

In our earlier post, “Low-latency Serving on Iceberg with Apache Pinot and StarTree Cloud,” we discussed how Apache Iceberg has evolved into the de facto source of truth for analytical data across modern data architectures. However, executing low-latency, high-concurrency queries directly on Iceberg remains non-trivial. Workloads such as serving personalized recommendations from near real-time clickstream data or computing ad campaign metrics on demand require a serving layer that can handle hundreds of queries per second (QPS) while maintaining sub-second latency.
The common workarounds each have trade-offs. ETL’ing data into a separate serving system (e.g., key-value or OLAP store) introduces data duplication, operational overhead, and staleness. Querying Iceberg directly using Trino or ClickHouse works well for exploratory analytics but doesn’t scale for always-on serving workloads due to their query planning and I/O patterns.
To bridge this gap, we introduced Iceberg Tables in Apache Pinot and StarTree Cloud—a feature that enables query acceleration directly on Iceberg data without ingestion or materialization. In this post, we present benchmark results demonstrating that Pinot can sustain 500+ QPS on a 1 TB Iceberg table with sub-second response times, using a 4 node (r6gd) cluster. We’ll also break down the architectural optimizations that make this possible.
Key Innovations
At the core of Pinot’s Iceberg integration is a simple but powerful idea: reduce the amount of data read and processed for each query. Since the primary bottleneck in querying Iceberg lies in network I/O latency—fetching Parquet files from remote object stores like S3—minimizing the number of files and pages read directly translates to faster queries. StarTree’s enhancements to Apache Pinot introduce several innovations to achieve this goal.
1. Metadata-based Pruning
When a query arrives, Pinot brokers intelligently determine the minimal set of segments that must be scanned. Using Iceberg metadata, Pinot can prune segments by time range, partition values, or other predicates. In addition, column-level statistics further eliminate irrelevant segments early in the query lifecycle—significantly reducing the amount of data fetched over the network.
2. Advanced Indexing
Pinot’s performance edge comes from its index-first architecture. It supports a rich variety of index types—JSON, text, StarTree, range, and inverted indexes—that can be configured on columns in the underlying Parquet files. These indexes narrow down the exact document IDs and Parquet pages relevant to a query. Instead of scanning entire files, Pinot can directly access the specific data blocks needed—dramatically reducing scan cost and latency. Contrast this with other query engines where the fetch granularity is coarser – at the column chunk level or worse still at the entire Parquet file level.
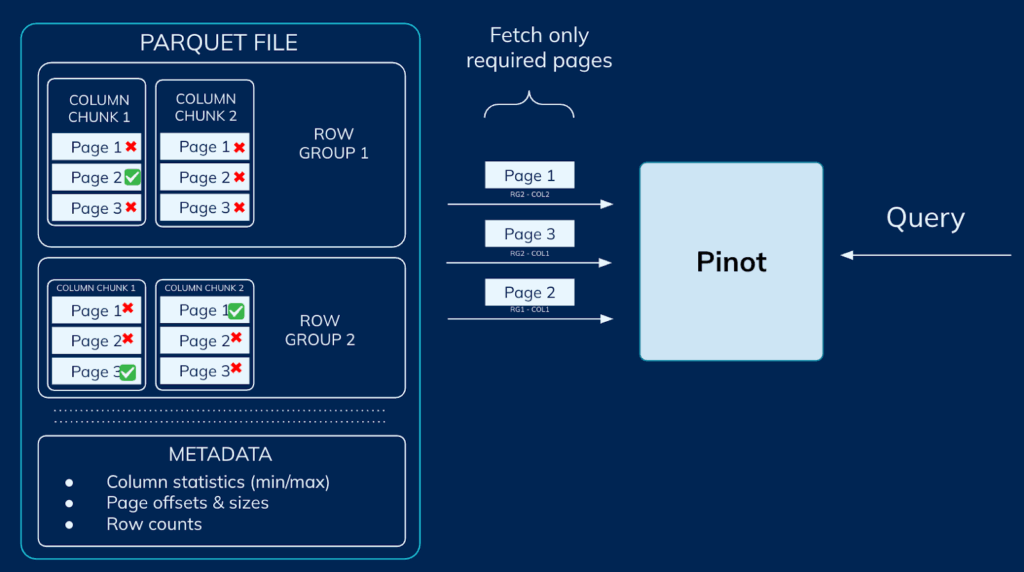
3. Intelligent Prefetching
Knowing which pages to read is only part of the equation; when those pages are available locally matters just as much. Pinot servers begin prefetching the required Parquet pages early—during query planning itself. Data fetching and decompression occur in parallel across multiple threads, ensuring that by the time the execution phase begins, most pages are already in memory and ready for processing. This concurrency model minimizes I/O wait time and ensures consistently low query latency.
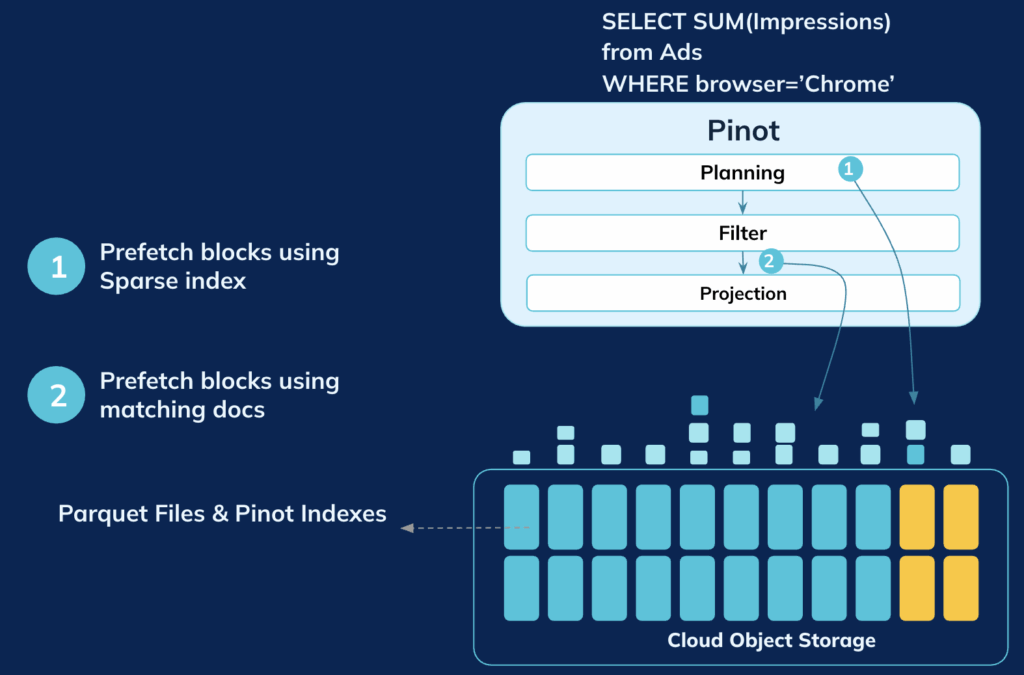
4. Custom Parquet Reader
StarTree built a custom Parquet reader deeply integrated into Pinot’s query execution engine. This reader supports remote Parquet access while seamlessly participating in Pinot’s caching, indexing, and prefetching mechanisms. The result is a system capable of reading Parquet files stored in Iceberg with near-native performance—without ingestion or data duplication.
5. Hierarchical Caching
Caching plays a central role in sustaining high throughput and low latency. StarTree implemented a multi-tier caching architecture that stores frequently accessed data such as forward indexes, Pinot indexes, and Parquet metadata. The cache is hierarchical—combining in-memory and on-disk layers with adaptive eviction strategies—so that subsequent queries can reuse previously fetched data efficiently, reducing both network I/O and deserialization overhead.
Benchmarking
In our benchmarking we will be comparing query latency and throughput performance between
- Regular Pinot table (Pinot Local): Data is ingested from Iceberg into Pinot and stored locally
- Remote Iceberg table: No data ingestion
Setup
- 4 r6gd Servers
- 16 core
- 128 GB memory
- JAVA Heap: 30GB
- Nvme local SSD per server
Data Characteristics
- Raw data size: ~ 1 TB
- Number of rows: ~ 12 Billion
- Schema: includes multiple dimensions including a Map type column + metrics
- Pinot Indexes configured: Inverted, Range , Composite Json
- Size of Indexes: ~ 300 GB
Queries
We used all high selectivity queries for this experiment to indicate data serving nature of the workload
- count(*) with Filter on various dimension look ups + time range filter
- Aggregation on primitive type column + filter
- Aggregation on primitive type column + filter + group by
- Aggregation on Map type column + filter + group by
Query Selectivity is generally very high, most of them ranging from around < 10% (most selective) to ~70% (least selective).
Cache
There are 2 kinds of caches: one for the raw data (coming from source Parquet file) and one for the Pinot indexes. In the experiments below, we can see comparative performance by turning on or off either or both of these caches. We’ve used the following caching configuration per node:
- Data cache: 100 GB
- Index cache: 300 GB
Comparing Query Latency
Let’s take a look at the query latency comparison between regular Pinot table and Iceberg table with the different caching modes. Note that the measurements have been taken when the cache is warm – when applicable.

