The Apache Pinot community recently released version 0.11.0, which has lots of goodies for you to play with. This is the second in a series of blog posts showing off some of the new features in this release.
In this post, we’re going to explore the INSERT INTO clause, which makes ingesting batch data into Pinot as easy as writing a SQL query.
Batch importing: The Job Specification
The power of this new clause is only fully appreciated if we look at what we had to do before it existed.
In the Batch Import JSON from Amazon S3 into Apache Pinot | StarTree Recipes video (and accompanying developer guide), we showed how to ingest data into Pinot from an S3 bucket.
The contents of that bucket are shown in the screenshot below:

Let’s quickly recap the steps that we had to do to import those files into Pinot. We have a table called events, which has the following schema:

We first created a job specification file, which contains a description of our import job. The job file is shown below:
executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: 's3://marks-st-cloud-bucket/events/'
includeFileNamePattern: 'glob:**/*.json'
outputDirURI: '/data'
overwriteOutput: true
pinotFSSpecs:
- scheme: s3
className: org.apache.pinot.plugin.filesystem.S3PinotFS
configs:
region: 'eu-west-2'
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS
recordReaderSpec:
dataFormat: 'json'
className: 'org.apache.pinot.plugin.inputformat.json.JSONRecordReader'
tableSpec:
tableName: 'events'
pinotClusterSpecs:
- controllerURI: 'http://${PINOT_CONTROLLER}:9000'Code language: JavaScript (javascript)At a high level, this file describes a batch import job that will ingest files from the S3 bucket at s3://marks-st-cloud-bucket/events/ where the files match the glob:**/*.json pattern.
We can import the data by running the following command from the terminal:
docker run
--network ingest-json-files-s3
-v $PWD/config:/config
-e AWS_ACCESS_KEY_ID=AKIARCOCT6DWLUB7F77Z
-e AWS_SECRET_ACCESS_KEY=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
apachepinot/pinot:0.11.0 LaunchDataIngestionJob
-jobSpecFile /config/job-spec.yml
-values PINOT_CONTROLLER=pinot-controllerCode language: PHP (php)And don’t worry, those credentials have already been deleted; I find it easier to understand what values go where if we use real values.
Once we’ve run this command, if we go to the Pinot UI at http://localhost:9000 and click through to the events table from the Query Console menu, we’ll see that the records have been imported, as shown in the screenshot below:
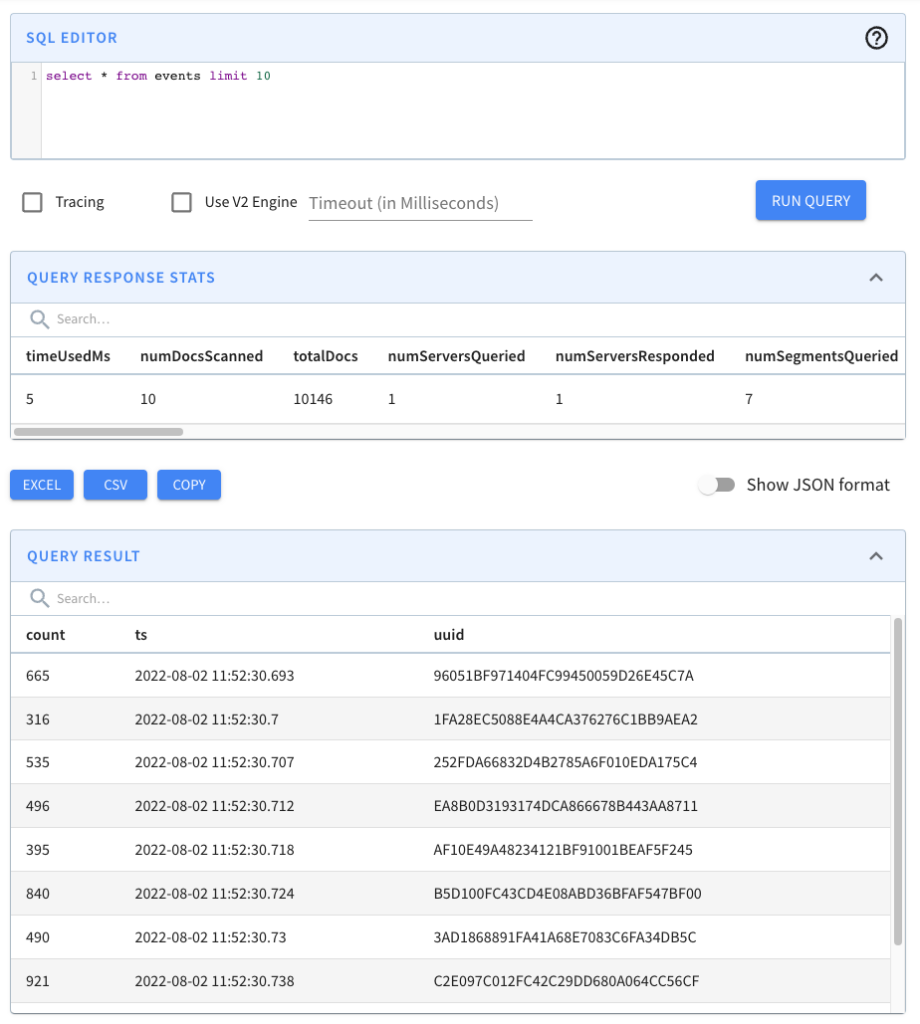
This approach works, and we may still prefer to use it when we need fine-grained control over the ingestion parameters, but it is a bit heavyweight for your everyday data import!
