
Last fall, the Apache Pinot community released version 0.11.0, which has lots of goodies for you to play with.
In this post, we’re going to learn about the deduplication for the real-time tables feature.
Why do we need deduplication on real-time tables?
This feature was built to deal with duplicate data in the streaming platform.
Users have previously used the upsert feature to de-duplicate data, but this has the following limitations:
- It forces us to keep redundant records that we don’t want to keep, which increases overall storage costs.
- We can’t yet use the StarTree index with upserts, so the speed benefits we get from using that indexing technique are lost.
How does dedup differ from upserts?
Both upserts and dedup keep track of multiple documents that have the same primary key. They differ as follows:
- Upserts are used when we want to get the latest copy of a document for a given primary key. It’s likely that some or all of the other fields will be different. Pinot stores all documents it receives, but when querying it will only return the latest document for each primary key.
- Dedup is used when we know that multiple documents with the same primary key are identical. Only the first event received for a given primary key is stored in Pinot—any future events with the same primary key are thrown away.
Let’s see how to use this functionality with help from a worked example.
Setting up Apache Kafka and Apache Pinot
We’re going to spin up Kafka and Pinot using the following Docker Compose config:
version: "3" services: zookeeper: image: zookeeper:3.8.0 hostname: zookeeper container_name: zookeeper-dedup-blog ports: - "2181:2181" environment: ZOOKEEPER_CLIENT_PORT: 2181 ZOOKEEPER_TICK_TIME: 2000 networks: - dedup_blog kafka: image: wurstmeister/kafka:latest restart: unless-stopped container_name: "kafka-dedup-blog" ports: - "9092:9092" expose: - "9093" depends_on: - zookeeper environment: KAFKA_ZOOKEEPER_CONNECT: zookeeper-dedup-blog:2181/kafka KAFKA_BROKER_ID: 0 KAFKA_ADVERTISED_HOST_NAME: kafka-dedup-blog KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-dedup-blog:9093,OUTSIDE://localhost:9092 KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9093,OUTSIDE://0.0.0.0:9092 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,OUTSIDE:PLAINTEXT networks: - dedup_blog pinot-controller: image: apachepinot/pinot:0.11.0-arm64 command: "QuickStart -type EMPTY" container_name: "pinot-controller-dedup-blog" volumes: - ./config:/config restart: unless-stopped ports: - "9000:9000" networks: - dedup_blog networks: dedup_blog: name: dedup_blog Code language: JavaScript (javascript)
We can spin up our infrastructure using the following command:
docker-compose up
Data Generation
Let’s imagine that we want to ingest events generated by the following Python script:
import datetime import uuid import random import json while True: ts = datetime.datetime.now().strftime("%Y-%m-%dT%H:%M:%S.%fZ") id = str(uuid.uuid4()) count = random.randint(0, 1000) print( json.dumps({"tsString": ts, "uuid": id[:3], "count": count}) )Code language: JavaScript (javascript)
We can view the data generated by this script by pasting the above code into a file called datagen.py and then
running the following command:
python datagen.py 2>/dev/null | head -n3 | jq
We’ll see the following output:
{ "tsString": "2023-01-03T10:59:17.355081Z", "uuid": "f94", "count": 541 } { "tsString": "2023-01-03T10:59:17.355125Z", "uuid": "057", "count": 96 } { "tsString": "2023-01-03T10:59:17.355141Z", "uuid": "d7b", "count": 288 }Code language: JSON / JSON with Comments (json)
If we generate only 25,000 events, we’ll get some duplicates, which we can see by running the following command:
python datagen.py 2>/dev/null | jq -r '.uuid' | head -n25000 | uniq -cdCode language: JavaScript (javascript)
The results of running that command are shown below:
2 3a2 2 a04 2 433 2 291 2 d73
We’re going to pipe this data into a Kafka stream called events, like this:
python datagen.py 2>/dev/null | jq -cr --arg sep '[.uuid, tostring] | join($sep)' | kcat -P -b localhost:9092 -t events -K Code language: JavaScript (javascript)
The construction of the key/value structure comes from Robin Moffatt’s excellent blog post . Since that blog post was written, kcat has started supporting multi byte separators, which is why we can use a smiley face to separate our key and value.
Pinot Schema/Table Config
Next, we’re going to create a Pinot table and schema with the same name. Let’s first define a schema:
{ "schemaName": "events", "dimensionFieldSpecs": [{"name": "uuid", "dataType": "STRING"}], "metricFieldSpecs": [{"name": "count", "dataType": "INT"}], "dateTimeFieldSpecs": [ { "name": "ts", "dataType": "TIMESTAMP", "format": "1:MILLISECONDS:EPOCH", "granularity": "1:MILLISECONDS" } ] }Code language: JSON / JSON with Comments (json)
Note that the timestamp field is called ts and not tsString , as it is in the Kafka stream. We’re going to transform the DateTime string value held in that field into a proper timestamp using a transformation function.
