
Upserts — “Insert or Update” — is a powerful feature in modern databases. Many OLTP systems handle updates atomically with strong consistency. These systems are row-based, storing data contiguously on disk, and are optimized to process inserts and updates seamlessly. But bringing this efficiency into a real-time analytics database like Apache Pinot is a very different challenge.
Pinot organizes data in immutable columnar segments. This design enables indexes and highly compressed data structures, delivering blazing-fast query performance — perfect for analytical workloads. However, immutability also means Pinot wasn’t originally designed to handle updates.
To support Upserts at scale — without compromising ingestion rates or sub-second query latency, we introduced new primitives and revisited some core assumptions. In this blog, I’ll walk through a quick overview of Pinot’s Upsert capability and the challenges of productionizing it at thousands of reads and writes per second. The main focus will be on how to make node restarts fast and reliable while introducing new state management and coordination mechanisms.
If you are already familiar with the Pinot’s Upserts design, please skip to Operational Challenge
Who needs real-time Upserts in analytics?
The demand for real-time Upserts is widespread: retail companies analyzing continuous changes in transactions and orders, geo-spatial defense systems processing coordinates every millisecond, and platforms like Uber constantly refreshing delivery or trip status. Apache Pinot powers all of these use cases with low-latency, real-time Upserts.
How Pinot achieves Upserts?
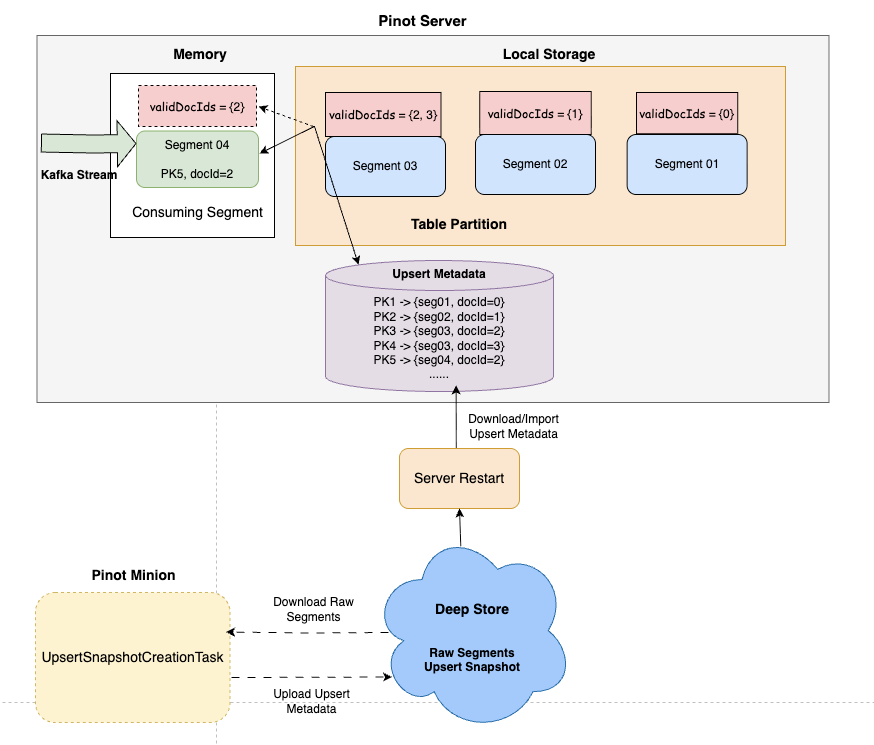
Since segments in Pinot are immutable, supporting Upserts required a way to track changes and make them visible to both ingestion and query components. To achieve this, we introduced a mutable metadata layer on top of the existing immutable segment structure. Let’s walk through how this works:
- Upsert tables ingest from real-time streams, which are partitioned at the source. The partition key (also the primary key) is used to track row-level updates.
- In Pinot, data is stored as segments. To identify the location of the latest record for a given primary key, Pinot maintains a metadata map on the server containing segment and row information. This metadata map can be in-memory or on disk: {Primary Key → Record Location(segmentId, documentId)}
- Each segment also maintains an in-memory bitmap (referred to as the validDocId bitmap) to track which rows are current. This enables queries to skip outdated entries efficiently.
- When a new record arrives, Pinot:
- Uses the metadata map to locate the previous record.
- Invalidates the old entry in the validDocId bitmap.
