
Today, Databricks announced Lakehouse//RT, a real-time data warehouse powered by a new engine called Reyden. The pitch: millisecond query performance directly on governed Delta and Iceberg data, no separate serving layer, no data movement.
We have one reaction. Welcome.
For more than a decade, StarTree and Apache Pinot have challenged a core assumption of modern data architectures: that analytics systems are for internal analysis and separate systems are required for serving. Organizations routinely built pipelines to move data from warehouses and lakes into specialized serving stores just to make analytic insights usable in applications. Pinot was designed to collapse those layers into a single platform capable of both analytics and serving at scale. This architecture has powered some of the world’s largest customer-facing analytics applications at LinkedIn, Uber, Stripe, and many others for years.
What Databricks is now recognizing with Lakehouse//RT is the same fundamental truth: analytics and serving should not be separate systems. The costs of maintaining distinct analytic and serving layers are too high in an era where every application, dashboard, and AI agent expects real-time intelligence.
“No data movement” is not a Databricks advantage. StarTree already reads your open tables directly.
The strongest part of the Lakehouse//RT story is the architectural one: query governed open-format data directly, zero data copy, keep Unity Catalog governance intact. It is a good argument. It is also not exclusive to Databricks.
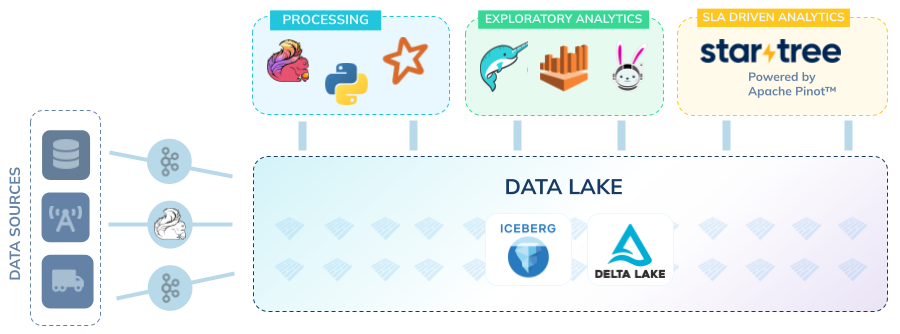
StarTree’s serving engine has a decade of production scale behind it. What is newer is that you no longer have to move your lakehouse data into Pinot’s native format to get it. StarTree reads Delta Lake and Apache Iceberg tables directly.
- Native Iceberg and Parquet support lets StarTree query lakehouse tables directly, with no transformation and no duplication, while applying Pinot’s indexing on top.
- StarTree integrates with Unity Catalog, so your governance model travels with the data.
That combination is the point: the serving engine that already runs LinkedIn- and Stripe-scale workloads now points straight at your governed Delta and Iceberg tables. So when Databricks frames the separate serving layer as a “broken compromise” that forces you into proprietary storage, that critique does not land on StarTree. We read your open tables, in their open formats, governed by your catalog, and we layer purpose-built indexing and a high-concurrency serving engine on top.
What Lakehouse//RT actually claims
Databricks is precise about its numbers, so we will be too. From the announcement:
- Response times as low as 10ms on smaller datasets, sub-100ms on larger ones
- Sub-100 millisecond latency at 12,000 queries per second on standard analytical benchmarks
- Available in beta, for select read-only workloads, with more capabilities arriving “in the coming months”
The number that matters for customer-facing apps: 12,000 QPS vs. 200,000
The promise of “eliminating the separate serving layer” only holds if the unified engine can actually carry the serving layer’s load. That load is not a few thousand analytical queries. It is tens to hundreds of thousands of small, filtered, concurrent queries per second, each returning in well under a second, fired by public applications and, increasingly, by swarms of AI agents.
Here is the contrast:
Lakehouse//RT, in beta: sub-100ms at 12,000 QPS on a benchmark.
Apache Pinot and StarTree, in production, right now:
- LinkedIn serves upwards of 200,000 QPS at sub-100ms p95 latency, powering features like “Who Viewed My Profile” and feed analytics.
- Stripe runs extreme QPS against a single table holding more than a petabyte of data, while maintaining sub-second latency and 99.99% availability.
