Introduction
In a previous blog, we talked about how Real-Time Upserts work in Apache Pinot. The upsert feature has been designed to complete most of the work of merging upserts at ingestion time to minimize the overhead on query performance. The ingestion overhead is kept low by leveraging data partitioning and just one bitmap per segment to track upserted data. The raw data is always kept in the segments, so that users can view all the previous versions of a given primary key with a simple query flag `skipUpsert=true`. In addition, the upsert feature in Apache Pinot has been extended to support partial upserts, data deletion, and data compaction to empower more and more use cases.
As explained in the previous blog, one of the limitations of the upsert feature in Apache Pinot is the memory overhead from tracking the primary keys in the JVM heap. The heap size puts a hard limit on the total number of primary keys that can be managed by one Pinot server. In this blog, we will discuss in depth how StarTree Cloud overcomes this limitation in addition to addressing more such bottlenecks exposed while operating upserts at scale.
High-level architecture
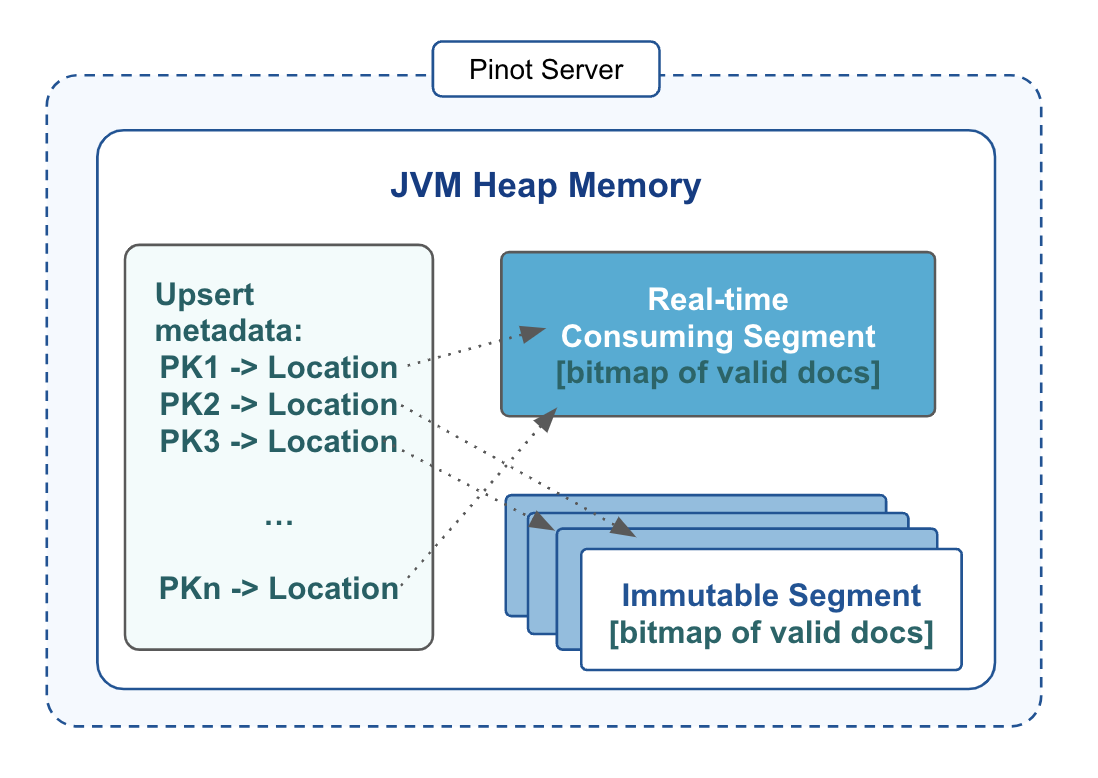
As shown in the figure above, the open source implementation of the upsert feature in Apache Pinot uses the on-heap map to keep track of the primary keys and their locations in the table’s segments. Besides, each segment has a bitmap called validDocIds for queries to identify the valid records and skip the obsolete ones quickly, and those bitmaps are kept on heap too. Depending on the size of the JVM heap, one Pinot server may potentially handle millions or even hundreds of millions of primary keys. Beyond this scale the memory overhead starts impacting overall ingestion and query performance.