- Marks the new record as valid.
- Updates the metadata map with the new record’s location.
This design ensures that updates are as fast as inserts while keeping query performance sub-second, even at scale. Refer Fig 1 for the flow.
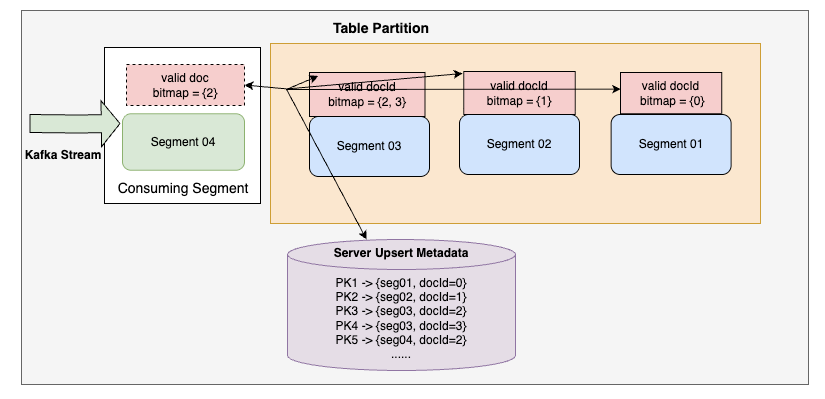
Most analytical systems that support Upserts rely on asynchronous refreshes and batch merges, which introduce delays before updates become visible. In contrast, Pinot’s design — combining valid document bitmaps with efficient metadata mapping makes updates visible immediately, without costly background merges.
This is a major differentiator in Pinot’s Upsert support: not only can it handle updates in real time, but it also enables users to track historical changes with the same efficiency.
Offheap Upserts
Initially, Pinot stored primary key metadata on-heap. But heap memory is a limited resource, and on heavy utilization it could make the system susceptible to GC pauses and out-of-memory errors. This approach capped scalability at only a few hundred million primary keys per server, beyond which ingestion rates and query performance began to suffer. At StarTree Cloud, we engineered Offheap Upserts using RocksDB to persist metadata on disk. This boosted capacity by 10x, enabling storage of more than 5 billion primary keys per server — far beyond the limits of heap storage. Today, some of our customers manage tens of terabytes of data in a single upsert table, with ingestion rates peaking at ~1.5M records/sec for updates. (More details here: Offheap Upserts)
Operational Challenge during Server Restarts
Now we come to the primary focus of this blog which is a critical concern in large-scale systems — operational ease at scale. When Pinot segments were fully immutable, server restarts were relatively simple and fast. But with Upserts, we face a new class of operational challenges. Specifically, how to restore mutable states and metadata optimally and reliably during restarts in large distributed setups.
With Offheap Upserts, primary key metadata is stored on disk in RocksDB. However, the validDocId bitmaps which track the set of up-to-date records for fast query performance, still reside in memory (as they should, for low-latency querying).
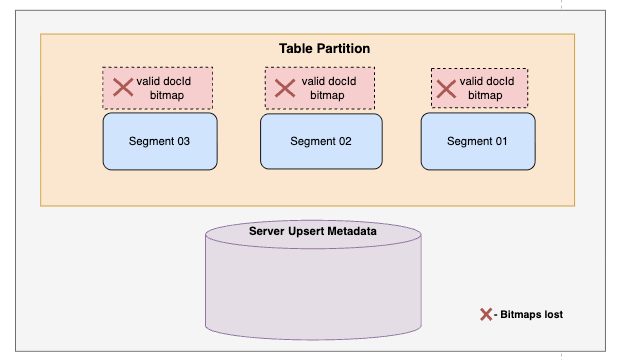
This design introduced few key challenges during server restarts:
- Loss of in-memory bitmaps: Since validDocId bitmaps only live in memory, they are lost on restart and must be rebuilt before queries can run efficiently (Refer Fig 2)
- Inconsistent RocksDB state: While RocksDB persists metadata on disk, ingestion involves continuously appending data. A portion of this data lives in CONSUMING segments — in-memory data not yet committed to disk. These records still update RocksDB state, but on restart the underlying data is re-ingested, making the RocksDB state inconsistent.
- Cold start: The complexity multiplies further during cold starts, when partitions are rebalanced onto new servers that have no existing RocksDB metadata on disk.