We have the following observations
- With the data and index cache enabled, Iceberg table performance is pretty much the same as Pinot local.
- With only Index cache enabled, filter queries are extremely fast. Similarly, all other queries are sub-second.
Comparing Query Throughput
Now, let’s take a look at query throughput with the same setup

Again, we observe that with both data and index cache, we’re able to sustain very high query throughput on all the queries. With Index only cache, some queries (count(*) with filter) can run with high concurrency since we don’t need to fetch any remote data in that case.
Conclusion
Our benchmarking validates that with the right architectural optimizations—metadata pruning, intelligent indexing, prefetching, custom Parquet reader, and hierarchical caching—Apache Pinot can deliver sub-second query latency and high throughput directly on Iceberg, comparable to querying locally ingested Pinot tables. When caching is enabled, query latency and throughput effectively match Pinot local performance while operating at a fraction of the cost, since data stays in Iceberg with no duplication or ETL overhead.
This fundamentally changes the economics of real-time analytics. Organizations can now serve low-latency, high-concurrency workloads directly from their Iceberg data lake, using Pinot as a lightweight, query acceleration layer. Whether for personalized recommendations, operational dashboards, or campaign analytics, this approach combines the flexibility of open data formats with the performance of a purpose-built serving engine—bringing true “always-on analytics” to the modern data stack.
Try it yourself with StarTree Cloud
If you’d like to explore low-latency serving on data in Iceberg, you can try this out with StarTree Cloud. The onboarding team at StarTree can set you up with Apache Pinot to explore this powerful new functionality. Book a Meeting with us to get started today.
