

This article was originally based on this presentation given at Real-Time Analytics Summit. The article has been updated to reflect changes and improvements to the respective products.
Over the last decade, there has been a big shift towards ‘real-time’ OLAP (OnLine Analytical Processing) from traditional, batch-oriented, OLAP systems. Business has moved from having reports or dashboards which were hours delayed, to interactive analysis of data as its being generated – within milliseconds.
Three of the most popular real-time analytical databases are Apache Pinot, Apache Druid, and ClickHouse. This article attempts to present an in-depth comparison of these three systems. In addition, we will also look at some salient features in-depth to uncover how things work under the hood across different systems.
Comparison Structure
Here’s a simplified view of the internal layers of a typical real-time OLAP database. In the following few sections, we will go through each layer and compare the capabilities across the three systems mentioned above. The versions used for each project are Apache Pinot 1.4, released in September 2025; Apache Druid 35, released on Jan 4, 2023; and ClickHouse 25, released in January, 2025.
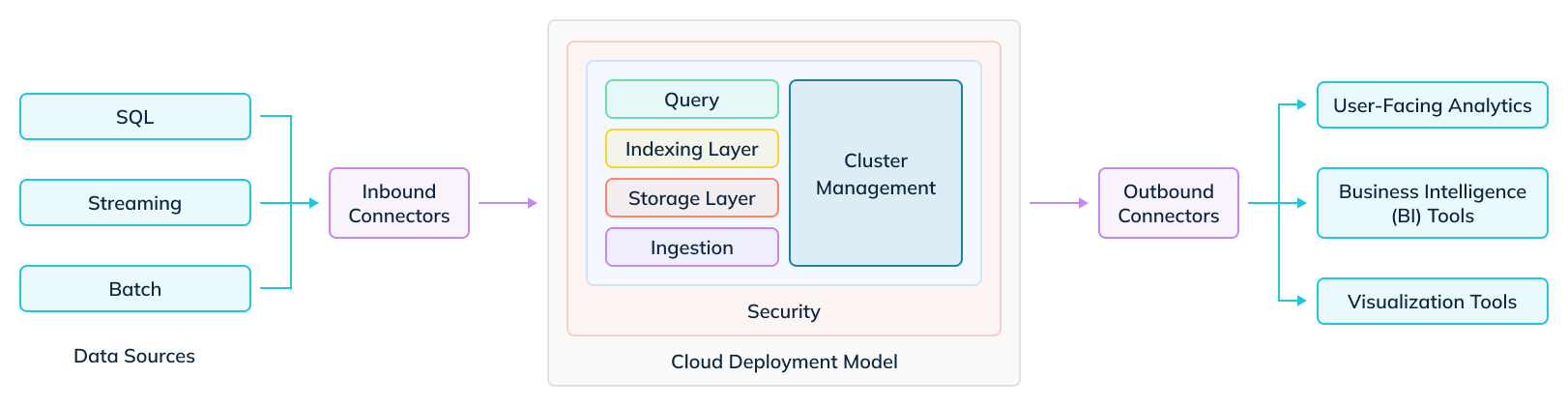
Note: There are some cases where certain capabilities are supported in the respective commercial Database-as-a-Service (DBaaS) product offerings. We will make explicit note of these in the comparison table wherever necessary.
Summary
Based on our observations, as described below in great detail, here’s a quick summary of the strengths and weaknesses of each system.
Apache Pinot
Highlights:
Apache Pinot has been designed for scale and performance with best-in-class indexing strategies and smart data layout techniques used to boost query performance, amongst other things. It has great support for ingesting data from real-time and batch data sources and is the only system that can support upserts in real-time. Overall, it’s easy to operate with rich cluster management tools and the only system to support true multi-tenancy. Lastly, the flexible cloud deployment model and best-in-class cloud tiered storage make it a compelling choice for companies of all sizes to build real-time analytical applications.
Needs Improvement:
Apache Pinot needs to improve on its data type support, outbound connectors for ease of BI integration, and SQL based pre-processing.
Apache Druid
Highlights:
Apache Druid is also designed to handle large-scale data and does a great job of ingesting from real-time and batch data sources. It has great support for data pre-processing during ingestion and also supports a flexible SQL based ingestion approach.
Needs Improvement:
Apache Druid currently does not support real-time upserts, which is needed in many critical use cases. It does not support any way to push/write data in real time. It has limited indexing capabilities and no current support for any cloud based tiered storage.
ClickHouse
Highlights
Of all the three systems, ClickHouse is the easiest to get started for new developers with the least number of components. Compared to the other two – it has a better real-time push model – albeit with some limitations. It has great data type support and very rich support for outbound connectors.
Needs Improvement:
ClickHouse has poor support for pulling data from real-time sources. (see below for why this is important). Like Druid, indexing support is also quite limited, which hinders query performance — especially when dealing with a large amount of data. Although single node deployment is easy, running ClickHouse in distributed mode is quite complex. It has some operational limitations in terms of difficulty to scale-up/out nodes, lack of multi-tenancy, and management console. In general, scalability is one of the key challenges with ClickHouse.
Ok, let’s dive into each of the layers in detail:
High-Level Architecture:
To set some context for the rest of the blog, let’s take a high-level look at each system’s architecture.
All of the real-time OLAP databases considered here are column-oriented. Columnar data formats are good for efficiently scanning only selected columns of data, minimizing storage footprint, and scanning through highly redundant data entries (also called “low-cardinality columns”).
They are also optimized to run in a cluster of servers for high availability and horizontal scalability (scale out). However, the ease of scaling and management and the way queries are handled differs greatly across the different implementations, as we will see in the sections to come.
Each of these three databases has the concept of a table, a logical abstraction representing a collection of related data composed of columns and rows. Each table’s data is broken down into small chunks, which are packed in a columnar fashion. These chunks are called segments in Apache Pinot and Apache Druid, and parts in ClickHouse.
Apache Pinot
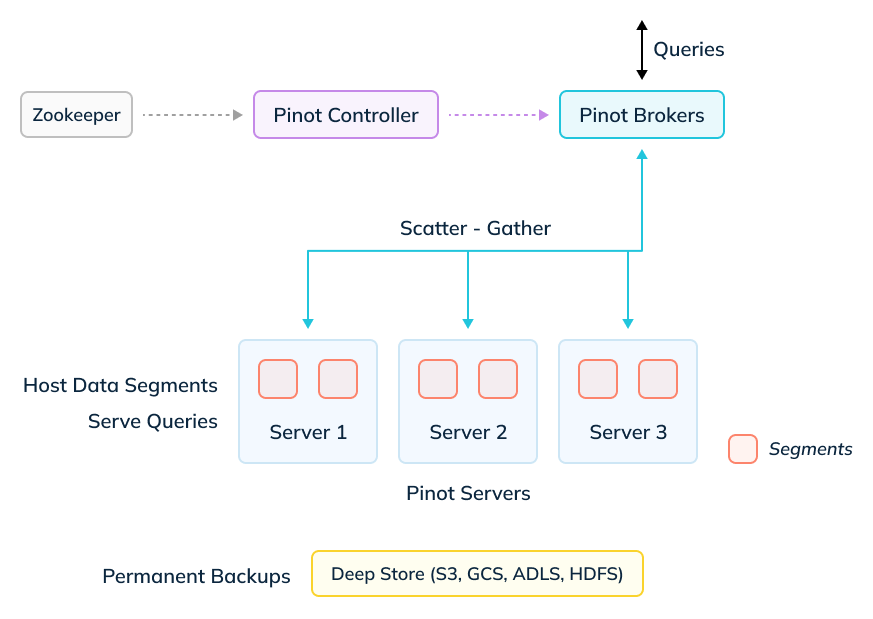
Fig: Apache Pinot architecture
- Data layer : This layer contains Servers , which store a subset of segments locally and process them at query time. Servers either pull data from streaming sources directly to build segments, or Minions can build and push segments from batch data sources. Segments are also stored onto a deep store —a cloud object store such as Amazon S3, GCS, ADLS—for permanent backups and recovery.
- Query layer : This layer contains Brokers , who receive queries from clients and perform a scatter gather to and from Servers.
- Control layer : This layer contains the Controllers , which manage all the components of the cluster. Apache Zookeeper is used as a persistent metadata store.
Read more details in the Pinot architecture docs.
Apache Druid
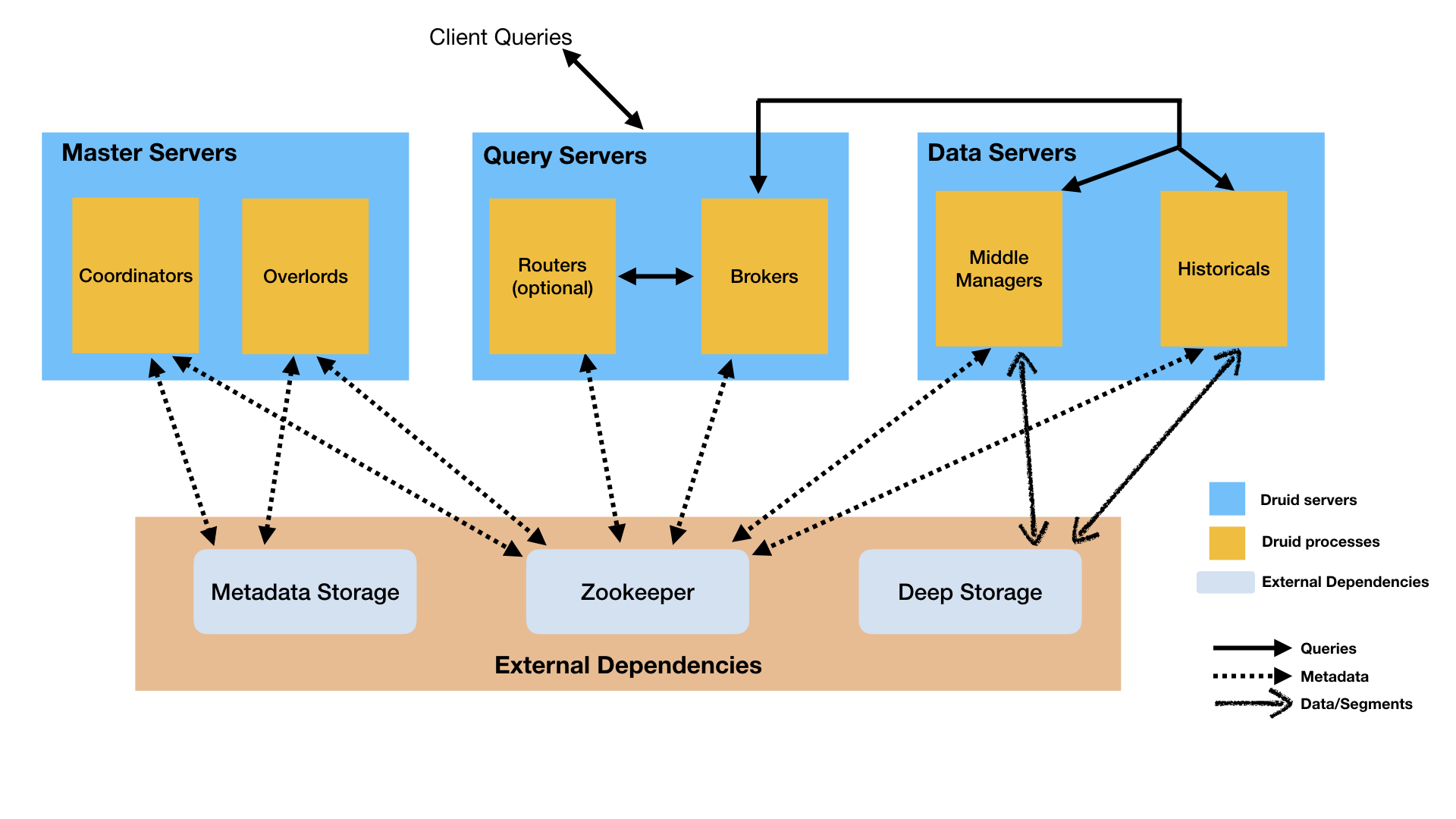
Fig: Apache Druid Architecture
- Data layer : This layer consists of Middle Managers, which execute ingestion workloads, and Historicals, which store all queryable data. Segments are stored in a deep store for permanent backup and recovery.