Even if one could keep increasing the heap size for Pinot servers to support larger and larger upsert tables, they would see another bottleneck before long. Basically, the on-heap map has to be restored when the server restarts or the table partition gets rebalanced to a new server. As the map gets bigger, the time used to restore the upsert metadata gets longer too, often by tens of minutes if not hours. And this could severely increase the time to restart a Pinot cluster in a rolling fashion during software upgrades or other cluster operations.
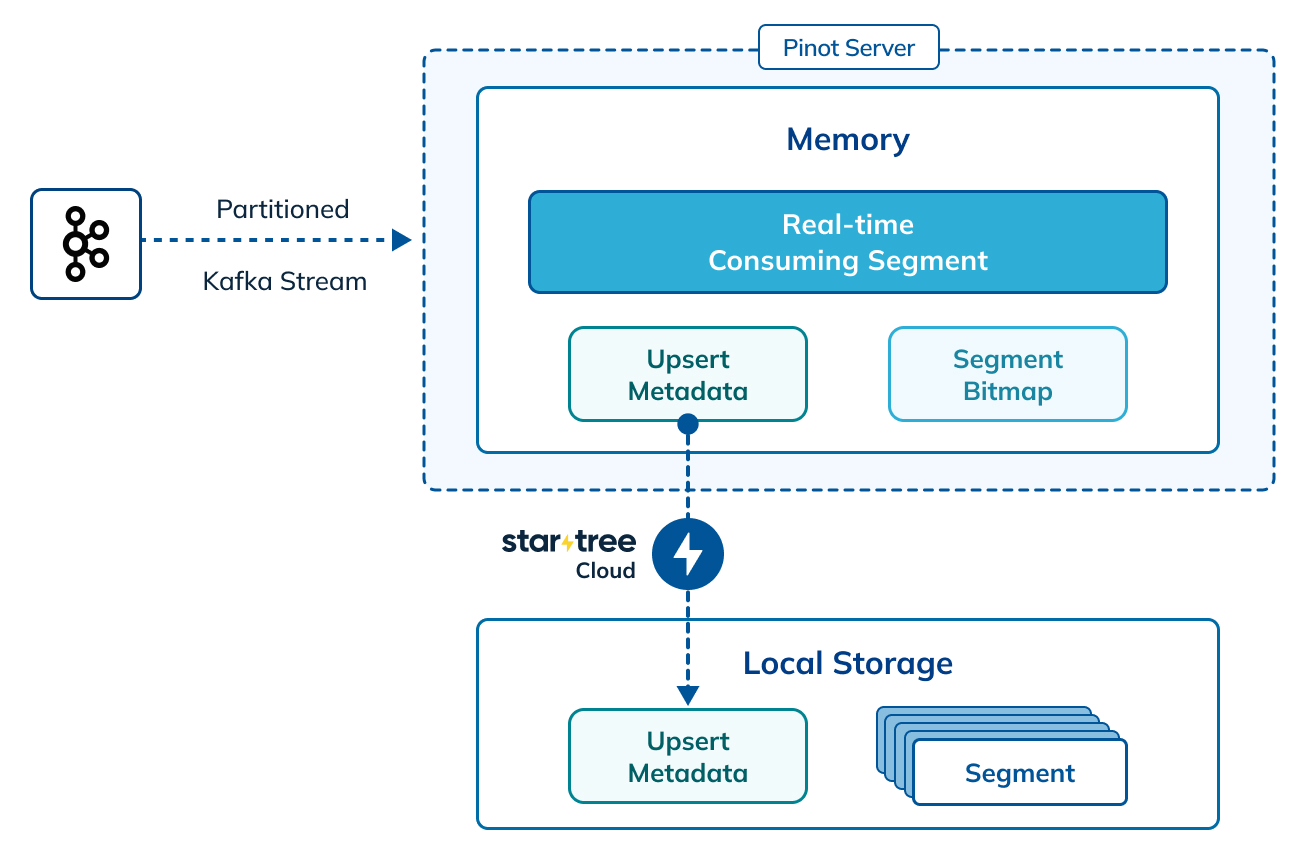
To address those issues, in StarTree Cloud, we decided to use a disk-backed storage system (RocksDB as of now) to keep the mapping from records’ primary keys to their locations. We can limit the memory resources used by the write buffers and read caches of the RocksDB store, to reduce the impact on the real-time data ingestion and query executions.
As shown in figure 1, each segment has a bitmap called validDocIds for queries to identify the valid records quickly. Those bitmaps are kept on heap as before, so the query performance is not affected much by the choice of the upsert metadata store. In fact, as we reduce the memory pressure from keeping the upsert metadata, we can improve the overall performance and stability for the Pinot servers.