All these challenges forced us to cleanup and fully rebuild Upsert metadata whenever servers restarted. This rebuild process is slow because it requires iterating through every record across all segments to reconstruct the metadata map and validDocId bitmaps — a process that becomes prohibitively expensive at billions of records per table.
What follows next is the series of improvements we introduced to make metadata restoration faster, with the goal of drastically reducing restart times. We’ll walk through this optimization journey — from naive full rebuilds to bitmap preloading, minion-based snapshots, and finally to our latest advancement: intelligent metadata persistence.
If you’re already familiar with all the current restoration techniques with Offheap Upserts, feel free to skip ahead to the new approach: Smart Persistence
Our Optimization journey
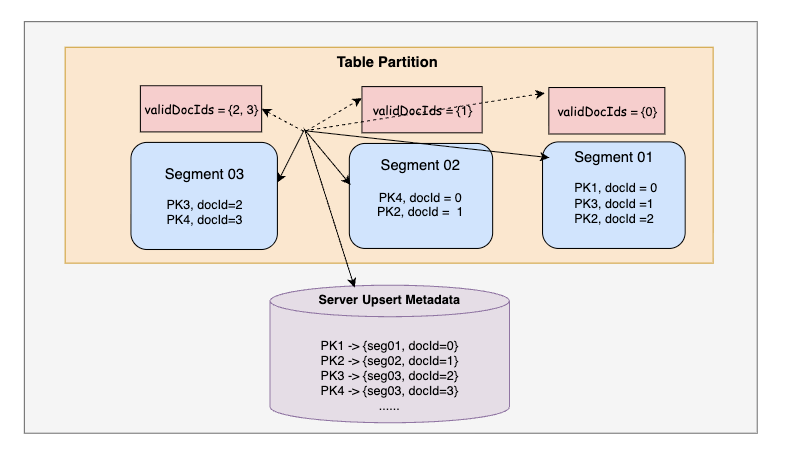
Our first approach was pretty straightforward but naive — reconstruct the entire RocksDB metadata from scratch on every restart. This meant replaying Upsert comparisons for every single document across all segments: checking for primary key existence, running comparisons, inserting metadata, and marking documents as valid. Refer Fig 3
While this process was basic and correct, it was painfully slow. This rebuild involved read-heavy operations that are CPU-intensive in RocksDB. For tables with billions of primary keys on a server, a single restart could stretch into tens of hours, turning upgrades into dreaded ordeals.
Approach 1. Preloading with persisted bitmaps
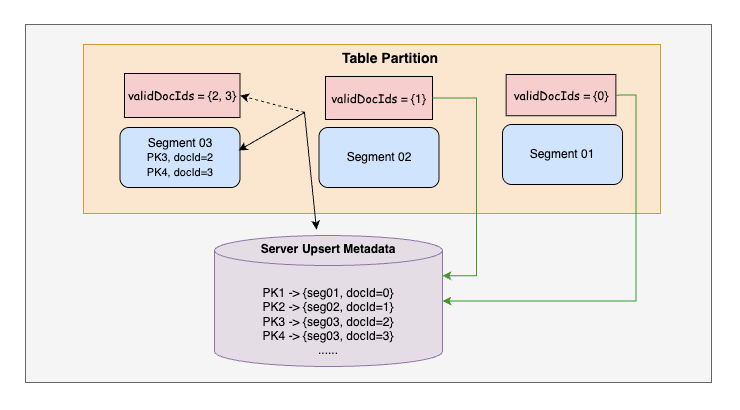
We knew there had to be a better way than replaying Upsert comparisons on every startup. Our next idea was to persist in-memory segment bitmaps to disk, so that restarts could reuse and add them into the metadata map instead of recomputing it. This eliminated redundant comparisons and primary key existence checks, significantly cutting down rebuild time.
However, bitmaps continuously change as new updates arrive, and persisting a consistent snapshot without impacting ingestion SLAs proved difficult. We couldn’t afford to put persistence in the critical ingestion path. Instead, segment bitmaps were persisted asynchronously after each segment commit. As a result, some segments occasionally lacked an up-to-date persisted bitmap. During restart, any segment without a persisted bitmap had to fall back to the standard Upsert replay logic. Refer Fig 4 for the flow.
Even with these limitations, this approach improved startup times by ~50%. However, it remained unpredictable, since success depended on whether asynchronous persistence had fully completed. And because the metadata map still had to be rebuilt in its entirety, the overall startup time was still significant.
