
The Apache Pinot community recently released version 0.11.0, which has lots of goodies for you to play with.
In this post, we will learn about a feature that lets you pause and resume real-time data ingestion. Sajjad Moradi has also written a blog post about this feature, so you can treat this post as a complement to that one.
How does real-time ingestion work?
Before we get into this feature, let’s first recap how real-time ingestion works.
This only applies to tables that have the REALTIME type. These tables
ingest data that comes in from a streaming platform (e.g., Kafka).
Pinot servers ingest rows into consuming segments that reside in volatile memory.
Once a segment reaches the segment threshold, it will be persisted to disk as a completed segment , and a new consuming segment will be created. This new segment takes over the ingestion of new events from the streaming platform.
The diagram below shows what things might look like when we’re ingesting data from a Kafka topic that has 3 partitions:
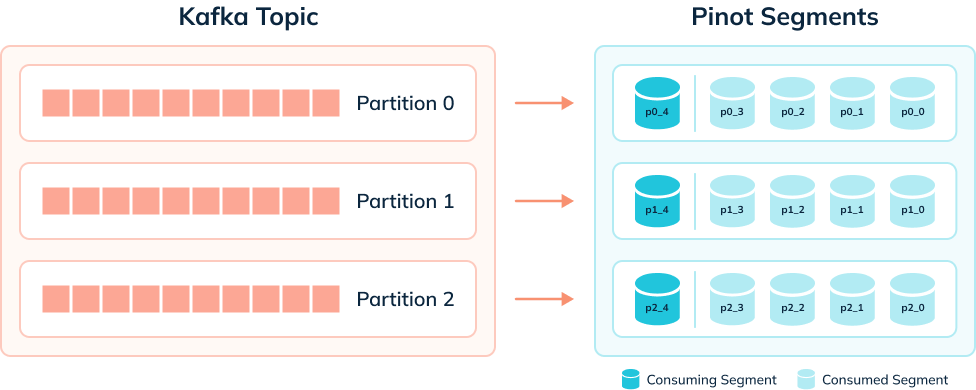
A table has one consuming segment per partition but would have many completed segments.
Why do we need to pause and resume ingestion?
There are many reasons why you might want to pause and resume ingestion of a stream. Some of the common ones are described below:
- There’s a problem with the underlying stream, and we need to restart the server, reset offsets, or recreate a topic
- We want to ingest data from different streams into the same table.
- We made a mistake in our ingestion config in Pinot, and it’s now throwing exceptions and isn’t able to ingest any more data.
The 0.11 release adds the following REST API endpoints:
- /tables/{tableName}/pauseCompletion
- /tables/{tableName}/resumeCompletion
As the names suggest, these endpoints can be used to pause and resume streaming ingestion for a specific table.
This release also adds the /tables/{tableName}/pauseStatus endpoint, which returns the pause status for a table.
Let’s see how to use this functionality with help from a worked example.
Data Generation
Let’s imagine that we want to ingest events generated by the following Python script:
import datetime import uuid import random import json while True: ts = datetime.datetime.now().strftime("%Y-%m-%dT%H:%M:%S.%fZ") id = str(uuid.uuid4()) count = random.randint(0, 1000) print( json.dumps({"tsString": ts, "uuid": id, "count": count}) )Code language: JavaScript (javascript)We can view the data generated by this script by pasting the above code into a file called datagen.py and then running the following command:
python datagen.py 2>/dev/null | head -n3 | jq
We’ll see the following output:
{ "tsString": "2022-11-23T12:08:44.127481Z", "uuid": "e1c58795-a009-4e21-ae76-cdd66e090797", "count": 203 } { "tsString": "2022-11-23T12:08:44.127531Z", "uuid": "4eedce04-d995-4e99-82ab-6f836b35c580", "count": 216 } { "tsString": "2022-11-23T12:08:44.127550Z", "uuid": "6d72411b-55f5-4f9f-84e4-7c8c5c4581ff", "count": 721 }Code language: JSON / JSON with Comments (json)We’re going to pipe this data into a Kafka stream called ‘events’ like this:
python datagen.py | kcat -P -b localhost:9092 -t events
We’re not setting a key for these messages in Kafka for simplicity’s sake, but Robin Moffat has an excellent blog post that explains how to do it.