Bootstrap bottleneck
In some open source deployments, we’ve noticed that servers could take tens of minutes or longer to get started up, with most of the time spent rebuilding the upsert metadata. This is because when a server bootstraps the upsert metadata, it has to scan through all the records in the table partitions assigned to it. It’s pretty common for the server to have hundreds of millions or billions of records in the upsert tables. And for each record, it has to read multiple columns to compose the primary key, check the metadata map for previous record of the same primary key, conditionally update the validDocIds bitmap and add the new record location in the metadata map. Using RocksDB makes the issue a bit more complex. RocksDB read operations are very CPU intensive due to the need to check many internal caches intended to speed up reads. RocksDB write operations can also get CPU intensive when under heavy workload.
As RocksDB is a disk backed storage system, in theory we could keep the upsert metadata across server restarts and just reuse it to reduce the time to bootstrap the metadata for upsert tables. But it turned out to be pretty complex to reuse the upsert metadata across server restarts. This is primarily because the segment assignments can change across server restarts and the upsert metadata from uncommitted segments has to be cleaned up on server restarts too. Besides, when a table is rebalanced to new servers, the new servers have to bootstrap the upsert metadata from scratch anyway.
Leveraging RocksDB bulk import
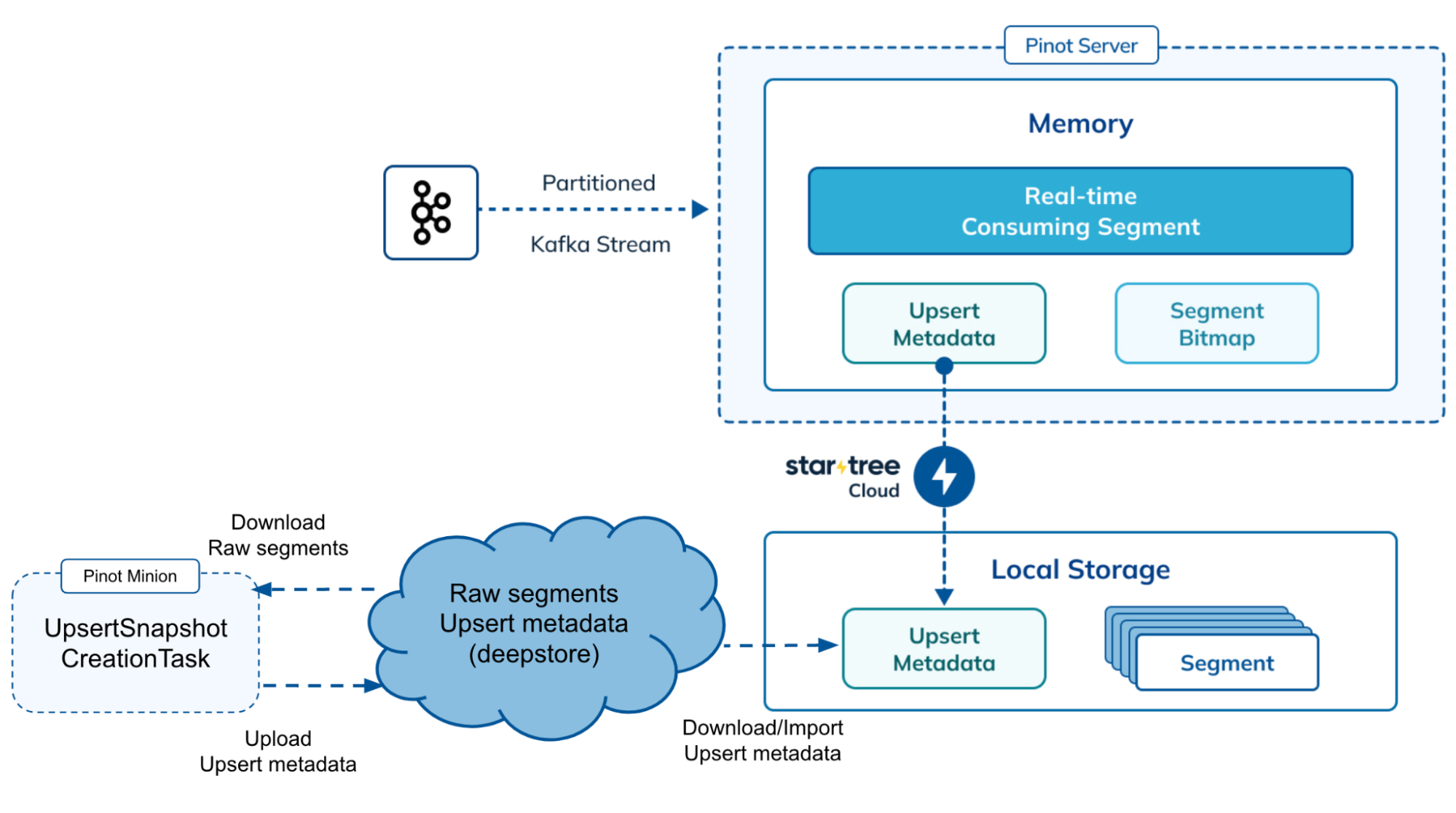
In order to get around this bottleneck, we took a different approach of leveraging the bulk import feature in RocksDB. StarTree Cloud uses a special background minion job to periodically go through all the segments and prebuild the corresponding upsert metadata in the form of RocksDB Sorted Strings Table (SST) files. These prebuilt snapshots are stored alongside the segments in the deep store. When a Pinot server needs to rebuild the metadata – instead of doing it one row/document at a time, it can simply import this prebuilt file after downloading it from the deep store.
The new minion task is called UpsertSnapshotCreationTask, and it can be managed like the other minion tasks. It is recommended to run periodically to keep the upsert metadata updated with the latest set of segments from the table.