- Production Pinot clusters routinely serve 100,000+ queries per second under strict low-latency SLAs.
That is not a benchmark we ran in a lab. It is measured, in production, on workloads that pay the bills for some of the most demanding data products on the internet. The gap between 12,000 QPS in a controlled test on a small batch data set and 200,000 QPS serving live customer traffic is the difference between “faster warehouse” and “real-time analytic serving layer.”
The metric Databricks didn’t publish: P99
Lakehouse//RT reports sub-100ms latency at 12,000 QPS. What’s missing is the percentile. No P95. No P99. No indication of how latency behaves as concurrency rises.
For customer-facing applications, that matters. Average latency tells you how a typical request performs. P99 tells you how your slowest users experience the product. At 12,000 QPS, even a small tail latency problem can mean hundreds of poor user experiences every second.
This is where production experience matters. Apache Pinot was engineered for predictable tail latency at scale, using segment-level parallelism, partition-aware routing, and a serving architecture optimized for high concurrency. That’s why companies like LinkedIn and Stripe run Pinot-powered applications under strict latency SLAs at massive scale.
Benchmarks demonstrate potential. P99 under production workloads demonstrates readiness.
Best-of-breed beats one-vendor-for-everything
There is a false assumption inside the Lakehouse//RT announcement that the right answer is to run every workload on a single vendor’s platform.
Let’s be clear about what Databricks is genuinely excellent at. They built the modern lakehouse. For data science, large-scale ETL, and Spark-based batch processing, they are best-in-class, and a decade of engineering and production hardening stands behind that. We have real respect for it. Real-time serving is a different discipline, and on that front Lakehouse//RT is new. It is a freshly announced engine, in beta, limited to read-only workloads, with no published P99 and freshness left to the batch pipeline. No customers running in production at scale.
This is exactly why a single-vendor stack is the wrong default, and the open data movement Databricks itself helped build agrees. The entire premise of open table formats (Delta, Iceberg, Unity Catalog, the REST catalog spec) is that your data should not be hostage to one vendor. You pick the best tool for each job and point them all at the same governed tables. Data science, ETL, and Spark jobs on Databricks, where they are excellent. High-concurrency, customer and agent facing, fresh-data serving on an engine purpose-built and production-proven for exactly that (SLA Driven Analytics).
A single vendor optimizing for “good enough across everything” is, structurally, the opposite of best-of-breed, and “good enough” is most risky on the customer and agent facing part of the stack.
The cost question Databricks left out
Read the Lakehouse//RT announcement again and notice what is missing: cost. No cost-per-query, no efficiency figure, no accounting for what it actually takes to serve a query at scale. That silence is telling, because cost is exactly where the serving-layer promise gets tested in the real world. What a decade of running these workloads taught us is that at scale, cost-per-query is the metric that compounds. Serve millions of queries a day to an application or a fleet of agents and a few extra milliseconds of compute, a few extra megabytes read from S3, a few wasted CPU cycles per query stop being rounding errors and turn into your infrastructure bill.
The only way to win that math is to be obsessive about minimizing every read, every I/O operation, and every compute cycle on the path to an answer, which is precisely what Pinot’s indexing is built to do: touch the smallest possible set of columns and blocks, transfer the least data from object storage, and avoid dragging whole partitions into the query path.
StarTree is the undisputed cost minimizer here, and we have the numbers to prove it. In a recent head-to-head benchmark on an identical 12.2-billion-row Parquet dataset in S3, on identical hardware, StarTree measured dramatically lower CPU usage, fewer S3 reads, and lower cost per query than both Trino and ClickHouse. ClickHouse, worth noting, is very likely one of the unnamed alternatives in Databricks’ own comparison (certainly wasn’t StarTree).
Try it yourself. It is fast and easy to evaluate.
You do not have to take our word, or Databricks’, for any of this. StarTree runs on the Delta and Iceberg tables you already have. Point it at your governed lakehouse data, run your real query patterns at your real concurrency, and measure it against the SLA your customers actually hold you to.
That is the test that matters. Not a benchmark slide. Your workload, your data, your numbers.
