
Upserts are crucial for real-time analytical databases because they enable handling late-arriving data, corrections, and rapid updates, which are essential for data accuracy for many analytical use cases.
Apache Pinot provides real-time upsert functionality with additional features like partial upserts, deletion, and various consistency modes. StarTree makes Pinot upserts more cost efficient by using RocksDB as an upsert metadata store, which reduces memory requirements by 10x in our fully-managed service.
This post dives into scalability challenges when data is updated at a high rate which makes compaction very important for upsert tables and then describes how StarTree provides an elegant solution for this.
With this solution, StarTree has enabled customers to continuously update data which is periodically compacted & merged thus
- reducing storage costs by 2X – 10X (depending on rate of upserts)
- enabling customers to increase data retention period
- ensuring predictable query latencies
Why Upserts Are Challenging at Scale
Pinot stores data in a columnar format to optimize analytical query performance. This column-oriented architecture excels at aggregating large datasets and performing complex analytical operations.
In Apache Pinot, upserts are modelled as append only writes + metadata update. This leads to following challenges :
- Data Bloat: Each upsert operation results in versioned data that accumulates over time, increasing storage and cloud costs.
- Query Performance Degradation: The database engine must now scan through multiple versions of the same logical record, filter out obsolete data, and merge results during query execution.
These challenges become particularly acute in high-throughput environments where billions of upsert operations occur daily. To mitigate this, users are forced to set low retention periods in many databases.
Databases actually require sophisticated compaction processes that merge and deduplicate records. This process should:
- Be efficient enough to run frequently without significant cost overhead
- Not impact query performance
- Provide consistent query results (every query sees only the latest version of each primary key)
Pinot’s Upsert Metadata
Pinot’s upsert support is designed for real-time event ingestion. When a new record arrives, it marks older records with the same primary key as obsolete via in-memory bitmaps. The old records, though filtered from queries, still live in the table segments.
The diagram below shows the relevant metadata
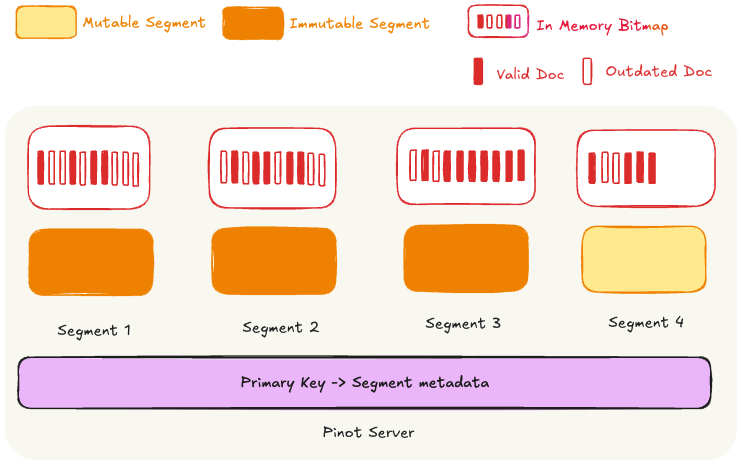
- A mutable segment: is a data file that is being ingested in realtime (via kafka / kinesis).
- An Immutable segment is a sealed data file that contains the physical data of a given time range / partition.
- In-memory bitmap: (per segment) tracks which docs are valid (latest version) within the segment
- Upsert Metadata: This is a map from primary key -> segment id which tracks the current segment which has the valid doc for a given primary key.
