed vs. a more optimized query plan – if the planner runs very fast, it might not give the best performing query plan; on the other hand, if the planner attempts all possible optimization techniques, it could take even longer than executing a sub-optimal query plan.
In a traditional query planner setup, all metadata such as distributed table statistics, data distribution, etc. are transferred to a central planner for execution. This setup works well in long-running query engines. However, we decided against following a similar approach in Pinot, because the network round-trip overhead would add an unacceptable amount of latency to the query.
Here, we made a trade-off by deciding to run a two-step planner:
- Queries are processed by the “stage-planner” in the Broker to generate the collection of stage plans, which are an intermediary logical plan format. The stage plans are then transferred to the servers.
- The stage plans then run through a physical planner on the server, where table/segment metadata resides, to optimize and convert into the final executable format.
What’s Next?
The new multi-stage query engine enables Pinot to run complex SQL queries that were never possible before while still retaining Pinot’s blazing fast query execution performance. As of today, this new engine is still in the beta phase. But it already unlocks the following:
- Generic multi-stage query execution with data shuffling.
- Support for distributed join algorithms.
It is available for trial as part of an early release feature branch. Please follow the instruction on this PR to try it yourself on local environment.
We are also expanding support to a list of advanced features. To name a few:
- Support for full ANSI SQL syntax
- Tuning knobs for query planner optimization, such as cost-based and metadata-based query planning
- Fine-tuned performance optimization
Please stay tuned!
We’d love to hear from you
The best way to explore the Multi-stage query engine is to try Apache Pinot on StarTree Cloud. Book a Demo or contact us for a free trial.