Our table config is described below:
{ "tableName": "events", "tableType": "REALTIME", "segmentsConfig": { "timeColumnName": "ts", "schemaName": "events", "replication": "1", "replicasPerPartition": "1" }, "tableIndexConfig": { "loadMode": "MMAP", "streamConfigs": { "streamType": "kafka", "stream.kafka.topic.name": "events", "stream.kafka.broker.list": "kafka-dedup-blog:9093", "stream.kafka.consumer.type": "lowlevel", "stream.kafka.consumer.prop.auto.offset.reset": "smallest", "stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory", "stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder" } }, "ingestionConfig": { "transformConfigs": [ { "columnName": "ts", "transformFunction": "FromDateTime(tsString, 'YYYY-MM-dd''T''HH:mm:ss.SSSSSS''Z''')" } ] }, "tenants": {}, "metadata": {} }Code language: JSON / JSON with Comments (json)
Let’s create the table using the following command:
docker run --network dedup_blog -v $PWD/pinot/config:/config apachepinot/pinot:0.11.0-arm64 AddTable -schemaFile /config/schema.json -tableConfigFile /config/table.json -controllerHost "pinot-controller-dedup-blog" -exec Code language: JavaScript (javascript)
Now we can navigate to http://localhost:9000 and run a query that will return a count of the number of each uuid:
select uuid, count(*) from events group by uuid order by count(*) limit 10Code language: JavaScript (javascript)
The results of this query are shown below:
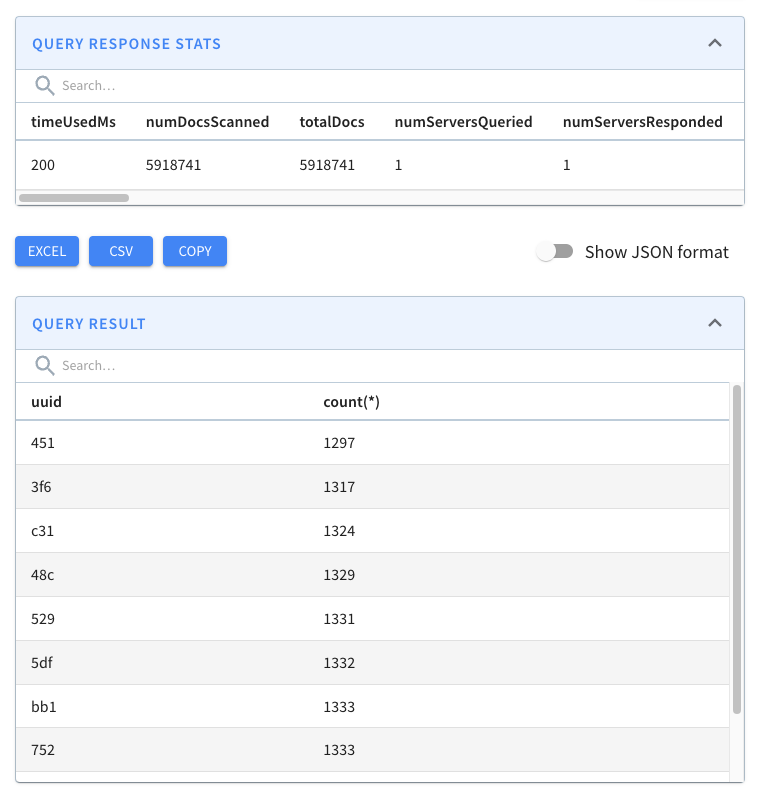
We can see loads of duplicates!
Now let’s add a table and schema that uses the de-duplicate feature, starting with the schema:
{ "schemaName": "events_dedup", "primaryKeyColumns": ["uuid"], "dimensionFieldSpecs": [{"name": "uuid", "dataType": "STRING"}], "metricFieldSpecs": [{"name": "count", "dataType": "INT"}], "dateTimeFieldSpecs": [ { "name": "ts", "dataType": "TIMESTAMP", "format": "1:MILLISECONDS:EPOCH", "granularity": "1:MILLISECONDS" } ] }Code language: JSON / JSON with Comments (json)
The main difference between this schema and the events schema is that we need to specify a primary key. This key can be any number of fields, but in this case, we’re only using the uuid field.