- Query layer : This layer contains the Brokers, which handle queries from external clients, and the optional Routers, which route requests to Brokers, Coordinators, and Overlords.
- Control layer : This layer contains the Coordinator which manages data availability on the cluster, and the Overlords, which control the assignment of data ingestion workloads. Zookeeper is used for internal service discovery, coordination, and leader election. A system like MySql or Postgres is used for segment and task metadata storage.
Read more details in the Druid design docs.
ClickHouse
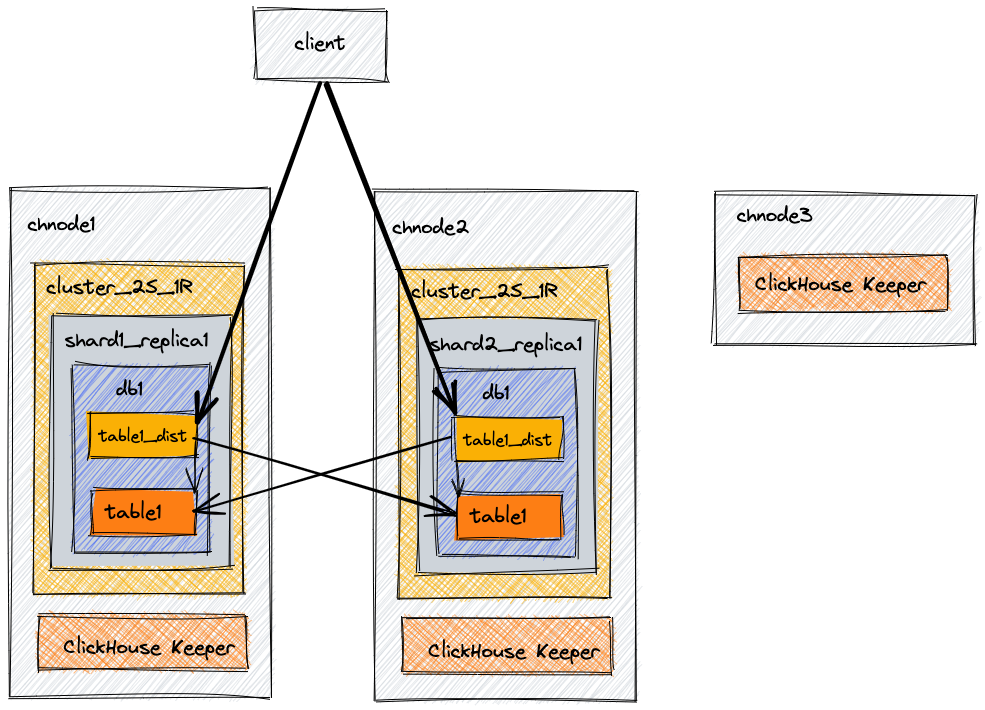
- Data layer : This layer contains the ClickHouse Servers , which host the data shards and manage ingestion. ClickHouse has no concept of a deep store for permanent storage.
- Query layer : There is no architectural separation between data and query layer. A query can be directly made to any ClickHouse server to query data on that server. Of course, data is usually distributed, so a Distributed Table would be created on some dedicated nodes to act as query nodes.
- Control layer : ClickHouse Keeper / Apache Zookeeper is used for metadata. No other centralized cluster management takes place.
Read more details in the ClickHouse “scaling out” docs.
Overall, ClickHouse has the fewest moving parts, followed by Pinot, then Druid. ClickHouse achieves this by combining many functionalities onto the same node or skipping some altogether.
While this makes getting started with ClickHouse relatively easier, several challenges arise when you hit a certain scale that comes with any practical setup.
- Scalability : Separation of concerns is always a better design for scalability – e.g. In Pinot if the rate of events goes up one can simply scale the real-time servers minimizing the impact on query latency if queries per second increase one can simply scale the brokers.
- Operational complexity : Users have to build tooling and automation on their own for every skipped functionality – e.g. distributed query routing, or cluster management operations such as replication, ingestion, and node maintenance in ClickHouse have to be set up manually, which is automatic and out-of-the-box in Pinot and Druid, making them more operator-friendly for managing production workloads.
Data Sources
This section gives a very high-level view of native ingestion support for various kinds of data sources. The corresponding in-depth details are captured in the ingestion section below.
Note : Native here means no external component is needed for that capability.
Real-Time Data Sources
Native, out-of-the-box support for real-time data sources:
| Real-time data source | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| Apache Kafka | Supported (native) | Supported (native) | Supported (Kafka Table engine / ClickPipes) |
| Amazon Kinesis | Supported (native) | Supported (native) | Clickpipes only |
| Google PubSub | Supported *StarTree Cloud | Supported (Extension) | No |
| Apache Pulsar | Supported | Not native. Can be done via KoP | Not native. Can be done via KoP |
| Change Data Capture Ability to ingest CDC stream consistently | Supported | Not supported (lack of upserts) | Limited (due to limited upsert support) |
Batch Data Sources
Native, out-of-the-box support for batch sources:
| Batch data source | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| S3 | Yes | Yes | Yes |
| GCS | Yes | Yes | Yes |
| ADLS | Yes | Yes | Yes |
| HDFS | Yes | Yes | Yes |
| Databricks DeltaLake | Yes *StarTree Cloud | Needs custom data pipeline | Yes |
| Apache Iceberg | Yes* Startree Cloud | Needs custom data pipeline | Yes |
| Apache Hudi | Needs custom data pipeline | Needs custom data pipeline | Yes |
SQL Data Sources
Native, out-of-the-box support for SQL sources:
| SQL data source | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| Snowflake | Yes *StarTree Cloud | Needs custom data pipeline | Needs custom data pipeline |
| BigQuery | Yes *StarTree Cloud | Needs custom data pipeline | Needs custom data pipeline |
| MySQL | No (can be done via CDC) | Yes | Yes |
| Postgres | No (can be done via CDC) | Yes | Yes |
Note: Although ClickHouse mentions the above systems in the integrations section, that’s primarily for query processing and not for data ingestion.
Ingestion
Before a database can run analytical queries, the data must get into the system. This is the process of ingestion . This layer deals with all the capabilities required for ingesting data into the OLAP system from various kinds of data sources, as mentioned above. As we go through the details of each data source, here are the key things to keep in mind:
- Append only vs upserts: Append only ingestion is the minimum requirement from an OLAP database. But supporting upserts provides data and query consistency.
- Pull vs push: Can the OLAP database support a pull / push based ingestion or both. Each one has its pros and cons.
- At least once vs exactly once: At-least-once semantics is the minimum requirement to ensure there’s no data loss. Having the ability to do exactly once data ingestion is great for certain business critical applications.
Real-Time Ingestion
Ingesting data from real-time data sources like Apache Kafka is integral to real-time analytics. In this section, we will look at the different ways of ingesting real-time data and compare the nuances of each system.
Pull vs Push Based Real-Time Ingestion
There are two ways of ingesting real-time data:
- Pull based: Actively poll/fetch data from the real-time data source
- Push based: Push messages directly into the database
A native pull-based ingestion model is generally considered to be better than a push-based model for real-time data ingestion. Here are the reasons why:
- Fewer moving parts: A native pull-based approach works great with systems like Apache Kafka and Amazon Kinesis and obviates the need for an intermediate connector (e.g., the Kafka Connect framework). This improves overall freshness and error probability by reducing the number of hops in the pipeline.
- More scalable: Based on empirical data, the pull-based approach supports higher throughput than a corresponding push-based approach.
- Ease of replication: The pull-based model makes it very easy to replicate data since all replicas can fetch independently from the data source. In addition, strict partition ordering within the data source also alleviates the need for strong coordination among replicas to keep them in sync. For instance, replicas can all agree on the same Kafka offset to ensure data synchronization. A push-based model has to deal with the overhead of how to keep the replicas in sync.
- Ease of exactly once semantics: A pull-based model makes it easier to guarantee exactly once semantics with systems like Kafka. Arguably, a push based model has to do more work to ensure correctness in this case.
Need for Push Based Ingestion
There are certain cases where push based ingestion is preferred. For instance, in some cases, the real-time data might be generated directly by an application/service without any Kafka in the picture. In other cases, even though data might exist in a Kafka cluster, pull based ingestion may not be possible due to network connectivity issues (eg: Kafka in another VPC without any inbound access). For all such cases, we need the ability to push events directly to the database.
Next, we’ll go through each such mechanism in more detail.
Pull Based Ingestion
| Capability | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| Real-time pull modelAbility to fetch data from real-time sources | Native support which provides high ingestion performance and low ingestion latency | Native support which provides high ingestion performance and low ingestion latency | With workarounds **See Below |
| Out-of-order handlingAbility to handle late arriving events in real-time | Supported | Supported. Out of order events will end up generating smaller segments | Supported |
| Real-time ingestion scalabilityAbility to handle very high ingestion rate (messages/second) | High Can sustain high incoming message rate | High: Can sustain high incoming message rate | Moderate-Low because of the complex setup described below |
| Exactly once ingestion guaranteesAbility to persist messages from the data source in an exactly once manner in the database | Supported | Supported | Not supported in pull based approach |
| Stream partition changesAutomatically handle partition changes at the source | Supported | Supported | Supported |
** ClickHouse does not have a true pull based model but you can get similar behavior with a more complex setup. For example, in the case of Apache Kafka users need to configure Kafka table engine + Materialized view + MergeTree. Ultimately, data is still being pushed into the MergeTree family table. Real-time data goes through multiple hops before it can be queried by the user. (see Integrating Kafka with ClickHouse) In general, this approach has a bunch of limitations:
- Higher ingestion latency due to large batches of data
- Chance of duplication
- Cloud Readiness
To understand the reasons behind this, let’s look at the role of Apache Kafka in real-time analytics.
Apache Kafka Integration: Apache Pinot & ClickHouse comparison
It can be said that the real-time analytics journey began with Apache Kafka. The popularity and widespread adoption of Kafka in nearly every major company worldwide has made it one of the most important sources of real-time data. Apache Pinot was designed to integrate well with Apache Kafka and has excellent support for handling a high ingestion rate, out of order events, and exactly once semantics.
As noted in the table above, Druid and Pinot are very similar in terms of Kafka integration, whereas ClickHouse took a very different approach. This section will focus on these differences between Pinot and ClickHouse.
Low-Level vs Consumer groups
Internally, ClickHouse uses Consumer Groups within the Kafka Table Engine to fetch data from Kafka. This has many issues, including message duplication, scalability challenges, fault tolerance, and so on, as described in this talk about Pinot’s journey away from the Consumer group approach. Conversely, Pinot evolved to use a low-level Kafka consumer approach that addresses all these issues.
Ingestion Latency
Ingestion latency is defined as the amount of time between an event being produced at the source and the event being queryable in the database. Kafka Table Engine in ClickHouse reads messages in large batches. Default is mentioned as 64K, and higher batch sizes are recommended.500K to 1 Million entries per batch are not uncommon). Needless to say, this will result in higher ingestion latency. Pinot, on the other hand, is able to stream data in much smaller batches – almost 3 orders of magnitude lower thus leading to much lower ingestion latency without adding any additional overhead.
In our recent comparison study of ingestion freshness between Pinot and Clickhouse, we measured ingestion latency for Pinot vs Clickhouse as shown in this chart:
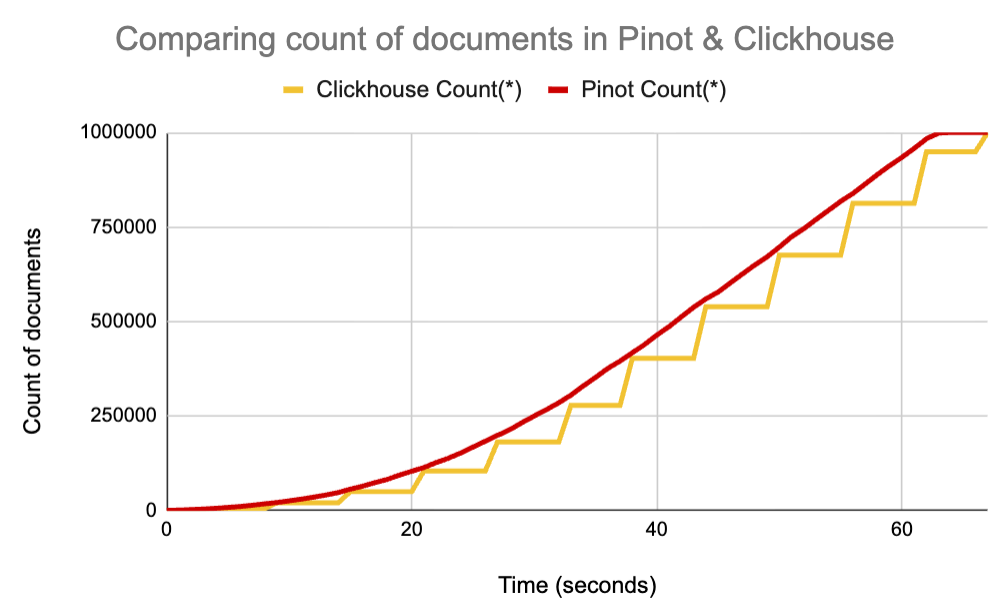
Because of the micro-batch ingestion pattern in Clickhouse, we see visible “plateaus” in the ingestion latency whereas events are queryable within milliseconds in case of Apache Pinot.