As new records are ingested in the mutable segment, the bitmap is updated in older segments for the corresponding primary key(s). This is done atomically to ensure queries only see 1 result for every primary key. A sample sequence of steps is
- Record with PK=5 arrives in the mutable segment
- Server looks up PK=5 in upsert metadata and finds it in segment S1 at docId 3
- Server flips bit 3 off in S1’s bitmap, sets the bit in the mutable segment’s bitmap and updates the upsert metadata to point PK=5 to the mutable segment. This is done atomically
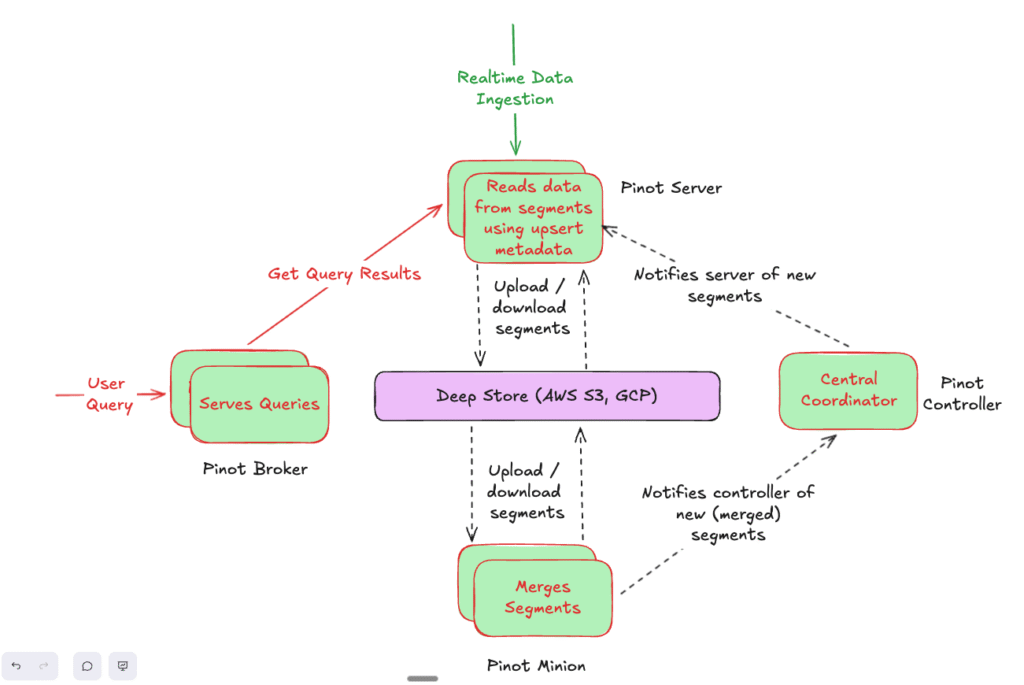
StarTree’s Solution for Compaction
StarTree provides a background task – SegmentRefreshTask for this.
This runs outside the query path (via Pinot Minions) as a scheduled job at a fixed cadence. It
- Selects groups of segments (prioritises segments which have a higher ratio of obsolete docs)
- Extracts only the valid (non-obsolete) documents
- Merges / compacts them into new segments. The decision to merge / compact a segment is based on the desired output size of a segment.
- Uploads the segments to a deep store (AWS S3, GCP)
Then, the servers download these segments and atomically replace the current segments on disk with the new compacted / merged segment while ensuring no degradation in query / ingestion performance.
The overall process ensures query consistency & correctness, which we’ll explore further in the next section
Query consistency
Problem: How do you replace old segments with new compacted & merged ones without queries briefly seeing duplicate or missing records?
Let’s assume segment S1 and S2 are merged to a new segment S3
During segment replacement, Pinot leverages validDocIds bitmaps itself to ensure atomicity and a consistent table view for upsert tables. This mechanism works as follows:
- Immediate Visibility of New Segments: New segments are made visible to queries immediately. Initially, their bitmaps are empty, meaning no documents within them are visible. So queries read the documents from S1 and S2 only.
- Progressive Document Visibility: As documents in the new segments are processed in the background, the upsert metadata and bitmaps are updated, making documents progressively visible. Queries can read documents from S1, S2 or S3. Bitmaps are updated atomically (similar to the process during new data ingestion) so a given PK is set in either S1 or S2 or S3 alone.
- Completion of Replacement: Upon completion of the segment replacement process, the validDocIds bitmaps of the new segments become accurate (also reflecting ongoing data ingestion that may invalidate some documents). Conversely, the validDocIDs bitmaps of the old segments become empty. So queries read the documents from S3 alone.
The diagram below illustrates the query consistency. The numbers inside the bars are the primary keys which are guaranteed to be visible throughout the process with the latest value.
The merged segment is generated from Input Segment 1 and Input Segment 2. As documents are individually loaded, the corresponding bitmaps are unset in the input segments and set in the merged segment. If the primary key is present in a new consuming segment, it is unset in the older input / merged segment.
