What is Apache Pinot?
Let’s dive into Apache Pinot. How it works and how you can best utilize it…
So – what, exactly– is Apache Pinot?
Pinot is essentially just a database – with a lot of innovative ways of optimizing and storing data
It’s an open-source, real-time, distributed OLAP database designed for low-latency analytics on large datasets. But at its core it has a very familiar interface in which data is in tables, and the tables have columns with all the usual data types. Pinot even supports joins across tables, and you can query it all using SQL
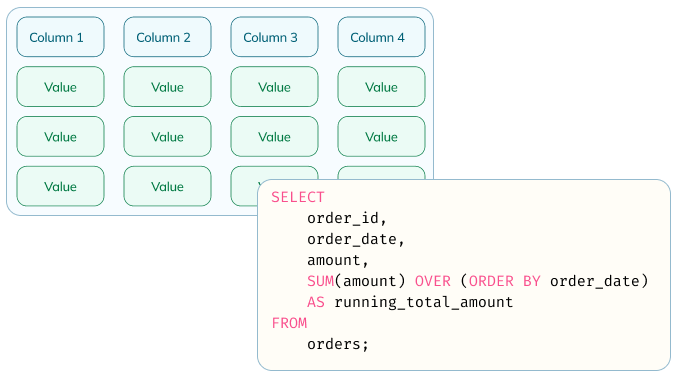
Optimized for analytics on rapidly changing data
Pinot is designed for fast responses to analytical and aggregation type queries (OLAP) on streaming data. Pinot utilizes a columnar storage format with rich indexing options.
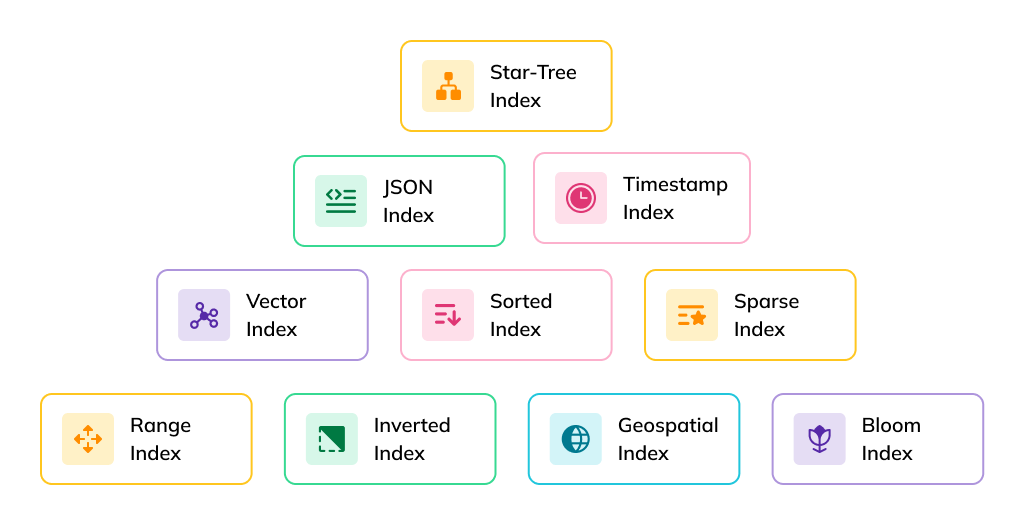
Apache Pinot’s claim to fame comes with how data is indexed. A large and growing collection of index types allows for efficient reads in real time. (inverted, sorted, star-tree, JSON, geospatial). This enables efficient data retrieval and filtering, minimizing data scans and accelerating query execution, which is crucial for handling high concurrency with low latency.
Flexible high-speed ingest
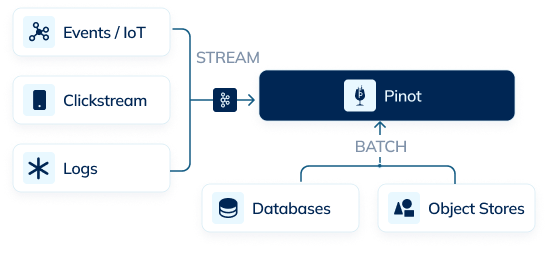
Pinot provides convenient ways to ingest data from various streaming sources (Apache Kafka, Amazon Kinesis) as well as batch sources (like Amazon S3 and Delta Lake) or data warehouses (such as Snowflake and BigQuery).
Pinot’s distributed architecture is able to ingest large volumes of data efficiently, and without affecting query times. Data is typically available for query within milliseconds. Pinot also supports upserts, and can transform records on the fly during ingestion.
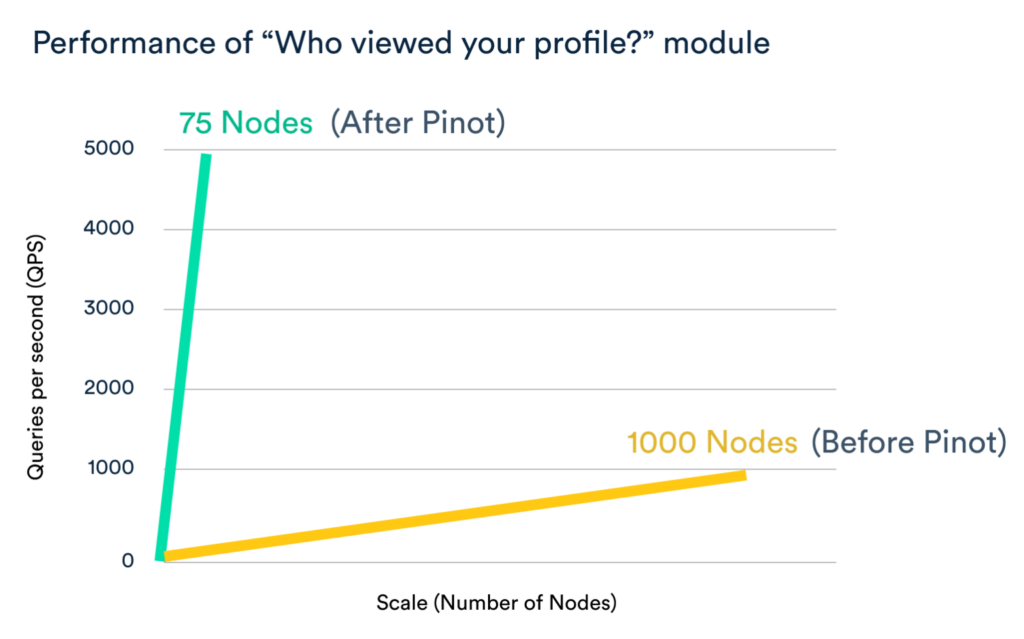
Distributed architecture for scale
Apache Pinot uses a modular and distributed architecture that allows it to scale horizontally to handle high concurrency –– often serving hundreds to thousands of queries per second with response times under 100ms. It is capable of expanding to handle growing data and query loads. This sets it apart from other real-time OLAP systems.
As data grows, you can add more servers to increase storage capacity and improve parallelism for queries (more servers = faster scans). Pinot has several smart scaling features to keep performance snappy.
Pinot is proven at some of the world's largest companies