Data Duplication
The recommended pull ingestion mechanism in ClickHouse is not only complex, but it can also result in data duplication. The recommended way to resolve those is to use ReplacingMergeTree, which has its own issues as discussed in the upsert section. On the other hand, since Pinot generates segments in lockstep with Kafka offsets – it’s guaranteed to not generate any duplicates (unless duplicates are present in the Kafka stream itself, which can also be handled by Pinot – see Upsert section below).
Scalability
In ClickHouse, the number of servers is limited by the number of Kafka partitions and, therefore, difficult to scale. In the case of Pinot, segments can be automatically moved to different hosts.non-consuming), which makes it very easy to scale and not limited by the number of Kafka partitions.
Data Replication
As mentioned previously, a pull based approach makes data replication in Pinot much simpler by relying on Kafka offsets for coordinating across replicas. On the other hand, since ClickHouse does not have a pure pull model, it has to rely on a much more complex replication system. For each batch of data inserted into the ReplicatedMergeTree family table, metadata is written to Zookeeper / ClickHouse Keeper. It’s important to note that this happens in the fast path of data ingestion, and having a strict dependency on Zookeeper / ClickHouse Keeper is quite a bit of an overhead.
Cloud Readiness
It appears that Kafka Table Engine is not GA in ClickHouse Cloud and the recommendation is to use alternate approaches (eg: push based techniques). Conversely, Pinot has productionized Kafka integration over the last several years and is fully supported in StarTree Cloud.
Push Based Ingestion
As mentioned before, push based ingestion is often needed to get around Kafka dependency or network connectivity issues. Let’s take a look at how it works in the three systems:
| Capability | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| Real-time push modelAbility to insert records in real-time | Experimental feature Supported in StarTree Cloud. In addition, Apache Pinot also supports writing batches of data via Segment Writer API | Supported on older versions. (with Tranquility) Not guaranteed to work with newer versions. Apache Druid does have the ability to do a batch insert using the SQL based ingestion approach | Supported However, the recommendation is to use bigger batch sizes during data ingestion. As mentioned previously, this comes at a cost of higher ingestion latency |
| Out-of-order handlingAbility to handle late arriving events in real-time | Supported | N/A | Supported |
| Real-time ingestion scalabilityAbility to handle very high ingestion rate (messages/second) | Limited as compared to the pull model | N/A | Limited as compared to the pull model |
| Exactly once ingestion guaranteesAbility to persist messages from the data source in an exactly once manner in the database | Currently not supported | N/A | Supported via Kafka Connect Sink for ClickHouse Relies on a complex design that uses a hash of insert data blocks which is stored in ClickHouse Keeper (like Zookeeper) for de-duplication. |
Real-Time Upserts
In the case of real-time event streaming data sources such as Apache Kafka, duplicate or upsert events may exist in the stream. Several mission-critical use cases require the database to handle such events during ingestion to ensure accurate query results. Uber’s financial dashboards, Citi’s risk monitoring, and many others rely on upserts to ensure business continuity. This section compares how the different systems handle such events.
| Capability | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| Full row upsertAbility to upsert an existing row with a new row having the same primary key. | Supported | Not supported during ingestion | Limited support during ingestion The recommended way is to use ReplacingMergeTree which handles upsert events asynchronously. This means queries results may not be accurate. This asynchronous process typically happens every 9-10 mins or not at all (in case of not enough data) – thus leading to severe query inconsistency issues. It is possible to perform mutations (alter table) synchronously via this flag: mutations_sync to 2. However this is not recommended to be used since updating is a very expensive step in ClickHouse. |
| Partial row upsertAbility to upsert certain columns in schema with new values for the same primary key | Supported | Not supported during ingestion | Supported with same caveats as above |
| Real-time DeduplicationAbility to de-duplicate incoming rows based on a primary key | Supported | Not supported during ingestion | Supported with same caveats as above |
| ScalabilityAbility to handle large number of primary keys | Supported *StarTree Cloud | N/A | Limited due to the above caveats |
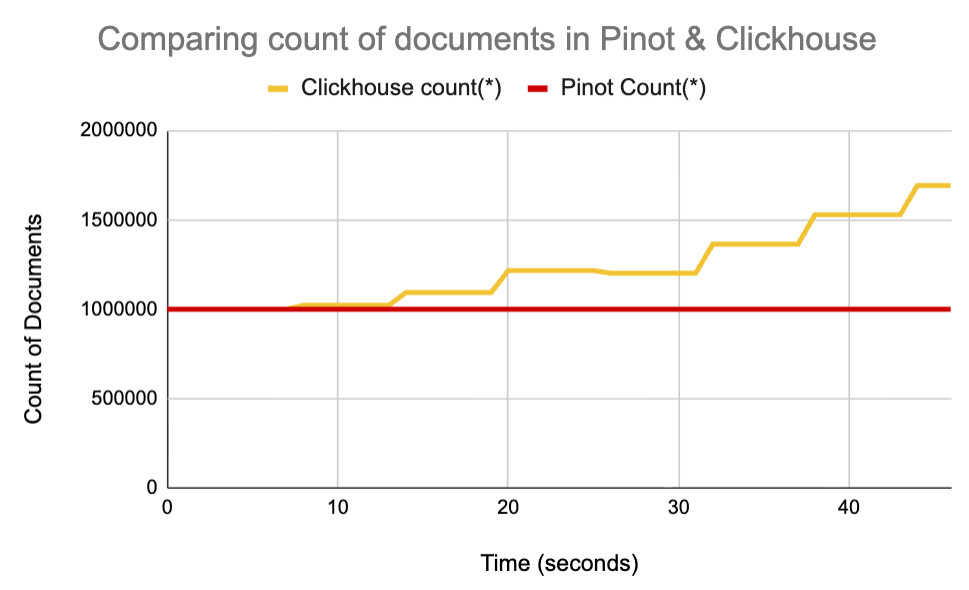
Note that both Apache Druid and ClickHouse claim the ability to do upserts. However, they require complex workarounds such as batch insertions, query time aggregations, or a complex data model that is difficult to generalize.
In our recently published study, we measured the query accuracy in presence of realtime upserts between Pinot and Clickhouse which is shown here in this chart:
Upserts in Pinot
Pinot has great support for handling upsert events in the incoming real-time stream for event-streaming technologies like Kafka. This is done without sacrificing ingestion and query performance and maintains real-time data freshness — which is not true in the case of the other systems.
How does it work?
Users can enable upserts in a real-time Pinot table by specifying a primary key (see the Stream Ingestion with Upsert docs.. Each server in turn maintains a map of the primary key to the location of the latest version of the record for that key. When an existing record is upserted by a new one, the server uses this map to mark the old record as obsolete using a per segment bitmap. All such obsolete records are then filtered out during query execution. This design ensures least overhead during ingestion and query time and works at scale.
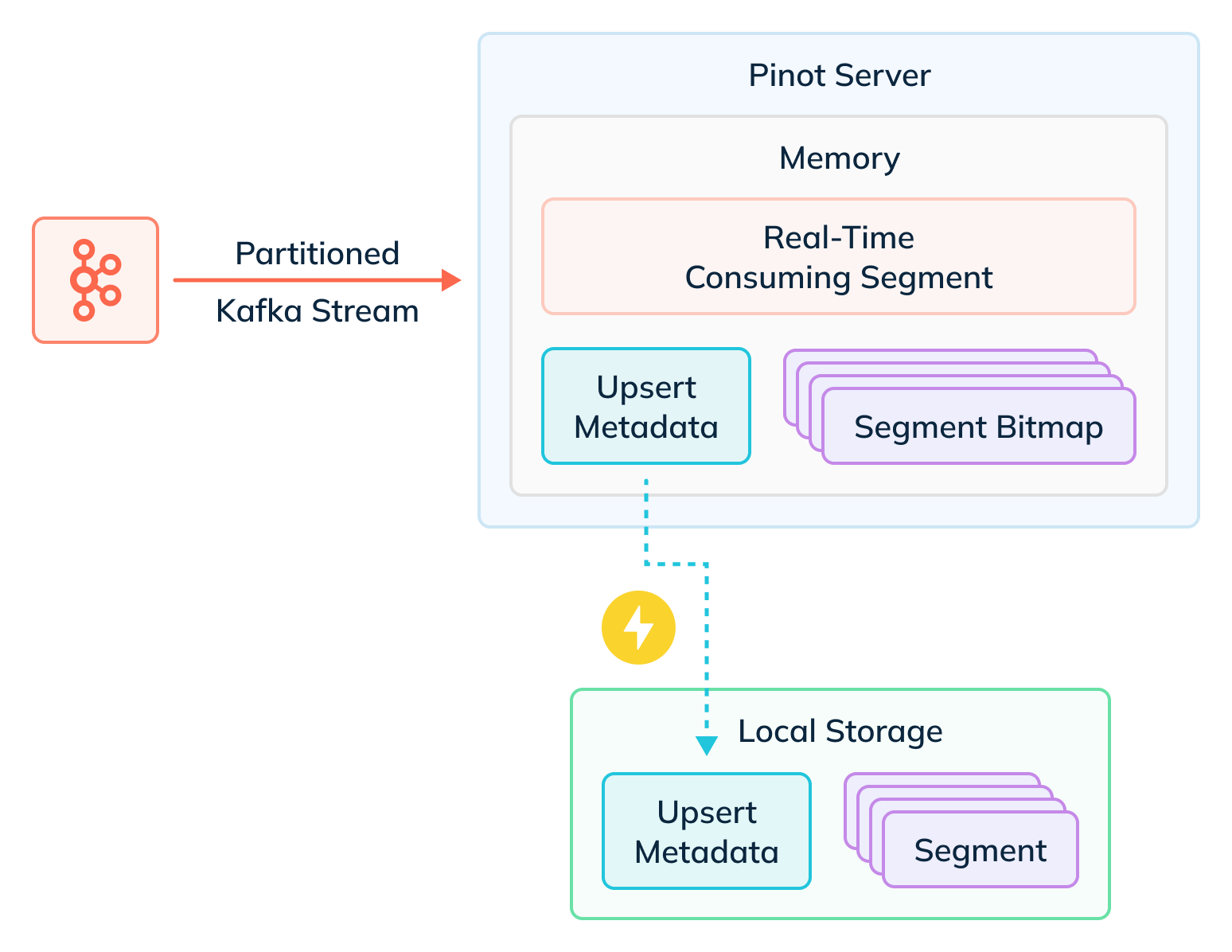
Scalable Upserts with StarTree Cloud
One caveat of upserts in Pinot was the memory overhead experienced by Pinot servers when a large number of primary keys are involved. StarTree Cloud removes this limitation by eliminating the in-memory requirement of managing upsert metadata. StarTree Cloud workspaces can easily handle billions of primary keys per server without sacrificing performance.
Some of the highlights related to upserts include:
- Time To Live ( TTL): for the primary keys — helps in reducing the footprint of the upsert metadata and thus memory overhead on the server.
- Compaction: ability to delete obsolete records and improve storage efficiency
- Ease of bootstrap: Bootstrapping historical data in an upsert table is currently challenging. Some users rely on a Flink Pinot connector to push historical segments in the real-time upsert enabled table. We will be adding native support for this shortly.
Read more about realtime upsert support in Pinot and StarTree.