Batch Importing with SQL
Now let’s do the same thing in SQL.
There are some prerequisites to using the SQL approach, so let’s go through those now, so you don’t end up with a bunch of exceptions when you try this out!
First of all, you must have a Minion in the Pinot cluster, as this is the component that will do the data import.
You’ll also need to include the following in your table config:
"task": {
"taskTypeConfigsMap": { "SegmentGenerationAndPushTask": {} }
}Code language: JavaScript (javascript)As long as you’ve done those two things, we’re ready to write our import query! A query that imports JSON files from my S3 bucket is shown below:
INSERT INTO events
FROM FILE 's3://marks-st-cloud-bucket/events/'
OPTION(
taskName=events-task,
includeFileNamePattern=glob:**/*.json,
input.fs.className=org.apache.pinot.plugin.filesystem.S3PinotFS,
input.fs.prop.accessKey=AKIARCOCT6DWLUB7F77Z,
input.fs.prop.secretKey=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,
input.fs.prop.region=eu-west-2
);Code language: JavaScript (javascript)If we run this query, we’ll see the following output:
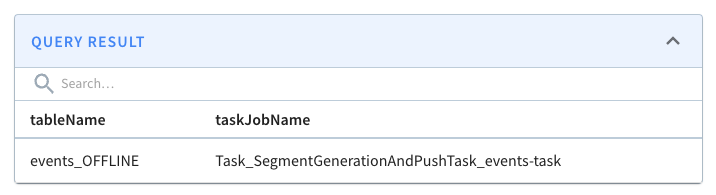
We can check on the state of the ingestion job via the Swagger REST API. If we navigate to http://localhost:9000/help#/Task/getTaskState, paste Task_SegmentGenerationAndPushTask_events-task as our task name, and then click Execute, we’ll see the following:
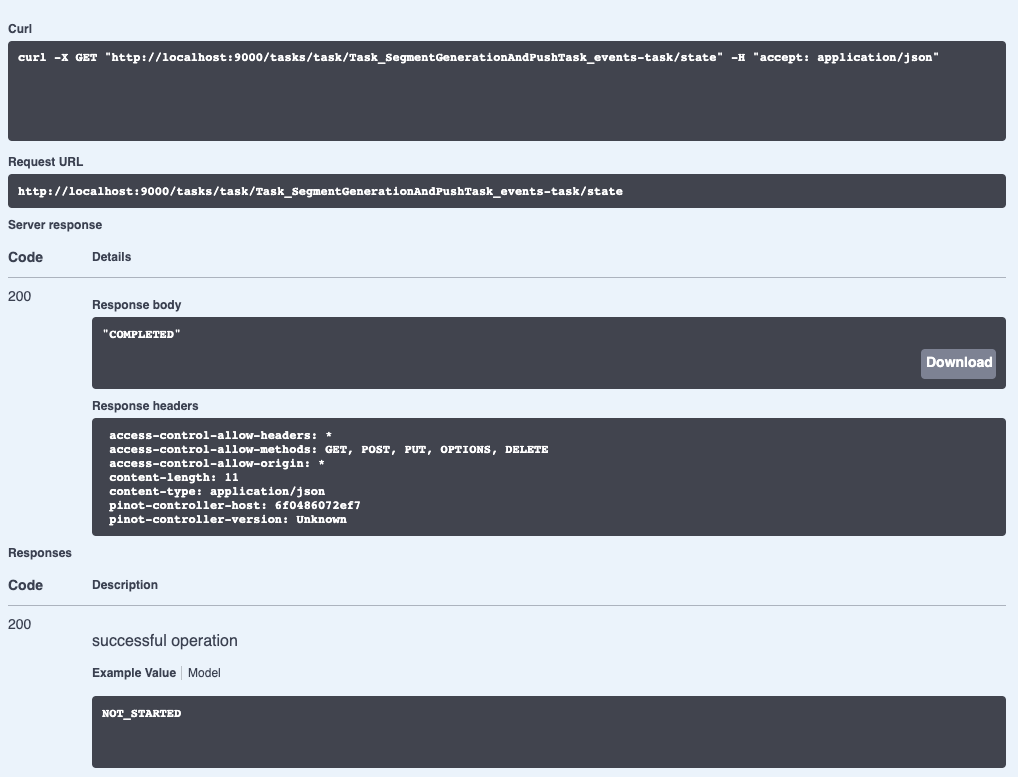
If we see the state COMPLETED, this means the data has been ingested, which we can check by going back to the Query console and clicking on the events table.
Summary
I have to say that batch ingestion of data into Apache Pinot has always felt a bit clunky, but with this new clause, it’s super easy, and it’s gonna save us all a bunch of time.
Also, anything that means I’m not writing YAML files has got to be a good thing!
So give it a try and let us know how you get on. If you have any questions about this feature, feel free to join us on Slack, where we’ll be happy to help you out.