Next, the table config:
{ "tableName": "events_dedup", "tableType": "REALTIME", "segmentsConfig": { "timeColumnName": "ts", "schemaName": "events_dedup", "replication": "1", "replicasPerPartition": "1" }, "tableIndexConfig": { "loadMode": "MMAP", "streamConfigs": { "streamType": "kafka", "stream.kafka.topic.name": "events", "stream.kafka.broker.list": "kafka-dedup-blog:9093", "stream.kafka.consumer.type": "lowlevel", "stream.kafka.consumer.prop.auto.offset.reset": "smallest", "stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory", "stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder" } }, "routing": {"instanceSelectorType": "strictReplicaGroup"}, "dedupConfig": {"dedupEnabled": true, "hashFunction": "NONE"}, "ingestionConfig": { "transformConfigs": [ { "columnName": "ts", "transformFunction": "FromDateTime(tsString, 'YYYY-MM-dd''T''HH:mm:ss.SSSSSS''Z''')" } ] }, "tenants": {}, "metadata": {} }Code language: JSON / JSON with Comments (json)
The changes to notice here are:
- “dedupConfig”: {“dedupEnabled”: true , ” hashFunction”: ” NONE “} – This enables the feature and indicates that we won’t use a hash function on our primary key.
- “routing”: {“instanceSelectorType”: “strictReplicaGroup”} – This makes sure that all segments of the same partition are served from the same server to ensure data consistency across the segments.
docker run --network dedup_blog -v $PWD/pinot/config:/config apachepinot/pinot:0.11.0-arm64 AddTable -schemaFile /config/schema-dedup.json -tableConfigFile /config/table-dedup.json -controllerHost "pinot-controller-dedup-blog" -exec select uuid, count(*) from events_dedup group by uuid order by count(*) limit 10Code language: JavaScript (javascript)
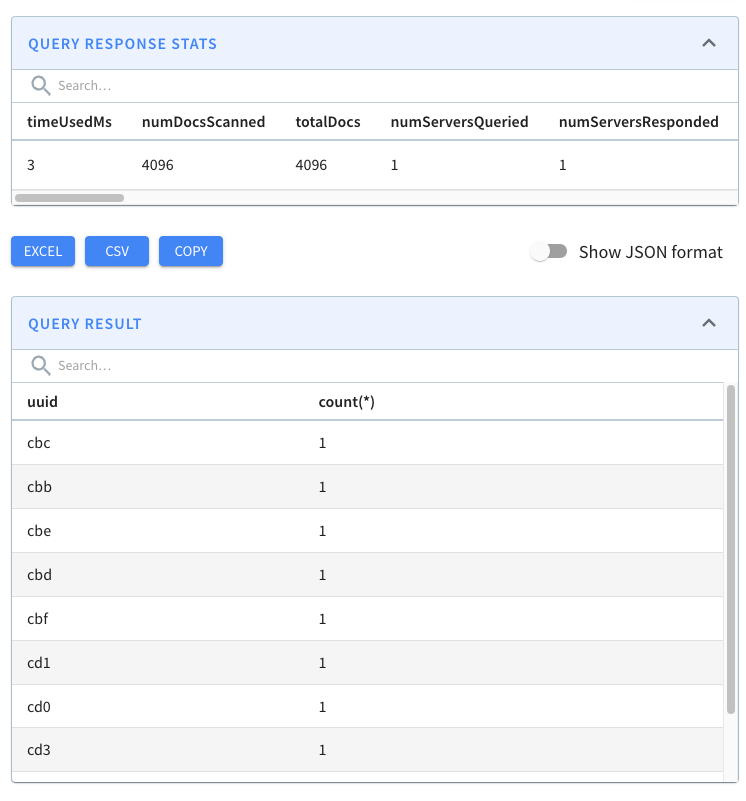
We have every combination of hex values (16^3=4096) and no duplicates! Pinot’s de-duplication feature has done its job.
How does it work?