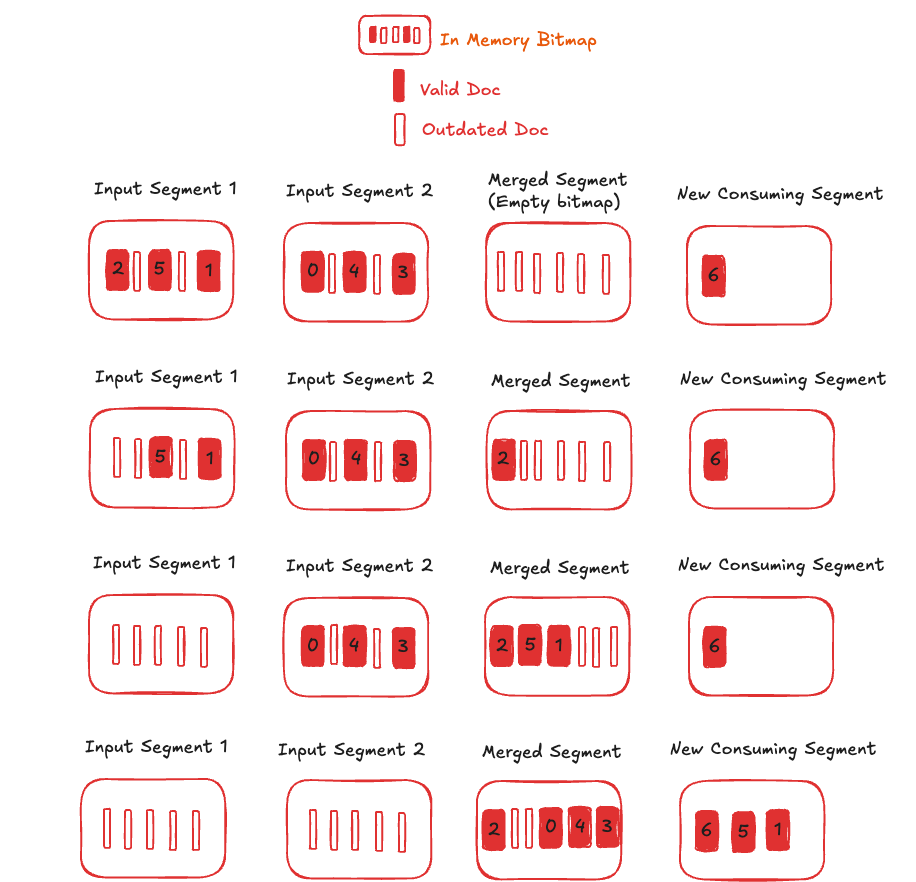
This approach guarantees that queries always see a consistent table view throughout the process, effectively making compaction and merging an invisible background operation.
Query correctness
Problem: When compaction creates new segments from old ones, the system must ensure that tie-breaking rules for records with the same primary key still produce correct results. Otherwise, compaction could surface stale data.
Upsert tables use a comparison column to decide which record wins when two records share the same primary key. By default, Pinot uses the timeColumn for this.
When the comparison values are equal, Pinot falls back to positional ordering: a monotonically increasing DocumentId within a segment, and the segment’s SequenceId across segments. This works well during normal ingestion — newer segments naturally get higher sequenceIds, so the latest record wins.
But compaction introduces a new challenge. A merged segment is newer than the original segments it was built from, yet it contains older data. If we’re not careful, positional ordering could let a stale record in a merged segment beat a fresher record from the input stream, simply because the merged segment was created later.
The ordering we need for comparison ties is:
newly ingested records > records in merged segments > records in original segments
In other words, live ingestion always wins, merged segments take precedence over the raw originals they replaced, and original segments have the lowest priority.
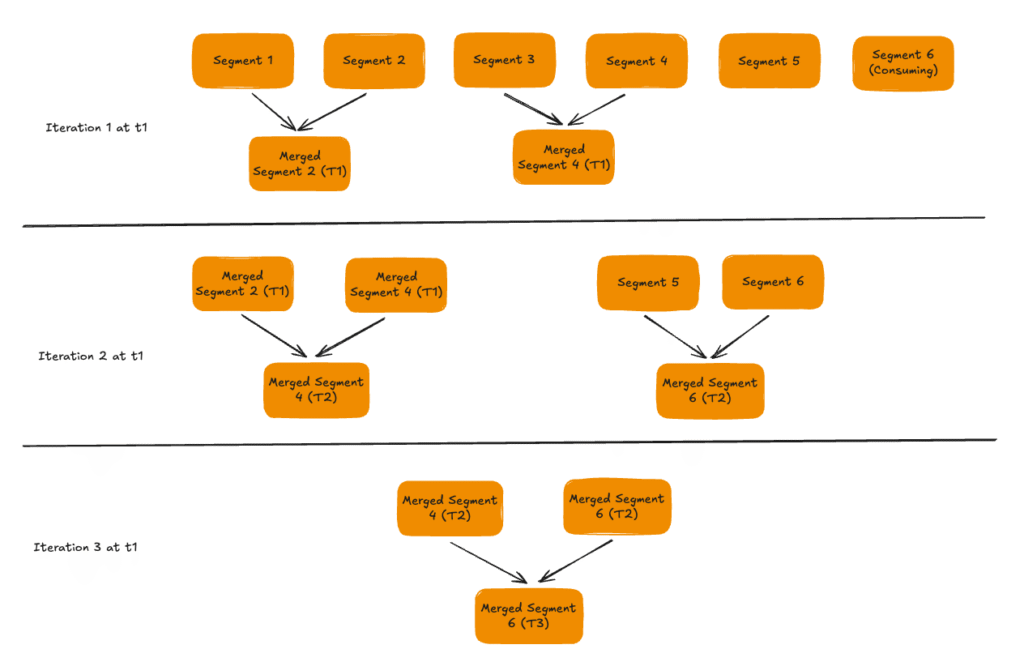
The key insight is in how merged segments are named and assigned a SequenceId.
