

This article maps out how bytes that start in Kafka are ultimately transformed into Pinot segments. We will also explore the protective mechanisms such as flush thresholds, state machines and commit coordination that keep ingestion sane in demanding production environments. Expect both structured detail and a touch of lighthearted commentary.

Turning time into money (using analytics)
As the streaming ecosystem matured, organizations demanded tools that could keep up not just with ingestion but also with analysis. The goal was simple: incrementally process new data and update statistics in real time. No more recomputing entire pipelines, no more waiting hours or days. Just fresh insights, nearly instantaneously.
For one of our large customers, real-time analytics pipelines process nearly 40 million events per second with an expectation of under 5 seconds lag and zero tolerance for data loss.
In one large BYOC deployment on GCP, Pinot ingests around 100–150K events per second, roughly 1–2 TB of data each day across 180 Kafka partitions.
These demands gave rise to specialized OLAP systems optimized for speed. Apache Pinot sits at the forefront of this frontier. It’s able to process millions of events per second while still delivering sub-second query latencies. The result is a platform where time quite literally can be transformed into money: powering fraud detection, ad optimization, and logistics tracking, all on up-to-the-second data.
Enter Apache Pinot: The powerhouse of real-time analytics
Pinot’s ingestion speed directly translates to freshness, data becomes queryable within seconds of being produced. This ability to process streams rapidly ensures that dashboards, anomaly detectors, and user-facing applications always reflect the most recent events. Traditional databases might handle internal analytics well enough. But when freshness defines user experience like surfacing live delivery ETAs or monitoring concurrent viewership, batch pipelines and caching layers fall short. Pinot bridges this gap by keeping ingestion and indexing fast, ensuring the latest data is always available for analysis.
The secret lies beneath the surface. While Kafka focuses on delivering event streams reliably, Pinot extends the real-time boundary by tightly managing offsets, partitions, and segment life cycles. This design guarantees both freshness and data integrity without trading off performance.
First contact with Pinot
Creating a realtime table in Pinot initiates a carefully orchestrated sequence of events. The Pinot Controller, specifically the PinotLLCRealtimeSegmentManager, determines the relevant Kafka partitions and establishes starting offsets based on configuration. Take a look at this example below, where we have 4 Pinot servers, a Kafka topic with 4 partitions and a replication factor of 2.
Next, Pinot persists this metadata in ZooKeeper, the coordination layer. At this point, ZooKeeper holds the “flight plan”: partition to server assignments, offset checkpoints, and segment placeholders. The Controller then generates a segment entry, assigns servers, and issues a directive: “Spin up this segment and prepare for takeoff.”