Approach 2: Minion-based prebuilt snapshots
Because of the limitations in the previous approach, servers still took hours to start. We wanted to skip the full metadata rebuild on restart, but without risking corrupt or inconsistent states from reusing on-disk data directly.
To achieve this, we offloaded metadata generation to Pinot Minions — a component designed to handle computationally expensive background tasks. Minion jobs periodically take snapshots of the current RocksDB state and validDocId bitmaps, and then upload them to the deep store (e.g., S3 or Azure, depending on cluster configuration).
During recovery, servers bootstrap metadata and validDocId bitmaps from these snapshots, instead of rebuilding everything from scratch. Only the segments added after the snapshot creation need to be processed with the standard Upsert replay logic (Refer Fig 5)
With this approach, startup times were reduced by ~90% — a server with just 4 cores and 30 GiB memory could now load 1 billion keys in ~15 minutes instead of hours. It also streamlined cold starts, making it far easier to rebalance partitions onto nodes without existing metadata. More details are in the Blog
This approach delivered a significant performance boost — but a few bottlenecks still remained:
- Resource limitations: Downloading and extracting the metadata snapshot file (stored as tarred SST files) for eg: file ~1.5 GB size from deep store was taking around ~1 min. Even on a 16 vCore server instance and disk throughput being set to ~500 MB/s, restoring a table with ~5 billion primary keys still took ~20 minutes.
- High infra costs: Frequent snapshot generation increased infrastructure expenses as cluster size and data volume grew.
- Ineffectiveness under compaction: Frequent invalidation of segments (e.g., repeated Upsert Compaction tasks) caused many segments to be skipped by snapshots, forcing them to fall back to slower rebuild methods.