When the server needs to bootstrap the upsert metadata, either due to server restarts or table rebalances, it can download the prebuilt upsert metadata from the deepstore and import it to its local RocksDB store. Once the upsert metadata is imported, the server can resume the real-time data ingestion and start to serve queries. The prebuilt snapshots contain metadata like the columns used for primary keys and comparison keys, the table partition configs etc. in order for the server to check if the prebuilt snapshot is still usable for the table before importing.
This new minion task could help reduce the time to bootstrap upsert metadata significantly. For example, recently a server (4 cores/30 GiB memory) hosting close to 1 billion primary keys was restarted for upgrading but it couldn’t finish bootstrapping its upsert metadata even after a few hours. Although we could use RocksDB backed upserts to host billions of primary keys on servers with limited resources, the metadata bootstrapping became severely slow.
Then we enabled this new minion task to prebuild upsert metadata for all table partitions. With the Pinot minion framework, we could use many workers to build snapshots in parallel to reduce the overall time. Once the snapshot was ready, the servers could use it to get restarted in less than 10 minutes. As shown in the figure below, the cluster rolling restart finished quickly.
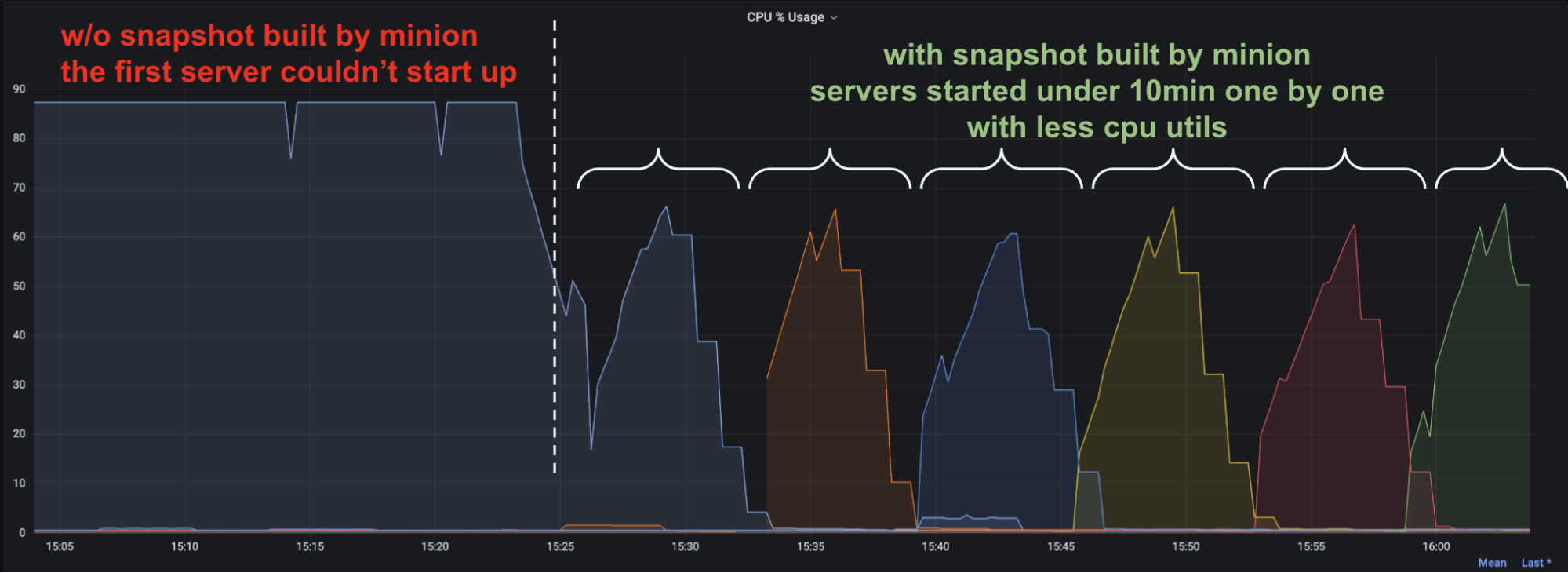
And as seen in many other customer environments, the speedup could be 5X or higher. Overall, the more primary keys a server hosts, the greater the speedup it could see.
After using RocksDB to store upsert metadata and Pinot minions to accelerate the bootstrapping of upsert metadata, we are able to enable real-time upserts for very large tables with billions of primary keys per server, and meanwhile keep their operations simple and reliable. Many StarTree customers come to us specifically for the real-time upsert feature, so it’s very important to continue to make it fast, reliable and easy to use at whatever scale our customers need.
Additional extensions for upserts in StarTree Cloud
Compact and merge
As mentioned in the previous blog, one can use the minion task UpsertCompactionTask to compact the segments from the upsert table to remove invalid docs to reduce disk usage. As compaction continues to happen, many segments may end up with only a small number of valid docs. If a table contains too many small segments, system efficiency and query performance can get worse. So we merge those tiny segments.
In StarTree Cloud, there is a minion task called SegmentRefreshTask that can merge small segments continuously, and apply many other optimizations on the merged segments. This worked for non-upsert tables very well today, and we are making it work for upsert tables too.
Star-Tree Index