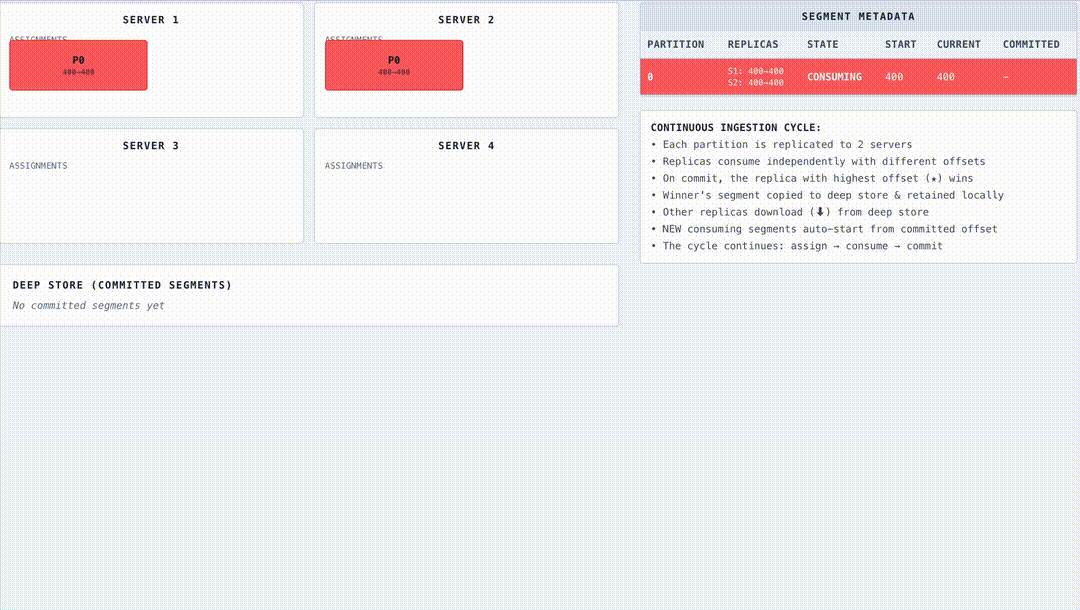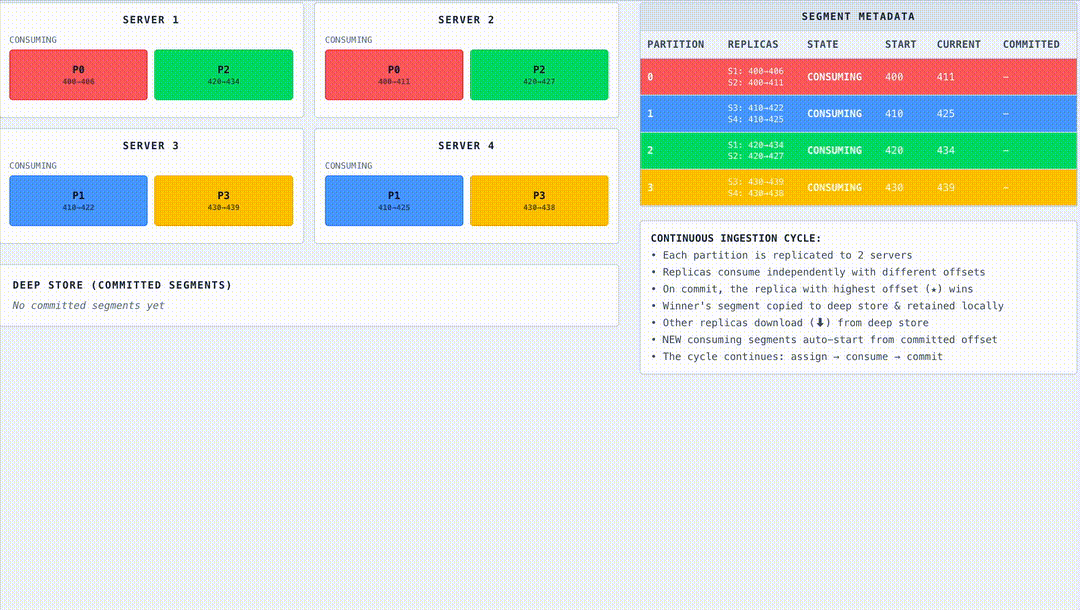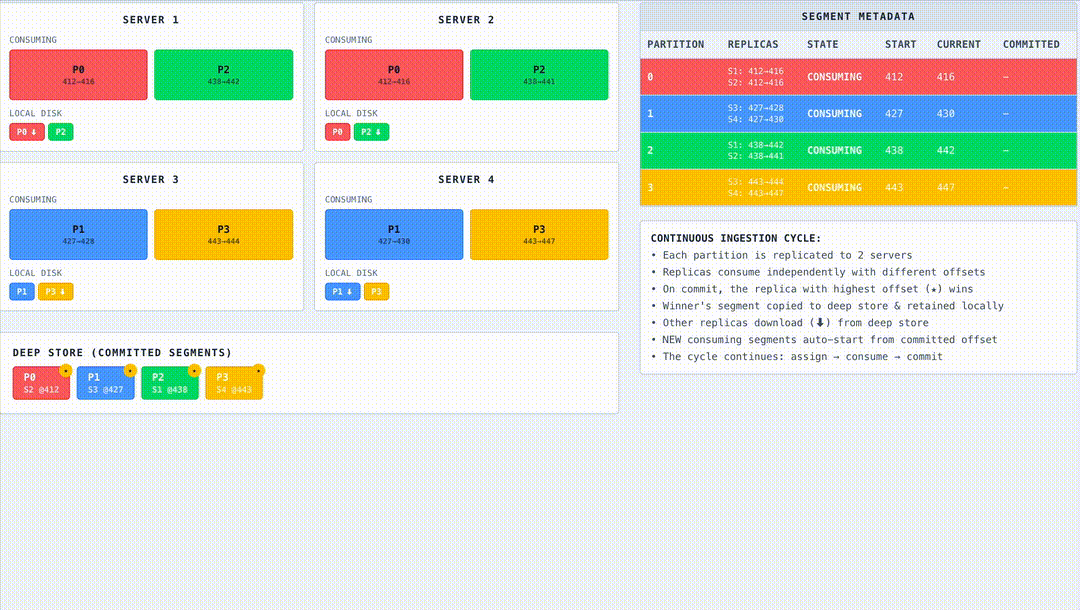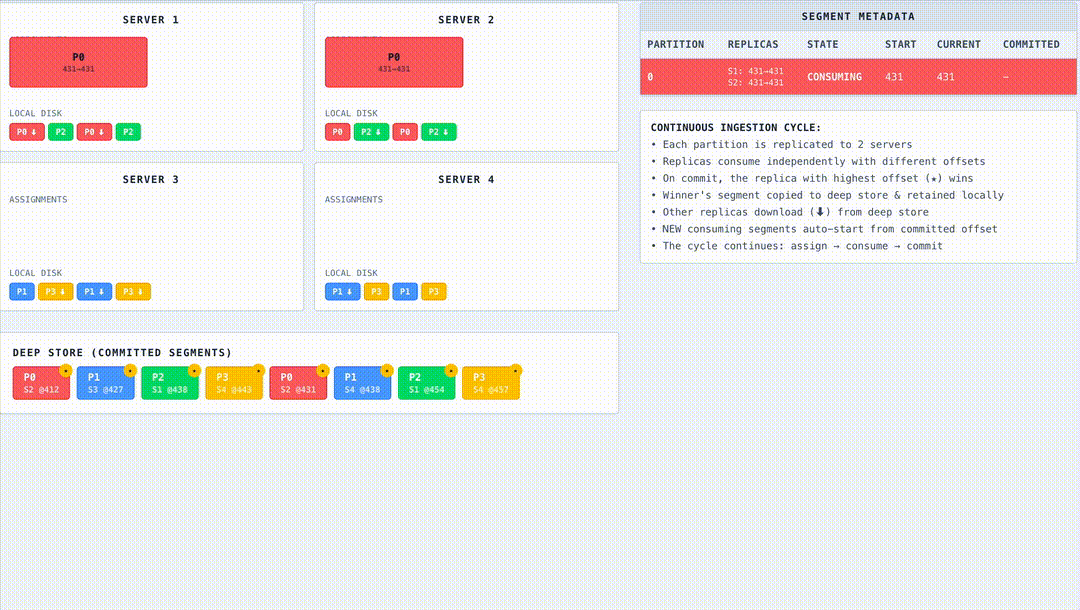
Fueling the consumers
On the server side, this directive passes through several orchestrators:
- Instance Data Manager: Validates metadata and routes the request to the correct table.
- Table Data Manager: Manages table-level state, creating and tracking SegmentDataManagers for each segment.
- Realtime Segment Data Manager: The heavyweight operator responsible for ingestion lifecycle management, running the consume loop, enforcing thresholds, reporting metrics, and communicating with the Controller.
Before consumption begins, Pinot creates a Mutable Segment, an in-memory structure capable of indexing incoming rows in real time. To optimize memory, it uses mmap for off-heap allocations. Once indices are ready, a consumer thread begins pulling data from Kafka.
Liftoff: The consume loop
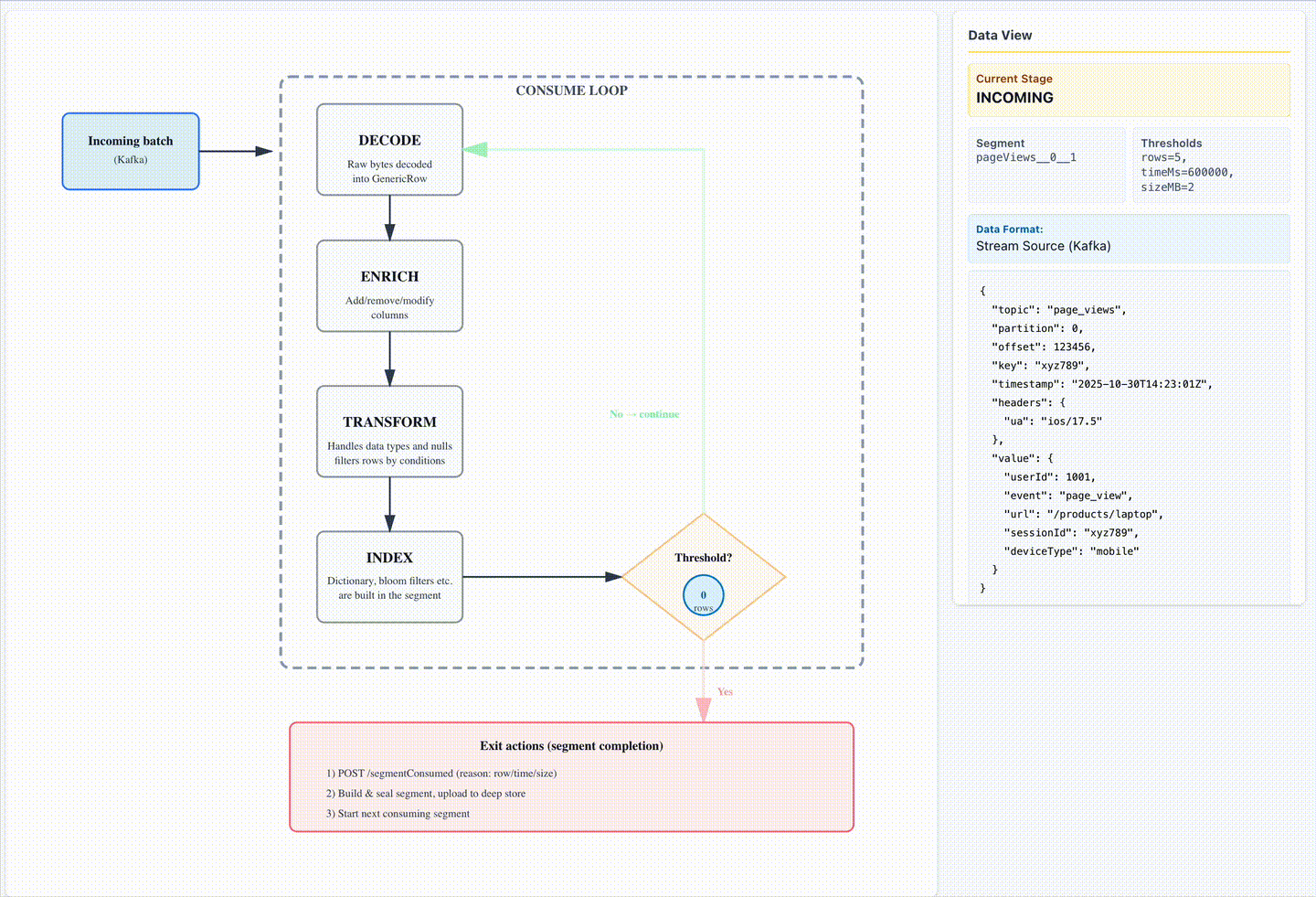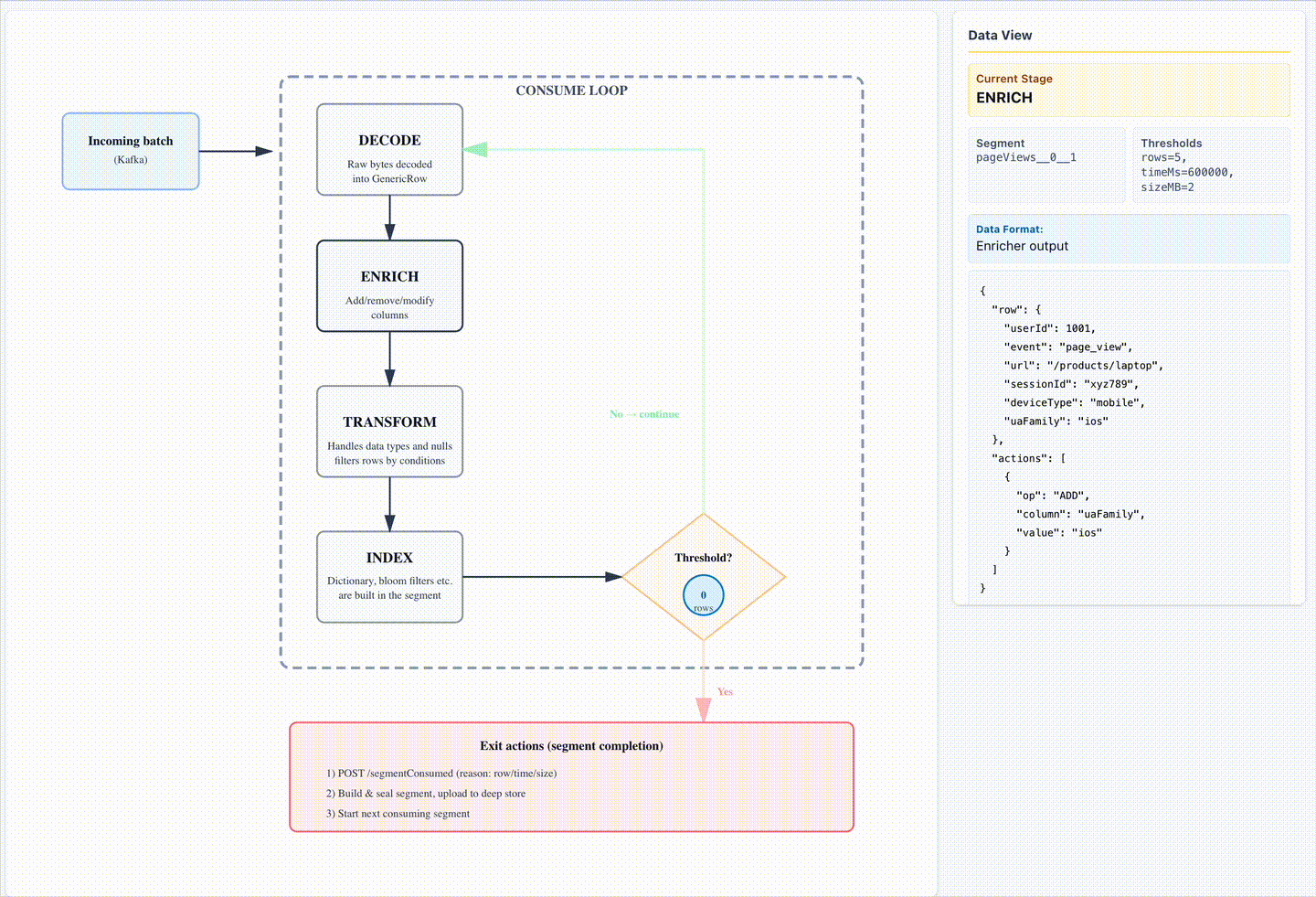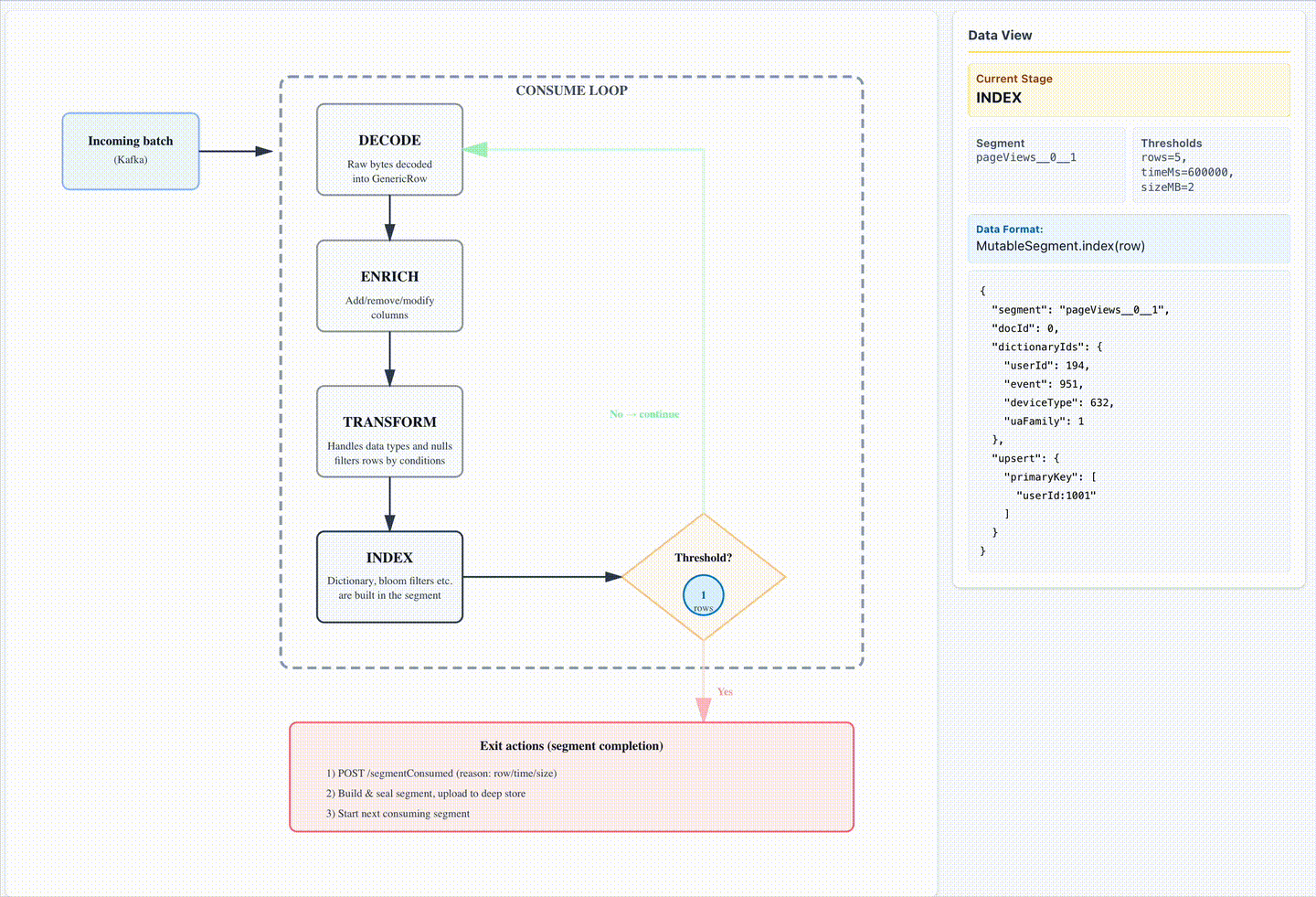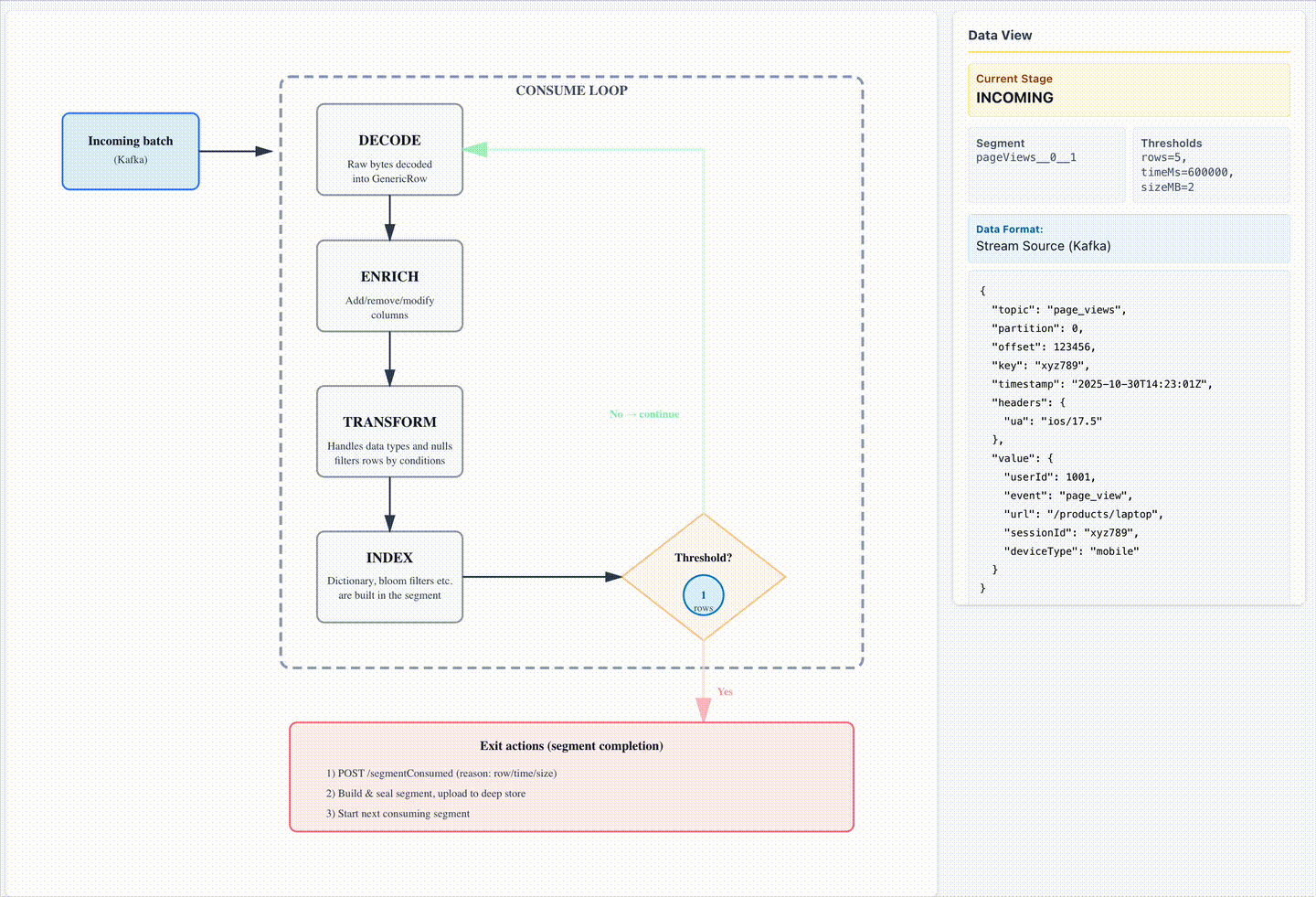
The consume loop is the heartbeat of Pinot’s real-time ingestion. Each iteration processes a small batch of events and prepares them for querying. Steps include:
- Fetch a batch – Retrieve messages at the current Kafka offset. If nothing is available, wait and retry.