Batch Data Ingestion
A native, out-of-the-box support for importing data from batch data sources (e.g., S3 or GCS) is crucial for developer productivity. Otherwise, users must maintain custom data pipelines, which becomes a big overhead to maintain and scale up.
| Capability | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| Pull based Batch Ingestion Native Support for batch ingestion by pulling data from remote data sources | Yes Scalable and performant. Uses a background task framework to ingest data from batch data source into Pinot. Most of the work is done outside of Pinot, with minimal impact on query performance. | Yes Scalable and performant. Uses a background task framework to ingest data from batch data source into Druid. Most of the work is done outside of Druid, with minimal impact on query performance. | Supported via ClickPipes Scalable and performant. Clickpipes provides one time load as well as continuous ingestion. Data is inserted in batches into a live Clickhouse cluster. This can impact query performance. |
| Batch ingestion input format Additional supported data formats for batch ingestion | JSON CSV/TSV ORC Parquet Avro Protobuf ThriftSee Input Formats in the Pinot docs for details | JSON CSV/TSV Kafka* ORC Parquet Avro Stream Avro OCF ProtobufSee Data Formats in the Druid docs for details. * Kafka by header, key, value | JSON CSV/TSV ORC Parquet Avro Protobuf Arrow CapnProto and many more!See Formats for Input and Output Data in the ClickHouse docs for details. |
| Push based ingestion: Native support for pushing large batches of data from remote data sources | Supported (Spark and Flink connectors available) | Supported (no built-in connector) | Supported Official Spark connector. |
| At least once semantics | Supported | Supported | Supported |
| Exactly once semantics | Supported at segment level | Supported at segment level | No native support. Needs custom pipeline |
SQL Data Ingestion
SQL data ingestion can be done in 2 ways – using CDC (Change Data Capture) in real-time or in a batch manner. This section covers the batch oriented ingestion from SQL data sources.
| Capability | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| Native support for one time ingestion (bootstrap) from SQL sources | Supported *StarTree Cloud | Supported | Needs custom data pipeline |
| Native support for incremental ingestion from SQL sources | Supported *StarTree Cloud | Supported | Needs custom data pipeline |
Batch and SQL ingestion support in StarTree
StarTree provides a native, out-of-the-box support for ingesting the batch and SQL data sources mentioned above. Read No-code Batch Ingestion for Apache Pinot in StarTree Cloud for more details. This is done by a background job that runs alongside the primary cluster.
Key benefits:
- Easy to use: There is no need for additional ETL tools for most common scenarios.
- Efficient: Segments are generated by the background job outside the primary cluster and pushed to the server serving live queries, with negligible impact
- Robust: Ingestion tasks are checkpointed and retried upon failures
- Scalable & cost efficient: auto-scaling is enabled in StarTree cloud for elastic scale-up/down of the ingestion tasks
Ingestion time pre-processing
Often, data needs to be pre-processed before it can be ingested and queried in Pinot. Examples include flattening a complex JSON structure, rolling up data, or type/value transformation. Let’s look at some of the popular pre-processing capabilities requested by users.
| Capability | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| Ingestion time transformsBasic filtering, type/value transformation applied as data is being ingested | Rich filter and transformation function support Filter functions: We can use either Groovy expressions or built-in scalar functions for filtering (see Ingestion-Level Transformation in the Pinot docs). Rich transformation function support including Groovy expressions as well as built-in functions for string, math, JSON, datetime computation and so on. A full list of Pinot functions is available in the docs. | Rich filter and transformation function support Various types of built-in Filter functions including JavaScript, regex, logical, extraction, column types and so on (see Query Filters in the Druid docs). Transformation functions including string, math, time, array, JSON, lambda and other operators. | Limited support Data can be transformed via the insert into select clause from another table (Materialized View). However, there doesn’t seem to be a way to apply filtering or aggregation functions during ingestion itself. |
| FlatteningFlatten a nested schema often needed for query optimization | Yes Built-in flattening support for nested JSON records. In addition, users can also use the json_extract transformation function. In general, a JSON column and an optional JSON index is recommended to accelerate query performance on JSON/nested fields. | Yes Convenient way of flattening nested records using FlattenSpec. | Yes When using the new JSON column Clickhouse will automatically flatten it into sub-columns based on a limit (max_dynamic_paths). The legacy method was to use the flatten_nested spec |
| Rollups during Real time ingestion | Supported Variety of ingestion aggregation functions such as SUM, MIN, MAX, DISTINCTCOUNTHLL. Currently, specifying granularity/interval is not supported, but can be achieved with derived columns. | Supported Variety of aggregation functions such as SUM, MIN, MAX, Approximate (Sketches). In addition, it’s possible to define custom granularity, interval (see Ingestion Data Rollup in the docs). | Limited Support Can use SummingMergeTree or AggregationMergeTree for rolling up records based on a specified primary key in the background (not during ingestion). |
| Rollups during batch/offline ingestion | Supported.SUM, MIN, MAX, DistinctCountHLL, Theta sketches) | Supported | Limited: Same as above (use the right MergeTreeFamily) |
| SQL based ingestion transformFlexible way of inserting data into a table based on the output of a SQL query | Not Supported | Supported with the new Druid multi-stage query engine. | Supported with insert into select clause. |
| Denormalization supportDenormalize data from multiple sources during ingestion | Not Supported | Basic support using Druid MSQ: Insert with Join: limited to dimension tables | Limited to existing tables in ClickHouse using insert into select clause |
| Ability to partition data during ingestion | Supported for batch sources. In case of real-time sources, partitioning scheme is tied to the source (Eg: Kafka/Kinesis) | Supported for batch sources. In case of real-time sources, partitioning scheme is tied to the source (Eg: Kafka/Kinesis) | Supported for MergeTree family tables. As data is inserted, it can be partitioned as configured by the PARTITION BY spec |
| Ability to sort data during ingestion | Supported for batch sources on any dimension (limited to 1 dimension) | Druid is limited to sorting by timestamp as the primary sorted dimension | Supported for MergeTree family tables using the primary key |
Table Management
Table data often needs to undergo some change after ingestion to keep up with changes in the data or the workload. This section compares how the three systems fare in this area.
| Capability | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| BackfillsAbility to replace the data in the database for a certain time range or condition, using data from another batch or streaming source (e.g. replace data for the 3am hour two days ago, using files in an S3 bucket). Useful when data needs to be corrected due to upstream changes or issues. | Backfill is easily possible if the table is time partitioned, which is often true for offline tables. Realtime tables are not naturally time partitioned, but tools are available to time-partition and then execute a backfill. | MaybeCould not find documentation or recipes, but seems possible by design. | PartialSupport is available for making small scale additions, updates and deletes to columns. No support for large backfills for time ranges to data. |
| Dynamic re-indexingAbility to dynamically add remove indexing for columns of the table, without needing a full bootstrap or downtime. This is extremely useful when iterating between optimizations during initial setup. | Yes Easily add or remove indexes with no downtime by making config changes followed by a reload operation. | YesCan be achieved via reindexing, which refers to a reingestion task that can apply any changes to existing data. However, this is modeled as batch ingestion with existing data as source, effectively making it not-in-place. | YesSkipping indexes can be added / removed dynamically. |
| Dynamic data layout changeSupport for making changes to the data layout such as partitioning, sorting, bucketing, rollups, resizing dynamically without having to rebootstrap and without downtime. Picking the right layout based on the data and workload aids better compression, optimized routing, segment pruning and scanning, which helps improve performance. | GoodNative support for roll ups and merge via Minions which handles partitioning, bucketing, trimming. Partitioning: Yes Sorting: Yes (StarTree Cloud) Bucketing: Yes Rollups: Yes Trimming: Yes | GoodCan be achieved through overwrite, which is essentially re-ingestion using the existing data as source. Partitioning: Yes Sorting: Custom sorting itself is not supported, so this is NA Bucketing: Yes Rollups: Yes Trimming: Yes | LimitedWhile some operations like altering columns / deleting columns can be done via mutations, the ones involving entire data layout changes can only be done by dropping and recreating the data. It can be achieved by creating a materialized view or projection but this solution increases storage footprint, defeating the purpose of some operations like rollups and trimming. Partitioning: No Sorting: No Bucketing: No Rollups: No Trimming: No |
Schema Management
This section compares the three systems on schema characteristics, such as native support for data of varied types and being able to evolve the schema.
| Capability | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| Data typesExtensivity of data types supported as compared to SQL databases. Native data types are easier to use and in their absence, columns need to be modeled as strings which can be inefficient for compression and access. | BasicBasic data types such as int, long, float, double, char, string, boolean, bytes, in addition to some special ones like big decimal, geo types, JSON. No array support like SQL, multi-value columns semantics are like column explosion. | Basic Basic data types broadly in the categories of int, long, float, double, char, string, boolean. No array support like SQL, multi-value columns semantics are like column explosion. | Rich set of data types supported natively in comparison to Druid and Pinot. Along with the basic int, long, float, double, string, boolean, many specialized ones such as UUID, Enum, Array, Map, tuple, geo types, IP. expression, set. |
| Nested ColumnsSupport for ingestion and fast query of unstructured / semi-structured nested columns. Such support helps eliminate the need for data pre-processing workflows to extract data from nested structures. | SupportedStrong support for nested columns ingestion, with strong indexing support during query time. | Supported | SupportedGood support for ingesting and storing JSON either as structured or semi-structured objects using string/JsonObject |
| Schema EvolutionAbility to make schema changes dynamically, in place. This is needed as data keeps evolving, and the system needs to react fast so as to not miss these changes. | YesSchema changes possible and reloads functionality to make changes take effect | With new data only Supported for new data, but for existing data, documentation suggests to go with reindexing which is called out as time consuming since it is a full overwrite of data | Possible with mutations |
Storage
As mentioned earlier, each of these databases has a columnar storage format.
- At a columnar level, there are differences in compression & encoding schemes which further affect the storage footprint and access latencies.
- At a segment level, data layout configuration options help increase pruning.
- At a server level, smart storage mapping strategies help drastically reduce query-fanout, further reducing latency and boosting throughput.
- At a cluster level, the availability of storage options (multi-volumes, cloud object storage) and the ability to create storage tiers for hot / cold data to control cost-latency trade off, greatly improves cost to serve.
This section looks at the above aspects for the three systems.
| Capability | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| EncodingTypes of dictionary encoding available. These impact column size which affect access latency and cost to serve. | Dictionary encoding done by default.Ability to skip dictionary encoding based on configurable compression ratio. Option to create a variable length dictionary for string / bytes columns for better compression. Ability to load dictionary on-Heap for faster access | Dictionary encoding. No ways to smartly determine when to skip this encoding, or create any advanced / nuanced dictionary encodings. | Dictionary encoding via LowCardinality data type.No advanced thresholds available, other than cardinality based disabling of LowCardinality. |
| CompressionStandard / specialized techniques available to compress columns. These impact column size, which affect cost to serve. | snappy, lz4, zstd | lz4, lzf, zstd | z4, lzf, zstd Plus some specialized codecs like delta, double delta, gorilla, fpc, t64. |
| Data layout: PartitioningControl the data layout in terms of custom partitioning. Partitioning data helps with pruning servers / segments reducing query fanout. | Can choose custom keys for partitioning | Data always partitioned by time column first, and a secondary partitioning can be done using a custom key. | Can choose a custom key for partitioning |
| Data layout: SortingControl the data layout in terms of custom sorting. Sorting data helps improve data locality and enable smarter encoding (like RLE) reducing work done in applying filters during scans. | Ability to pick any column as sort key | Always sorts by primary time column. No option to make a column of your choice as primary sort column (can set a secondary sort column). | Ability to pick any column as sort key |
| Data layout: Strategies to reduce query fan outAbility to use smart instance assignment and segment assignment. These strategies help reduce query fanout which improves latency, throughput and operability. | Highly mature and advanced strategies for segment assignment This helps achieve better p99 latency and throughput, plus instance assignment strategies available, to improve ease of operations. More details in the ‘Data Layout’ section below. | LimitedOnly strategy available for segment to instance assignment is the balanced strategy which distributes segments evenly on historical nodes. Druid does allow clustering to improve data locality | NoDocumentation doesn’t indicate the existence of any advanced segment to instance assignment strategies. |
| Tiered Storage using local storage / compute nodes separationAbility to split hot / cold data onto multiple local (or directly-attached) volumes or onto different compute node tenants. For example, some local storage volumes might be fast NVMe SSDs, and others slower HDDs. | Two types 1. Multi-volume tiering using different types of local volumes 2. Compute node separation using multiple tenants | One type1. No tiering using multi-volumes on same tenant 2. Supports compute node separation using service tiers. | One type: 1. Tiered storage support using multi-volumes 2. No compute node separation due to the absence of tenant / tagging concepts. |
| Tiered Storage using Cloud Object StorageAbility to split hot / cold data between local and cloud object storage. While reducing cost to serve is one aspect of this feature, the design choices need to be made carefully as we still want the database to be fast. | Tiered storage using cloud object storage available in StarTree Cloud. Cloud object store as a tier supported in StarTree Cloud. Fully on par with local mode, no restrictions on data altering. All indexes available Several optimization techniques like prefetching, pipelined fetch and execution, columnar / block fetch for performance Caching available in addition, for further speedup, but no dependence on it Works with both Pinot segment as well as Parquet format on StarTree Cloud | No support for tiered storage using Cloud Object Storage | Tiered storage support using cloud object storage. One big limitation of this approach is lack of indexing support. Key features include: Supports open file formats like gzip, parquet, csv Can prefetch granules async Limitations: No data altering support. Documentation mentions no indexing support, but this article says index and mark files can be cached locally. No columnar fetch, always reading granule which contains all columns. Relies on caching (lazy loading) to make cold tier queries fast. |
Data Layout: Strategies to Reduce Query Fanout
This blog post talks about the lifecycle of a query in Apache Pinot and the optimizations available at each point – from broker, to servers, to segments, to columns – to reduce the amount of work done. This section focuses on query fanout – reducing the number of nodes a query is scattered to. Reducing the fanout helps eliminate long tail latency (your query will be as slow as the slowest server) and, in turn, helps improve throughput.