Today the star-tree index doesn’t work with upsert tables. This is because the star-tree index assumes the docs in the segment are immutable, but upserts change the set of valid docs in a segment. If the star-tree index is not updated according to the upserts, the query results can be wrong. We are exploring a few options to make the star-tree index work with the upsert tables and would love to share our progress with you later. If you have strong opinions on how you’d like to see the star-tree index work with upserts in StarTree Cloud, contact us so we can incorporate your thoughts into our design and implementation.
Off-heap dedupe
The dedupe feature is similar with the upsert feature, as both make sure the queries only see one record for each unique primary key. But the dedupe feature keeps the first record for a primary key and simply discards all the following ones with the same key; while the upsert feature gives queries the latest record for a primary key and has to keep previous records until they expire by data retention. The partial upsert feature can be configured to make the first version of a record available to queries, but that comes with extra overhead too.
Some of our customers wanted the dedupe feature but found the OSS implementation didn’t scale very well, as the dedupe metadata is kept in the JVM heap as well. They turned to the offheap upsert to deduplicate records as a workaround, which works but is less efficient. So we are enhancing the dedupe feature in StarTree Cloud, as we have done for the upsert feature, to make it more efficient and easier to operate.
Summary
The upsert feature is critical to build powerful real-time analytical applications. Doing upsert in real-time efficiently on very large tables is pretty challenging. The upsert feature as implemented in the open source Apache Pinot works well at medium scale, like keeping 10s millions of primary keys per server, but gets expensive and hard to use at even larger scales, due to the problems of heap memory usage and bootstrapping time as explained in this blog. In StarTree cloud, we have solved those problems by leveraging RocksDB as the upsert metadata store and using the Pinot Minion task framework to prepare metadata snapshot to speed up the bootstrapping. Those techniques make the upsert feature efficient and simple to use on very large tables for StarTree customers.
If you’re interested in tackling those problems, we’re hiring!
Want to try StarTree Cloud? Get started with your own fully-managed Apache Pinot environment with a StarTree Cloud Trial. If you have specific needs or want to speak with a member of our team, you can book a demo.
