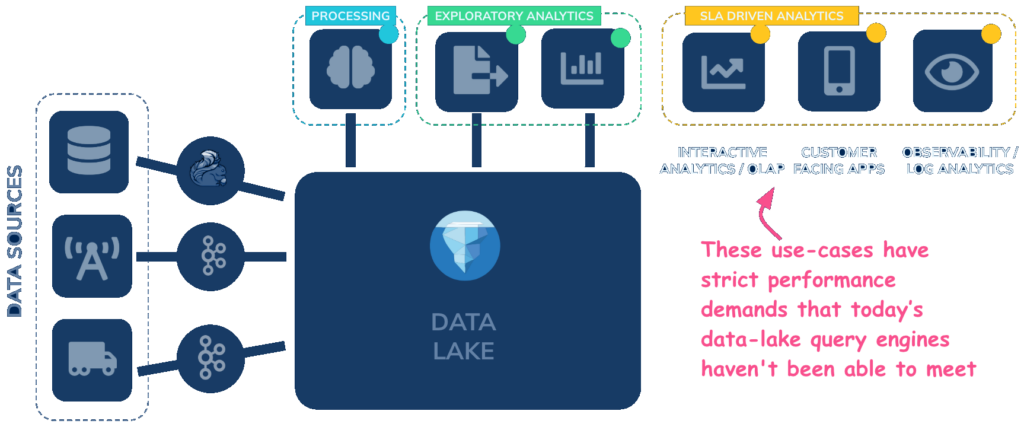
Sub-second analytics on the data lake!
With Apache Pinot on StarTree Cloud, you can now reliably serve low-latency, high-concurrency analytics directly on data in Apache Iceberg.
The lakehouse solved storage. It didn’t solve performance
Open table formats like Iceberg, Delta Lake and Hudi promise a modern, open data platform where data is stored once, governed once, and accessible by various engines purpose-built for different workloads.
The missing piece of the puzzle has been how to access it with reliably interactive performance?
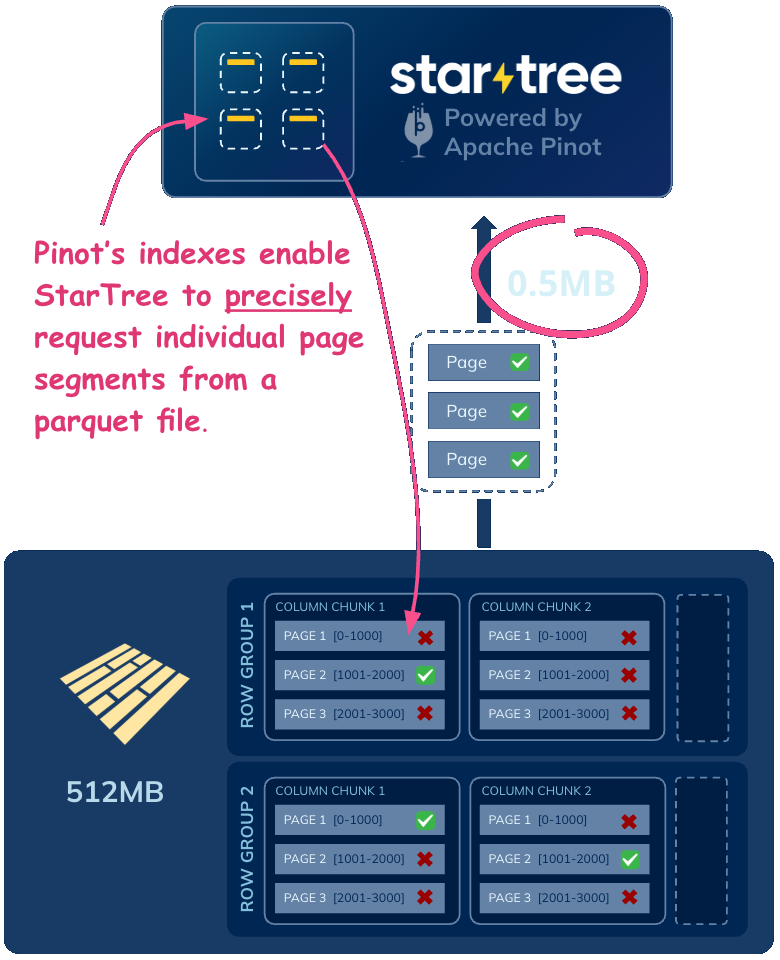
The power of Apache Pinot, brought to the lake!
- Prune aggressively StarTree uses Iceberg metadata and column statistics to narrow the query to the smallest relevant set of files and segments as early as possible.
- Narrow further with filters and indexes Bloom filters and Pinot indexes reduce the search space even more, helping StarTree find exactly which data blocks matter.
- Fetch precisely Instead of reading whole files or coarse column chunks, StarTree fetches only the relevant Parquet pages required for the query.
- Execute efficiently Intelligent prefetching, hierarchical caching, and a custom Parquet reader help keep performance fast and predictable, even on externally stored data.