- Decode – Convert byte arrays into GenericRow objects. Rows that fail schema validation are discarded.
- Enrich – Run configured record enrichers to add/remove/modify columns or extract fields before complex transforms.
- Transform – Apply ingestion logic: timestamp parsing, JSON extraction, renaming, or filtering.
- Aggregate (optional) – Aggregate metrics (e.g., SUM, COUNT) at ingestion time to reduce storage costs.
- Deduplicate/Upsert (optional) – Enforce primary key rules, discarding outdated or duplicate records.
- Index into Mutable Segment – Dictionary encode values, update forward/inverted indexes, build JSON/text indexes, and track nulls.
- Advance offsets – Update in-memory pointers to ensure smooth continuation.
This loop runs continuously, fortified with strong error handling. Pinot tracks ingestion metrics (rows fetched, dropped, indexed, retried) and gracefully recovers from Kafka hiccups, malformed records, or memory pressure. It’s designed not just for speed, but for durability under stress.
In-flight processing: The mutable engine that keeps Pinot airborne
Once a server begins consuming, each partition births its own mutable segment which is an in-memory engine where incoming rows are instantly transformed into query-ready data. At our largest customer scales with tens of millions of events per second, sub-5-second freshness, and zero-loss tolerance, this mutable path is what keeps Pinot’s “real-time” truly real.