Pinot Schema/Table Config
We want to ingest this data into a Pinot table with the same name. Let’s first define a schema:
Schema:
{ "schemaName": "events", "dimensionFieldSpecs": [{"name": "uuid", "dataType": "STRING"}], "metricFieldSpecs": [{"name": "count", "dataType": "INT"}], "dateTimeFieldSpecs": [ { "name": "ts", "dataType": "TIMESTAMP", "format": "1:MILLISECONDS:EPOCH", "granularity": "1:MILLISECONDS" } ] }Code language: JSON / JSON with Comments (json)Note that the timestamp field is called ts and not tsString , as it is in the Kafka stream. We will transform the DateTime string value held in that field into a proper timestamp using a transformation function.
Our table config is described below:
{ "tableName":"events", "tableType":"REALTIME", "segmentsConfig":{ "timeColumnName":"ts", "schemaName":"events", "replication":"1", "replicasPerPartition":"1" }, "tableIndexConfig":{ "loadMode":"MMAP", "streamConfigs":{ "streamType":"kafka", "stream.kafka.topic.name":"events", "stream.kafka.broker.list":"kafka-pause-resume:9093", "stream.kafka.consumer.type":"lowlevel", "stream.kafka.consumer.prop.auto.offset.reset":"smallest", "stream.kafka.consumer.factory.class.name":"org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory", "stream.kafka.decoder.class.name":"org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder", } }, "ingestionConfig":{ "transformConfigs": [ { "columnName": "ts", "transformFunction": "FromDateTime(tsString, 'YYYY-MM-dd''T''HH:mm:ss.SS''Z''')" } ] }, "tenants":{}, "metadata":{} }Code language: JSON / JSON with Comments (json)Our transformation has a subtle error. The second parameter passed to the FromDateTime function describes the format of the DateTime string, which we defined as:
YYYY-MM-dd”T”HH:mm:ss.SS”Z”
But tsString has values in the following format:
2022-11-23T12:08:44.127550Z
i.e., we don’t have enough S values – there should be 5 rather than 2.
If we create the table using the following command:
docker run --network pause-resume -v $PWD/pinot/config:/config apachepinot/pinot:0.11.0-arm64 AddTable -schemaFile /config/schema.json -tableConfigFile /config/table.json -controllerHost pinot-controller-pause-resume -exec Code language: JavaScript (javascript)Pinot will immediately start trying to ingest data from Kafka, and it will throw a lot of exceptions that look like this:
java.lang.RuntimeException: Caught exception while executing function: fromDateTime(tsString,'YYYY-MM-dd'T'HH:mm:ss.SS'Z'') … Caused by: java.lang.IllegalStateException: Caught exception while invoking method: public static long org.apache.pinot.common.function.scalar.DateTimeFunctions.fromDateTime(java.lang.String,java.lang.String) with arguments: [2022-11-23T11:12:34.682504Z, YYYY-MM-dd'T'HH:mm:ss.SS'Z'] Code language: HTTP (http)At this point, we’d usually be stuck and would need to fix the transformation function and then restart the Pinot server. With the pause/resume feature, we can fix this problem without resorting to such drastic measures.
The Pause/Resume Flow
Instead, we can follow these steps:
- Pause ingestion for the table
- Fix the transformation function
- Resume ingestion
- Profit $$$
We can pause ingestion by running the following command:
curl -X POST "http://localhost:9000/tables/events/pauseConsumption" -H "accept: application/json"Code language: JavaScript (javascript)The response should be something like this:
{ "pauseFlag": true, "consumingSegments": [ "events__0__0__20221123T1106Z" ], "description": "Pause flag is set. Consuming segments are being committed. Use /pauseStatus endpoint in a few moments to check if all consuming segments have been committed." }Code language: JSON / JSON with Comments (json)Let’s follow the response’s advice and check the consuming segments status:
curl -X GET "http://localhost:9000/tables/events/pauseStatus" -H "accept: application/json"Code language: JavaScript (javascript)We’ll see the following response:
{ "pauseFlag": true, "consumingSegments": [] }Code language: JSON / JSON with Comments (json)So far, so good. Now we need to fix the table. We have a config, table-fixed.json, that contains a working transformation config. These are the lines of interest:
{ "ingestionConfig":{ "transformConfigs": [ { "columnName": "ts", "transformFunction": "FromDateTime(tsString, 'YYYY-MM-dd''T''HH:mm:ss.SSSSSS''Z''')" } ] } }Code language: JSON / JSON with Comments (json)We now have five S values rather than two, which should sort out our ingestion.