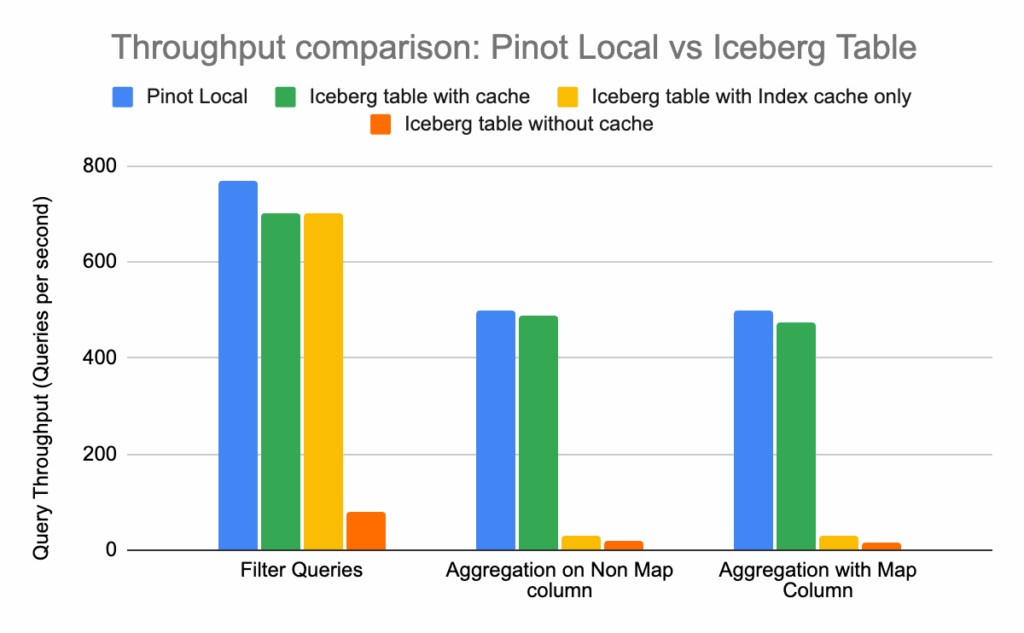
500+ QPS on a 1 TB Iceberg table with sub-second response times
More than a materialized view of the lake
But, the bigger your lake gets, the worse this approach becomes!
Ideal for projects that already have data in Iceberg — and need it to do more
Interactive Analytics
Exploratory analytics on the data lake doesn’t need to be slow. Give users the power to explore data interactively, filter by many dimensions, and ask new questions as data structures evolve.
Deep-Dive Observability
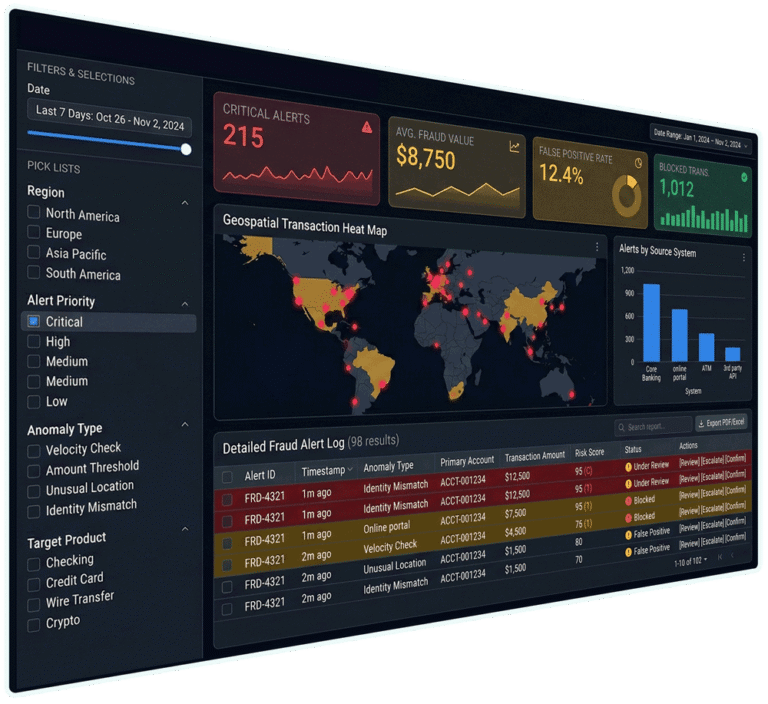
Give anomoly detection and observability systems the power and performance to run at high query volumes and with minimal latency. Slice and dice and investigate issues interactively, handle high concurrency and bursty traffic, and to do this all with predictable p95/p99 latencies.
Customer & Agent Facing Data Products
Build customer-facing apps and agent-facing data products without building new data pipelines or custom data stores. Ideal for prototyping new products or tapping into historical data that was previously limited to delayed reports.
Recent Articles
More from the blog »


Try StarTree with your lakehouse data
Book a demo to chat about your lakehouse demands and query patterns, and to learn more about how StarTree can help you deliver faster analytics with less complexity.