Hot path design
- Single writer per partition. Each source topic partition per replica maps to one dedicated mutable segment. There’s no cross-partition locking, writes simply append as docId = 0,1,2…, guaranteeing ordered inserts and effortless concurrency.
- Row → columnar in one pass. Every event is decoded and expanded just once, then fanned out column-by-column into compact in-memory writers.
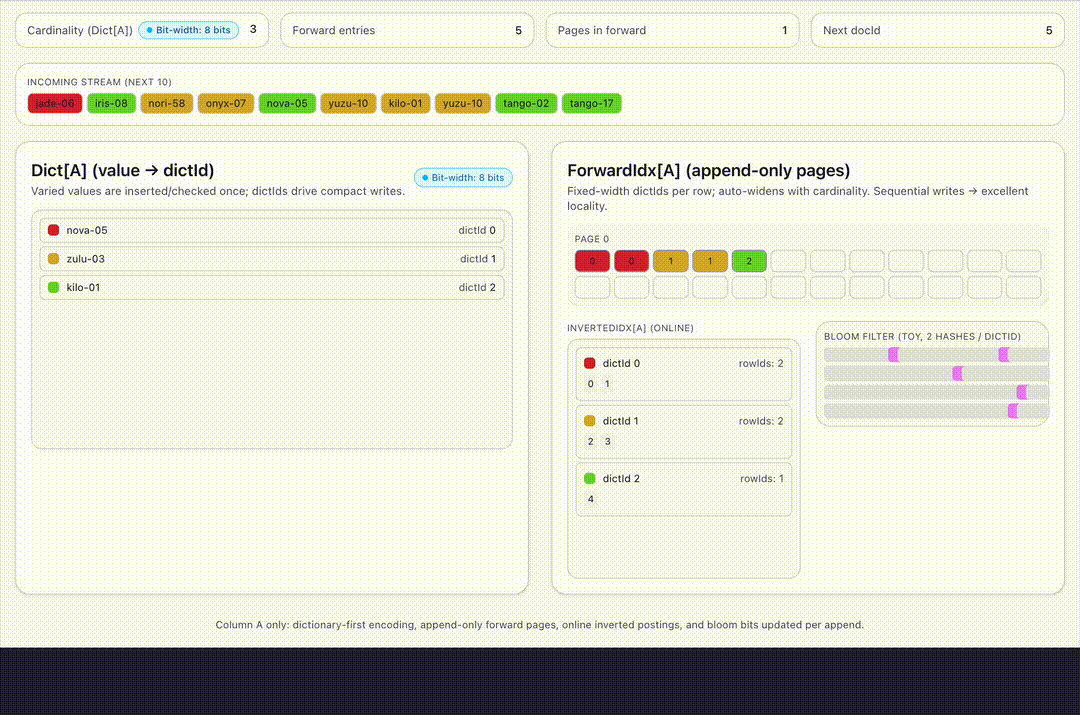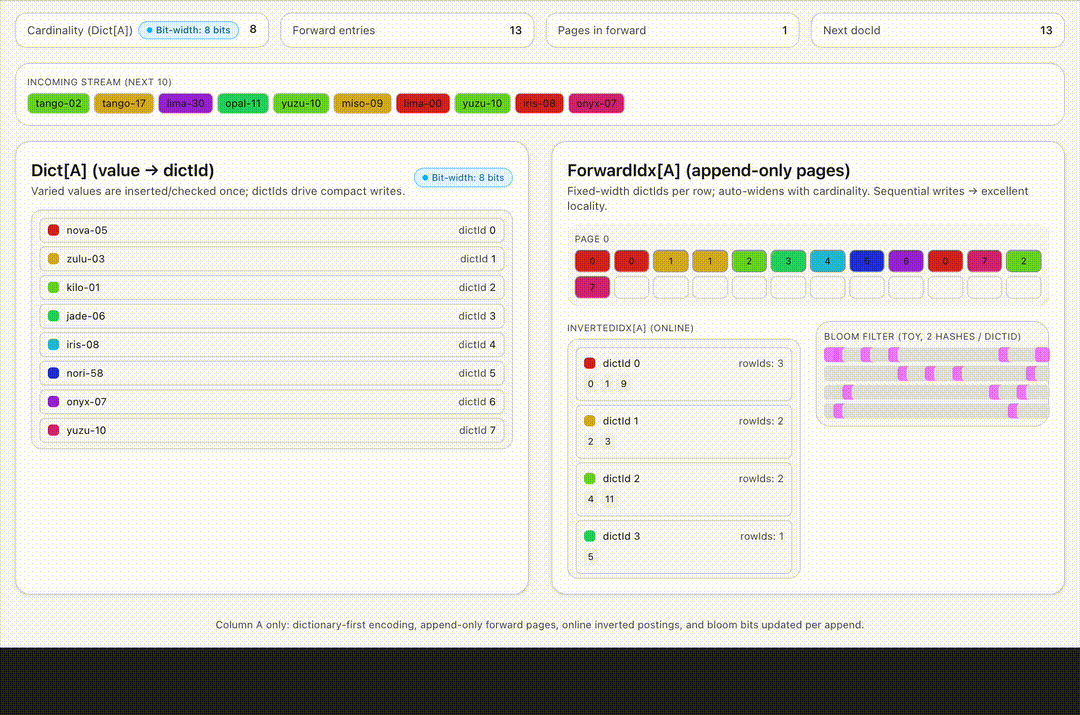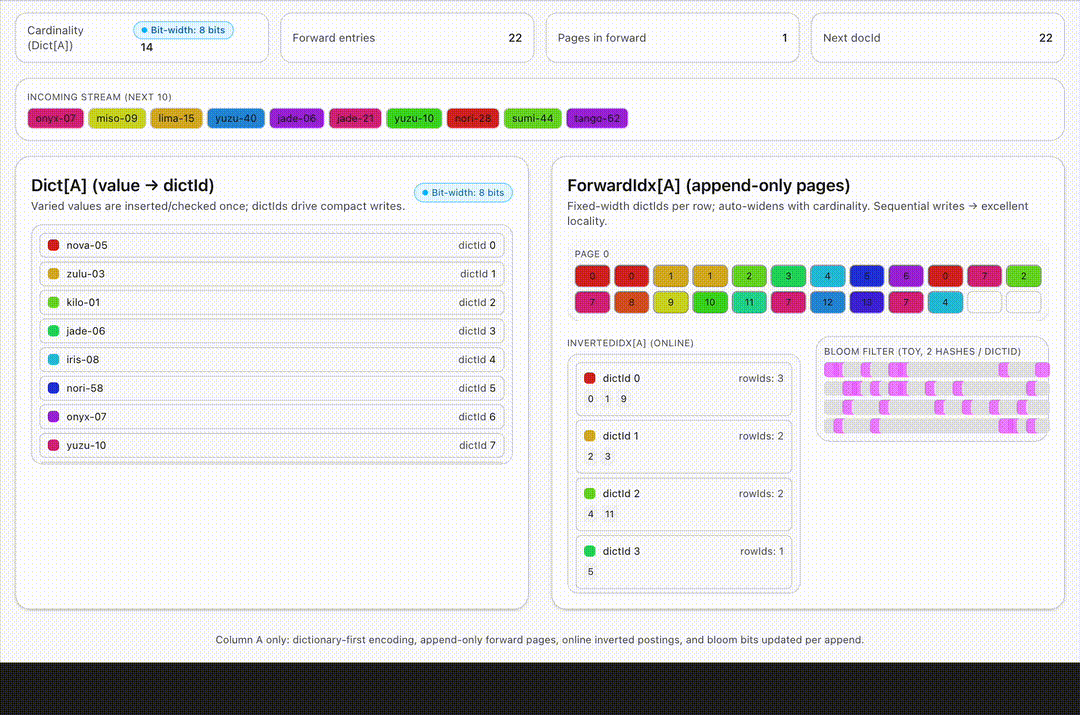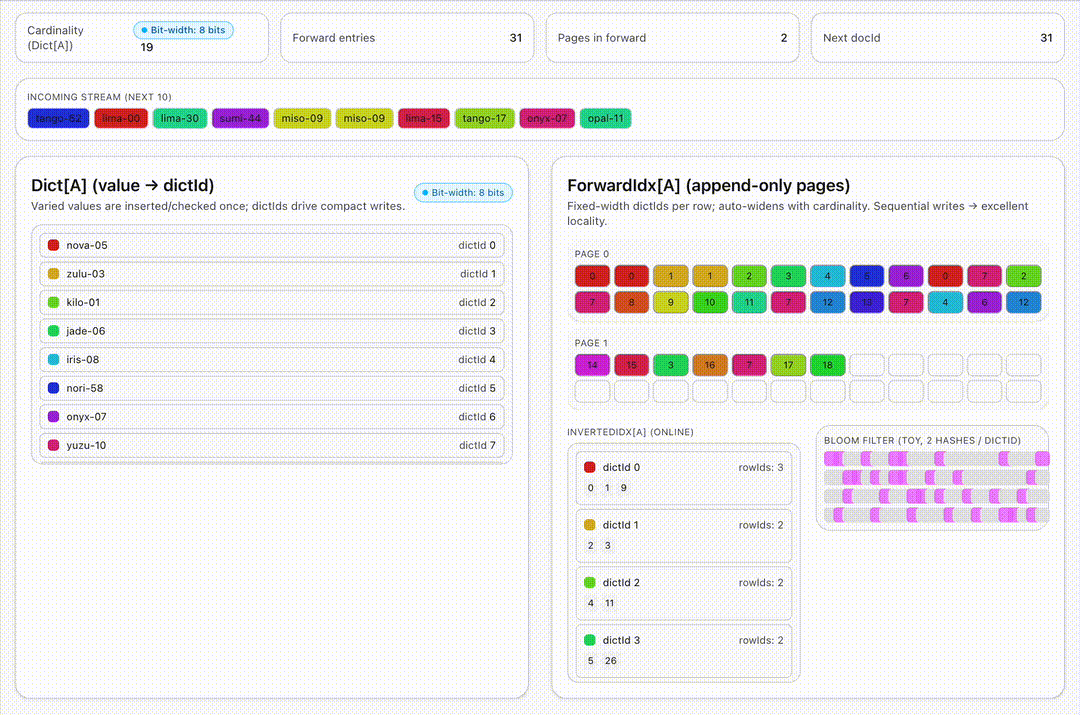
- Dictionary-first encoding. For string or enum columns, values are encoded into per-column dictionaries. Only a few bytes (the dictId) are stored in the forward index. Then we store only these 8 byte unique ids instead of the actual string for each row.
- Append-only forward indexes. Each new row extends fixed-width off-heap arrays for columns, no read-modify-write required.
- Selective, realtime-safe indexes. Lightweight ones like inverted or bloom filters are maintained live while the heavyweights such as star-tree await the immutable seal stage. The hot path stays lean.
Memory layout & allocation
- Off-heap buffers. Mutable segments use direct or mmap-backed pages to dodge GC pauses and lean on the OS page cache.
- Bit-packing on the fly. As dictionaries grow, Pinot auto-widens index widths (8→12→16 bits) without rewriting old rows – ingestion never stalls.
- Cache-friendly appends. Columnar writes are sequential, enabling tight CPU cache locality and predictable throughput.
Concurrency and backpressure
Each partition’s mutable segment operates in isolation. Even if one hits its flush threshold or pauses for commit, its neighbors continue ingesting. Adaptive size and time-based thresholds learn from previous segments, balancing memory stability with consistent freshness.
Querying while still mutable
Fresh rows don’t hide behind lag. Queries can hit mutable segments directly; the same forward and inverted indexes power lookups even before sealing. However, since different replicas can consume at different rate, you can notice slight differences in the query results from the consuming segments.
When a segment seals, Pinot builds the immutable version and swaps it in seamlessly. This ensures all replicas have the same copy of the segment thus ensuring consistent results. The brokers notice the change instantly, no downtime required. We’ll cover more on this in next blog.
Why it works at scale
- High write QPS, low CPU. Append-only dictIds and no global locks keep ingestion cores free for query workers.