The strategies available in Pinot to map the data segments onto servers and enhance pruning at broker level are:
- Balanced: This strategy simply distributes segments evenly and is also the only strategy adopted by Druid and ClickHouse.
- Replica-group: This strategy creates groups of servers such that an entire replica of the dataset is constrained to each group, thus reducing server fanout and being able to scale horizontally for higher throughput.
- Partition-based replica-group: This strategy further creates partition based groups to reduce segment fanout within a replica group.
The strategies available in Pinot to map the tables onto servers and improve ease of operation are:
- Creating pools for a no-downtime rolling restart of large shared clusters
- Fault-domain aware instance assignment
Tiered Storage using Cloud Object Storage
Each of the three systems started with having tightly coupled storage and compute, wherein they used compute nodes that included local or directly attached high performance storage, such as NVMe SSDs. This is one of the reasons that make them suitable for low latency.
However, local high-performance storage is expensive compared to decoupled systems that primarily use cloud object storage. Cloud storage is cheaper but slower and, therefore, usually unsuitable as the sole storage layer for interactive real-time analytics. Simply choosing one of these two systems for all analytics needs does not make sense.
Real-time (or recent) data tends to be more valuable and is queried more frequently. On the other hand, historical data is queried less frequently. Latency is still important, but with this data being large and ever growing, cost becomes a dominating factor. Data teams often choose a hybrid approach where they add both systems and migrate the data from one to another depending on cost / latency expectations. Therefore, many users need to consider how to span their data, choosing what they wish to store in high performance local storage and what is placed on slower but more cost-effective cloud storage.
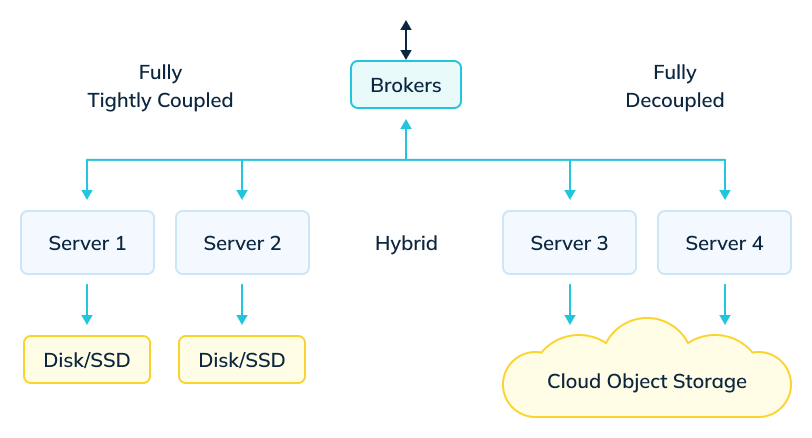
Tiered storage for Apache Pinot in StarTree Cloud is designed to address this problem. With the option to use cloud object storage such as S3 / GCS directly in the query path, Pinot can now act as a hybrid system — it can use completely decoupled or tightly-coupled storage or have a mix of both. It lets you flexibly configure data to be on any tier and query it all seamlessly like any other table.
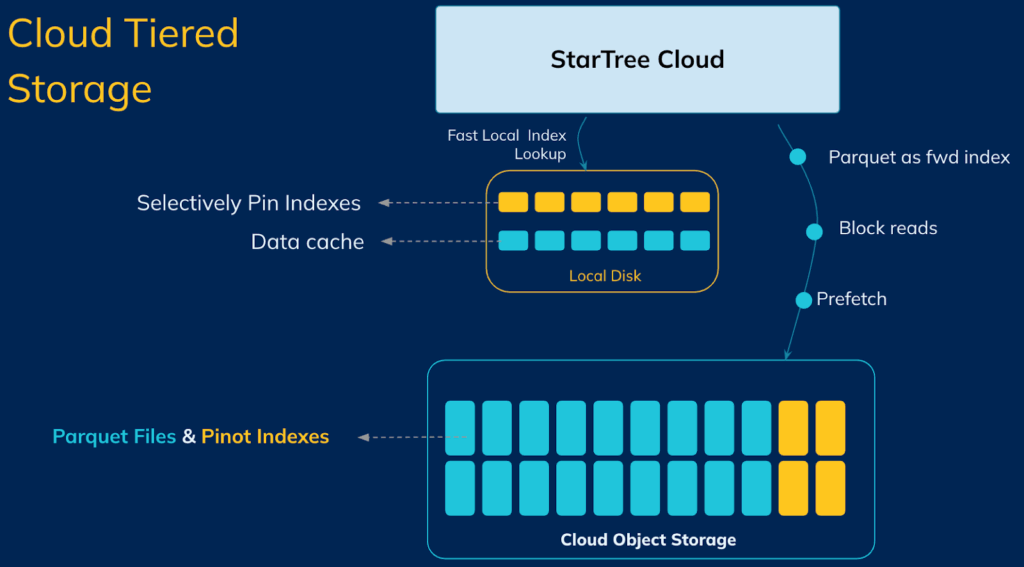
Most importantly, several investments have been made to reduce the latency issues that come with using decoupled storage. For instance, the design consciously stays away from approaches such as lazy loading — where entire segments would be downloaded during query time — or using local caches. Typical OLAP workloads consist of arbitrary slice-and-dice over varying time ranges, and caching-based approaches cannot offer predictable p99 latency due to the frequent download and churn of segments.
Instead, the tiered storage approach in Pinot for reading from cloud object storage uses strategies such as selective columnar / block reads, smart prefetching, pipelining fetch and compute. These optimizations, along with the ability to use the army of native indexes available in Pinot, help Pinot achieve the best of both worlds — reduced cost to serve while keeping the speed of Pinot.
These optimizations are depicted in the diagram below:
Remote Iceberg Tables
A special case of cloud tiered storage is the ability to execute queries directly on an existing Iceberg table backed by a cloud object store (eg: Amazon S3). This is a crucial, cost effective feature for serving analytical queries without having to ingest large datasets.
ClickHouse
ClickHouse provides an Iceberg table engine and a table function for executing queries against a remote Iceberg dataset. It has support for some Iceberg specific features such as time travel, positional deletes and limited schema evolution. Its optimized for adhoc analytical workloads on Iceberg tables.
Apache Pinot
StarTree cloud has recently added support for configuring remote Iceberg tables in Apache Pinot. It currently provides support for Iceberg REST catalog with append only mode. Support for deletes, time travel will be added in early 2026. One key differentiator of this implementation is the ability to run extremely low latency, high QPS analytical queries at a fraction of the cost. This helps unlock several internal and external facing analytical applications for serving insights directly from Iceberg.
Read more about how Pinot and Startree Cloud were able to drive more than 500 QPS analytical queries with sub-second latency.
Indexing Strategies
Indexing is a fundamental function of a real-time OLAP database which ensures queries can be executed efficiently and perform minimum data scans. In this section, we will compare the indexing strategies available across the three systems and also dive into why this is important.
| Type of Index | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| Inverted IndexFast Filter | Supported | Supported | Experimental |
| Sorted IndexPersonalized Analytics | Supported | No | Supported |
| Range IndexRange Queries | Supported | No | No |
| JSON IndexAnalyze Semi-structured data | Supported | No | No |
| Geo IndexLocation queries | Supported | No | No |
| StarTree IndexFast Aggregation | Supported | No | No |
| Bloom FilterApproximate Filter | Supported | Supported | Supported |
| Text IndexLog Analytics | Supported | No | Limited Text Index support (Beta) – does not support full text search capabilities (regex, phrase, etc) |
| TimeStamp IndexTime based rollups | Supported | No | No |
| Sparse IndexApproximate Filter | *StarTree Cloud | No | Limited only on the primary sorted column |
| Composite JSON indexCost efficient and flexible set of indexes on JSON columns (ability to use text, range index at a finer granularity) | *Startree Cloud (Beta) | No | No |
Why do Indexes Matter in an OLAP Database?
Indexes help minimize the data scans needed for processing a given OLAP query. This is important to ensure query performance is optimal and predictable regarding high throughput and latency, even as the underlying data keeps growing organically.
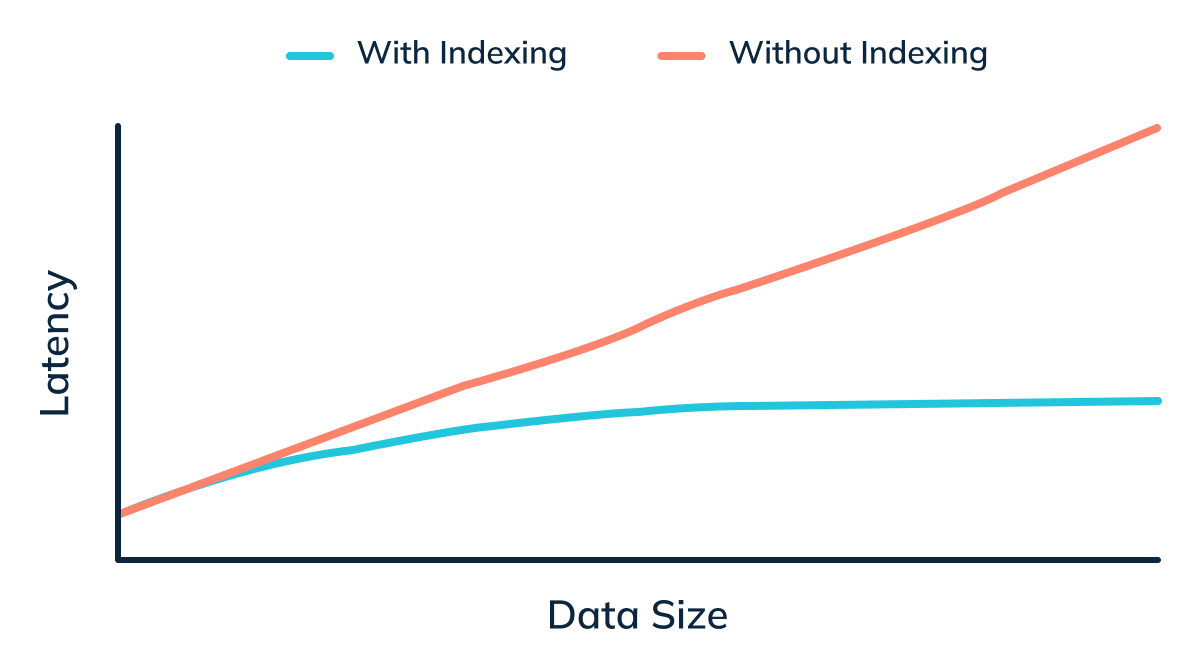
Apache Pinot natively supports a wide range of indexing strategies, making it the ideal OLAP platform for myriad use cases ( as discussed here.. In addition, it has a pluggable architecture, making it extremely easy to add new indexes as and when needed. For instance:
- Star-Tree Index: Pinot’s way of building intelligent materialized views is crucial for running user-facing analytical applications. Specifically, it allows users to pre-aggregate data in a tunable fashion, leaving the source data intact. This enables highly concurrent, low latency key-value style queries. Any changes in the pre-aggregation function or corresponding dimensions can be handled dynamically without having the need to re-ingest all the data.