The SegmentRefreshTask always selects a contiguous range of segments (by SequenceId) as input. The resulting merged segment is named merged__{tableName}__{partitionId}__{creationTime}__{sequenceId} where the sequenceId is set to the maximum sequenceId of the input segments.
Here’s a concrete example to see why this works:
- Suppose segments with
SequenceIds 3, 4, 5 are selected for compaction. - The merged segment is assigned
SequenceId5 (the max of the inputs). - Meanwhile, real-time ingestion continues and produces a new segment with
SequenceId6. - On a tie-break,
SequenceId6 > 5, so the newly ingested record wins — exactly as desired.
What about successive rounds of compaction? Suppose a later round merges the merged segment (SequenceId 5) with segments 6 and 7. The new merged segment gets SequenceId 7. A fresh real-time segment will be assigned SequenceId 8, and again, ingestion wins.
This is also why input segments must be contiguous — gaps would break the SequenceId ordering invariant.
Tie breaks are now handled in below order
- Comparison value(s)
- DocumentId (within a segment)
- SequenceId (across segments)
- CreationTime (across segments with same sequenceId) – This can occur during the replacement window when a merged segment coexists with one of its input segments that shares the same max sequenceId
Reliability
Upsert tables have 3 sources of data – Upsert PK metadata, Valid doc id bitmap, segment data. A major challenge is keeping these sources consistent with each other. Any inconsistency can result in data consistency or worse data loss.
The task has been hardened through stress and chaos testing with 100k+ segments under concurrent ingestion, rebalancing, schema evolution, and failure scenarios, intermittent delays, etc
Conclusion
The SegmentRefreshTask has enabled customers to scale their upsert use cases to
- 1 billion+ primary keys
- 100k/sec ingestion rate with predictable query latencies and query result consistency
- Infinite retention period – Because obsolete records are physically removed, storage costs remain constant even with infinite retention
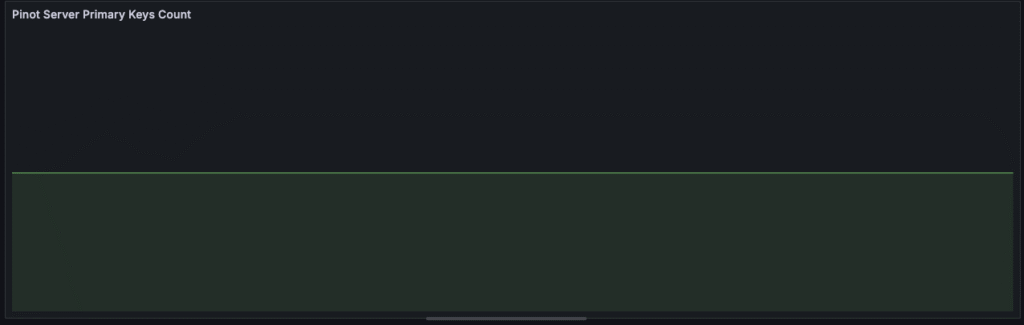
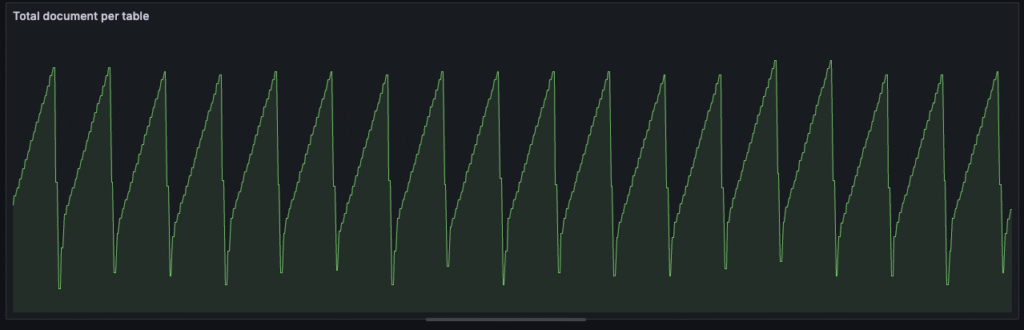
Below graphs show the results with a fixed number of primary keys being continuously updated. It is seen that the total primary key count (as measured by queries) is constant while the total number of documents follows a see-saw pattern. The total number of documents increases as data is updated and then falls to a baseline as compaction runs
For more details on using and configuring SegmentRefreshTask in StarTree Cloud, see Compaction after Upserts – StarTree Docs
Talk to a Pinot Expert
If you have more questions about Apache Pinot or StarTree Cloud, we’d love to talk with you. Book a meeting with a Pinot expert today.