- Predictable tail latencies. Avoiding GC and pointer chasing stabilizes p99s even during load spikes.
- Linear growth. Add partitions, gain throughput. Add servers, gain parallelism. The system scales cleanly, without centralized contention.
Hitting the brakes: Flush thresholds
Segments cannot grow forever. Unchecked growth would overwhelm memory and delay ingestion. Pinot uses flush thresholds to determine when to stop:
- Row Count: Seal the segment after ingesting a specified number of rows (e.g., 5M).
- Time Limit: Flush after a set duration (e.g., 6 hours), regardless of size.
- Segment Size: Estimate size and flush when nearing the configured limit (e.g., 100 MB).
Row and time thresholds are straightforward. Segment-size thresholds are more nuanced: compression and encoding can make disk size differ from in-memory estimates. Pinot mitigates this by smoothing ratios across past segments and calibrating future thresholds. Think of it as a Goldilocks strategy, aiming for “just right.”
Houston, we’ve gone immutable
When thresholds are reached, Pinot transitions the segment from mutable to immutable:
- Freeze – Halt ingestion into the mutable segment.
- Convert – Build a columnar, indexed immutable segment.
- Generate Metadata – Record statistics such as min/max values and column cardinalities.
- Upload – Compress and upload the tarball to the Controller or deep store.
- Replace – Swap the mutable segment with the immutable one, marking it ONLINE.
- Clean up – Terminate threads, release memory, and prepare for the next cycle.
At this point, the segment becomes query-ready. In some deployments, local retention may keep the segment on the server while still marking it immutable.
Why Pinot optimizes for freshness
We had a lot of choices for the real-time paradigm. Spark does micro-batching: you set a trigger, it groups records into small batches, checkpoints offsets, and pushes on schedule. Freshness follows the trigger you pick.
Flink and Kafka Streams run record-at-a-time with checkpoint barriers and transactional sinks for exactly-once. Great for stateful joins and windows; latency is per event.
ClickHouse ingests from Kafka into MergeTree via materialized views. Each insert becomes a part that is queryable immediately, while merges and any deduplication run in the background. It is at-least-once by default. Duplicates can appear until merges complete, and forcing dedup at read adds latency and CPU, with merge timing sometimes causing brief count swings.