- JSON index and text index are great at processing semi-structured data in sub-seconds (eg: analyzing system and application logs at scale)
- Geo index accelerates geospatial queries , which are required by many logistics and delivery companies around the globe, as well as various other real-world location-based services.
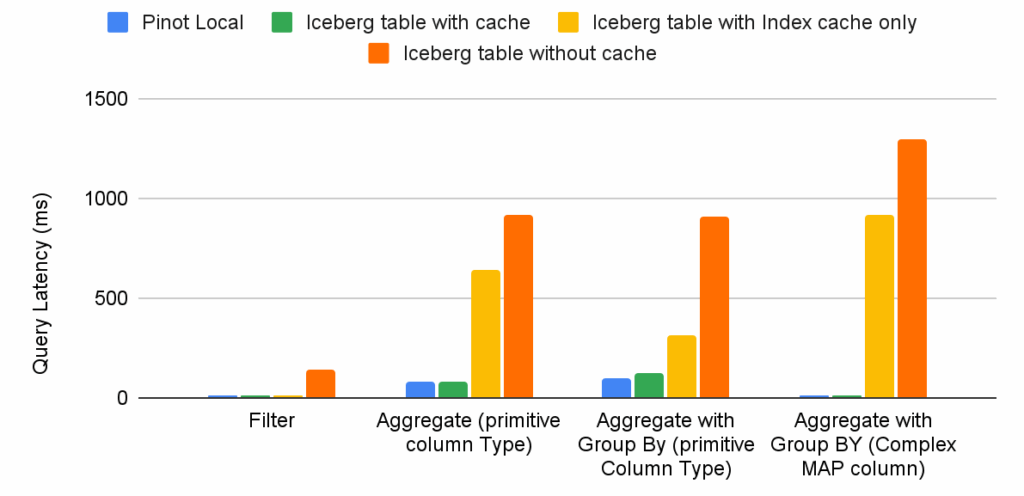
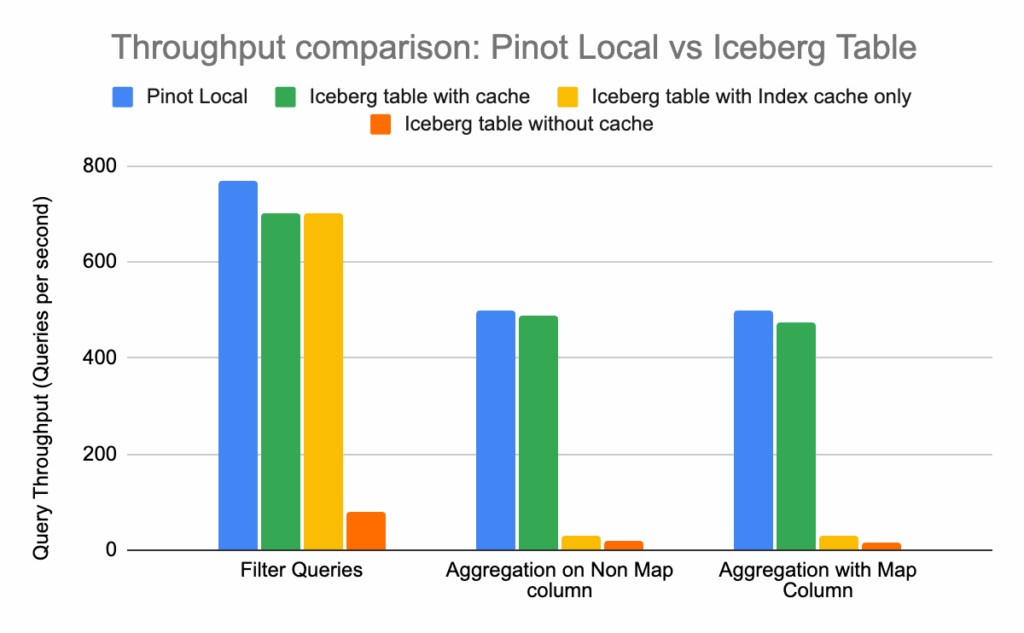
Here’s a quick view of the power of indexes – comparing query latencies with and without the corresponding index.
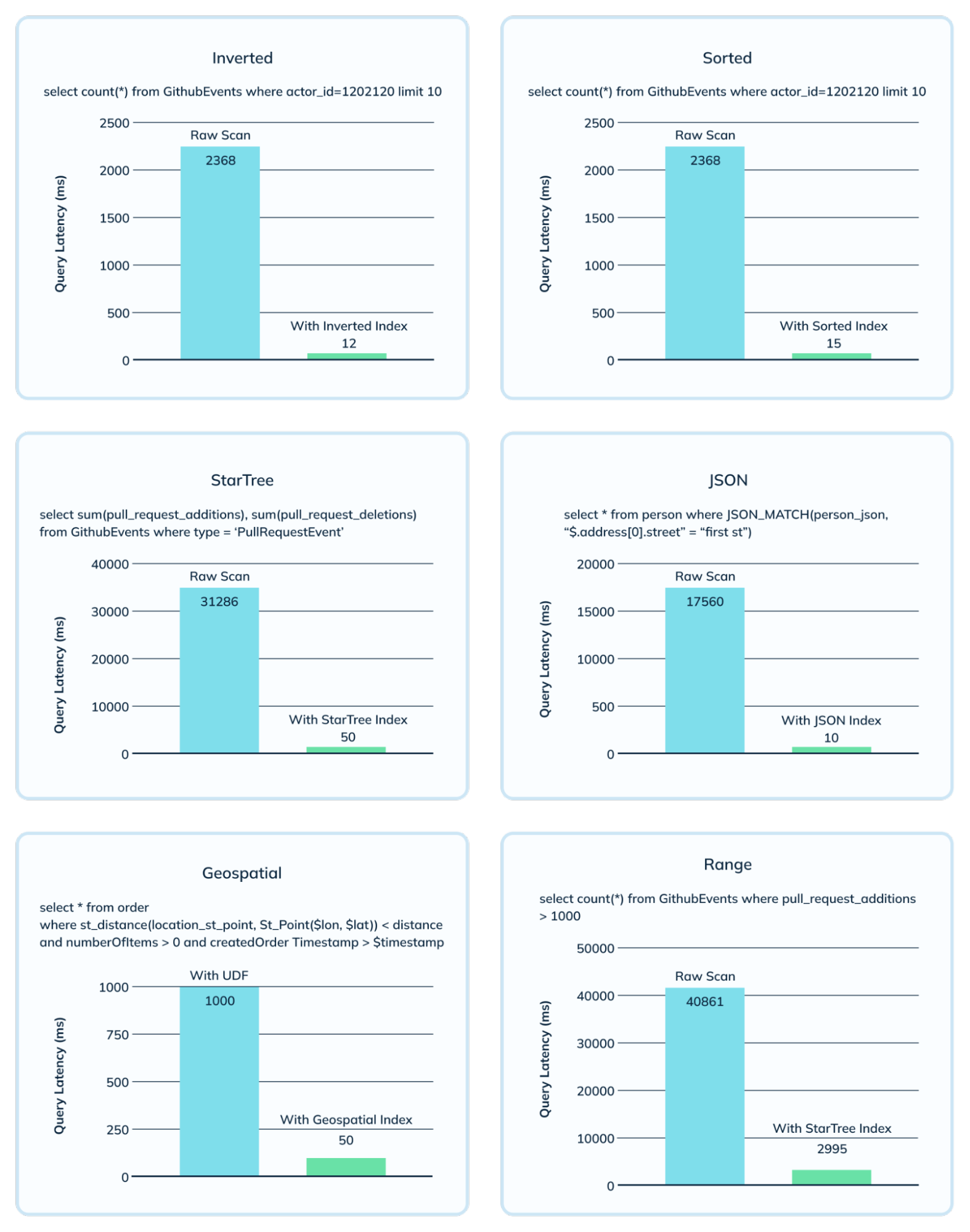
As depicted above, indexes help reduce the query latency by many orders of magnitude. In addition, it reduces the amount of work and resources needed per server, thus increasing the system’s overall throughput.
Query
This section compares the three systems in all aspects related to querying the database. It discusses commonly used query constructs in OLAP and advanced multi-stage query features such as joins and window functions. It finishes with query latency optimizations and features such as caching, routing, and pruning strategies.
| Capability | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| Filter | Yes | Yes | Yes |
| Group by | Yes | Yes | Yes |
| Order by | Yes | Yes | Yes |
| SketchesUseful for fast and approximate counting of distinct values in large sets | Yes | Yes | Yes |
| Multi-stage query engineRequired for executing more complex SQL queries such as JOIN, OVER window, which can cause bottlenecks if executed in a single-stage scatter-gather fashion. | YesHas a multi-stage query engine that is fully distributed, designed for interactive queries | Limited The multi-stage query engine executes SQL statements as batch tasks in the indexing service, and appears to be used more for ingestion. This is not suitable for interactive low-latency OLAP queries. | YesHas a multi-stage query engine. |
| JoinsA useful query construct for combining data from multiple tables in the scope of a single query. In the absence of joins, expensive data pre-processing and denormalization needs to be done. | Supported Mature Join support with various strategies supported | Limited You can only join regular Druid tables with lookup and inline data sources. In other words, no multi-stage joins) | Supported, with limitations. See below section for more details. |
| Window functionsA useful query construct for applying aggregations over a window (set of rows). | Supported using the Multi-stage Query engine | Work in progress. | Supported Standard window function syntax along with many basic aggregations |
| Pluggable User Defined Functions (UDFs)Ability to easily write custom UDFs and plug them into the system. | Support for using Groovy, or defining Scalar functions via annotations which can be plugged in as a custom jar. | Support for writing JavaScript functions. No ability to write a function and plug it in via custom jar. | Can define UDFs using CREATE FUNCTION. Uses lambda expressions which aren’t as powerful and can be inadequate at times. Clickhouse also supports invoking a UDF from an external executable program/script (in Private Preview |
| Query cachingSupport for caching results of a query. Useful when there would be repeated executions of the same expensive query. | No query caching mechanisms exist. | Two types of query result caches available A per-segment cache on server and a whole-query cache on broker. Mechanisms in place to evict stale cache entries as soon as data changes, and also an explicit config to use cache. | Supported. Three types of query cache (cache entire query, query condition cache as well as data/dictionary cache) |
| Pruning strategies during query executionAbility to prune out servers / segments without having to process all the segments. Two stages where this can be done: 1)Reduce server fanout 2)Reduce segment fanout | Reduce server fanout:Partition based: Prune out server groups based on partition infoReplica group based: Route to only 1 replica group for any query Reduce Segment fanout Min / max value: Prune out a segment based on filter clause and min / max values stored in segment metadata Partition info: Prune out a segment based on partition info stored in segment metadata Bloom filters: Prune out segments based on bloom filters created for columns and stored in segments. | Reduce server fanout: None. The segment pruning techniques are directly applied on brokers, but no attempts to reduce the set of servers fanned out to. Reduce segment fanout:Time based as segments are always time partitioned firstPartition based pruning | Reduce server fanout: None. Routing itself is a manual process – due to the absence of a dedicated Query Layer – involving setting up a Distributed Table using cluster.xml, and no smart controls exist to further optimize this. Reduce segment fanout:Block level pruning achieved using sparse primary indexes and skip indexes.with techniques like min / max, set, bloom filters).Partition based pruning |
Joins
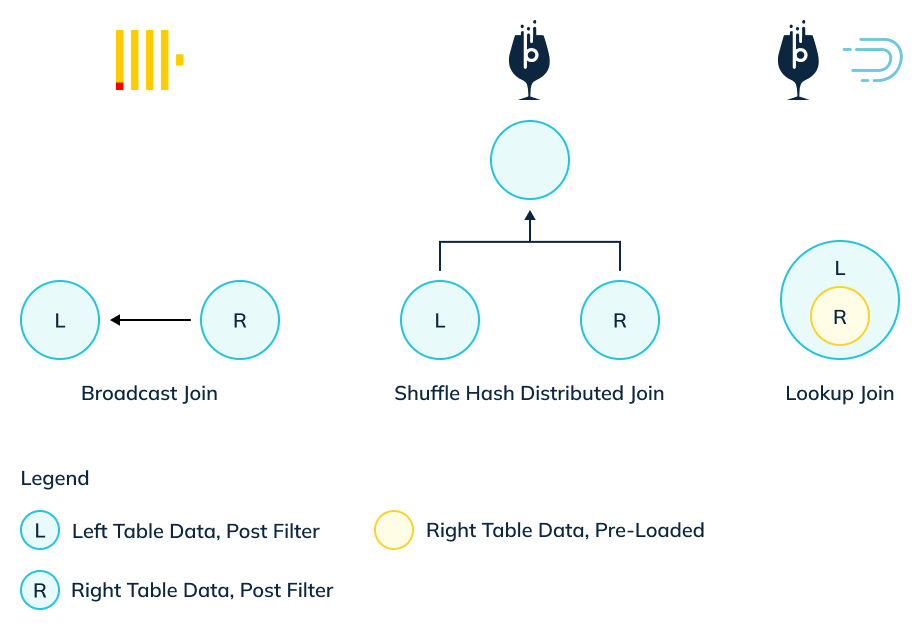
A Join query fundamentally works on two parts – a left table and a right table. There are three ways to execute a join.