Despite these limitations, minion-based prebuilt snapshots were a major milestone in our scaling journey, cutting server downtime from hours to minutes. But as customer SLAs began demanding sub–5 minute restart windows, we knew we had to push the boundaries further and explore smarter ways to set new benchmarks.
Approach 3: Smart metadata Persistence
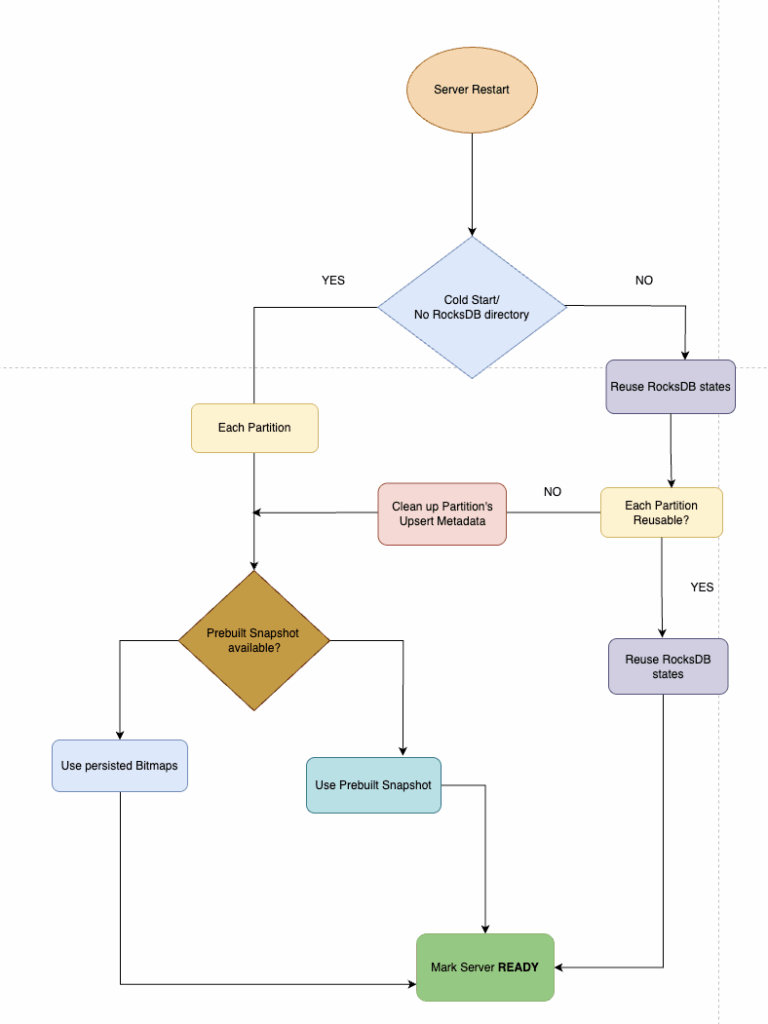
It was clear that the best path forward was to reuse the on-disk states instead of rebuilding everything, but executing this cleanly came with challenges. We needed a way to intelligently preserve metadata across restarts while ensuring data consistency. Here’s how we designed this:
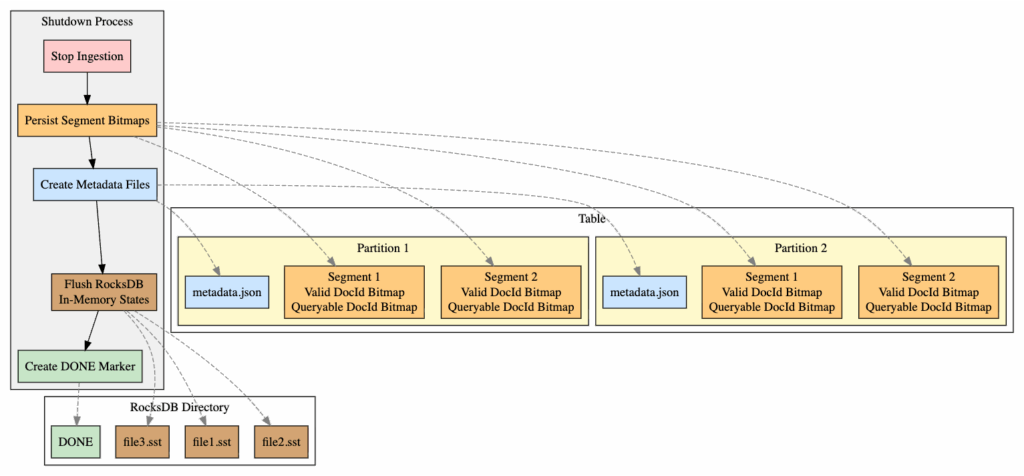
During Shutdown
When ingestion is stopped, Pinot follows a sequence of steps to persist metadata safely:
- Persist all segment bitmaps to disk (except CONSUMING segments).
- For each table partition, create metadata files cataloging the persisted metadata and segment bitmaps.
- Flush in-memory RocksDB states to disk.
- Create a marker file to indicate a clean, successful shutdown signaling that the metadata can be reused.
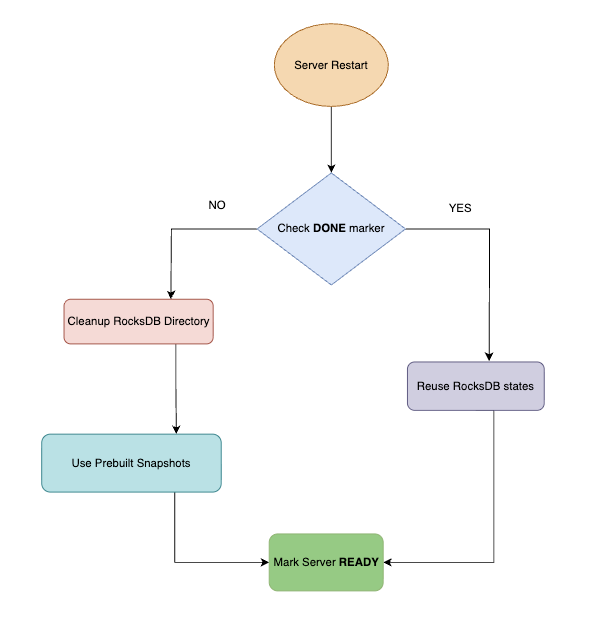
During Restart
On restart, the system backtracks through these steps:
- Check for the clean marker file in the RocksDB directory.
- If the marker exists, skip metadata rebuild entirely. Load existing RocksDB metadata and bitmap files from disk for each reusable partition.
- If a partition isn’t reusable, clean up its metadata and fall back to prebuilt snapshot preload.
- Finally, once CONSUMING segments catch up, the server is marked ready.
For consuming segments, metadata may already exist in RocksDB but the data itself hasn’t been fully committed. After all immutable segments are restored from disk, Pinot simply validates the documents of the consuming segments already present in RocksDB, ensuring they stay consistent as ingestion resumes.