Pinot, however, chose a serving-first path. We consume per partition into a mutable segment, build indexes inline, then seal on row, time, or size thresholds and publish immediately so queries see new data right away. Enforcing end-to-end exactly-once across Kafka and Pinot would add coordination that slows publishes. We intentionally run at-least-once to keep freshness and availability high, and when we seal and commit the controller coordinates a single authoritative commit so every replica downloads the same sealed bytes and serves an identical snapshot. This gives a predictable publish cadence and consistent view across replicas without waiting on background merges.
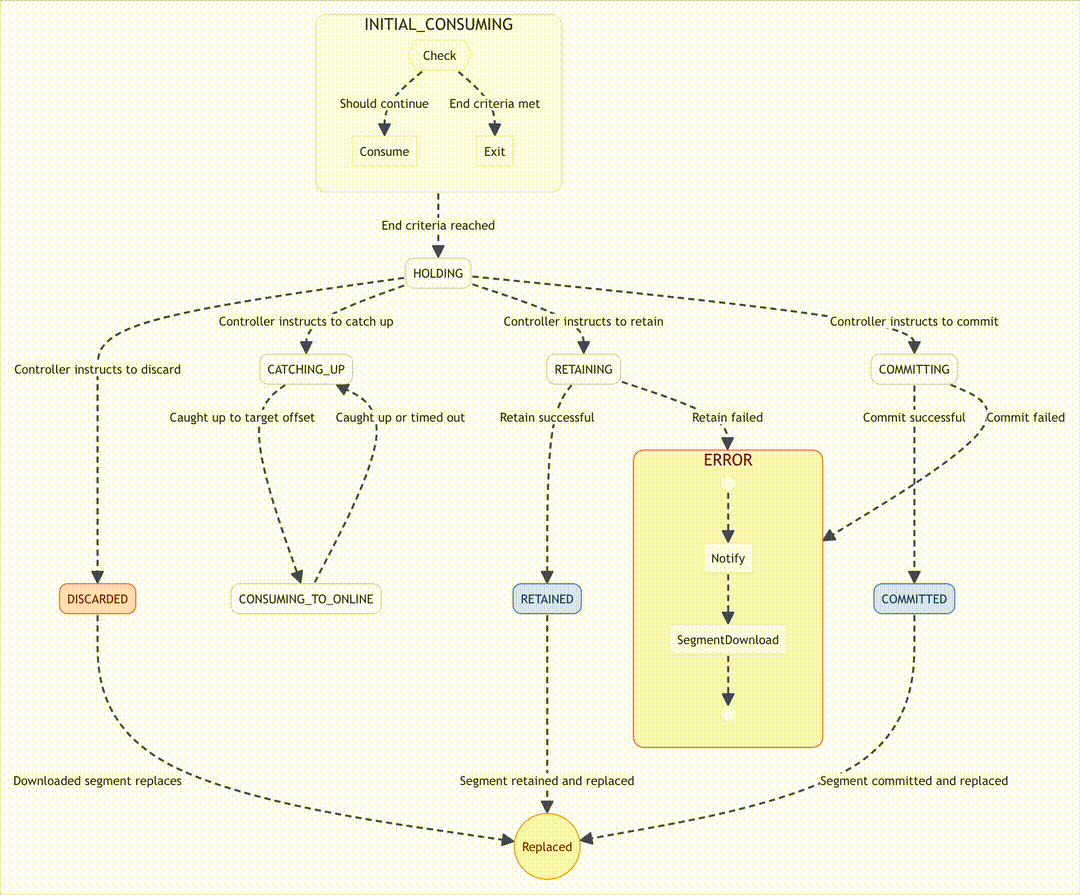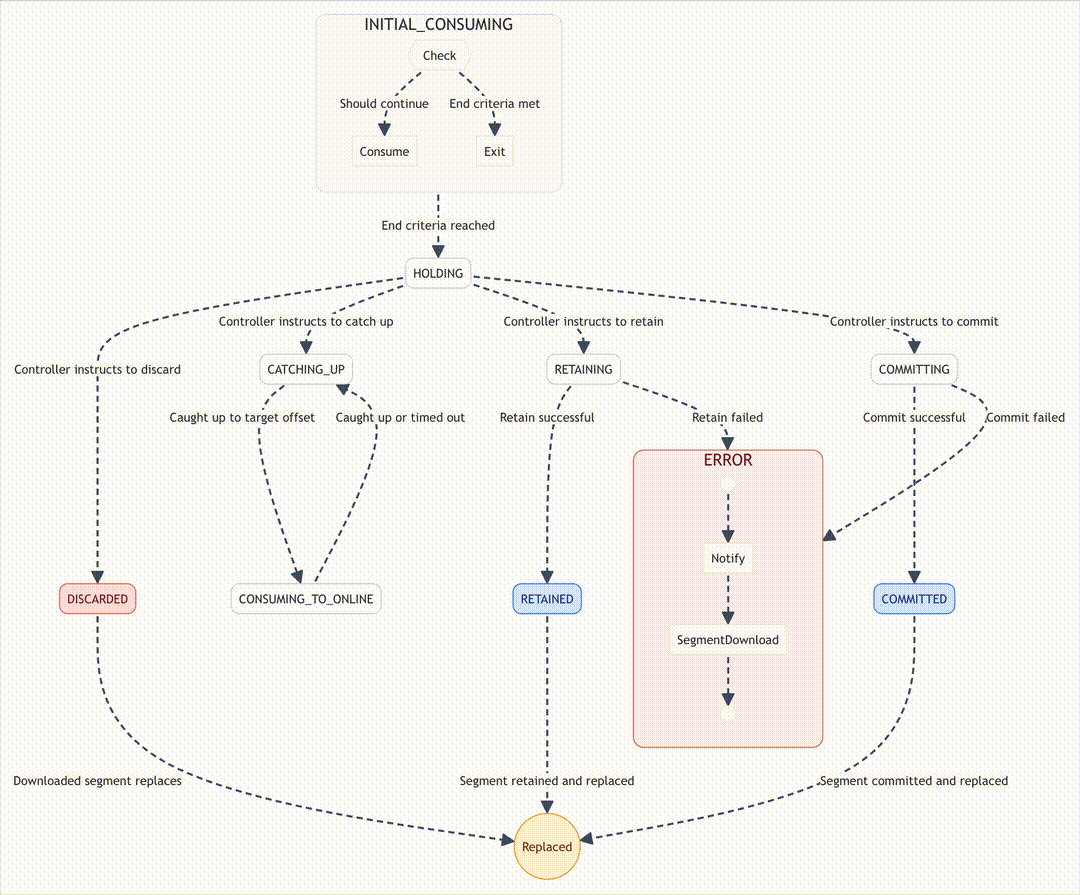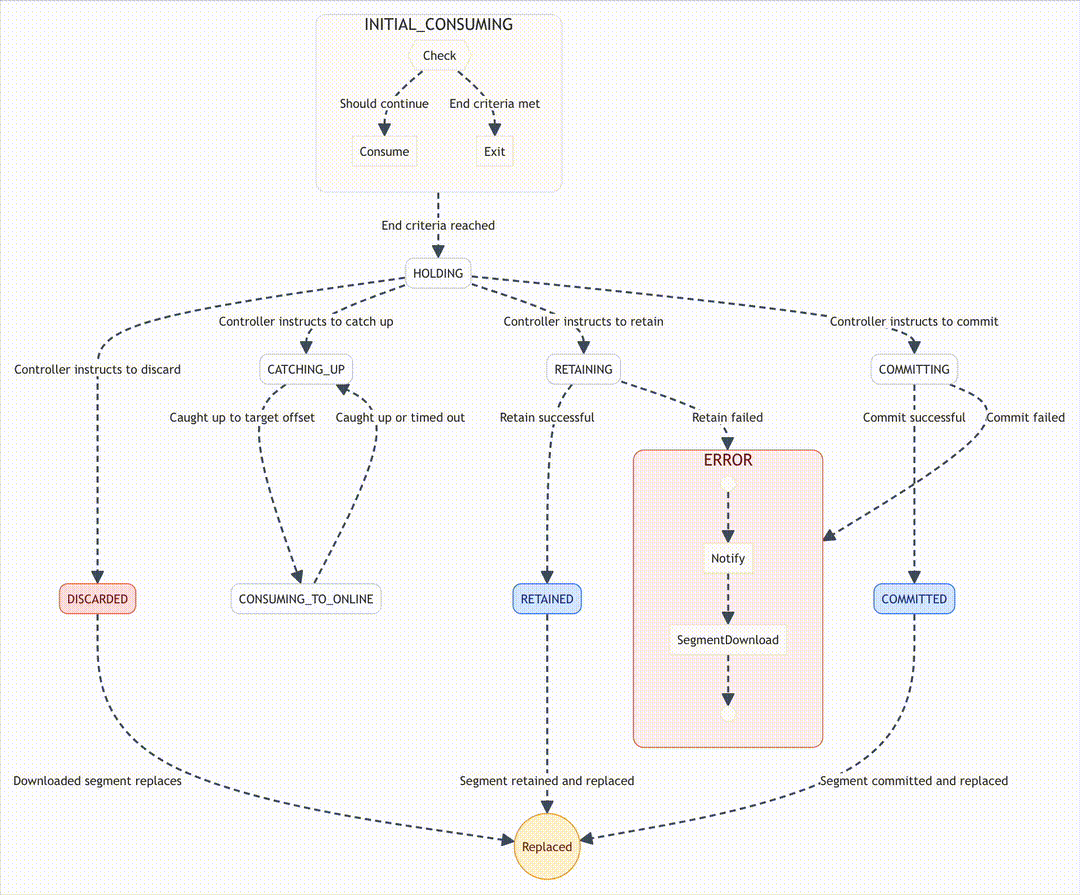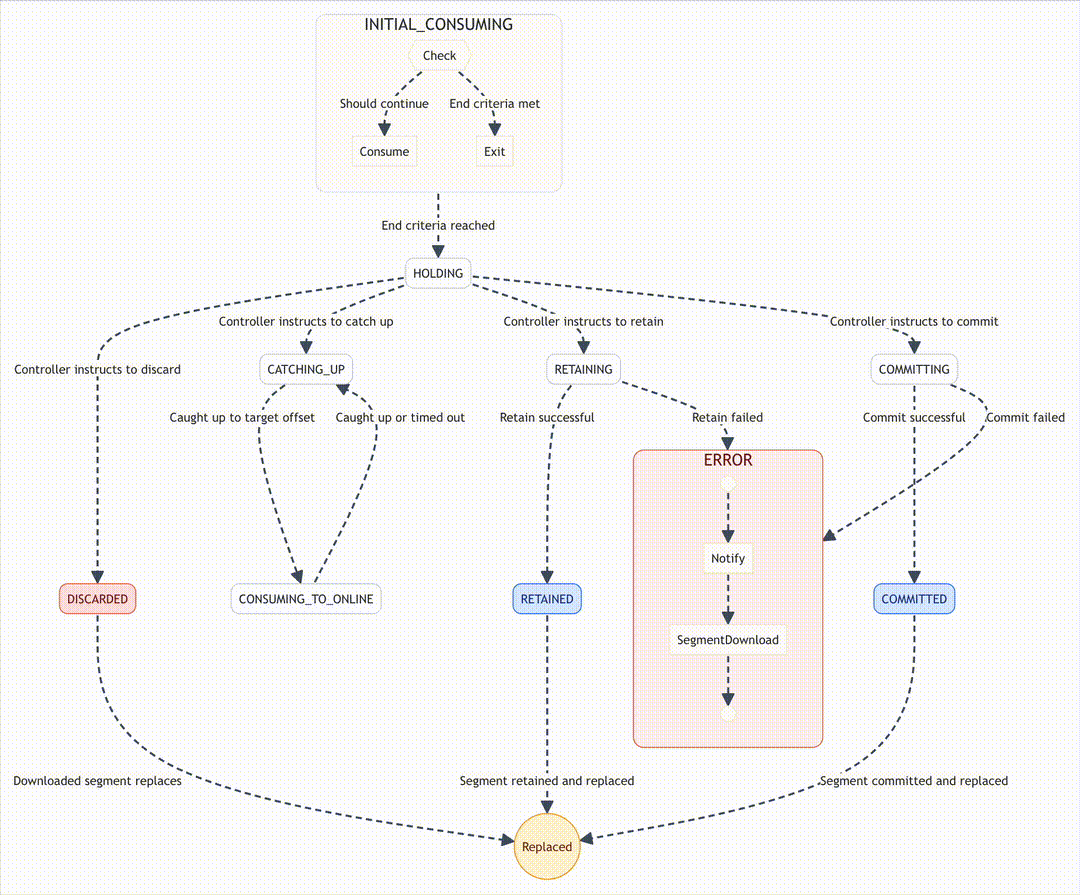
Mission control: The state machine that keeps Pinot in-flight
If ingestion is the rocket, Pinot’s consumer state machine is mission control. It ensures every step of the consume loop happens safely, even when servers fail.
To prevent chaos, Pinot manages ingestion with a Finite State Machine (FSM). This ensures operations happen in the correct order. Key states include:
- INITIAL_CONSUMING: Begin ingestion.
- CATCHING_UP: Synchronize with Controller-specified offsets.
- HOLDING: Pause while awaiting further instructions.
- CONSUMING_TO_ONLINE: Final synchronization before going online.
- COMMITTING: Build and upload the immutable segment.
- RETAINING/RETAINED: Retain the segment locally.
- COMMITTED: Segment committed successfully.
- DISCARDED: Segment discarded and replaced.
- ERROR: A failure state for retries or intervention.
The FSM is Pinot’s mission control. It orchestrates transitions, reduces race conditions, and guarantees ingestion consistency.
Mission accomplished (for now)
That concludes the flight, from Kafka bytes flowing through partitions to fully queryable Pinot segments. We examined how the consume loop processes events step by step, how flush thresholds prevent runaway growth, and how the FSM ensures order amid complexity. The outcome: a fast, resilient ingestion pipeline that turns raw streams into structured insights.
Yet this is only part of the journey. The greater challenge lies in maintaining consistency across replicas. When multiple servers ingest the same data, all must agree on what “committed” truly means. Pinot’s commit protocol addresses this, serving as the air-traffic control tower for distributed ingestion.
That, is the mission for the next chapter: From “segmentConsumed” to “COMMIT_SUCCESS” without losing your mind (or your offsets)