- Broadcast join: All data post filtering from the right table (R), is shipped to all nodes (N) of the left table (effective data moved R * N). This works well for cases when the filtered data being shipped is small and the number of nodes is also small. But query latency increases proportionately as the size of R increases or the number of nodes N increases. This is the only algorithm that ClickHouse applies for large joins (when data is not colocated).
- Shuffle distributed hash join: After applying filters, data from both sides (L and R) is hashed on the join key and shipped to an independent shuffle stage (effective data moved L + R). This scales well even if the size of data on either side increases. Plus, the performance is unaffected by the number of nodes on either side. Pinot is the only system that can execute joins using this algorithm .
- Lookup join: Right table must be pre-loaded (replicated) on all nodes of left table. This can only work for very small right hand datasets. This is the only kind of join that Druid can execute . This is available in Pinot as well, for small dimension tables.
Apache Pinot supports all the above join strategies. The query engine will intelligently pick the strategy based on the data characteristics. In addition, users can explicitly provide hints about which strategy to use. Apache Pinot’s join support has been GA for several years and is now broadly adopted in production. At scale, some deployments sustain hundreds of complex join queries per second
Materialized Views
Materialized views (MVs) create a virtual table only using a subset of data from a base table, such as a select number of columns pertinent to a specific query. Users commonly use this to optimize query performance for well-known query patterns. Here’s how these different systems have implemented materialized views:
| Capability | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| Flexibility | High Native support via star-tree index | Low. Requires a Hadoop cluster | High Native support via CREATE VIEW |
| Ingestion overhead | Low Index can be created at any time and segment reload will automatically create the index for the entire source table | High Requires a Hadoop cluster | High for Materialized Views Any aggregation in the view query is only applied on new data. POPULATE can backfill existing data but is not recommended since any data being ingested at the time of view creation will be lost. Special consideration needs to be given to the materialized_views_ignore_errors flag. Otherwise any errors in any of the views will block ingestionClickHouse also has the concept of Projection which seems to be built automatically for the entire table |
| Storage overhead | Medium Allows tuning space vs query latency overhead. In other words, not all rows of the view are fully materialized, thus allowing for space efficiency, while still maintaining low query latency | High Materializes all the rows as a traditional view | High Materializes all the rows as a traditional view |
| Query overhead | Low User does not need to know about the existence of the index. The same query on the source table will automatically pick the right star-tree index under the hood | Moderate Queries need to target a specific view | Moderate Queries need to target a specific view. ClickHouse has a separate concept of Projection which is transparently applied without the user having to know about it. In general though, Projections are considered more heavyweight as compared to a Materialized View. |
Star-Tree Index: Pinot’s intelligent materialized view
The star-tree index provides an intelligent way to build materialized views within Pinot. Traditional MVs work by fully materializing the computation for each source record that matches the specified predicates. Although useful, this can result in non-trivial storage overhead. On the other hand, the star-tree index allows us to partially materialize the computations and provide the ability to tune the space-time tradeoff by providing a configurable threshold between pre-aggregation and data scans.
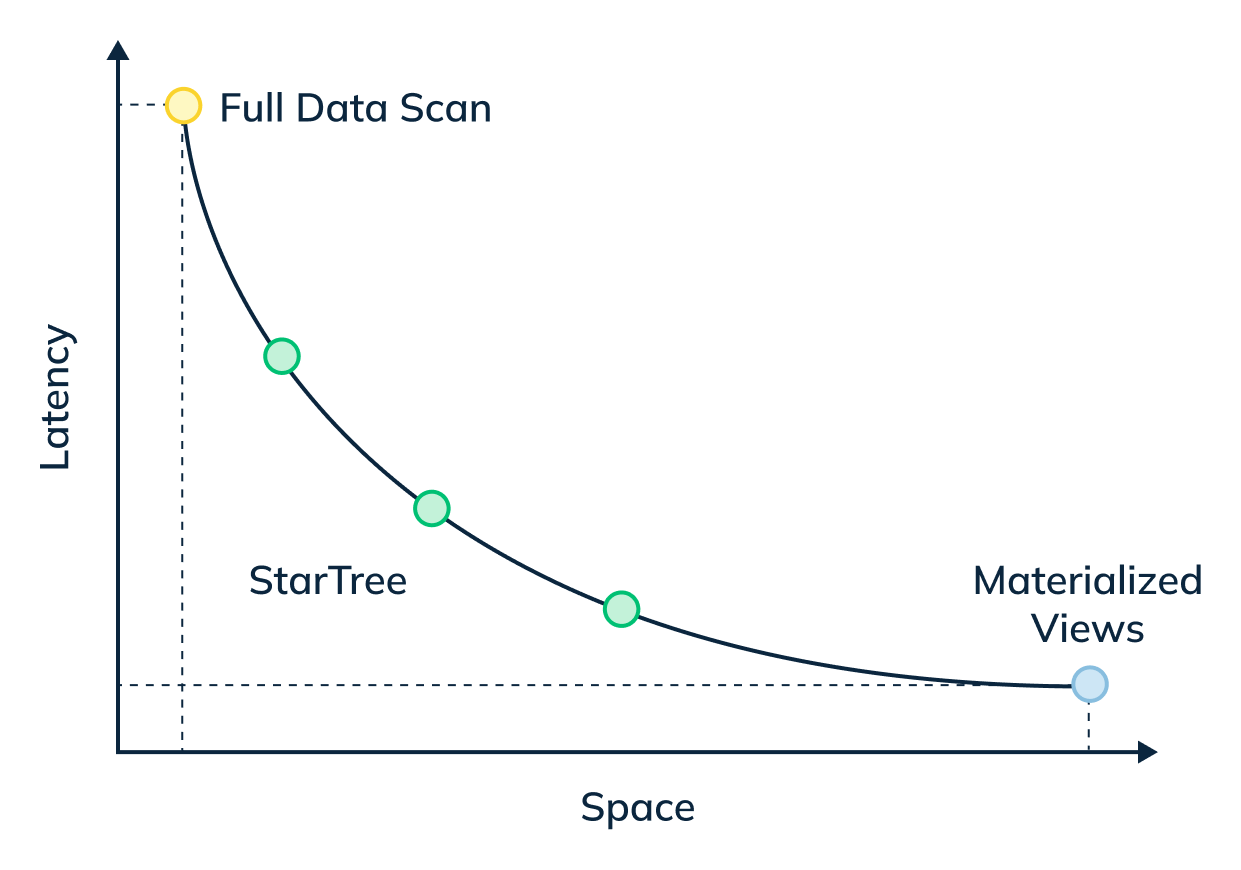
Fig: star-tree index lets you choose your space-time tradeoff between pre-aggregating everything (a materialized view) or doing everything on-the-fly
The star-tree index allows us to pre-compute values of an aggregation function across the dimensions specified in a given materialized view. A configurable parameter called maxLeafRecords determines the maximum rows that need to be scanned to compute an aggregation. In other words, if maxLeafRecords is set to 1 then we get full materialization – same as a traditional MV. Setting this to a higher value results in significant space savings with a small query overhead.
Key benefits:
- User controllable: Tune space vs. time overhead
- Flexible: create any number of indexes. The right index is chosen based on the query structure.
- Transparent: Unlike traditional MVs, users don’t need to know about the existence of a star-tree index. The same query will be accelerated with a star-tree index in place.
- Dynamic: Very easy to generate a new index at any point of time.
Learn more about the Star-tree index here.
Query Performance
Performance benchmarking is highly use-case, query pattern, and dataset dependent. We recommend you evaluate query performance on your datasets across these systems. Here are some benchmarking numbers provided by neutral third parties:
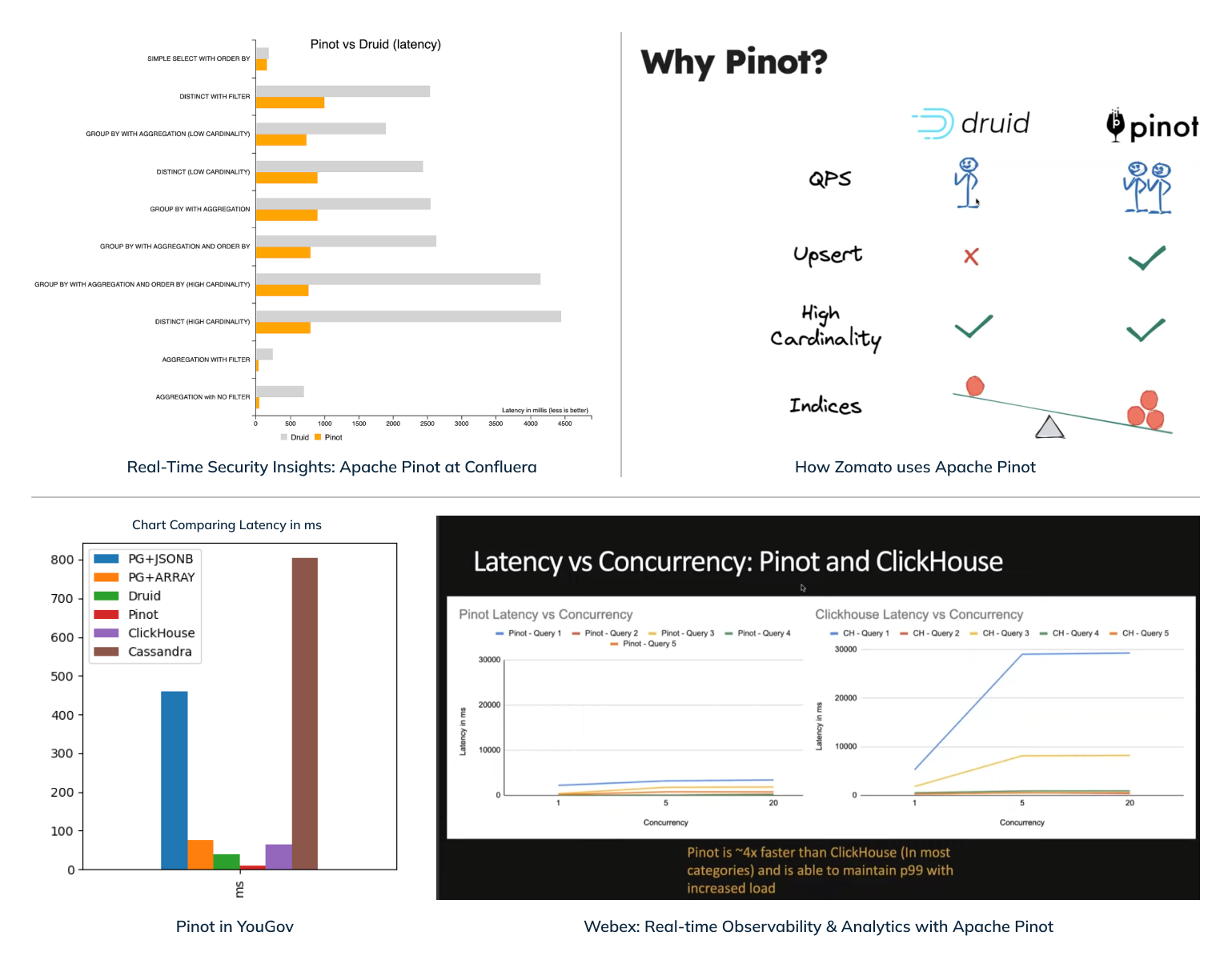
Fig: Query performance benchmark graphs from the various sources as listed below
- Cisco did an evaluation comparing ClickHouse and Pinot. View the setup details and results in Webex: Real-Time Observability & Analytics with Apache Pinot. A quote from the presentation – “ Pinot is 4x faster than ClickHouse (in most categories) and is able to maintain p99 with increased load.”