Results
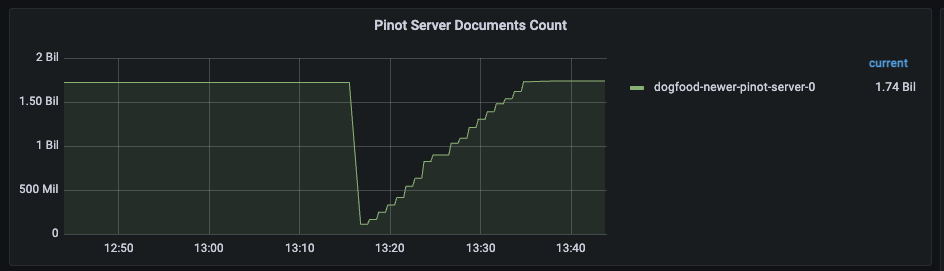
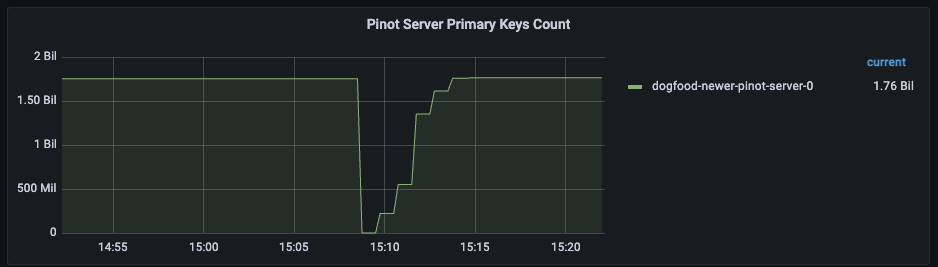
From a recent customer POC, server (16 vcore) with ~5 billion primary keys from 32 table partitions came back up in ~6 minutes with smart persistence whereas with prebuilt snapshots it was taking ~20 minutes — 75% downtime reduction.
Likewise, restoring a server having ~1.7 billion keys spread across 8 table partitions improved from ~15 minutes with prebuilt snapshots to ~4 minutes with the new optimization (Refer Fig 8 and Fig 9).
When Metadata persistence doesn’t apply
While metadata persistence covers most scenarios during restart, there are still a few edge cases where a rebuild is unavoidable — particularly when a server starts up without its saved state or without a chance to persist metadata during shutdown. One example is a cold server start, which occurs when partitions are rebalanced onto new servers. Another is a hard crash, where the shutdown sequence doesn’t complete and metadata is left inconsistent.
In these situations, Pinot falls back to minion-based prebuilt snapshots or, in some cases, bitmap preloading to restore state. The key advantage now is that these snapshot tasks can be scheduled far less frequently, thanks to the efficiency gains delivered by smart metadata persistence.
Flexibility in startup options
While the shutdown and restart flows may seem simple conceptually, in practice coordinating a clean freeze and restoring hundreds of table partitions without introducing corruption was a hard engineering challenge. We solved this by building a spectrum of startup modes — ranging from fully preserved states to complete rebuilds — giving us the ability to pick the right path depending on the situation. Refer Fig 10 for detailed flow.
Designing this flexibility required careful engineering trade-offs, but it ensures Pinot can now handle restarts safely while automatically choosing the most efficient path.
Conclusion
Through these optimizations, we’ve dramatically accelerated Pinot server restarts, reduced infrastructure overhead, and made scaling to billions of primary keys per server practical and reliable. Just as importantly, this work highlights Pinot’s ability to evolve incrementally — adding sophisticated features like Upserts without architectural upheaval and to meet the demanding needs of real-time analytics at massive scale.
Future Work
This improvement does not yet support pauseless ingestion on Upsert tables. A similar approach is planned for Dedup Tables as well. We will be enhancing this approach further to support hard server crashes, where states can be restored from existing RocksDB metadata and on-disk bitmaps. Stay Tuned.
Connect with us
Millions of concurrent users. Tens of thousands of queries per second. Hundreds of thousands of events flowing every second. If these are the kinds of numbers you operate with, aspire to handle, or are simply curious about, let’s connect! We’d love to share our lessons in serving at scale, hear your use cases, and geek out over low-latency analytics.
- Join the community slack Apache Pinot, StarTree Community
- Follow our adventures on LinkedIn StarTree
- Catch us on X Apache Pinot, StarTree