Five signs you might need Apache Pinot
Low latency analytics
Pinot is typically able to provide 100ms p99 for critical use cases.
High concurrency
Apache Pinot is uniquely designed to handle upwards of 100,000 queries per second. However, even workloads measured in hundreds of QPS may perform poorly on systems that were never designed for real-time analytics in the first place.
Data freshness
Real-time data with historical context
Reduce infrastructure bloat
How does Apache Pinot compare with other databases?
- Compared to Relational databases like MySQL and Postgres Pinot has a columnar architecture that makes it much more efficient for aggregations and summarizing data. And it’s distributed architecture makes it possible to do this at scale.
- Compared to Search databases like Elastic Pinot has more powerful and varied indexing options, and is better suited for working with tabular data, mutable data and analytical queries. More
- Compared to streaming databases like kSQLdb, Apache Pinot has a much broader range of functionality. It can perform batch ingestion, queries on demand, and can maintain a broad historical context.
- Compared to data warehouses like Snowflake, BigQuery, and other ‘Data Lakes’ Apache Pinot is optimized to provide much faster response times to queries on fresher data –– Think milliseconds, not many seconds. Pinot can support very high QPS, and is more suitable for powering responsive applications. More
- Compared to time-series databases like InfluxDB, Timescale & Prometheus Apache Pinot is also well suited to observability use-cases that these databases excel at. Pinot offers more capable ingestion and transformation, is able to handle high-cardinality data, and has more powerful query capabilities. More
- Compared to other real-time analytical databases like Apache Druid, Clickhouse Apache Pinot delivers fast query at scale. This makes it more suitable for customer facing applications with high queries per second. It has more flexibility working with upserts and changing data. More
Pinot has a columnar architecture that makes it much more efficient for aggregations and summarizing data. And it's distributed architecture makes it possible to do this at scale.
Pinot has more powerful and varied indexing options, and is better suited for working with tabular data, mutable data and analytical queries.
Apache Pinot has a much broader range of functionality. It can perform batch ingestion, queries on demand, and can maintain a broad historical context.
Apache Pinot is optimized to provide much faster response times to queries on fresher data –– Think milliseconds, not many seconds. Pinot can support very high QPS, and is more suitable for powering responsive applicati
Apache Pinot delivers fast query at scale. This makes it more suitable for customer facing applications with high queries per second. It has more flexibility working with upserts and changing data.
Incredible response times under some of the most demanding workloads

A thriving community
Apache Pinot Community Surges to 5k

StarTree Cloud elevates Apache Pinot