- This engineering blog post titled Real-time Security Insights: Apache Pinot at Confluera talks about their benchmarking done on Druid and Pinot. The results showed queries on Pinot were 2x – 4x faster than on Druid and could sustain a much higher throughput.
- This blog post titled Pinot in YouGov discusses a comparison they did with several technologies, and Pinot was 5x – 7x faster than Druid and ClickHouse .
- This session How Zomato uses Apache Pinot talks about how Pinot could handle 2x the query throughput compared to Druid using the same cluster size.
- Nubank – a large bank in South America uses Apache Pinot for real-time observability. Its able to execute 10s of thousands of queries per second in a cost effective manner (saving $1M+ annually).
Cluster Management
This section compares the systems on operability, which comprises several aspects such as, ease of cluster operations (scaling, maintenance, disaster recovery), visibility into cluster status, flexible cluster setup options to enhance manageability and help maintain SLA guarantees, and so on.
While all three databases are designed for high availability (HA), and each seeks to avoid single points of failure (SPOFs), each handles cluster component failures differently and thus provides differing overall reliability and resiliency.
| Capability | Apache Pinot | Apache Druid | Clickhouse |
|---|---|---|---|
| Management consoleA UI for managing cluster components and performing regular operations related to the lifecycle of tables, schemas, segments. Having such a console greatly improves ease of operability and developer productivity. | GoodA functional console available, covering the management and lifecycle of all physical and logical components. Also includes a query console. For advanced users, a UI for access to all endpoints and Zookeeper viewer. Advanced consoles available in StarTree Cloud for ingestion (Data Portal, Query Console) and easy data layout and cluster management (Pinot Control Panel) *StarTree Cloud | GoodA comprehensive console for loading data, managing data sources and tasks, and viewing server status and segment information. The console can also be used to run SQL and native Druid queries. | No management console. SQL console is available only in *ClickHouse Cloud. |
| Multi-tenancy Ability to create groupings amongst components of different use-cases in the same cluster. This helps provide physical as well as logical isolation and eases operations. | Strong Tenant is a first class concept in Pinot, that can be used to isolate brokers and/or servers of a table within a multi-tenant cluster. Tenants in Pinot not only help with isolation of resources and workload, but also bring benefits to operations such as independent scaling, rollouts etc. | Poor The concept of tenant is used to define a “user,” and multi-tenancy refers to multiple users / teams querying the same data source. No references found regarding techniques like node pools / tagging etc, for achieving isolation of tables within a cluster. Instead, suggestions include creating separate partitions for every tenant, creating separate data sources for every tenant or group similar tenants and creating a shared datasource. | No concept of tenants. The recommendation is to keep the number of tables in the cluster small. |
| Scale up / scale out Ease of making capacity changes to the cluster hardware (vertical as well as horizontal scaling up / down) and data redistribution. This is commonly required in order to adapt to changing workloads on a cluster. | Easy Very easy to make capacity changes and rebalance the cluster. StarTree Cloud has a Pinot Operator, which facilitates more automated scaling up / down of nodes, including rebalancing without down-time. It includes heterogeneous hardware support, which is often needed for multi-tenant clusters or tiered storage use cases. *StarTree Cloud | Possible While no documentation was found, these links indicate it’s possible to scale out the nodes and automatically balance the segments. | Not Easy Document indicates this is not easily possible. One needs to manually create the table on new nodes, copy over data, and is operationally heavy. |
| Node maintenance Ease of operations when having to replace or take down a node from the cluster for maintenance, which is a common operation in large scale distributed clusters. | Easy Easy to take down a node and have another one join in its place by using the same node identifier. | Easy There’s a maintenance mode flag that can be used to mark a node as decommissioned, so new data stops getting assigned to it, and balancer starts moving existing data to a new node. | Difficult Involves manual steps like copying over data from 1 replica to another, which means you cannot do this unless replica > 1. |
| Disaster Recovery Permanent backup and recovery mechanisms, to recover the data in the event of node / disk failures and cluster outages. | Automatic All segments are backed up to deep store by default, and data can be restored completely in the event of cluster failures / data loss. This copy is also used to load data onto newly added nodes, nodes which lose their data. | Automatic. All segments are backed up to deep store by default, and data can be restored completely in the event of cluster failures / data loss. This copy is also used to load data onto newly added nodes, nodes which lose their data. | Manual Backups need to be set up manually. There’s no concept of a deep store, where a permanent copy is backed up by default. Recovering after node failures is manual and requires copying data from another replica, which indicates we cannot recover if we lose all replicas. |
| High Availability Ability to keep service available in the event of partial component failures. Avoid any “Single Point of Failure (SPOF).” | Strong Each component and data shard can be scaled and replicated. Data can be replicated easily. Can operate queries, ingestion, and background tasks in the face of a failure in any of the components. Pinot can also tolerate failures in deep store availability, with peer downloading capabilities | With Limitations Each component and data shard can be scaled and replicated. Data can be replicated easily. Can operate queries, ingestion, and background tasks in the face of a failure in any of the components. However, does not have a way to provide high availability if the deep store goes down. | With Limitations It is possible to run ClickHouse without Zookeeper involved. However, in this mode, you cannot have replication, and hence cannot be highly available. Additionally, absence of a deep store and the fact that ClickHouse servers are the sole component responsible for all activities in the system (no separation of concerns), makes it much harder to provide high availability. |
| System tables System tables capture information about the cluster components, query / ingestion workload, etc, which can be extremely useful in monitoring system health and debugging without requiring a separate management port or interface. | No concept of system metadata tables. Virtual metadata columns – docId, hostId, segmentName – built by default and available during query time. | Two system tables available Information Schema (tables and column types) and Sys Schema (servers, segments, tasks). | A rich set of system tables for server states, internal processes and environments |
Security
Here, we compare the key security requirements needed for an enterprise-grade real-time OLAP database.
| Capability | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| OIDC based Authentication | Supported *StarTree Cloud | Supported | No |
| Kerberos based Authentication | No | Supported | Supported but not available in Clickhouse Cloud |
| Authorization: (ABAC) Attributed Based Access Control | Supported *StarTree Cloud | No | No |
| Authorization: (RBAC) Role Based Access Control | Supported | Supported | Supported |
| Data encryption (“Data-at-Rest”) | Storage level encryption | Storage level encryption | Storage level encryption + Built-in encryption support |
| Network encryption (“Data-in-Motion”) | SSL/TLS | SSL/TLS | SSL/TLS |
Cloud Deployment Model
Finally, we look at how easy it is to deploy these three systems as a fully-managed cloud solution, requiring a commercial Database-as-a-Service (DBaaS) provider. Users can, of course, self-deploy any open-source databases to the public cloud as a self-managed solution.
| Capability | Apache Pinot (StarTree Cloud) | Apache Druid (Imply) | ClickHouse (ClickHouse Cloud) |
|---|---|---|---|
| SaaS Cluster provisioned in vendor’s cloud account. User has to ship data to this cluster | Supported *StarTree Cloud | Supported *Imply | Supported *ClickHouse Cloud |
| Bring Your Own Cloud (BYOC) Cluster provisioned in customer’s cloud account. Customer retains full control of data. | Supported. No VPC peering needed between control plane and data plane. Supported in AWS, GCP, Azure. Fully managed offering. *StarTree Cloud | Supported with limitations. Needs VPC peering between control plane and data plane. This is not only a point of friction for the users, but also problematic in terms of having to deal with CIDR range overlap across multiple deployments. Resolving CIDR overlap needs a complex setup as documented here.*Imply | Supported Customers are expected to manage infrastructure. AWS Only. *ClickHouse Cloud |
| Bring Your Own Kubernetes (BYOK) Cluster provisioned in customer’s existing Kubernetes cluster | Supported (GA in AWS) | Not supported | Not supported |
StarTree’s Bring Your Own Cloud (BYOC) deployment model
StarTree provides a fully managed BYOC offering in which the data never leaves the customer’s cloud account. This is tremendously beneficial for the customer who retains full control over the data and access to that data without having to deal with the complexities of running a production grade Pinot cluster.
Here are the key benefits of this model:
- Data security/governance: Data never leaves the customer’s cloud perimeter. Customers also retain full control over data access.
- SLA : StarTree customers get the same SLA as the corresponding SaaS model
- Fully managed : StarTree is responsible for handling deployment, upgrades, routine maintenance, backups / recoveries, and capacity planning on behalf of the customers.
- Principle of least privilege : StarTree Cloud runs with the least privilege model for operating and managing BYOC clusters with the exception of the one time deployment.
- No VPC peering needed : StarTree’s control plane does not need any VPC peering with the remote data plane. This makes it frictionless to deploy and scalable across multiple deployments
- Cost Effective : Customers can fine-tune the cluster configuration for cost optimization regarding instance type, storage type, and avail of their cloud discounts as applicable.
StarTree’s Bring Your Own Kubernetes (BYOK) deployment model
BYOK allows you to deploy StarTree, powered by Apache Pinot™, directly on your own Kubernetes infrastructure. This option joins StarTree’s existing deployment models—Software as a Service (SaaS) and Bring Your Own Cloud (BYOC)—giving you more choices for implementing analytics solutions that align with your specific requirements.
Outbound Connectors
The ability to connect these databases with Business Intelligence (BI) or visualization tools is crucial for doing ad-hoc analysis on real-time data. Here is how the three systems compare in terms of outbound connectors:
| Connector | Apache Pinot | Apache Druid | ClickHouse |
|---|---|---|---|
| JDBC | Yes | Yes | Yes |
| PrestoDB | Yes | Yes | Yes |
| Trino | Yes | Yes | Yes |
| Tableau | Yes | Yes | Yes |
| Looker | Via PrestoDB/Trino | Yes | Yes |
| PowerBI | Via PrestoDB/Trino | Via PrestoDB/Trino | Yes (ODBC driver) |
| Grafana | Yes | Yes | Yes |
| Superset | Yes | Yes | Yes |
Feedback
We hope you enjoyed reading this comparison! We’ve tried our best to ensure that all the content is accurate and to the best of our knowledge. However, it’s possible that we missed something or overlooked some details. Plus, of course, this is a point-in-time analysis. Future updates to any of these databases could require revisions to the information provided above. Please contact us if you have any feedback, and we’ll be happy to incorporate it!
Changelog
Jan 8, 2025
The following things have been updated since the original publication of this blog:
Apache Pinot
- Improved realtime ingestion with pauseless support
- Multi-stage engine GA – rich joins and window functions support
- Native Iceberg & S3 query support
- Outbound connector improvements (Grafana)
- RBAC support added
- New deployment model: BYOK (Bring Your Own Kubernetes)
Clickhouse
- Native support for various input sources (Kafka, S3, Iceberg etc)
- Improved JSON column handling
- Native Iceberg and S3 query support
- Improved query cache support
- Limited BYOC model support
Intrigued by Apache Pinot? Try it out!
Perhaps the analysis you’ve read above has gotten you curious about Apache Pinot. You can download open-source Apache Pinot, or the easiest way to get started is to Request a trial of Apache Pinot on StarTree Cloud
Acknowledgements:
Thanks to Rachel Pedreschi for the very thorough review and insights on Apache Druid, Xiaobing Li for reviewing and helping us dig deep into ClickHouse, and Shounak Kulkarni for validating some of our findings and assumptions on real cluster setups for all three systems!
Many thanks to Madison Sorenson for making the beautiful illustrations. And to all our internal reviewers and editors – Peter Corless, Tim Berglund, Kishore Gopalakrishna, Kulbir Nijjer, and Allison Murph. for the valuable feedback and direction!