Update the table config:
curl -X PUT "http://localhost:9000/tables/events" -H "accept: application/json" -H "Content-Type: application/json" -d @pinot/config/table-fixed.jsonCode language: JavaScript (javascript)And then resume ingestion. You can pass in the query string parameter consumeFrom, which takes a value of smallest or largest . We’ll pass in smallest since no data has been consumed yet:
curl -X POST "http://localhost:9000/tables/events/resumeConsumption?consumeFrom=smallest" -H "accept: application/json"Code language: JavaScript (javascript)The response will be like this:
{ "pauseFlag": false, "consumingSegments": [], "description": "Pause flag is cleared. Consuming segments are being created. Use /pauseStatus endpoint in a few moments to double check." }Code language: JSON / JSON with Comments (json)Again, let’s check the consuming segments status:
curl -X GET "http://localhost:9000/tables/events/pauseStatus" -H "accept: application/json"Code language: JavaScript (javascript)This time we will see some consuming segments:
{ "pauseFlag": false, "consumingSegments": [ "events__0__22__20221123T1124Z" ] }Code language: JSON / JSON with Comments (json)Navigate to http://localhost:9000/#/query and click on the events table. You should see the following:
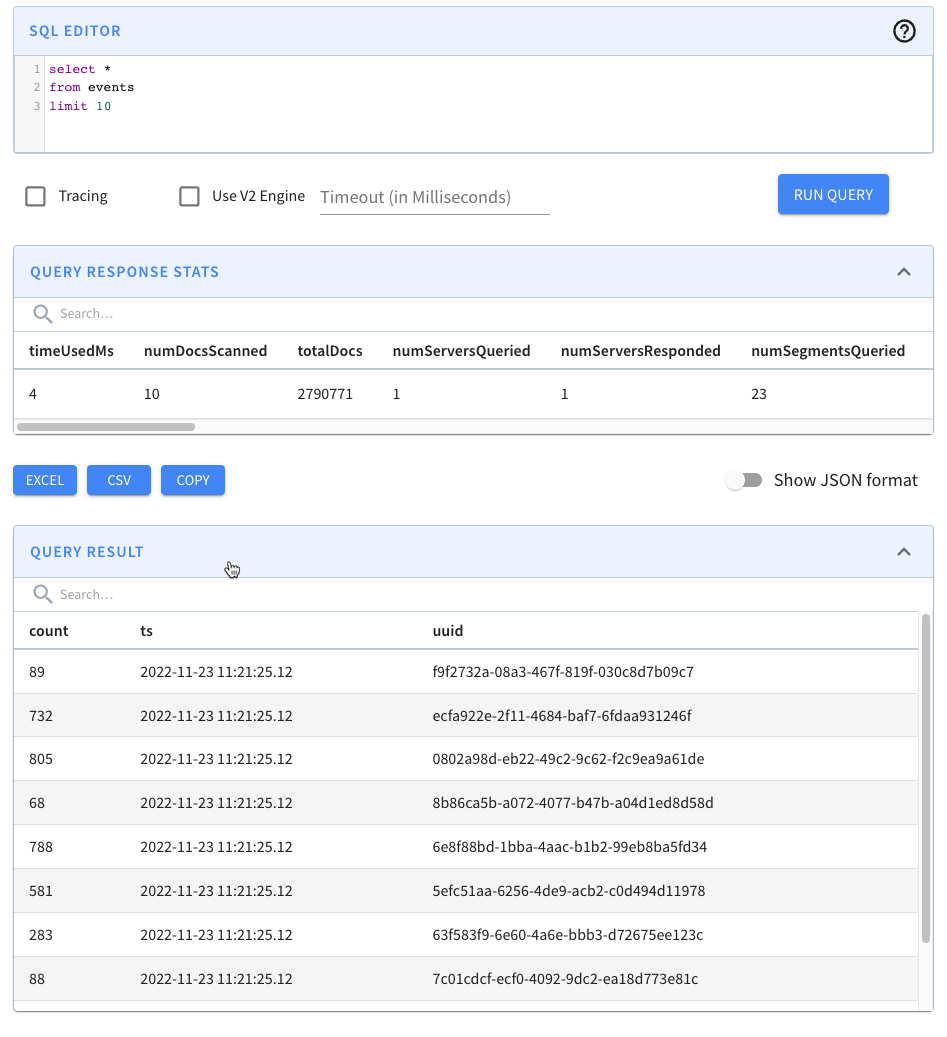
We have records! We can also run our data generator again, and more events will be ingested.
Summary
This feature makes real-time data ingestion a bit more forgiving when things go wrong, which has got to be a good thing in my book.
When you look at the name of this feature, it can seem a bit esoteric and perhaps not something that you’d want to use, but I think you’ll find it to be extremely useful.
So give it a try and let us know how you get on. If you have any questions about this feature, feel free to join us on Slack , where we’ll be happy to help you out.