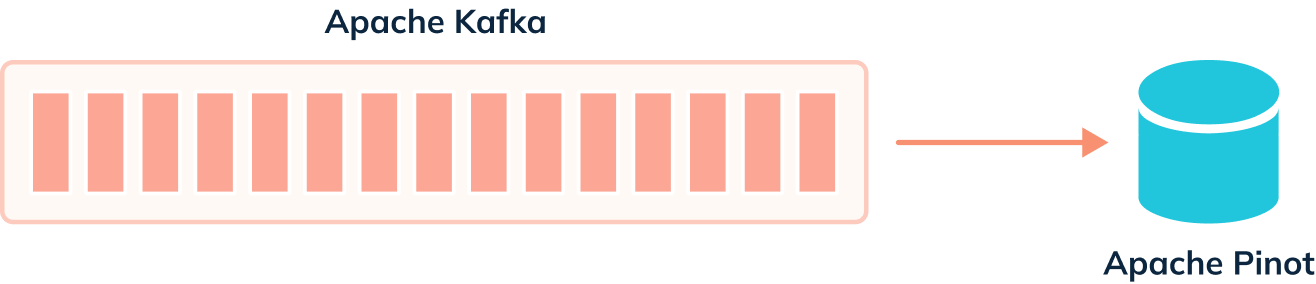
When we’re not using the deduplication feature, events are ingested from our streaming platform into Pinot, as shown in the diagram below:
When de-dup is enabled, we have to check whether records can be ingested, as shown in the diagram below:
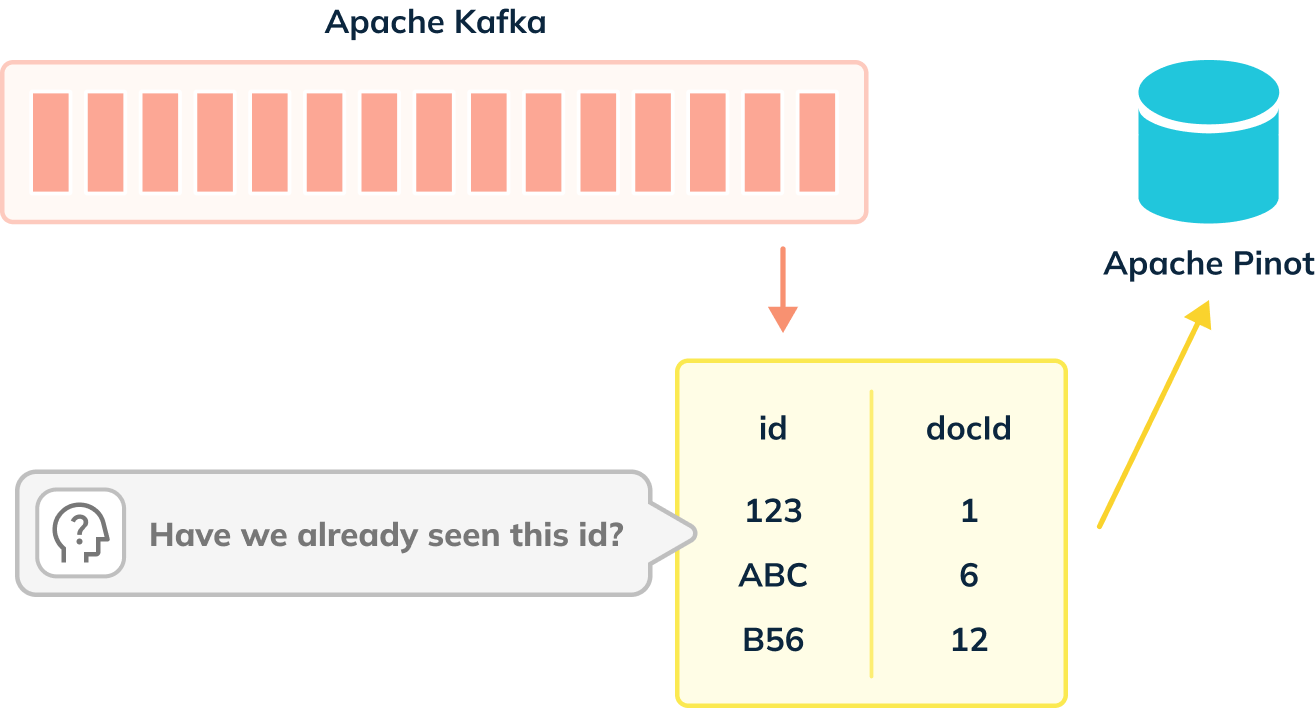
De-dup works out whether a primary key has already been ingested by using an in memory map of (primary key -> corresponding segment reference).
We need to take that into account when using this feature, otherwise, we’ll end up using all the available memory on the Pinot Server. Below are some tips for using this feature:
- Try to use a simple primary key type and avoid composite keys. If you don’t have a simple primary key, consider using one of the available hash functions to reduce the space taken up.
- Create more partitions in the streaming platform than you might otherwise create. The number of partitions determines the partition numbers of the Pinot table. The more partitions you have in the streaming platform, the more Pinot servers you can distribute the Pinot table to, and the more horizontally scalable the table will be.
Summary
This feature makes it easier to ensure that we don’t end up with duplicate data in our Apache Pinot estate.
So give it a try and let us know how you get on. If you have any questions about this feature, feel free to join us on Slack, where we’ll be happy to help you out.
And if you’re interested in how this feature was implemented, you can look at the pull request on GitHub.
